Linux性能优化--性能追踪3:系统级迟缓(prelink)
12.0 概述
本章包含的例子说明了如何用Linux性能工具寻找并修复影响整个系统而不是某个应用程序的性能问题。阅读本章后,你将能够:
- 追踪是哪一个进程导致了系统速度的降低。
- 用strace调查一个不受CPU限制的进程的性能表现。
- 用strace调查一个应用程序是如何与Linux内核进行交互的。
- 提交描述性能问题的bug报告,以便创作者或维护者有足够的信息修改该问题。
12.1调查系统级迟缓
本章我们调查系统级迟缓。首先会发现系统行为逐渐变慢,我们将用Linux性能工具找到确切的原因。这种类型的问题经常发生。作为一个用户或系统管理员,有时你可能会注意到Linux机器变得缓慢,或者需要很长时间才能完成任务。能够弄清楚机器变缓的原因是很有价值的。
12.2确定问题
和前面一样,第一个步骤是准确找出我们要调查的问题。本例中,在使用Fedora Core 2桌面系统的条件下,我们将调查发生的周期性迟缓问题。通常情况下,桌面系统性能良好,但偶尔磁盘会开始不停地读盘,其结果就是菜单和应用程序打开的时间非常长。过一会儿,磁盘研磨消退,而桌面系统行为又恢复正常。本章我们将弄清楚究竟是什么导致了这个问题,以及其发生的原因。
这个问题的类型与前两章的问题都不一样,因为一开始我们完全不知道系统的哪部分引发了问题。而在调查GIMP和nautilus的性能时,我们是知道应由哪个应用程序对问题负责的。在这种情况下,我们只有一个表现不佳的系统,理论上来说,性能问题可能存在于系统的任何部分。这种情况也是常见的。当遇到它时,重要的是用性能工具去实际追踪问题的原因,而不是仅仅去猜测原因并尝试解决方案。
12.3找到基线/设置目标
还是和前面一样,第一步是确定问题的当前状态。
不过,对本例来说,这一点不容易做到。我们不知道问题什么时候发生或者它会持续多长时间,因此在没有进一步调查前,我们无法真正地设置基线。至于说到目标,理想状态下,我们希望问题完全消失,但是导致问题出现的可能是重要的OS功能,因此,可能无法完全消除它。
首先,针对问题为什么会出现我们需要多做一点调查,以便找到一个合理的基线。第一步是在迟缓发生时运行top。这会给我们提供一个可能导致问题的进程列表,或者甚至也可能直指内核自身。
在这种情况下,如清单12.1所示,运行top并要求它只显示非空闲进程(top运行时按<>)。
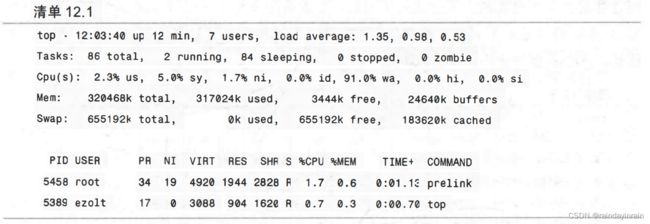
清单12.1中的top输出有几个有意思的特性。第一,我们注意到没有进程占用CPU,两个非空闲任务使用的CPU时间都不到2%。第二,系统花费了91%的时间等待I/O的发生。第三,系统没有使用任何交换空间,因此磨盘不是由交换导致的。最后,有一个未知进程prelink在问题发生时正在运行。由于不清楚这个prelink命令是什么,因此我们先记住应用的名字,之后再调查它。
我们的下一步是运行vmstat,看看系统做了什么。清单12.2给出了vmstat的结果,并确认了我们在top中看到的。也就是,大约90%的系统时间用于等待I/O。该清单还告诉我们磁盘子系统读数据的速度大概是1000块/秒。这个磁盘I/O量相当大。

