Linux设备驱动1:模块化编程初步讲解
Linux设备驱动1:模块化编程初步讲解
大家好,在掌握了C语言,STM32单片机,Linux网络编程等基础知识之后,接下来开始慢慢渗透Linux驱动,本专栏会持续更新,供大家一起学习。诸君共勉。。。
一.什么是模块化编程?
Linux的开发者,遍布世界各地,他们相互之间大多数估计都不认识。如果真的是对这些开发者进行统一管理,那是很难做到的。所以大牛们,在设计Linux内核的时候,融入了模块化的思想。也就是说,现在大家已经有一个现成的Linux操作系统了,所有的开发者写的代码对于这个Linux操作系统而言都是一个模块,开发者可以以模块的形式将自己的代码添加到内核,也可以从操作系统中卸载自己的模块。这种思想,在实际的开发中特别别有用。
例如:在你的设备上已经运行了一个成熟的Linux操作系统,由于客户的需求变化,你需要向这个操作系统上添加一些功能。现在你有两种做法:
第一种:获得Linux源代码,然后修改,添加功能,貌似挺牛,但是如果你写的代码不能一次性到达效果,你就必须去修改,这样就每次必须重新编译内核,是不是很麻烦。最可怕的是你一不小心,把内核源码给修改错了,那该怎么办呀?
第二种:快速编写自己的功能代码,然后以模块的形式添加到Linux操作系统中,然后测试,发现不行,卸载模块,继续修改代码,添加模块(高富帅的干活方式),。。是不是比使用第一种方法的苦逼程序员要轻松很多呀!
大家需要注意的是,一般我们都是通过模块化的方法向Linux操作系统添加驱动程序,那些Linux核心的代码,我个人觉得没有几个人会觉得不好,需要重新修改。
Linux 内核模块主要由以下几个部分组成:
模块加载函数(必须):当通过insmod命令加载内核模块时,模块的加载函数会自动被内核执行,完成本模块相关初始化工作;
模块卸载函数(必须):当通过rmmod命令卸载模块时,模块的卸载函数会自动被内核执行,完成与模块加载函数相反的功能;
模块许可证声明(必须):模块许可证(LICENCE)声明描述内核模块的许可权限,如果不声明LICENCE,模块被加载时将收到内核被污染的警告。
模块参数(可选):模块参数是模块被加载的时候可以被传递给他的值,它本身对应模块内部的全局变量;
模块导出符号(可选):内核模块可以导出符号(symbol,对应于函数或变量),这样其他模块可以使用本模块中的变量或函数;
模块作者等信息声明(可选)。
二.进行模块化编程:
参考代码:
linux/init.h
linux/module.h //必须包含的头文件
MODULE LICENSE("GPL")
MODULE_AUTHOR("dazai")
static int hello_init(void) //功能代码
{
printk("hello_init\n"); //内核的printf函数,用于输出信息
return 0;
}
static int hello_exit(void) //功能代码
{
printk("hello_exit\n"); //内核的printf函数,用于输出信息
return 0;
}
module_init(hello_init); //模块入口,完成模块加载
module_exit(hello_exit); //模块出口,完成模块卸载
看完上面的代码,请相信,你已经对模块化编程有了一个基本的认识。上面这段代码虽然很简单,但是他包含了Linux内核模块化编程需要的所有信息。
我们来一起总结一下Linux内核模块化编程必备的步骤:
第一步:
包含linux/init.h和inux/module.h这两个头文件;
linux/init.h
linux/module.h
通过MODULE LICENSE(“GPL”):
告诉内核你的模块遵从"GPL"协议,这个事情必须得做。如果不知道GPL的读者自己去查找相关资料;Linux能够成功一个关键因素就是遵循了GPL,从而一发不可收拾,在全球蔓延开来。
MODULE_AUTHOR(“dazai”):
用来指定编写这个模块的作者,可以不写。
第二步:
编写功能代码,注意这里没有main函数,这里叫模块的入口函数,函数名一般叫“xxx_init”,这里叫"hello_init"。你可以把模块的入口函数当做你的main函数,你的代码就从这个地方起步吧!
那这个函数什么时候被调用呢?
在模块加载到Linux内核的时候,Linux内核会调用这个函数模块的退出函数,这个函数的名字一般叫“xxx_exit”,这里叫“hello_exit”。这个函数里,我们一般会做些资源的释放。在模块卸载的时候会被调用到。当一个模块卸载的时候,我们肯定要把它占用的资源释放掉,不然不就造成资源浪费了。
第三步:
告诉内核,你的模块入入口和模块出口。Linux内核提供了两个宏,分别是:module_init 和 module_exit.
三.Linux内核打印函数printk:
printk的用法和printf类似,printf用于用户空间,printk用于内核空间。用printk函数时,内核会根据日志级别,可能把消息打印到当前控制台上,这个控制台通常是一个字符模式的终端、一个串口打印机或是一个并口打印机。
这些消息正常输出的前提是:日志输出级别小于console_loglevel(在内核中数字越小优先级越高)。
日志级别一共有8个级别,printk的日志级别定义如下:
(在include/linux/kemel.h中):

