RGB转HSL的FPGA实现
RGB转HSL的FPGA实现_bilibili
大脑视觉皮层运作机理简介,CNN其实不像它_bilibili 联系请用B站私信
上上个视频中讲了《FPGA如何实现图像直方图统计?》。这个视频再来讲个稍微复杂点的:如何手写Verilog用FPGA实现RGB转HSL。HSL就是色调、饱和度、亮度颜色模式。对此不了解的可以看看《视频调色基础:什么是HSL?色相、饱和度、亮度?》这个视频。
下文如果缺图片就请到视频中去看

在之前《FPGA图像处理中二值算子的一些妙用》这个视频中已经讲过HSL颜色模式的重要用途,比如想把图像中某个颜色的背景扣掉,就需要用到H值对图像进行阈值处理,也就是通过背景色调值的范围把背景标记出来,如上图所示。而这种处理在工业领域也比较常用,所以用FPGA实现实https://github.com/becomequantum/时的RGB转HSL是有实用价值的。

https://github.com/becomequantum/ https://github.com/becomequantum/RGB转HSL的C_sharp代码在上面这个“无限次元”开源软件里有,代码就在上面这个库中。“无限次元”工程里、"图像.cs"这个代码中、“RGB转HSL”这个函数实现的就是这个功能,这个函数是我从网上抄来的,它的转换结果和windows调色板里的是一样的。
https://github.com/becomequantum/RGB转HSL的C_sharp代码在上面这个“无限次元”开源软件里有,代码就在上面这个库中。“无限次元”工程里、"图像.cs"这个代码中、“RGB转HSL”这个函数实现的就是这个功能,这个函数是我从网上抄来的,它的转换结果和windows调色板里的是一样的。

要用FPGA实现这个功能,就是要对着上面这个C_sharp代码写出它的Verilog版本。还是有点小繁杂的,因为涉及到的基础知识点比较多,有下面这些:
1、乘除常数在Verilog里该如何写?结果四舍五入怎么写?(神经网络里的参数在推理时是常数,所以可以不用DSP乘法器。)
2、FPGA除法器IP核的使用,移位寄存器IP核的使用。
3、对RTL代码的时序要有深刻理解,如何看懂FPGA综合后给出的时序报告?如何插入流水线寄存器?
如果是一个对上面这些知识点还似懂非懂的初学者,想要把这个代码写出来还是有些难度的。换句话说就是,练习写这个代码是非常好的Verilog代码实战训练,会写了就能从新手成为熟手了。
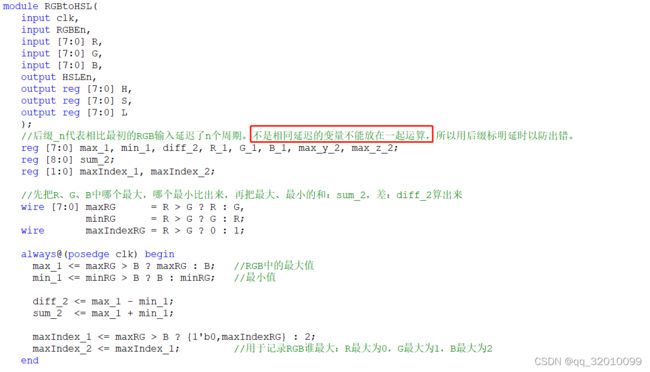
下面来看Verilog代码。上图是代码的第一部分,用来把R、G、B三个值中最大的和最小的那个找出来。这部分逻辑比较简单,关键知识点在于时序。代码中大部分变量名我都加了个数字后缀,用于标明它相对于最初的RGB输入延迟了多少个周期。比如max_1和min_1这两个寄存器变量就是相对于最初的输入数据有1个周期的延时。
那为啥要把延时了几个周期标在变量后面呢?这是为了方便自己知道这个变量的延时情况,因为不同延时的变量显然是不能放在一起做计算的。例如上图是后面计算色调值的代码,会有max减去B这样的运算,而max_1是比B延时了一个周期的,这时就不能拿max_1和B在一起计算,因为这两个信号时序差了一个周期,结果肯定是错乱的。只有把B延迟一个周期,成为B_1之后才能和max_1相减。所以把延时标在变量名后面,就是为了防止不要出现这样的时序错误。变量多了之后如果没有标记,那是根本记不住每个变量的延时是多少的,这样在写代码的时候就会很麻烦。
在写上位机软件代码时,计算延时这些问题几乎都不需要去考虑。但写Verilog代码这些就都要考虑,除了上面说的寄存器周期延时问题,还要考虑组合电路的延时问题。比如上面这个比出RGB最大值和最小值的代码时序情况如何呢?也就是这两级的比较电路延时是多少纳秒,这个组合电路的延时决定了整个电路能跑多高的频率。要得到这个信息,我们先得把代码跑一下综合。在ISE里综合后点如上图所示的综合报告,就能在报告的最后看到三条时序路径的具体延时信息。时序路径并不止这三条,这三条是选出来的代表,其中第一条是代码里某两级寄存器之间的路径。第二条是从某个输入信号管脚到某第一级寄存器之间的路径。第三条是从最后一级寄存器到输出信号管脚之间的路径。也就是选了这个电路模块前、中、后三个阶段的时序路径各一条展示在了这里。