现在我们知道磁盘被频繁使用,内核花费了很多时间等待I/O和未知应用程序prelink 的运行,我们可以开始弄清楚系统究竟在干嘛。
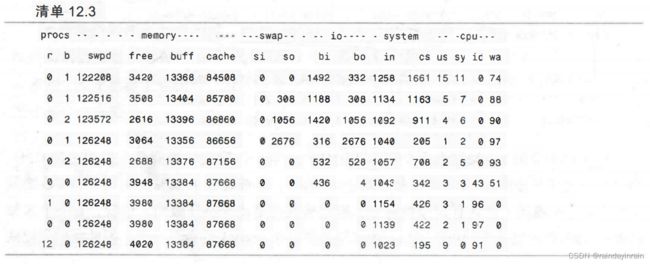
我们不能确认prelink是导致问题的原因,但是我们怀疑它是。明确prelink是否引起磁盘I/O的最简单方法就是“杀死”prelink进程,看看磁盘的使用是不是消失了。(这在生产用计算机上是不可能的,不过我们使用的是个人桌面系统,所以可以快一点儿,不那么严格。)清单12.3显示了vmstat的输出,在其中一半的地方,我们终止了prelink进程。如你所见,prelink被终止后,块读取降为零。
由于prelink看着像是事由应用程序,现在可以开始调查它到底是什么,以及它为什么运行。清单12.4请求rpm告诉我们哪些文件是prelink构成包的组成部分。

首先,我们注意到prelink包有一个日常运行的作业cron。这解释了为什么性能问题的发生是周期性的。其次,我们注意到prelink包含了描述其功能的手册页和文档。手册页将prelink描述为可以预链接可执行文件与库的应用程序,以此减少它们的启动时间。(有点讽刺意味的是,用于提高性能的应用程序正在拉低系统的速度。)prelink有两种运行模式。第一种模式使得所有指定的可执行文件和库都预链接,即使之前已经完成预链接了。(用–force或-f选项指定)。第二种是快速模式,prelink只需查看库与可执行文件的mtime与ctime,看看从上次预链接后是否发生了变化。(用–quick或-q选项指定。)通常,prelink会把已预链接的可执行文件的所有mtime和ctime写入它自己的缓存。然后在快速模式中使用这些信息,以避免对已经预链接过的可执行文件再执行预链接。
检查prelink包中的cron条目显示,默认情况下,Fedora系统同时使用了prelink的两种模式。每隔14天用完整模式调用prelink。而在此期间的每一天,prelink运行于快速模式。
对完整模式和快速模式下的prelink进行计时可以告诉我们最糟糕的情况有多慢(全预链接),以及使用快速模式后性能提升了多少。对prelink计时要小心,因为不同的运行可能会产生完全不同的时间。如果运行的应用程序使用了大量的磁盘I/O,就必须让它多运行几次以便获得对其基准性能的精确指示。磁盘密集型应用程序第一次运行时,许多数据从它的I/O加载到缓存。程序第二次运行时,其性能就会好很多,因为要使用的数据已经在缓存中了,不再需要从磁盘读取。如果用第一次运行作为基线,你会被误导,以为调整后性能就提升了,但其实提升的真正原因是预热了缓存。只有多运行应用程序几次,你才可以预热好缓存,获得准确的基线。清单12.5显示了运行多次后,两种模式下prelink 的结果。

清单12.5中首先要注意的事实是快速模式与完整模式相比,并没有都快得那么多。这点值得怀疑,需要更多的调查。第二点事实强调了top的报告。prelink只占用了一点CPU 时间,其余的全都用来等待磁盘I/O。
现在我们必须选择一个合理的目标。安装在prelink包中的PDF文件描述了预链接的过程。它也说明了完整模式需要花费几分钟,而快速模式需要花费几秒钟。作为目标,让我们试着把快速模式的时间减少到一分钟之内。即使我们可以优化快速模式,每隔14天仍然会遇到明显的磨盘,但是日常运行会有更多的改善。
12.4为性能追踪配置应用程序
调查的下一步是为性能追踪配置应用程序。prelink是一个小而独立的应用程序。事实上,它甚至不使用任何共享库。(它是静态链接的。)不过比较好的做法是,用全部的符号对其进行重编译,这样需要的时候就可以在调试器(gdb)中查看它。同样,这个工具用configure命令产生生成文件。我们必须下载源代码到prelink,并用符号对它重新编译。我们可以从Red Hat再次下载prelink的源rpm。源代码被安装在/usr/src/redhat/SOURCES 下。一旦解压了prelink的源代码后,就可以如清单12.6所示对其进行编译。

