Flink-窗口概念以及窗口API使用
6.3 窗口
6.3.1 窗口的概念
- 存储桶

水位线只是用来推动窗口的关闭,但不决定数据分到哪个窗口
6.3.2 窗口的分类
- 按照驱动类型分类
- 时间窗口
- 计数窗口

- 按照窗口分配数据的规则分类
- 滚动窗口:参数为窗口的大小

- 滑动窗口:参数为窗口大小,以及滑动步长
数据会重叠
运用场景,每个5分钟统计过去一小时的所有的活跃用户

- 会话窗口:参数是会话的超时时间
- 全局窗口
6.3.3 窗口API的概览
- 按键分区窗口
经过按键分区后(keyby),数据流会按照key被分为多条逻辑流,就是keyStream
stream.keyBy(...)
.window(...)
- 非按键分区
stream直接开窗,所有数据收集到窗口中,也就是并行度变成1,官方不推荐
stream.windowAll(...)
- 窗口API的调用
stream.keyBy(<key selector>)
.window(<window assigner>)//窗口分配器:要分配什么窗口
.aggregate(<window function>)//窗口函数:具体计算操作
6.3.4 窗口分配器


直接调用window()方法传入WindowAssigner,返回WindowedStream


WindowAssigner是一个抽象类,并且有assignWindows()方法,但是flink有抽象类的实现类,直接用实现类就好,不用自己整一个
- 滚动窗口
![]()
主要是根据窗口分类而设置的实现类,细分下面还有时间语义
例如图中的TumblingEventTimeWindows(事件时间)或者TumblingProcessingTimeWindows(处理时间)


TumblingEventTimeWindows的静态方法of需要传入一个Time大小,或者Time大小以及Time的偏移量,偏移量一般用在时差里面(伦敦时间和东八区时间)
![]()
Time这个类是flink下的,选包别选错,Time下就有很多方法了,例如.hour取小时
![]()
所以最后滚动事件时间窗口这么写
- 滑动窗口

其他的窗口还有SlidingEventTimeWindows滑动窗口,这个就有两个参数了,一个窗口大小,一个滑动步长,当然也有三个参数,跟滑动窗口一样可以多一个offset偏移量,也是用在计算时差(伦敦时间和东八区时间)
- 会话窗口
![]()
EventTimeSessionWindows是事件时间会话窗口,参数就是会话的时间了
- 计数窗口


![]()
countWindow是计数窗口,传一个参数表示滚动窗口,传两个参数表示滑动窗口,return的是全局窗口的,以及移除器和触发器
6.3.5 窗口函数
- 整体介绍


- 一般数据源获取到后做一些map等基本操作,返回的还是DataStream
- 如果keyby了,就变成了keyedStream,再做聚合操作,返回的DataStream
- 或者keyby后开窗,经过窗口分配器后,得到WindowedStream,再进行窗口函数,得到返回DataStream
- 增量聚合函数
流处理思路做批处理,依旧是来一个处理一个,等到时间点,输出计算好的数据
- 归约函数ReduceFunction

