论文阅读之《Kindling the Darkness: A Practical Low-light Image Enhancer》
目录
摘要
介绍
已有方法回顾
普通方法
基于亮度的方法
基于深度学习的方法
基于图像去噪的方法
提出的方法
2.1 Layer Decomposition Net
2.2 Reflectance Restoration Net
2.3 Illumination Adjustment Net
实验结果
总结
Kindling the Darkness: A Practical Low-light Image Enhancer(KinD)
ACM MM 2019
Yonghua Zhang, Jiawan Zhang, Xiaojie Guo (天津大学)
论文地址:http://cic.tju.edu.cn/faculty/zhangjiawan/Jiawan_Zhang_files/paper/yonghuazhang2019-2.pdf
项目地址:
https://github.com/zhangyhuaee/KinD
摘要
在弱光条件下拍摄的图像通常能见度较差。除了不理想的照明,多种类型的退化,如噪音和颜色失真,由于相机的质量有限,这些退化隐藏在黑暗中。仅提高黑暗区域的亮度将不可避免地放大隐藏的退化。这项工作建立了一个简单而有效的点燃黑暗的网络(表示为kinD),它的灵感来自视retinex理论,将图像分解成两个部分。一个组件(照明)负责光的调节,而另一个组件(反射率)负责退化去除。网络是在不同曝光条件下拍摄的成对图像进行训练的。可以抵抗严重的视觉缺陷,并且用户可以任意调节光线的亮度。
介绍

图1 不同光照条件下的自然图像
第一种情况是极低的光。严重的噪音和颜色失真隐藏在黑暗中。通过简单地放大图像的强度,退化就会显示在右上角。第二张照片是在日落时拍摄的(微弱的环境光),大多数物体都背光。中午对着光源(太阳)成像也很难摆脱像第二种情况那样的问题,尽管周围的光线更强,场景更清晰可见。最后两张照片中那些相对明亮的区域直接放大会导致饱和。
基于深度学习的方法在去噪、超分辨率等数值底层视觉任务中表现优异,但其中大部分都需要训练数据包含地面实况。对于特定问题,比如低光图像增强,虽然可以确定光强的大小顺序,但是不存在ground-truth真实数据。从用户的角度来看,不同的人/需求所喜欢的光照等级可能是多种多样的。
文中总结了低光图像增强的挑战如下:
1.如何从单个图像中有效地估计出光照分量,并灵活地调整光照?
2.如何在照亮黑暗区域后去除之前隐藏在黑暗中的噪声和颜色失真等退化?
3.如何训练一个模型,在没有明确的Ground truth条件下,只看两个/几个不同的例子情况下增强低光图像?
一个理想的弱光图像增强算法应该能够有效的去除隐藏在黑暗中的退化并灵活的调整曝光条件。、
论文主要贡献:
1.受Retinex理论的启发,该网络将图像分解为反射率和照明两部分。
2.该网络使用在不同光/曝光条件下捕获的成对图像进行训练,而不是使用任何地面真实反射率和照明信息。
3.模型提供了一个映射功能,可以根据用户的不同需求灵活地调整光线的等级。可有效地去除通过亮暗区域放大的视觉缺陷。
已有方法回顾
普通方法
1.对于全局光线较弱的图像,可以通过直接放大亮度来增强其可视性。但是噪声和颜色失真会沿着细节显示出来。对于包含明亮区域的图像,很容易导致(部分)饱和/过度曝光。
2.以直方图均衡化及其后续为代表的技术提高图像的对比度。
3.伽马校正(GC):以非线性方式在每个像素上单独执行,可以提高亮度但没考虑相邻像素的关系。
(几乎不考虑真实的光照因素,使增强的结果在视觉上很不稳定与真实场景不一致)
基于亮度的方法
1.基于Retinex理论的SSR,MSR方法,受限于生成最终结果的,方式输出看起来不自然,在某些地方过度增强。
2.NPE:同时增强对比度,保持照度的自然。
3.SRIE加权变分模型:同时进行反射率和光照估计,控制光照形成目标图像。可抑制噪声但处理颜色失真和较大噪声方面不足。
基于深度学习的方法
1.LLNet(Pattern Recognition 2017):构建了一个深度网络,作为同时进行对比度增强和去噪的模块。
2.MSR-net(arXiv 2017):认为多尺度retinex相当于具有不同高斯卷积核的前馈卷积神经网络 构建了卷积神经网络来学习暗图像和亮图像之间的端到端映射。
3.RetinexNet(BMVC2018):它集成了图像分解和光照映射,反射去噪,照明增强。没有考虑噪声对不同光照区域的影响。
4.SID(CVPR2018):基于全卷积网络端到端训练的低光图像处理管道(SID),可以同时处理噪声和颜色失真。然而,这项工作是针对raw格式的数据的,限制了其适用的场景。若修改网络以接受JPEG格式的数据,性能会显著下降。
基于图像去噪的方法
1.基于自然图像的特定先验(局部相似性,分段平滑性,信号稀疏等)BM3D,WNNM。
2.基于DL的去噪:SSDA-堆叠稀疏自编码器,DnCNN-残差学习和批量归一化
(没有考虑到光照增强图像的不同区域承载不同级别的噪声)
提出的方法
KinD Network分为三部分:(1)图像分解网络:Layer Decomposition Net(2)反射分量纠正网络:Reflectance Restoration Net(3)光照分量纠正网络:Illumination Adjustment Net。整个网络架构如下图所示。
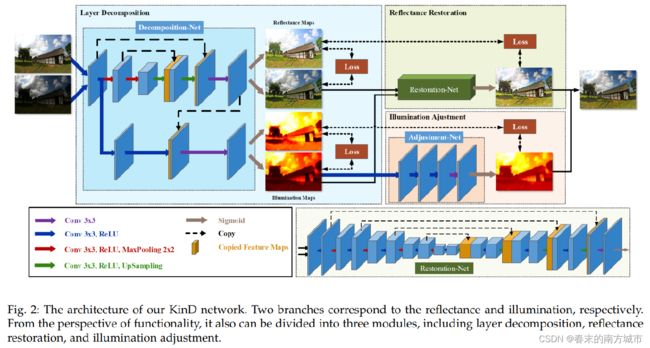
以暗光/正常光照图像对作为训练样本,Layer Decomposition Net对其依次进行分解,得到光照分量和反射分量。再通过Reflectance Restoration Net和Illumination Adjustment Net得到�~���和和�~���。
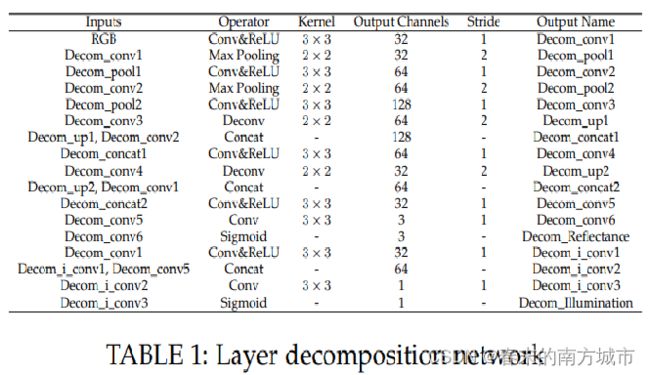

