PyTorch 模型性能分析和优化 - 第 6 部分
玩具模型
为了方便我们的讨论,我们使用流行的 timm python 模块(版本 0.9.7)定义了一个简单的基于 Vision Transformer (ViT) 的分类模型。我们将模型的 patch_drop_rate 标志设置为 0.5,这会导致模型在每个训练步骤中随机丢弃一半的补丁。使用 torch.use_definistic_algorithms 函数和 cuBLAS 环境变量 CUBLAS_WORKSPACE_CONFIG 对训练脚本进行编程,以最大限度地减少不确定性。请参阅下面的代码块以获取完整的模型定义:
import torch, time, os
import torch.optim
import torch.profiler
import torch.utils.data
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset
# use the GPU
device = torch.device("cuda:0")
# configure PyTorch to use reproducible algorithms
torch.manual_seed(0)
os.environ[
"CUBLAS_WORKSPACE_CONFIG"
] = ":4096:8"
torch.use_deterministic_algorithms(True)
# define the ViT-backed classification model
model = VisionTransformer(patch_drop_rate=0.5).cuda(device)
# define the loss function
loss_fn = torch.nn.CrossEntropyLoss()
# define the training optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=128,
num_workers=8, pin_memory=True)
t0 = time.perf_counter()
summ = 0
count = 0
model.train()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf')
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
with torch.profiler.record_function('forward'):
outputs = model(inputs)
loss = loss_fn(outputs, label)
optimizer.zero_grad(set_to_none=True)
with torch.profiler.record_function('backward'):
loss.backward()
with torch.profiler.record_function('optimizer_step'):
optimizer.step()
prof.step()
batch_time = time.perf_counter() - t0
if step > 1: # skip first step
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 500:
break
print(f'average step time: {summ/count}')
我们将在 Amazon EC2 g5.2xlarge 实例(包含 NVIDIA A10G GPU 和 8 个 vCPU)上运行实验,并使用官方 AWS PyTorch 2.0 Docker 映像。
初始性能结果
在下图中,我们捕获了 TensorBoard 插件跟踪视图中显示的性能结果:
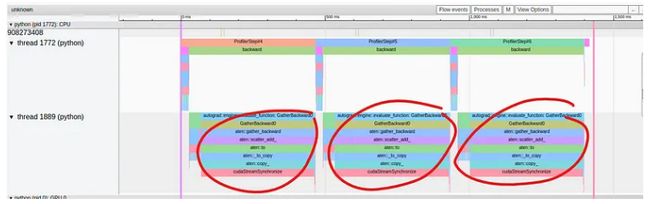
虽然训练步骤的前向传递中的操作在顶部线程中聚集在一起,但在底部线程的向后传递中似乎出现了性能问题。在那里我们看到单个操作 GatherBackward 占据了跟踪的很大一部分。仔细观察,我们可以看到底层操作包括“to”、“copy_”和“cudaStreamSynchronize”。
这时你自然会问:为什么会出现这种情况?我们的模型定义的哪一部分导致了它? GatherBackward 跟踪提示可能涉及 torch.gather 操作,但它来自哪里以及为什么会导致同步事件?
在我们之前的文章中(例如,此处),我们提倡使用带标签的 torch.profiler.record_function 上下文管理器来查明性能问题的根源。这里的问题是性能问题发生在我们无法控制的向后传递中!特别是,我们无法使用上下文管理器将单个操作包装在向后传递中。
理论上,可以通过对跟踪视图的深入分析以及将后向传递中的每个片段与其前向传递中的相应操作进行匹配来识别有问题的模型操作。然而,这不仅非常乏味,而且还需要深入了解模型训练步骤的所有低级操作。
使用 torch.profiler.record_function 标签的优点是它使我们能够轻松地定位模型的有问题的部分。理想情况下,我们希望即使在向后传递中出现性能问题的情况下也能够保留相同的功能。
使用 PyTorch Backward Hooks 进行性能分析
尽管 PyTorch 不允许您包装单独的向后传递操作,但它确实允许您使用其钩子支持来添加和/或附加自定义功能。 PyTorch 支持将钩子注册到 torch.Tensors 和 torch.nn.Modules。尽管我们在本文中提出的技术将依赖于将向后钩子注册到模块,但张量钩子注册可以类似地用于替换或增强基于模块的方法。
在下面的代码块中,我们定义了一个包装函数,它接受一个模块并注册一个 full_backward_hook 和一个 full_backward_pre_hook (尽管实际上一个就足够了)。每个钩子都被编程为使用 torch.profiler.record_function 函数简单地将消息添加到捕获的分析跟踪中。
backward_pre_hook 被编程为打印“之前”消息,backward_hook 被编程为打印“之后”消息。附加可选的详细信息字符串以区分同一模块类型的多个实例。
def backward_hook_wrapper(module, details=None):
# define register_full_backward_pre_hook function
def bwd_pre_hook_print(self, output):
message = f'before backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return output
# define register_full_backward_hook function
def bwd_hook_print(self, input, output):
message = f'after backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return input
# register hooks
module.register_full_backward_pre_hook(bwd_pre_hook_print)
module.register_full_backward_hook(bwd_hook_print)
return module
使用backward_hook_wrapper函数,我们可以开始定位性能问题的根源。我们首先仅包装模型和损失函数,如下面的代码块所示:
model = backward_hook_wrapper(model)
loss_fn = backward_hook_wrapper(loss_fn)
使用 TensorBoard 插件 Trace View 的搜索框,我们可以识别“之前”和“之后”消息的位置,并推断出模型和损失的反向传播的开始和结束位置。这使我们能够得出结论,性能问题发生在模型的向后传递中。下一步是使用 back_hook_wrapper 函数包装 Vision Transformer 的内部模块:
model.patch_embed = backward_hook_wrapper(model.patch_embed)
model.pos_drop = backward_hook_wrapper(model.pos_drop)
model.patch_drop = backward_hook_wrapper(model.patch_drop)
model.norm_pre = backward_hook_wrapper(model.norm_pre)
model.blocks = backward_hook_wrapper(model.blocks)
model.norm = backward_hook_wrapper(model.norm)
model.fc_norm = backward_hook_wrapper(model.fc_norm)
model.head_drop = backward_hook_wrapper(model.head_drop)
在上面的代码块中,我们指定了每个内部模块。包装所有模型第一级模块的另一种方法是迭代其named_children:
for submodule in model.named_children():
submodule = backward_hook_wrapper(submodule)
下面的图像捕获显示在有问题的 GatherBackward 操作之前存在“before back of PatchDropout”消息:

我们的性能分析表明,性能问题的根源是 PathDropout 模块。检查模块的forward函数,我们确实可以看到对torch.gather的调用。
就我们的玩具模型而言,我们只需要进行两次分析迭代即可找到性能问题的根源。在实践中,可能需要对该方法进行额外的迭代。
请注意,PyTorch 包含 torch.nn.modules.module.register_module_full_backward_hook 函数,该函数将在一次调用中将钩子附加到训练步骤中的所有模块。尽管这在简单情况下(例如我们的玩具示例)可能就足够了,但它无法使人区分同一模块类型的不同实例。
现在我们知道了性能问题的根源,我们可以开始尝试修复它。
优化建议:尽可能使用索引而不是收集
现在我们知道问题的根源在于 DropPatches 模块的 torch.gather 操作,我们可以研究长主机设备同步事件的触发因素可能是什么。我们的调查让我们回到 torch.use_definistic_algorithms 函数的文档,该函数告诉我们,当在需要 grad 的 CUDA 张量上调用时,torch.gather 会表现出非确定性行为,除非在模式设置为 True 的情况下调用 torch.use_definistic_algorithms。
换句话说,通过将脚本配置为使用确定性算法,我们修改了 torch.gather 向后传递的默认行为。事实证明,正是这种变化导致需要同步事件。事实上,如果我们删除此配置,性能问题就会消失!问题是,我们能否保持算法的确定性而不需要付出性能损失。
在下面的代码块中,我们提出了 PathDropout 模块前向函数的替代实现,该实现使用 torch.Tensor 索引而不是 torch.gather 产生相同的输出。修改后的代码行已突出显示。
from timm.layers import PatchDropout
class MyPatchDropout(PatchDropout):
def forward(self, x):
prefix_tokens = x[:, :self.num_prefix_tokens]
x = x[:, self.num_prefix_tokens:]
B = x.shape[0]
L = x.shape[1]
num_keep = max(1, int(L * (1. - self.prob)))
keep_indices = torch.argsort(torch.randn(B, L, device=x.device),
dim=-1)[:, :num_keep]
# The following three lines were modified from the original
# to use PyTorch indexing rather than torch.gather
stride = L * torch.unsqueeze(torch.arange(B, device=x.device), 1)
keep_indices = (stride + keep_indices).flatten()
x = x.reshape(B * L, -1)[keep_indices].view(B, num_keep, -1)
x = torch.cat((prefix_tokens, x), dim=1)
return x
model.patch_drop = MyPatchDropout(
prob = model.patch_drop.prob,
num_prefix_tokens = model.patch_drop.num_prefix_tokens
)
在下图中,我们捕获了上述更改后的跟踪视图:

我们可以清楚地看到,冗长的同步事件不再存在。
就我们的玩具模型而言,我们很幸运,torch.gather 操作的使用方式允许将其替换为 PyTorch 索引。当然,情况并非总是如此。 torch.gather 的其他用法可能没有基于索引的等效实现。
结果
在下表中,我们比较了在不同场景下训练玩具模型的性能结果:

在我们的玩具示例中,优化虽然可衡量,但影响不大——性能提升约 2%。有趣的是,可重现模式下的 torch 索引比默认(非确定性)torch.gather 的表现更好。根据这些发现,尽可能评估使用索引而不是 torch.gather 的选项可能是一个好主意。
总结
尽管 PyTorch 因易于调试和跟踪而享有(合理的)声誉,但 torch.autograd 仍然是一个谜,并且分析训练步骤的向后传递可能相当困难。为了应对这一挑战,PyTorch 支持在反向传播的不同阶段插入钩子。在这篇文章中,我们展示了如何在迭代过程中使用 PyTorch 向后钩子以及 torch.profiler.record_function 来识别向后传递中性能问题的根源。我们将此技术应用于一个简单的 ViT 模型,并了解了 torch.gather 操作的一些细微差别。
在这篇文章中,我们讨论了一种非常具体的性能瓶颈类型。请务必查看我们在媒体上发布的其他帖子,其中涵盖了与机器学习工作负载的性能分析和性能优化相关的各种主题。
本文由 mdnice 多平台发布