Hadoop3教程(二十四):Yarn的常用命令与参数配置实例
文章目录
- (132)YARN常用命令
-
- 查看任务
- 查看日志
- 查看容器
- 查看节点状态
- rmadmin更新配置
- 查看队列
- (133)生产环境核心配置参数
- (135)生产环境核心参数配置案例
- (140/141)Tool接口案例
- 参考文献
本章我是仅做了解,所以很多地方并没有深入去探究,用处估计不大,可酌情参考。
(132)YARN常用命令
查看任务
列出所有Application:yarn application -list
根据Application状态过滤出指定Application,如过滤出已完成的Application:yarn application -list -appStates FINISHED
Application的状态有:ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED。
杀掉某个Application:yarn application -kill application-id
其中,application_id是一串形如application_1612577921195_0001的字符串。
列出所有Application尝试的列表:yarn applicationattempt -list
打印ApplicationAttempt的状态:yarn applicationattempt -status
查看日志
非常重要。
查询某个Application的日志:yarn logs -applicationId
查询container日志:yarn logs -applicationId
查看容器
列出所有容器:yarn container -list
打印容器状态:yarn container -status
只有在任务运行的时候,才能看到container的状态
查看节点状态
列出所有节点:yarn node -list -all
就是打印出集群下所有服务器节点的运行状态和地址信息啥的。
rmadmin更新配置
加载队列配置:yarn rmadmin -refreshQueues
可以实现对队列配置信息的动态的修改,无需停机。
查看队列
打印队列信息:yarn queue -status
比如说yarn queue -status default,就是打印默认的队列
会打印出队列的状态、当前容量等等。
(133)生产环境核心配置参数
同样仅做了解,所以直接截教程的图了:
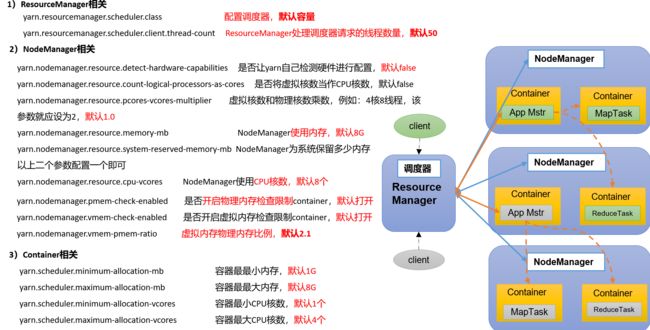
RM默认并发是50线程
这里有个"虚拟核数"的概念,需要简单介绍一下。
首先需要知道,集群里每个NM都有自己的一套配置参数,并不严格要求每个NodeManager的配置参数都必须是一样的。
这样做主要是考虑到节点间性能差异较大的情况。比如说节点1的单核CPU性能是节点2单核CPU性能的两倍,那么将二者一视同仁来分配任务的话就有问题了。这时候就可以开启节点1的虚拟核功能,把一个物理核视为两个虚拟核,这时候,节点1和节点2的单核(虚拟核)CPU性能就接近了,也方便RM来分配任务。
即不同NM的话,一个物理核数作为几个虚拟核数来使用,是不一样的。这样做是为了防止因节点CPU性能不同,不好统一管理各个CPU。
所以,如果有CPU混搭的情况,如有节点是i5,有节点是i7这种,是有需要开启虚拟核的。
“物理内存检查机制”,是为了防止节点内存超出导致崩溃,默认打开;
(135)生产环境核心参数配置案例
需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。
块大小使用默认的128M,1G/128M=8,所以整个任务需要启用8个MapTask,1个ReduceTask,以及1个MrAppMaster。
平均每个节点运行(8+1+1)/3台 约等于 3个任务,假设采用4+3+3分布。
基于以上需求和硬件条件,可以做出如下思考:
1G数据量不大,可以使用容量调度器;
RM处理调度器的线程数量默认50,太大了,没必要,可以削成8;
不同节点CPU性能一致,不需要开启虚拟核;
其他配置暂且不表。
直接把教程里的yarn-site.xml配置参数贴出来吧,方便之后查看。
<property>
<description>The class to use as the resource scheduler.description>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
<property>
<description>Number of threads to handle scheduler interface.description>
<name>yarn.resourcemanager.scheduler.client.thread-countname>
<value>8value>
property>
<property>
<description>Enable auto-detection of node capabilities such as
memory and CPU.