2.1 Layer Decomposition Net
Layer Decomposition Net有两个分支,一个分支用于预测反射分量,另一个分支用于预测光照分量,反射分量分支以五层Unet网络为主要网络结构,后接一个卷积层和Sigmoid层。光照分量分支由三个卷积层构成,其中还利用了反射分量分支中的特征图,具体细节可参考论文。
Layer Decomposition Net:

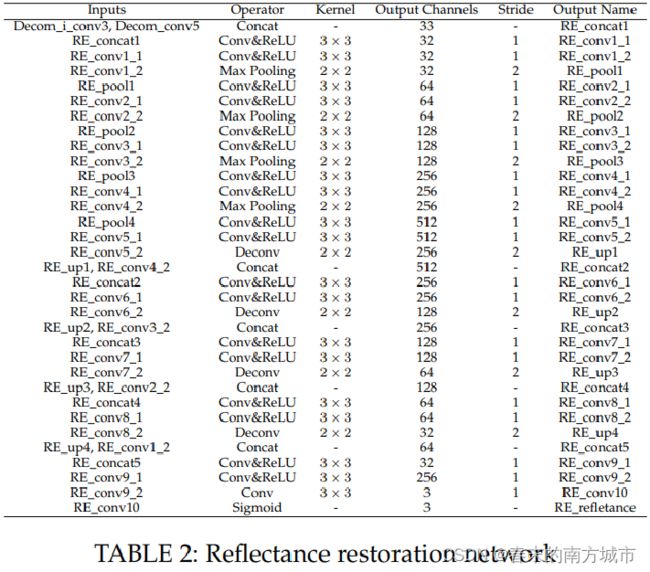
2.2 Reflectance Restoration Net
低光照图像的反射分量有更多的退化分量,所以这里使用高光照图反射分量作为真值约束训练;同时反射分量的分布和光照分量也有关系,所以这里将光照分量的信息也嵌入到该网络里。网络预测得到的纠正后反射分量为;Reflectance Restoration Net的Loss为:

2.3 Illumination Adjustment Net
网络比较轻量化,由三个卷积层组成。光照分量的纠正与反射分量纠正类似,这里同样使用高光照图光照分量作为真值约束训练,网络预测得到的纠正后反射分量;Illumination Adjustment Net的Loss为:
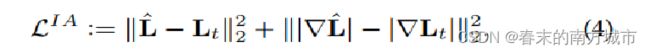
实验结果





总结
基于深度学习的图像暗光增强就是以Retinex理论为基础,用卷积神经网络去分解图像S,得到光照分量I和反射分量R,这也是相当于在深度学习中融入了图像增强的先验知识。最近一些更新的,效果更好的论文大多也都是围绕如何更好的分解图像,生成质量更好的光照分量和反射分量来进行。也有一些人通过GAN直接以图像生成的方式来进行图像增强。