Anomalib 图像异常检测算法
图像异常检测算法
- 1.简介
-
- 1.1. 问题描述
- 1.2. 挑战与需求
- 2. 图像异常检测定义
-
- 2.1 异常的定义及类型
- 2.2 图像数据中的异常
- 3. 图像异常检测技术研究现状
- 4.方法
- 5.安装和使用
-
- 5.1 安装
-
- PyPI 安装
- 本地安装
- 5.2 训练
- 5.3 特征提取与(预训练)backones
- 5.4 自定义数据集
- 5.5 推理
-
- PyTorch 推理
- Lightning 推理
- OpenVINO 推理
- Gradio 推理
- 5.6 超参数优化
- 5.7 基准测试
- 5.8 实验管理
1.简介
在工业生产中,质量保证是至关重要的,因为生产中的细小缺陷可能导致产品不合格,甚至损害消费者和企业的利益。工业异常检测是一项关键任务,旨在从大规模的生产数据中可靠地检测出异常情况,这些异常可能是缺陷、故障或其他不正常情况。以下是关于工业异常检测的更多详细内容:
1.1. 问题描述
在工业生产中,产品和生产过程通常受到监控和控制,以确保产品质量和生产效率。然而,由于各种因素,例如材料变异、设备故障、操作误差等,仍然存在生产过程中的异常情况。这些异常可能包括产品中的缺陷、生产线中的故障、异常的工艺参数,以及其他与正常生产不符的情况。
1.2. 挑战与需求
工业异常检测面临多种挑战,这些挑战在很大程度上区分它与传统监督学习问题的不同之处:
- 难以获取大量异常样本:工业生产中异常情况通常相对较少,因为异常情况不是常态。相比之下,正常情况的数据通常占主导地位,这使得异常检测成为无监督学习问题。
- 正常样本和异常样本差异较小:正常产品和异常产品可能在特征上没有明显的差异,而且异常可能在细节上表现出相对微弱的特征。
- 异常的类型不能预先得知:在某些情况下,异常的类型和性质可能在先验知识中未知,因此算法需要具备足够的灵活性来检测各种类型的异常。
2. 图像异常检测定义
2.1 异常的定义及类型
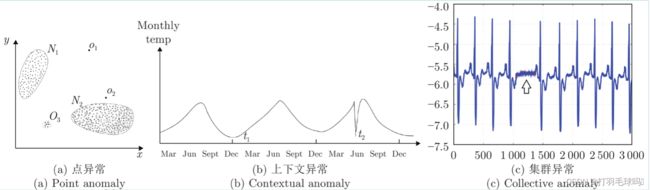
异常,又被称为离群值,是一个在数据挖掘领域中常见的概念,已经有不少的工作尝试对异常数据进行定义。一般情况下,会将常见的异常样本分为3个类:点异常、上下文异常和集群异常。
- 点异常一般表现为某些严重偏离正常数据分布范團的观测值,如下图 ( a ) (a) (a)所示的二维数据点,其中偏离了正常样本点的分布区域 ( N 1 , N 2 ) (N_1, N_2) (N1,N2)的点 ( O 1 , O 2 , O 3 ) (O_1,O_2,O_3) (O1,O2,O3)即为异常点。
- 上下文异常则表现为该次观测值虽然在正常数据分布范国内,但联合周围数据一起分析就会表现出显著的异常. 如下图 ( b ) (b) (b)所示, t 2 t_2 t2点处的温度值虽然依然在正常范围内,但联合前后两个月的数据就能发现该点属于异常数据。
- 集群异常,又称为模式异常,是由一系列观测结果聚合而成并且与正常数据存在差异的异常类型.该类异常中,可能单独看其中任意一个点都不属于异常,但是当一系列点一起出现时就属于异常,如下图 ( c ) (c) (c)箭头所指区域内单独看每一个点的值都在正常范围内,但这些点聚合在一起就形成了与正常信号模式完全不同的结构。
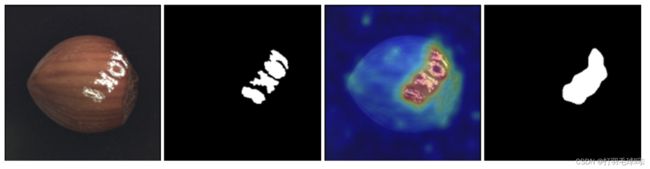
2.2 图像数据中的异常