**没有指定日志级别的printk语句默认采用的级别是:**DEFAULT_MESSAGE_LOGLEVEL(这个默认级别一般为<4>,即与KERN_WARNING在一个级别上)。
我们可以通过cat/proc/sys/kemel/printk这个文件,查看系统默认的日志级别:
cat/proc/sys/kemel/printk
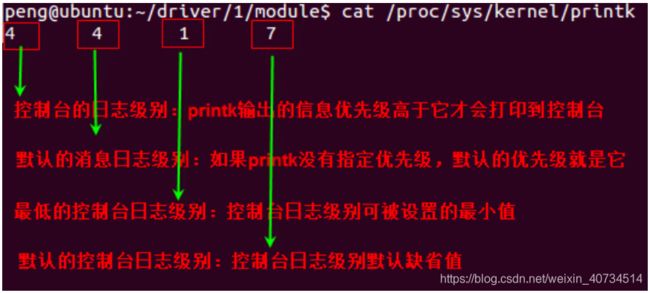
printk,其实不用想那么复杂,你就把它当做printf使用也可以的,在这里我们还不能测试printk输出的消息,是否能到控制台上,因为我们不知道如何编译我们的模块代码、如何加载我们的模块、如何卸载我们的模块。
好,接下来我们来看看,如何编译我们的模块。
四.模块的编译:
这里,先给出Linux模块化编译的流程:

模块的编译分两步:
第一步:调用linux源码树的Makefile进行收集编译一个模块所需要的信息
第二步:linux源码树的Makefile在收集完信息后,调用模块的Makefile。获取需要编译成模块的“.c”文件,最后生成模块文件.ko。
明白了模块的编译流程,接下来我们就来看具体如何编写模块的Makefile。
# KERNELRELEASE :在内核源码树的Makefile中定义,在当前的Makefile中,
它的值为空
#$(shell uname-r) :获得当系统的Linux内核版本
#KDIR :制定当前Linux操作系统源代码路径,即编译生成的模块是在当
前系统中使用
#如果想将你写的模块,用在你的开发板上运行的Linux系统中,
只需在KDIR变量中指定你开发板Linux系统源码树的路径
#PWD:=$(shell pwd)获得当前路径

我们来分析Makefile的执行过程:
-
在模块的源代码目录下执行make,此时,宏“KERNELRELEASE”【内核源码树的Makefile会定义】没有定义,因此进入else;
-
记录内核路径KDIR和当前工作目录PWD;

-
由于make 后面没有目标,所以make会在Makefile中的第一个不是以.开头的目标作为默认的目标执行,于是all成为make的目标;
all:的第一个命令