![]()
参数要传入ReduceFunction,和转换算子那一章keyby后用到的聚合函数一样的,同个类,即把集合每一个数据拿出来,然后按照一定的规则不停的规约,最终得到一个唯一规约聚合后的结果
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.map(new MapFunction<Event, Tuple2<String,Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
return Tuple2.of(value.user,1L);
}
})
.keyBy(data->data.f0)
//.countWindow(10,2)//滑动计数窗口
//.window(EventTimeSessionWindows.withGap(Time.seconds(2)))//事件时间会话窗口
//.window(SlidingEventTimeWindows.of(Time.hours(1),Time.minutes(5)))//滑动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))//滚动事件时间窗口
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0,value1.f1+value2.f1);
}
})
.print();
env.execute();
}
}
结果
(Mary,3)
(Bob,3)
(Alice,4)
(Bob,2)
(Alice,4)
(Mary,4)
(Alice,3)
(Bob,5)
(Mary,2)
(Alice,3)
(Bob,5)
(Mary,2)
(Mary,4)
(Alice,3)
(Bob,3)
Process finished with exit code 130
数据源一直产生,会一直不停,每隔十秒会输出一段
- 聚合函数(AggregateFunction)
1)相比于归约函数reduce的特点是,有三个泛型,并且可以更改输出的类型
2)有三个类型,输入类型(In),累加器类型(ACC),输出类型(OUT)
3)重写4个方法createAccumulator() ,add(Event value, Tuple2
案例1
public class WindowAggregateTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.keyBy(data->data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new AggregateFunction<Event, Tuple2<Long,Integer>, String>() {//中间类型:一个是所有类型的和,一个是所有数的个数
@Override
public Tuple2<Long, Integer> createAccumulator() {//创建一个累加器
return Tuple2.of(0L,0);//写初始值
}
@Override
//叠加器,参数是传过来的数值,还有当前的状态,返回的也是当前的状态的类型,这个过程主要涉及状态的改变
public Tuple2<Long, Integer> add(Event value, Tuple2<Long, Integer> accumulator) {
return Tuple2.of(accumulator.f0+value.timestamp,accumulator.f1+1);//前面是叠加规则,后面是个数
}
@Override
//输出结果,返回类型变化,变成String
public String getResult(Tuple2<Long, Integer> accumulator) {
//汇总数/个数得到平均数
Timestamp timestamp = new Timestamp(accumulator.f0 / accumulator.f1);
return timestamp.toString();//转成String输出
}
@Override
//merge合并累加器,一般用于会话窗口
//这边可以实现,也可以不实现,下面是实现的写法
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> a, Tuple2<Long, Integer> b) {
return Tuple2.of(a.f0+b.f0,a.f1+b.f1);//(和,个数)
}
})
.print();
env.execute();
}
}
结果
2022-11-22 22:44:19.803
2022-11-22 22:44:25.389
2022-11-22 22:44:24.522
2022-11-22 22:44:27.921
2022-11-22 22:44:34.588
2022-11-22 22:44:35.089
2022-11-22 22:44:35.293
2022-11-22 22:44:44.558
2022-11-22 22:44:44.349
2022-11-22 22:44:45.701
每隔十秒输出某一用户的访问时间戳平均值,意义不大,主要看的是aggregate一步可以实现求平均值用法
案例2
public class WindowAggregateTest {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.keyBy(data->data.user)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new AggregateFunction<Event, Tuple2<Long,Integer>, String>() {//中间类型:一个是所有类型的和,一个是所有数的个数
@Override
public Tuple2<Long, Integer> createAccumulator() {//创建一个累加器
return Tuple2.of(0L,0);//写初始值
}
@Override
//叠加器,参数是传过来的数值,还有当前的状态,返回的也是当前的状态的类型,这个过程主要涉及状态的改变
public Tuple2<Long, Integer> add(Event value, Tuple2<Long, Integer> accumulator) {
return Tuple2.of(accumulator.f0+value.timestamp,accumulator.f1+1);//前面是叠加规则,后面是个数
}
@Override
//输出结果,返回类型变化,变成String
public String getResult(Tuple2<Long, Integer> accumulator) {
//汇总数/个数得到平均数
Timestamp timestamp = new Timestamp(accumulator.f0 / accumulator.f1);
return timestamp.toString();//转成String输出
}
@Override
//merge合并累加器,一般用于会话窗口
//这边可以实现,也可以不实现,下面是实现的写法
public Tuple2<Long, Integer> merge(Tuple2<Long, Integer> a, Tuple2<Long, Integer> b) {
return Tuple2.of(a.f0+b.f0,a.f1+b.f1);//(和,个数)
}
})
.print();
env.execute();
}
}
结果
这边url不对,后续已经改正,但是不影响此次结果查看
- 全窗口函数
- 分析

ProcessWindowFunction是一个抽象类,继承了富函数类AbstractRichFunction,并且拥有4个泛型,并且最后一个泛型W继承了Window,可以选择TimeWindow作为子类传入

可以继承这个类后实现process()方法,参数分别是KEY key, Context context, Iterable elements, Collector out,第一个参数key的类型,第二个是上下文,第三个是输入(迭代器),第四个输出

