七大排序的顶级理解(近万字详解)
目录
1. 排序的概念及引用
2.常见的排序算法
2.1直接插入排序
2.2希尔排序( 缩小增量排序 )
2.3选择排序
2.4堆排序
2.5冒泡排序
2.6快速排序
2.6.1Hoare版
2.6.2挖坑法
2.6.3前后指针
2.7快速排序优化
2.7.1递归优化
2.7.2非递归实现快速排序
2.8归并排序
2.8排序算法复杂度及稳定性分析
3.小练一手(选择题 )
1. 排序的概念及引用

2.常见的排序算法
全文排序全为从小到大

2.1直接插入排序




public static void instersort(int[] arr){
for (int i = 1; i =0 ; j--) {
if(arr[j]>tmp){
arr[j+1]=arr[j];
}else{
break;
}
}
arr[j+1]=tmp;
}
} 1. 元素集合越接近有序,直接插入排序算法的时间效率越高2. 时间复杂度: O(N^2)3. 空间复杂度: O(1) ,它是一种稳定的排序算法4. 稳定性: 稳定
2.2希尔排序( 缩小增量排序 )
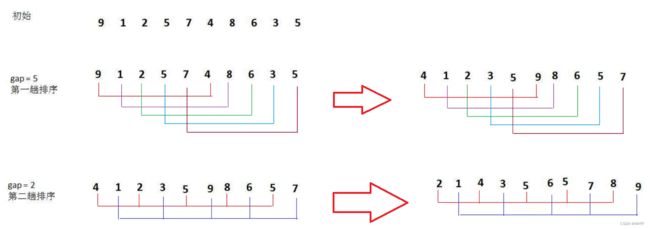

1. 希尔排序是对直接插入排序的优化。2. 当 gap > 1 时都是预排序,目的是让数组更接近于有序。当 gap == 1 时,数组已经接近有序的了,这样就会很 快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。3. 希尔排序的时间复杂度不好计算,因为 gap 的取值方法很多,导致很难去计算,因此在好些书中给出的希尔排 序的时间复杂度都不固定。
《数据结构-用面向对象方法与C++描述》--- 殷人昆

我们gap的取值方法就以此法为例:
代码:
public static void sellsort(int[]arr){
int gop=arr.length;
while(gop>1){
gop/=2;
sell(arr,gop);
}
}
public static void sell(int[]arr,int gap){
for (int i = gap; i =0 ; j-=gap) {
if(arr[j]>tmp){
arr[j+gap]=arr[j];
}else{
break;
}
}
arr[j+gap]=tmp;
}
} 2.3选择排序
在元素集合 array[i]--array[n-1] 中选择关键码最大 ( 小 ) 的数据元素若它不是这组元素中的最后一个 ( 第一个 ) 元素,则将它与这组元素中的最后一个(第一个)元素交换在剩余的 array[i]--array[n-2] ( array[i+1]--array[n-1] )集合中,重复上述步骤,直到集合剩余 1 个元素
步骤演示:

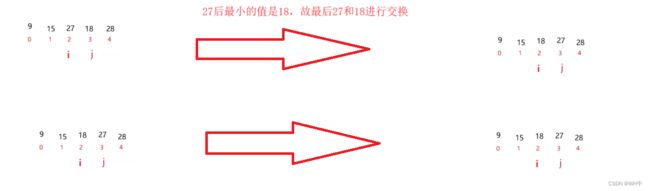
动态图展示:
代码:
public static void selecisort(int[]arr){
for (int i = 0; i < arr.length - 1; i++) {
int min=arr[i];
for (int j = i+1; j < arr.length; j++) {
if(arr[j]选择排序的特性总结
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用2. 时间复杂度: O(N^2)3. 空间复杂度: O(1)4. 稳定性:不稳定
扩展:双向选择排序
思路及过程:

代码:
public static void swap(int[]arr,int x,int y){
int tmp=arr[x];
arr[x]=arr[y];
arr[y]=tmp;
}
public static void selecisort2(int[]arr){
int left=0;
int right=arr.length-1;
while(leftarr[i]){
min=i;
}
if(arr[max]
2.4堆排序
1. 建堆升序:建大堆降序:建小堆2. 利用堆删除思想来进行排序建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
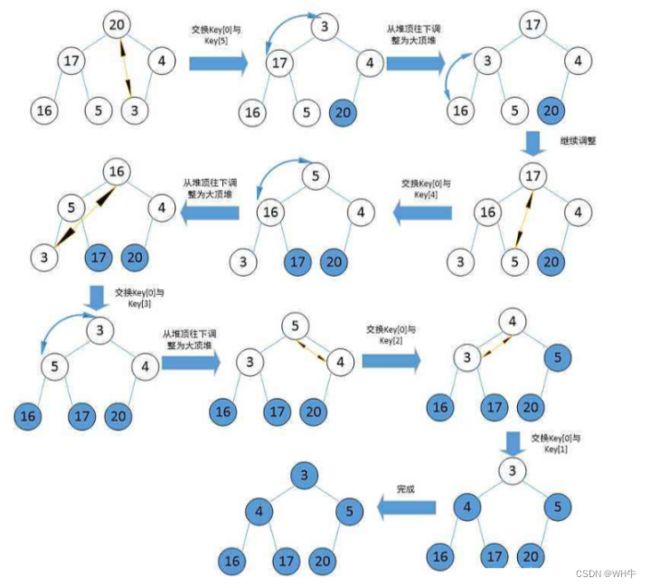
代码:
private void createbigheap(int[]arr){
for (int i =(arr.length-1-1)/2 ; i>=0 ; i--) {
shiftdown(arr,i,arr.length);
}
}
private void shiftdown(int[] arr,int parent,int len){
int child=2*parent+1;
while(childarr[child]){
child++;
}
if(arr[child]>arr[parent]){
swap(arr,child,parent);
parent=child;
child=2*parent+1;
}else {
break;
}
}
}
public void heapSort(int[]arr){
createbigheap(arr);
int end=arr.length-1;
while(end>0){
swap(arr,0,end);
shiftdown(arr,0,end);
end--;
}
} 特性总结
1. 堆排序使用堆来选数,效率就高了很多。2. 时间复杂度: O(N*logN)3. 空间复杂度: O(1)4. 稳定性:不稳定
2.5冒泡排序
冒泡排序是一种简单的排序算法,它也是一种稳定排序算法。 其实现原理是重复扫描待排序序列,并比较每一对相邻的元素,当该对元素顺序不正确时进行交换。 一直重复这个过程,直到没有任何两个相邻元素可以交换,就表明完成了排序。
动态图展示:
代码:
public void bubblesort(int[]arr){
for (int i = 0; i < arr.length - 1; i++) {
boolean flag=false;
for (int j = 0; j < arr.length - 1 - i; j++) {
if(arr[j]>arr[j+1]){
swap(arr,j,j+1);
flag=true;
}
}
if(flag!=true){
break;
}
}
}1. 冒泡排序是一种非常容易理解的排序2. 时间复杂度: O(N^2)3. 空间复杂度: O(1)4. 稳定性:稳定
2.6快速排序
2.6.1Hoare版
主要思考方向:分析如何按照基准值来对区间中数据进行划分的方式
动态图展示:

代码:
public void quicksort(int[] arr) {
int left = 0;
int right = arr.length - 1;
quick(arr, left, right);
}
public void quick(int[] arr, int left, int right) {
if (left >= right) {
return;
}
int tmp = partition(arr, left, right);
quick(arr, left, tmp - 1);
quick(arr, tmp + 1, right);
}
public int partition(int[] arr, int left, int right) {
int tmp = arr[left];
int i = left;
while (left < right) {
while (left < right && arr[right] >= tmp) {
right--;
}
while (left < right && arr[left] <=tmp) {
left++;
}
swap(arr, left, right);
}
swap(arr, left, i);
return left;
}
public static void swap(int[] arr, int x, int y) {
int tmp = arr[x];
arr[x] = arr[y];
arr[y] = tmp;
}2.6.2挖坑法
步骤:
我们需要在key处挖一个坑(把6拿出来存在一个tmp变量里),形成一个坑位,然后R向左找比6小的放进坑里,就又形成了一个新的坑,然后L向右找,找到比6大的,放进新的坑
动图演绎:
基准部分代码:
public int partition2(int[] arr, int left, int right){
int tmp=arr[left];
while(left= tmp) {
right--;
}
arr[left]=arr[right];
while (left < right && arr[left] <=tmp) {
left++;
}
arr[right]=arr[left];
}
arr[left]=tmp;
return left;
} 2.6.3前后指针
需要两个指针,一个在前一个在后,分别用cur表示前指针,prev表示后指针,初始时,我们规定cur在prev的后一个位置,这里我们还是选择第一个数为基准值
动图演绎:
步骤小结:
(1)prev每次都需要指向从左到它本身之间最后一个小于基准值的数
(2)如果cur的值大于基准值,这时只让cur++
(3)如果cur指向的位置小于基准值
(4)这时我们让prev++
(5)判断prev++后是否与cur的位置相等
(6)若不相等,则交换cur和prev的值
(7)直到cur > R后,我们再交换prev和key,这样基准值的位置也就确定了
基准部分代码:
public int partition3(int[] arr, int left, int right){
int prev=left;
int cur=left+1;
while(cur<=right){
if(arr[cur]细节思考:

2.7快速排序优化
2.7.1递归优化
优化思路:减少递归次数
(1)每次递归的时候,数据都是再慢慢变成有序的,当数据量少且趋于有序的时候,我们可以直接使用插入排序进行优化
(2)三数取中法
选取数组的第一个数、中间的数、和最后一个数,进行比较,三数中大小排第二的数作为每次的基数
代码:
public void quicksort2(int[] arr) {
int left = 0;
int right = arr.length - 1;
quick2(arr, left, right);
}
public void quick2(int[] arr, int left, int right) {
if (left >= right) {
return;
}
if(right-left+1<=10){
}
int mid=midThree(arr,left,right);
swap(arr,mid,left);
int tmp = partition(arr, left, right);
quick(arr, left, tmp - 1);
quick(arr, tmp + 1, right);
}
private int midThree(int[] arr,int left,int right) {
int mid=(left+right)/2;
if(arr[left]arr[right]) {
return right;
} else{
return mid;
}
}else{
if(arr[mid]>arr[left]){
return left;
} else if (arr[mid]= left; j--) {
if (arr[j] > tmp) {
arr[j + 1] = arr[j];
} else {
break;
}
}
arr[j + 1] = tmp;
}
}
public int partition(int[] arr, int left, int right) {
int tmp = arr[left];
int i = left;
while (left < right) {
while (left < right && arr[right] >= tmp) {
right--;
}
while (left < right && arr[left] <=tmp) {
left++;
}
swap(arr, left, right);
}
swap(arr, left, i);
return left;
}
public static void swap(int[] arr, int x, int y) {
int tmp = arr[x];
arr[x] = arr[y];
arr[y] = tmp;
} 2.7.2非递归实现快速排序
思路:
我们现在创建一个栈,把剩余区间的left、right位置的下标分别放入栈中,如图是已经找到一个基准6的情况