类似于printf函数,编译经过此处会打印提示信息。 -
make的第二条命令会执行 make -C ( K D I R ) M = (KDIR) M= (KDIR)M=(PWD) modules
翻译下就是:
make -C /lib/modules/3.2.0-29-generic-pae/build M=/home/peng/driver/1/module modules
-C 表示到存放内核的目录执行其Makefile,
M=$(PWD)表示返回到当前目录,
modules表示编译成模块的意思
之所以这么写是由内核源码树的顶层Makefile告诉我们的,当我们调用Linux内核源码树顶层的Makefile时,找到的是顶层Makefile的“modules”目标。我们来看下顶层Makefile的modules目标写了什么:


【截取了部分内容,我们没有必要全部了解,只需要关心红色部分即可,特别是对应的英文注释】
- 找到modules目标后,接下来Linux源码树的顶层Makeflle就需要知道是将那些".c"文件编译成模块。谁告诉它呢?是的,模块的Makefile文件。所以接下来就会回调模块的Makefile。需要注意的是,此时KERNELRELEASE已经在Linux内核源码树的顶层Makefile中定义过了,所以此时它获得信息是:
obj-m:=hello.o
obj-m表示会将hello.o目标编译成.ko模块;它告诉linux源码树顶层Makefile是动态编译(编译成模块)而不是编译进内核(obj-y),linux源码树顶层Makefile会根据hello.o找到hello.c文件
- 将模块文件hello.c编译为.o,然后再将多个目标链接为.ko。
最终编译结果如下:
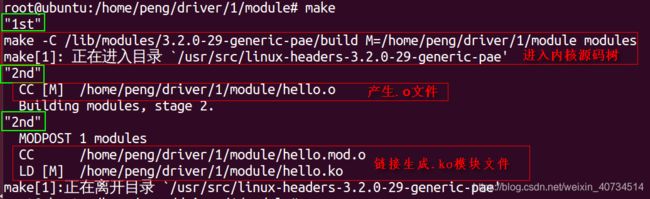
由执行结果可知,Makefile最终被调用了三次:
1) 执行命令make调用
2) 被linux内核源码树的顶层Makefile调用,产生.o文件
3) 被linux源码树顶层Makefile调用,将.o文件链接生成.ko文件
五.模块的加载、卸载:
如何将编译好的模块添加到Linux内核?如何从Linux内核将我们的模块卸载下来?
1.模块的加载命令:
insmod xxx.ko
例如:在ubuntu系统中添加自己写的模块
sudo insmod hello.ko
注意:在Linux系统中只有超级用户权限才可以添加模块到内核。
2.查看系统中的模块命令:
lsmod
例如:在系统中搜索自己添加的hello模块
sudo lsmod | grep hello
3.卸载模块命令:
sudo mmod hello
4.查看加载模块和卸载模块通过printk打印的信息命令:
dmesg或dmesg|tail
这个命令主要是从Linux内核的ring buffer(环形缓冲区)中读取信息的。
那什么是ring buffer呢?
在Limux系统中,所有通过printk打印出来的信息都会送到ring buffer中。我们知道,我们打印出来的信息是需要在控制台设备上显示的。在Linux内核初始化的时候,控制台设备并没有初始化的时候,使用printk会不会有问题
控制台设备,因为此时printk只是把信息输送到ring buffer中,等控制台设备初始化好后,在根据ring buffer中消息的优先级决定是否需要输送到控制台设备上。
如何清空ring buffer呢?
sudo dmesg -c
操作结果如下:
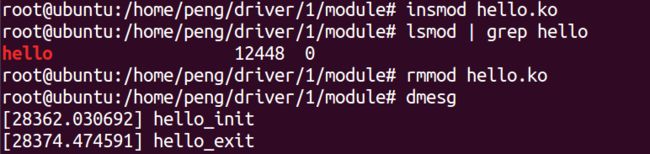
注意哟:哒宰操作全部在特权模式下,如果在普通用户权限下前面加sudo。