第二个参数上下文中有很多属性,例如窗口,当前处理时间,当前watermark,以及获取当前的状态还有侧输出流

![]()
![]()
TimeWindow这个类中getStart()和getEnd()用,一般通过上下文调用window返回TimeWindow,然后在调用getStart()和getEnd()用方法,例如Long start = context.window()
- 代码
public class WindowProcessTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
//使用ProcessWindowFunction计算UV
stream.keyBy(data->true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
//实现自定义的ProcessWindowFunction,输出一条统计信息
public static class UvCountByWindow extends ProcessWindowFunction<Event,String,Boolean,TimeWindow>{
@Override
//参数process(KEY key, Context context上下文, Iterable elements, Collector out)
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
//1.用一个HashSet保存user
HashSet<String> userSet = new HashSet<>();
//2.从elements遍历数据,放到set中去重
for (Event event : elements) {
userSet.add(event.user);
}
Integer uv = userSet.size();
//3.结合窗口信息
Long start = context.window().getStart();
Long end = context.window().getEnd();
//4.输出
out.collect("窗口"+new Timestamp(start)+"~"+new Timestamp(end)
+" UV值为:"+uv);
}
}
}
- 结果
窗口2022-11-23 00:00:20.0~2022-11-23 00:00:30.0 UV值为:2
窗口2022-11-23 00:00:30.0~2022-11-23 00:00:40.0 UV值为:3
窗口2022-11-23 00:00:40.0~2022-11-23 00:00:50.0 UV值为:3
- 两种函数结合
- 概述
增量函数看不到窗口信息,全窗口是将数据攒起来后进行批处理(非流处理),因此将两种函数组合,即调用增量函数中aggregate方法,窗口结束将getResult方法结果以参数形式作为element(第三个参数)输出给到全窗口函数的process()方法

- 代码
public class UvCountExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.print();
//使用AggregateFunction和ProcessWindowFunction结合计算UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UvAgg(),new UvCountResult())
.print();
env.execute();
}
//自定义实现AggregateFunction,目的在于增量计算uv值
public static class UvAgg implements AggregateFunction<Event, HashSet<String>,Long>{
@Override
public HashSet<String> createAccumulator() {
return new HashSet<>();
}
@Override
public HashSet<String> add(Event value, HashSet<String> accumulator) {
accumulator.add(value.user);
return accumulator;
}
@Override
public Long getResult(HashSet<String> accumulator) {
return (long)accumulator.size();
}
@Override
public HashSet<String> merge(HashSet<String> a, HashSet<String> b) {
return null;
}
}
//自定义实现ProcessWindowFunction,包装窗口信息输出
public static class UvCountResult extends ProcessWindowFunction<Long,String, Boolean,TimeWindow>{
@Override
public void process(Boolean aBoolean, ProcessWindowFunction<Long, String, Boolean, TimeWindow>.Context context, Iterable<Long> elements, Collector<String> out) throws Exception {
//3.结合窗口信息
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long uv = elements.iterator().next();
//4.输出
out.collect("窗口"+new Timestamp(start)+"~"+new Timestamp(end)
+" UV值为:"+uv);
}
}
}
- 结果
Event{user='Mary', url='./cart', timestamp=2022-11-23 21:02:49.478}
Event{user='Alice', url='./home', timestamp=2022-11-23 21:02:50.496}
窗口2022-11-23 21:02:40.0~2022-11-23 21:02:50.0 UV值为:1
Event{user='Mary', url='./home', timestamp=2022-11-23 21:02:51.504}
Event{user='Alice', url='./prod?id=100', timestamp=2022-11-23 21:02:52.513}
Event{user='Alice', url='./prod?id=100', timestamp=2022-11-23 21:02:53.588}
Event{user='Alice', url='./cart', timestamp=2022-11-23 21:02:54.602}
Event{user='Bob', url='./prod?id=100', timestamp=2022-11-23 21:02:55.615}
Event{user='Mary', url='./prod?id=100', timestamp=2022-11-23 21:02:56.627}
Event{user='Mary', url='./home', timestamp=2022-11-23 21:02:57.627}
Event{user='Mary', url='./prod?id=100', timestamp=2022-11-23 21:02:58.634}
Event{user='Mary', url='./prod?id=100', timestamp=2022-11-23 21:02:59.644}
Event{user='Alice', url='./home', timestamp=2022-11-23 21:03:00.65}
窗口2022-11-23 21:02:50.0~2022-11-23 21:03:00.0 UV值为:3
- 统计热门url案例
- 代码
public class UrlCountViewExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.自定义Source输入
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ZERO)//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.print("input");
//统计每个url的访问量
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UrlViewCountAgg(),new UrlViewCountResult())
.print();
env.execute();
}
//增量聚合,来一条数据就加1
private static class UrlViewCountAgg implements AggregateFunction<Event,Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator+1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
//包装窗口信息,然后输出UrlViewCount
//输入就是增量函数的输出
private static class UrlViewCountResult extends ProcessWindowFunction<Long,UrlViewCount,String, TimeWindow>{
@Override
public void process(String url,Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
//3.结合窗口信息
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long count = elements.iterator().next();
//4.输出
out.collect(new UrlViewCount(url,count,start,end));
}
}
}
- 结果
input> Event{user='Bob', url='./home', timestamp=2022-11-23 22:02:55.388}
input> Event{user='Mary', url='./prod?id=100', timestamp=2022-11-23 22:02:56.409}
input> Event{user='Mary', url='./prod?id=100', timestamp=2022-11-23 22:02:57.411}
input> Event{user='Alice', url='./prod?id=100', timestamp=2022-11-23 22:02:58.418}
input> Event{user='Alice', url='./fav', timestamp=2022-11-23 22:02:59.419}
input> Event{user='Bob', url='./home', timestamp=2022-11-23 22:03:00.42}
UrlViewCount{url='./home', count=1, windowStart=2022-11-23 22:02:50.0, windowEnd=2022-11-22 22:03:00.0}
UrlViewCount{url='./prod?id=100', count=3, windowStart=2022-11-23 22:02:50.0, windowEnd=2022-11-23 22:03:00.0}
最后一条input不算入窗口
6.3.6 其他API
- 触发器(Trigger)
- 用法
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger)
- 分析