12.5安装和配置性能工具
追踪的下一步是安装性能工具。本例中,无论是ltrace还是oprofile都派不上用场。oprofile用于剖析使用了大量CPU时间的应用程序,而prelink在运行时只使用了3%的CPU时间,所以oprofile对我们没有帮助。而prelink二进制文件是静态链接的,且不使用任何共享库,所以1trace也帮不上我们。不过,系统调用追踪器strace可能会有帮助,因此我们需要安装它。
12.6运行应用程序和性能工具
现在,我们终于可以开始分析prelink在不同模式下的性能特征了。正如你刚才看到的,prelink没有花很多时间使用CPU,相反,它把所有的时间都花在磁盘I/O上了。prelink必须调用内核进行磁盘I/O,因此我们用性能工具strace应该能追踪它的执行。prelink的快速模式没有表现得比标准完整运行模式快很多,所以我们用strace比较这两个运行,看看是否有任何可疑行为出现。
首先,我们要求strace追踪较慢的完整运行prelink。该运行创建了初始缓存,它将在prelink运行于快速模式时使用。起初,我们让strace显示prelink的系统调用汇总,看看其中的每一个要花多长时间完成。实现该操作的命令如清单12.7所示。
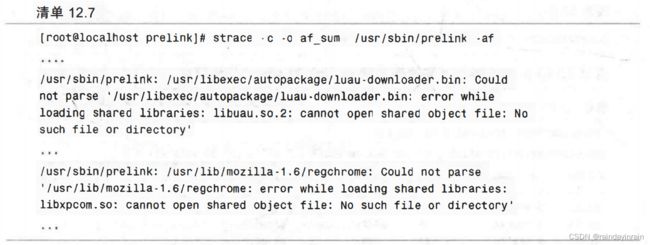
清单12.7还是prelink输出的一个样本。在尝试预链接一些系统可执行文件和库时,prelink显得有些吃力。这个信息在后面会变得很有价值,所以要记住它。
清单12.8显示了由清单12.7中的strace命令生成的输出汇总文件。

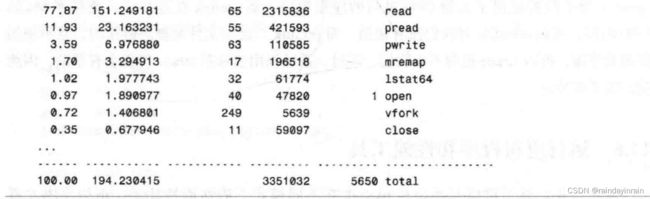
如同清单12.8所示,相当多的时间花在了系统调用read上。这是免不了的,prelink需要找出哪些共享库被链接到了应用程序,这就要把部分可执行文件读入并进行分析。prelink 文档表明,当生成应用程序所需库的列表时,该程序实际上是由动态加载器用特殊模式启动的,之后用通道从可执行文件中读取信息。这就是为什么在分析中pread也很高的原因。与之相反,我们希望快速版本中这样的调用会很少。
要查看快速版本的分析有何不同,我们在prelink的快速模式下运行同样的strace命令。实现该操作的strace命令如清单12.9所示。

清单12.10显示了运行于快速模式的prelink的strace分析信息。

和预期的一样,清单12.10表明快速模式执行了大量的lstat64系统调用。这些系统调用返回每个可执行文件的mtime和ctime。prelink在其缓存中查找,并把保存的mtime和ctime与可执行文件当前的mtime和ctime进行比较。如果可执行文件发生了变化,就对其启动prelink;如果没有变化,则继续下一个可执行文件。实际上prelink大量调用lstat64是个好现象,这就表示prelink的缓存正在工作。不过,prelink仍然大量调用read就不太好了。缓存应该记住已预链接的可执行文件,但不应试图分析它们。我们必须弄明白为什么prelink在尝试分析它们。最简单的方法就是以正常模式运行strace。strace将显示prelink 发起的全部系统调用,并有希望澄清哪些文件被读取,以及解释为什么read被调用得如此频繁。清单12.11显示的是strace对快速prelink使用的命令。