图像数据中每一个像素点上的像素值就对应着一个观测结果,由于图像内像素值的多样性,仅仅分析某一个点的像素值很难判断其是否属于异常.所以在大部分图像异常检测任务中,需要联合分析图像背景以及周国像素信息来进行分类,检测的异常也大多属于上下文或者模式异常:当然,这种异常类型之间并没有非常严格的界限 例如,有一部分方法就提取图像的各类特征,并将其与正常图像的特征进行比较以判断是否属于异常,这就将原始图像空间内模式异常的检测转专换到了特征空间内点异常的检测。
图像异常检测任务根据异常的形态可以分为定性异常的分类和定量异常的定位两个类别。
- 定性异常的分类:类似于传统图像识别任务中的图像分类任务,即整体地给出是否异常的判断,无需准确定位异常的位置. 如下图左上图所示,左侧代表正常图像,石侧代表异常图像,在第1行中,模型仅使用服饰数据集中衣服类型的样本进行训练,则其他类别的样本图像(鞋子等)对模型来说都是需要检测的异常样本,因为他们在纹理、结构和语义信息等方面都不相同,又或者如第2行所示,异常图像中的三极管与正常图像之间只是出现了整体的偏移,而三极管表面并不存在任何局部的异常区域,难以准确地定义出现异常的位置,更适合整体地进行异常与否的分类。
- 定量异常的定位:类似于目标检测或者图像分割任务,需要得到异常区域的位置信息.在这种类型的图像异常检测中,测试图象中只有一小部分区域出现了异常模式. 而异常定位任务根据具体的图像背景又可分为以下几类,如下图所示,其中被圈出部分为异常区域。
-
- 均匀背景
均匀背景代指一些内容较为单一的场景,如下中上图所示磨砂玻璃表面对局部缺陷的定位,或者深色山区图像中对盘山公路的定位,这一类背景下的异常检测属于相对简单的检测任务。
- 均匀背景
-
- 纹理背景
纹理背景主要出现在工业生产领域中,根据纹理形态又可以分为简单纹理、周期性纹理和随机纹理3种.其中,简单纹理代指因光照和材质反光等因素影响,在原本均匀的物体表面产生的一些非均匀的纹理背景,如下图的钢板表面图像.而周期性纹理则代指各类由大量重复单元组成的具有显著周期性的图像,最具代表性的就是下图所示的各类布匹图像.而随机纹理则代指一些由无规则结构组成的图像背景,如下图所示的声呐和纳米材料图像。
- 纹理背景
-
- 结构背景
结构背景则是一类更为广泛的图像背景,一般具有结构复杂、个体差异大和语义信息丰富等特点,需要整体进行分析而无法仅依定局部信息进行异常检四,如下图所示的各种医学图像,这类图像背景下的异常检测问题是相对较难的一类检测任务。

- 结构背景
3. 图像异常检测技术研究现状
一般情况下图像异常检测的目标是通过无监督或者半监督学习的方式,检测与正常图像不同的异常图像或者局部异常区域,近年来传统机器学习方法已经在图像异常检测领域有了较多的应用,而随着深度学习技术的发展,越来越多的方法尝试结合神经网络来实见图像异常检测。根据在模型构建阶段有无神经网络的参与,现有的图像异常检测方法可以分为基于传统方法和基于深度学习的方法两大类别。
如下图了所示,基于传统方法的异常检测技术大致包含6个类别:
- 基于模板匹配
- 基于统计模型
- 基于图像分解
- 基于频域分斤
- 基于稀疏编码重构
- 基于分类面构建
而基于深度学习的方法大致包含4个类别:
- 基于距离度量
- 基于分类面构建
- 基于图像重构
- 结合传统方法

4.方法