上图中展示的是从输入G到第一级寄存器min_1的时序路径之一,报告上写着它包含了10级组合逻辑,估计总延时是5.806纳秒。具体的10级逻辑中,先是经历了Less Than比较器,再经历一级选通,然后又经历了几级比较器和一级选通。因为我们的代码就是这样写的,比较了两次把RGB里的最小值比了出来。5.806纳秒的组合电路延迟意味着电路频率可以跑到160多兆赫兹。这个频率在一般应用中也基本够用了,比如1080p,60帧的视频流像素时钟也才150兆。当然这个延时值是和具体的FPGA型号和速度等级相关的。如果出现了组合电路延时过大,导致电路频率达不到要求的情况,那可能就要考虑加流水线寄存器了。比如把上面代码中的maxRG和minRG从wire改为寄存器,就是插入了流水线寄存器,把原本放在一个周期中完成的两次比较拆到两个周期中去完成,这样每一级的延时大概就会减半,电路就能跑到更高的频率。代价就是多耗费了一些寄存器。
下面继续来看亮度值L的计算,它是HSL三个值中最好算的。亮度值的算法就是把RGB中的最大值和最小值加起来,然后压缩一下取值范围。当RGB的值都是最大255时,L值最大为510,也就是亮度值的取值范围是0到510,这个范围一个字节表示不下,所以要压缩一下。但也不是就除以2,压缩为0到255。而是除以51再乘以24,也就是乘以0.47,把取值范围压缩为0到240。这是为了和H色调值的取值范围保持一致。
从上图可以看出,色调值其实就是某种颜色在这个色环上的角度值,取值范围应该是0到360,但360一个字节又存不下,所以就把H值的取值范围压缩到了最大值240,然后饱和度S和亮度值L也都被统一到这个取值范围。
那乘以0.47在Verilog里又该怎么写呢?乘以常数是不需要DSP乘法器IP的,但又不能直接写乘0.47,写乘浮点数综合似乎过不了,那就只能写乘整数,也就是取9位0.47的二进制有效数字去乘,然后截取最前面的8位,再把后面一位做为四舍五入加上即可。
在用FPGA加速神经网络推理时,网络参数其实也算是常数,可以像这样写在代码里。这样写的好处就是无需消耗DSP乘法器资源,可以更多的利用片上逻辑资源进行计算。坏处就是把参数写死在代码里就不能改了,要改只能重新编译代码,重新烧写FPGA的比特文件。如果参数并不需要经常变的话,这种写法也是可以考虑的。当然把参数写在代码里这个事情并不需要自己手写,写个程序自动从神经网络模型文件中把参数读出来填入Verilog代码模板中即可。
L值只需要两个周期就算出来了,但H和S值的计算需要用到除法器IP,需再延时20个周期。而最后输出H、S、L值时,时序肯定是要对齐的,所以即使L很早就算出来了,也需要再延时一段时间和H、S一齐输出。而在FPGA里,Ram based Shift Register,也就是基于Ram的移位寄存器IP就是专门干这个事情的,用这个IP要比自己写一排寄存器进行延时更省资源。这个IP的使用很简单,填一下位宽和深度即可,深度就是所需要延迟的周期数。
接下来看饱和度S值的计算代码,S值也比较好算,基本上就是用RGB中最大值和最小值的差去除以它们的和。得到的结果值是在0,1之间,然后乘以240,让其取值范围变为0到240即可。这里面的知识点就是Divider、除法器IP的使用。Divider是专门用于两个整数相除的IP,如果是浮点数的乘除、开方、三角函数等运算用的则是另外的浮点IP。
除法器的除数和被除数宽度自然都选8位,Remainder Type要选Fractional,也就是需要小数部分,而不是要余数。因为上述除法的结果在0,1之间,也就是有效数字都在小数部分,位数需要大概10位精度才够。然后选择的是无符号的除法,最后Latency这一栏会告诉我们这样的配置所需的计算延迟是20个周期。看来两个变量的除法还是挺费事的。
最后再来看色调值的计算,H的计算稍微麻烦一点,俺在这懒得讲了,留给大家自己琢磨练习吧。我想提示一下的是,整个模块只用到了两个除法器,算S和H各用到了一个。如果你去看C sharp代码就会发现,里面除法出现的地方好像不止这些。H和S的计算的确只需要各算一次除法即可,但在写软件代码时肯定是怎么方便,怎么好理解就怎么写,并没有想着要去优化运算次数,少写几个除法。但在写Verilog代码时,由于硬件资源比较宝贵,所以自然就会更多的考虑该如何简化计算,把实际上是冗余的计算步骤去掉,得出最精简的代码写法。