strace的输出是一个14MB的文本文件aq_run。浏览后发现prelink用lstat64检查了许多库和可执行文件。但是,它也揭示了使用read()的几种不同情况。如清单12.12所示,首先prelink读取一个shell脚本。由于shell脚本不是二进制ELF文件,因此它不能被预链接。
这些shell脚本从最初的完整系统prelink开始运行起就没有改变过,所以如果prelink 的缓存能记录该文件不能被预链接的事实就好了。如果ctime和mtime不变,prelink甚至都不会去尝试读取它们。(如果是上一个完整预链接中的shell脚本,且我们还没有碰过,它还是不能预链接。)

其次,在清单12.13中,我们观察到prelink试图操作一个静态链接的应用程序。该应用程序不依赖于任何共享库,因此试图对它进行预链接是没有意义的。prelink的初始运行应该抓住一个事实,即这个应用程序不能被预链接,并将该信息保存到prelink的缓存中。在快速模式下,甚至不应该去尝试预链接这个二进制文件。

最后,在清单12.14中,我们看到prelink在读取一个二进制文件,该文件在最初的完整系统运行时存在预链接故障。在初始prelink输出中,我们看到了关于这个二进制文件的错误。当开始读取该文件时,它会捕捉其他库,并操作其中的每一个库及其依赖项。这会触发大量的读取。


对这种情况进行优化有些复杂。因为该二进制文件不是真正的问题(而是它链接的库libxpcom.so),我们不能只是在缓存中将该可执行文件标记为坏。但是,如果我们将错误库的名称libxpcom.so与失败的可执行文件一起保存,它可能会检查该二进制文件与库的时间,只有当其中的一个发生变化,才会尝试再次预链接。
12.7模拟解决方案
strace揭示的信息显示,prelink花了大量的时间试图打开并分析它可能无法预链接的二进制文件。测试缓存不可预链接的二进制文件是否能改善prelink的性能的最好方法是修改prelink,将所有这些不可预链接的二进制文件都添加到prelink的初始缓存中。可惜的是,添加代码来缓存这些“不可预链接的”二进制文件会是一个复杂的过程,其中涉及大量的有关prelink应用程序的内部知识。更简单的方法是模拟缓存,将所有的不可预链接的二进制文件替换为已知的可预链接的二进制文件。这会导致运行快速模式时忽略之前全部的不可预链接二进制文件。若我们有一个工作缓存,这正是会发生的,因此,如果prelink能够缓存并忽略不可预链接的二进制文件,可以用它来评估我们将看到的性能提升。
开始实验,我们把/usr/bin/中的所有文件都复制到sandbox目录下,并在这个目录上运行prelink。这个目录包含了正常二进制文件、shell脚本和其他不能被预链接的库。然后在sandbox目录上运行prelink,并告诉它创建一个新缓存,而不是用系统缓存。如清单12.15 所示。

接着,在清单12.16中,我们对快速模式的prelink运行了多久进行计时。需要多次运行,直到给出的结果达到一致。(第一次运行是为随后的每一次运行进行缓存热身。)清单12.16中的基线时间为0.983秒。为了显示我们的优化(改善缓存)调查是值得的,必须击败这个时间。

然后,在清单12.17中,我们在这个prelink命令上运行strace,记录prelink在sandbox目录中打开了哪些文件。

接着我们创建一个新目录sandbox2,我们再次将/usr/bin/中的所有二进制文件都复制到这个目录下。但是,我们用一个已知的好的、能被预链接的二进制文件覆盖了在之前strace输出中prelink“打开的”所有文件。我们把这个文件复制到全部的有问题的二进制文件,而不仅仅是删除它们,所以两个sandbox所含的文件数相同。建立第二个sandbox后,我们用清单12.18中的命令在这个新目录上运行完整版prelink。