然后弹出栈顶一个元素9给right,再弹出一个栈顶元素6给left,根据新的L和H找到新的基准,再重复上面的操作
代码:
public void quicksort3(int[] arr) {
Stack stack = new Stack<>();
int left = 0;
int right = arr.length - 1;
int pivot=partition(arr,left,right);
if(pivot>left+1){
stack.push(left);
stack.push(pivot-1);
}
if(pivotleft+1){
stack.push(left);
stack.push(pivot-1);
}
if(pivot 1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫 快速 排序2. 时间复杂度: O(N*logN)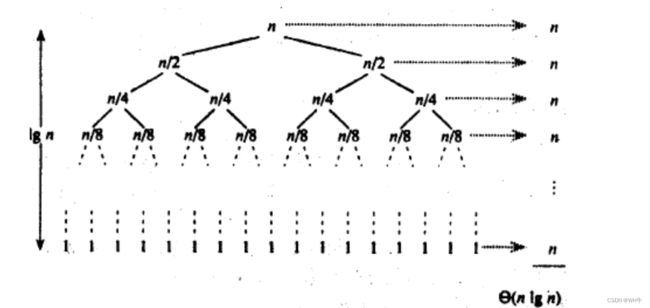 3. 空间复杂度: O(logN)4. 稳定性:不稳定
3. 空间复杂度: O(logN)4. 稳定性:不稳定
2.8归并排序
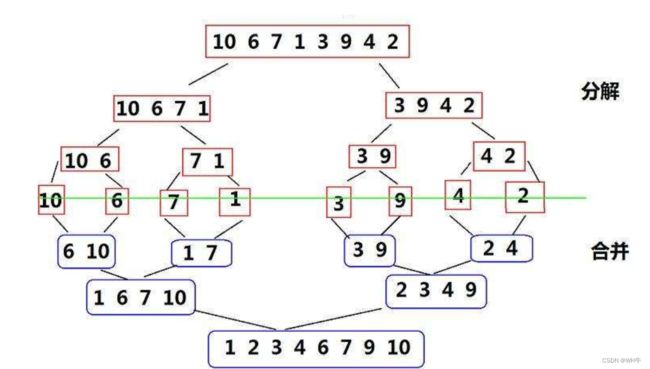
动图演绎: 
递归的代码:
public void mergeSort1(int[] array) {
mergeSortFunc(array, 0, array.length - 1);
}
private void mergeSortFunc(int[] array, int left, int right) {
if (left >= right) {
return;
}
int mid = (left + right) / 2;
mergeSortFunc(array, left, mid);
mergeSortFunc(array, mid + 1, right);
merge(array, left, right, mid);
}
private void merge(int[] array, int left, int mid, int right) {
int s1 = left;
int e1 = mid;
int s2 = mid + 1;
int e2 = right;
int[] arr = new int[right - left + 1];
int k=0;
while(s1<=e1&&s2<=e2){
if(array[s1]>array[s2]){
arr[k++]=array[s2++];
}else{
arr[k++]=array[s1++];
}
}
while(s1<=e1)
{
arr[k++]=array[s1++];
}
while(s2<=e2)
{
arr[k++]=array[s2++];
}
for (int i = 0; i 非递归的代码:
private static void merge(int[] array, int left, int mid, int right) {
int s1 = left;
int e1 = mid;
int s2 = mid + 1;
int e2 = right;
int[] arr = new int[right - left + 1];
int k=0;
while(s1<=e1&&s2<=e2){
if(array[s1]>array[s2]){
arr[k++]=array[s2++];
}else{
arr[k++]=array[s1++];
}
}
while(s1<=e1)
{
arr[k++]=array[s1++];
}
while(s2<=e2)
{
arr[k++]=array[s2++];
}
for (int i = 0; i = array.length) {
mid = array.length-1;
}
int right = mid+gap;//有可能会越界
if(right>= array.length) {
right = array.length-1;
}
merge(array,left,mid ,right);
}
//当前为2组有序 下次变成4组有序
gap *= 2;
}
} 1. 归并的缺点在于需要 O(N) 的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。2. 时间复杂度: O(N*logN)3. 空间复杂度: O(N)4. 稳定性:稳定
对于空间复杂度:O(N)的进一步介绍:
递归代码的空间复杂度并不能像时间复杂度那样累加。尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个元素的大小,所以归并排序的空间复杂度是 O(n)。
外部排序:排序过程需要在磁盘等外部存储进行的排序 前提:内存只有 1G ,需要排序的数据有 100G 因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序1. 先把文件切分成 200 份,每个 512 M2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以3. 进行 2 路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
2.8排序算法复杂度及稳定性分析
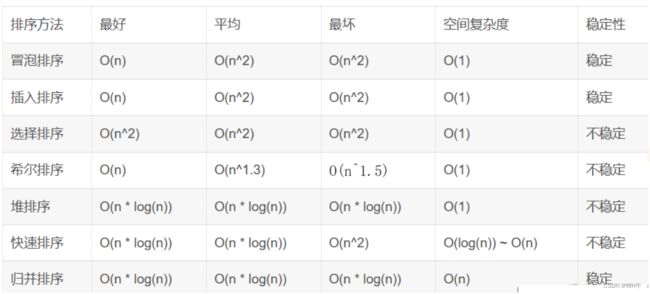
3.小练一手(选择题 )
【参考答案】A

【参考答案】D
【参考答案】B
【参考答案】D堆排序空间复杂度的为 O(1)
【参考答案】A
以上为我个人的小分享,如有问题,欢迎讨论!!!
都看到这了,不如关注一下,给个免费的赞 