description>
<name>yarn.nodemanager.resource.detect-hardware-capabilitiesname>
<value>falsevalue>
property>
<property>
<description>Flag to determine if logical processors(such as
hyperthreads) should be counted as cores. Only applicable on Linux
when yarn.nodemanager.resource.cpu-vcores is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true.
description>
<name>yarn.nodemanager.resource.count-logical-processors-as-coresname>
<value>falsevalue>
property>
<property>
<description>Multiplier to determine how to convert phyiscal cores to
vcores. This value is used if yarn.nodemanager.resource.cpu-vcores
is set to -1(which implies auto-calculate vcores) and
yarn.nodemanager.resource.detect-hardware-capabilities is set to true. The number of vcores will be calculated as number of CPUs * multiplier.
description>
<name>yarn.nodemanager.resource.pcores-vcores-multipliername>
<value>1.0value>
property>
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
description>
<name>yarn.nodemanager.resource.memory-mbname>
<value>4096value>
property>
<property>
<description>Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.description>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>4value>
property>
<property>
<description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager.
description>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>1024value>
property>
<property>
<description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException.
description>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
<property>
<description>The minimum allocation for every container request at the RM in terms of virtual CPU cores. Requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have fewer virtual cores than this value will be shut down by the resource manager.
description>
<name>yarn.scheduler.minimum-allocation-vcoresname>
<value>1value>
property>
<property>
<description>The maximum allocation for every container request at the RM in terms of virtual CPU cores. Requests higher than this will throw an
InvalidResourceRequestException.description>
<name>yarn.scheduler.maximum-allocation-vcoresname>
<value>2value>
property>
<property>
<description>Whether virtual memory limits will be enforced for
containers.description>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
<property>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.
description>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
(140/141)Tool接口案例
生产环境下比较有用的一个功能。仅做了解吧,本节我其实并没有深入,只做了简单的复制。
通过tools接口,可以实现我们自己程序的参数的动态修改
接下来以自定义实现WordCount为例。
在编写代码的时候,pom.xml里要引入:
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
dependencies>
创建类WordCount,并实现Tool接口:
package com.atguigu.yarn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.io.IOException;
public class WordCount implements Tool {
private Configuration conf;
//核心驱动
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
@Override
public Configuration getConf() {
return conf;
}
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
outK.set(word);
context.write(outK, outV);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
}
新建WordCountDriver:
package com.atguigu.yarn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.Arrays;
public class WordCountDriver {
private static Tool tool;
public static void main(String[] args) throws Exception {
// 1. 创建配置文件
Configuration conf = new Configuration();
// 2. 判断是否有tool接口
switch (args[0]){
case "wordcount":
tool = new WordCount();
break;
default:
throw new RuntimeException(" No such tool: "+ args[0] );
}
// 3. 用Tool执行程序
// Arrays.copyOfRange 将老数组的元素放到新数组里面
// 相当于是拷贝从索引为1的参数到最后的参数
int run = ToolRunner.run(conf, tool, Arrays.copyOfRange(args, 1, args.length));
System.exit(run);
}
}
然后执行:
[atguigu@hadoop102 hadoop-3.1.3]$ yarn jar YarnDemo.jar com.atguigu.yarn.WordCountDriver wordcount /input /output
注意此时提交的3个参数,第一个用于生成特定的Tool,第二个和第三个为输入输出目录。此时如果我们希望加入设置参数,可以在wordcount后面添加参数,例如:
[atguigu@hadoop102 hadoop-3.1.3]$ yarn jar YarnDemo.jar com.atguigu.yarn.WordCountDriver wordcount -Dmapreduce.job.queuename=root.test /input /output1
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】