为了解决图像异常检测上的问题,这里介绍无监督学习的一种方法。无监督学习采用深度学习技术,如卷积神经网络(CNN)、生成对抗网络(GAN)和自动编码器(AE)等,以进行无监督的异常检测和定位。这些方法通常利用深度学习模型来学习数据的表示,并使用这些表示来计算异常分数或执行像素级异常定位。它们属于基于深度学习的异常检测方法中的一部分。
无监督图像异常检测和定位方法从方法上可以分为判别方法和生成方法。下面将对其中一些算法进行更详细的介绍
判别方法:
- CFlow:CFlow是一种基于密度比的方法,它使用条件密度比估计来判别异常点。该方法依赖于密度比的计算,以区分正常和异常数据点。
- DFKDE:DFKDE(Density-Ratio Based Kernel Density Estimation)是一种基于密度比的方法,它通过估计两个条件密度函数之间的比值来识别异常点。
- PatchCore:PatchCore方法使用卷积神经网络(CNN)来学习数据的表示,然后在表示空间中使用聚类方法来定位异常区域。
- STFPM:STFPM(Spatial-Temporal Fusion Proximity Map)是一种用于视频数据的异常检测方法,它结合了空间和时间信息,以识别视频中的异常区域。
生成方法:
- GANomaly:GANomaly结合了生成对抗网络(GAN)和自编码器(Autoencoder)的思想,通过生成和重建来检测异常数据点。异常数据点通常不能被生成模型伪装。
- Draem:Draem(Deep Recurrent Autoencoder for Extreme Multiclass Classification)是一种深度递归自编码器,用于检测和定位异常点。它在大规模多类别异常检测中表现出色。
- Padim:Padim(Part-based Anomaly Detection for Images)是一种图像异常检测方法,它将图像分解为部分,并检测异常部分,以实现异常定位。
- Reverse Distillation:Reverse Distillation方法使用知识蒸馏的思想,将大型模型的知识传递给小型模型,以识别异常数据点。
- Fast-Flow:Fast-Flow是一种在图像上进行流场估计的方法,通过检测像素级的流场异常来定位图像中的异常区域。
那如何更快上手使用这么多算法呢,这里介绍一个python异常检测库anomalib
github:https://github.com/openvinotoolkit/anomalib
5.安装和使用
Anomalib 是一个深度学习库,旨在收集最先进的异常检测算法,以便在公共和私有数据集上进行基准测试。Anomalib 提供了近期文献中描述的异常检测算法的几种即用型实现,以及一套便于开发和实现自定义模型的工具。该库重点关注基于图像的异常检测,算法的目标是识别异常图像或数据集中图像的异常像素区域。
5.1 安装
这是一个有关"anomalib"库的安装和使用的教程
PyPI 安装
你可以通过使用pip轻松开始使用anomalib。
pip install anomalib
本地安装
强烈建议在安装anomalib时使用虚拟环境。例如,使用Anaconda,可以按以下方式安装anomalib:
yes | conda create -n anomalib_env python=3.10
conda activate anomalib_env
git clone https://github.com/openvinotoolkit/anomalib.git
cd anomalib
pip install -e .