Trigger是一个抽象类


CountTrigger是实现类,使用onEventTime()方法返回TriggerResult类,即触发的结果
![]()
TriggerResult是一个枚举类,有CONTINUE(不动),FIRE_AND_PURGE,FIRE(发射到下游),PURGE(把窗口清空关闭)
后面听不懂了,毁灭吧
- 移除器(Evictor)
stream.keyBy(...)
.window(...)
.evictor(new MyEvictor())
- 允许延迟
- 窗口延迟关闭
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
- 测输出流
大招:把迟到的数据放到测输出流
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
- 代码测试
public class LateDataTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.socketTextStream("hadoop2",7777)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fileds = value.split(",");
return new Event(fileds[0].trim(),fileds[1].trim(),Long.valueOf(fileds[2].trim()));
}
})
.assignTimestampsAndWatermarks(WatermarkStrategy
//乱序事件为0,相当于升序
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))//得到WatermarkGenerator
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
stream.print("input");
//定义一个输出标签
//使用匿名类定义测输出流标签定义出来
OutputTag<Event> late = new OutputTag<Event>("late"){};
//统计每个url的访问量
SingleOutputStreamOperator<UrlViewCount> result = stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.allowedLateness(Time.minutes(1))//允许一分钟的延迟
.sideOutputLateData(late)//测输出流
//可以传入两个参数,一个AggregateFunction<,另一个ProcessWindowFunction
.aggregate(new UrlCountViewExample.UrlViewCountAgg(),
new UrlCountViewExample.UrlViewCountResult());
result.print("result");
result.getSideOutput(late).print("late");
env.execute();
}
}
结果

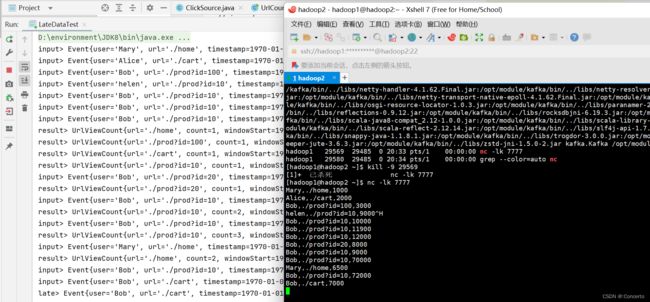
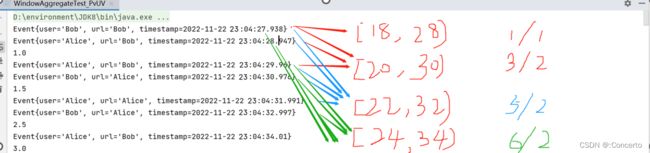
当输入Bob,./prod?id=10,12000的时候,0-10的窗口才会关闭(依据水位线10),并计算前面4条的属于0-10窗口结果,
当再次输入Bob,./prod?id=20,8000,Bob,./prod?id=10,9000,由于设置了allowedLatenes窗口延迟一分钟,因此仍然可以叠加计算并输出结果
即使Bob,./prod?id=10,70000后,关闭的是10-20秒的窗口,如果后面有20-30也会关闭,即使水位线在68秒,继续输入Mary,./home,6500,也会继续叠加计算
只有当输入Bob,./prod?id=10,72000的时候,水位线才到了70,那么窗口时间根据水位线以及延迟的1分钟,即0-10的窗口才是真正关闭掉了
窗口关闭,此时再输入数据Bob,./cart,7000,就会被放到测输出流中