最后,对快速模式的运行计时,并将其与我们的基线进行比较。
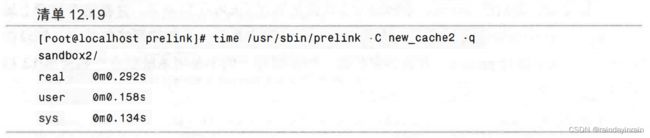
同样的,这也需要运行多次,第一次运行也是缓存热身。清单12.19中,我们可以看到我们所做的,事实上,能看到性能的提升。执行prelink的时间从约0.98秒下降到约0.29秒。
接着,我们比较两次不同运行的strace输出,确认进行读取的次数,实际上,这个次数减少了。清单12.20显示了sandbox的strace汇总信息,其中包含了prelink不能链接的二进制文件。

清单12.21显示了sandbox的strace汇总信息,其中prelink可以链接所有的二进制文件。
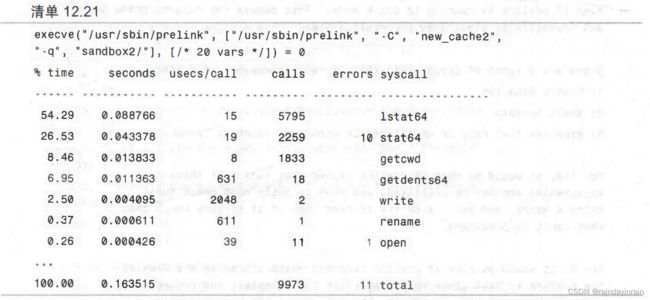
如同你从清单12.20和清单12.21的不同中发现的一样,我们已经显著减少了目录中读取的次数。同时,我们还已经大大减少了预链接该目录所需的时间。缓存和回避不可预链接的可执行文件看起来是一种有前途的优化方法。
12.8 报告问题
我们已经发现了问题,并在系统软件相当低的层次上找到了可能的解决方案,因此,与作者一起解决这个问题是一个好主意。我们至少要提交一个bug报告以便作者知道这个问题的存在。提交用于发现问题的测试也有助于作者重现问题并增加修复问题的希望。本例中,我们将向Red Hat的bugzilla(bugzilla.redhat.com)追踪系统添加一个bug报告。(大多数其他发行版也有相似的bug追踪系统。)我们的bug报告描述了我们遇到的问题以及发现的可能的解决方案。
在bugzilla中,我们首先搜索prelink的bug报告,看看是否已经有其他人提交了关于该问题的报告。本例中,没有人提交相关报告,因此我们输入如清单12.22所示的bug报告,等待作者或维护者的回复,或者问题修复。



即便作者或维护者从未回复,把问题输入到bug追踪数据库仍旧是个好主意。问题及其可能的解决方案将被记录下来,某些热心的程序员也许会继续探索并修复该问题。
12.9测试解决方案
由于我们还没有解决prelink代码中的问题,而是提交了bug报告,因此我们不能立即以原始基线为参照测试被修复的prelink时间。不过,如果作者或维护者能够实现提交的变化,或者甚至是找到了更好的方法进行优化,我们将能在更新版本出现时检查其性能。
12.10本章小结
本章中,我们从一个表现不佳的系统开始,用性能工具找出哪个子系统被过度使用(如vmstat所示的磁盘子系统),以及哪个组件导致了问题(prelink)。接着调查prelink应用程序确定了它为什么有这么多的磁盘I/O(用strace)。我们在prelink的文档中发现缓存模式可以大大减少磁盘I/O。研究了缓存模式的性能之后,我们发现它消除的磁盘I/O并不如预期那样多,其原因是它试图对不能预链接的文件进行预链接。之后,我们模拟了一个缓存,避免对不可预链接的文件尝试进行预链接,以此证明它明显减少了磁盘I/O的数量以及快速模式下prelink的运行时间。最后,我们向prelink的作者提交了bug报告,希望该作者能意识到问题并修复它。本章是Linux性能追踪的最后一章。
在下一章,也就是本书最后一章,我们将从更高层次来看看Linux的性能和性能工具。我们将回顾本书介绍的方法和工具,并考虑一些已成熟并可改进的Linux性能工具领域。