5.2 训练
默认情况下,python tools/train.py 在MVTec AD(CC BY-NC-SA 4.0)数据集的leather类上运行PADIM模型。
python tools/train.py # 在MVTec AD的leather上训练PADIM
在特定数据集和类别上训练模型需要进一步配置。每个模型都有其自己的配置文件config.yaml,其中包含了数据、模型和训练可配置参数。要在特定数据集和类别上训练特定模型,需要提供相应的配置文件:
python tools/train.py --config <path/to/model/config.yaml>
例如,要训练PADIM,可以使用以下命令:
python tools/train.py --config src/anomalib/models/padim/config.yaml
或者,也可以提供模型名称作为参数,脚本会自动找到相应的配置文件。
python tools/train.py --model padim
目前可提供的模型:
- CFA
- CFlow
- DFKDE
- DFM
- DRAEM
- EfficientAd
- FastFlow
- GANomaly
- PADIM
- PatchCore
- Reverse Distillation
- STFPM
5.3 特征提取与(预训练)backones
预训练的骨干模型来自PyTorch图像模型(timm),它们由FeatureExtractor包装。
配置骨干模型可以在配置文件中设置,以下是两个示例:
model:
name: cflow
backbone: wide_resnet50_2
pre_trained: true
5.4 自定义数据集
也可以在自定义文件夹数据集上进行训练。为此,需要修改config.yaml文件的数据部分,如下所示:
dataset:
name: -of-the-dataset>
format: folder
path: >
normal_dir: normal # name of the folder containing normal images.
abnormal_dir: abnormal # name of the folder containing abnormal images.
normal_test_dir: null # name of the folder containing normal test images.
task: segmentation # classification or segmentation
mask: > #optional
extensions: null
split_ratio: 0.2 # ratio of the normal images that will be used to create a test split
image_size: 256
train_batch_size: 32
test_batch_size: 32
num_workers: 8
normalization: imagenet # data distribution to which the images will be normalized: [none, imagenet]
test_split_mode: from_dir # options: [from_dir, synthetic]
val_split_mode: same_as_test # options: [same_as_test, from_test, sythetic]
val_split_ratio: 0.5 # fraction of train/test images held out for validation (usage depends on val_split_mode)
transform_config:
train: null
val: null
create_validation_set: true
tiling:
apply: false
tile_size: null
stride: null
remove_border_count: 0
use_random_tiling: False
random_tile_count: 16
通过将上述配置放置到config.yaml文件的数据部分,模型将在自定义数据集上进行训练。
5.5 推理
Anomalib包括多个推理脚本,包括Torch、Lightning、Gradio和OpenVINO推理器,用于使用训练/导出的模型执行推理。在这一部分,我们将介绍如何使用这些脚本进行推理。
PyTorch 推理
# 要获得有关参数的帮助,请运行:
python tools/inference/torch_inference.py --help
# 示例Torch推理命令:
python tools/inference/torch_inference.py \
--weights results/padim/mvtec/bottle/run/weights/torch/model.pt \
--input datasets/MVTec/bottle/test/broken_large/000.png \
--output results/padim/mvtec/bottle/images
Lightning 推理
# 要获得有关参数的帮助,请运行:
python tools/inference/lightning_inference.py --help
# 示例Lightning推理命令:
python tools/inference/lightning_inference.py \
--config src/anomalib/models/padim/config.yaml \
--weights results/padim/mvtec/bottle/run/weights/model.ckpt \
--input datasets/MVTec/bottle/test/broken_large/000.png \
--output results/padim/mvtec/bottle/images
OpenVINO 推理
要运行OpenVINO推理,您需要首先将PyTorch模型导出到OpenVINO模型中。确保在相应的模型config.yaml文件中设置export_mode为"openvino"。
# 示例OpenVINO配置文件config.yaml
optimization:
export_mode: "openvino" # 选项: openvino, onnx
# 要获得有关参数的帮助,请运行:
python tools/inference/openvino_inference.py --help
# 示例OpenVINO推理命令:
python tools/inference/openvino_inference.py \
--weights results/padim/mvtec/bottle/run/openvino/model.bin \
--metadata results/padim/mvtec/bottle/run/openvino/metadata.json \
--input datasets/MVTec/bottle/test/broken_large/000.png \
--output results/padim/mvtec/bottle/images
确保在需要正确应用标准化时提供metadata.json路径。
Gradio 推理
使用Gradio推理与训练模型交互,使用用户界面。有关更多详情,请参阅我们的指南。
# 要获得有关参数的帮助,请运行:
python tools/inference/gradio_inference.py --help
# 示例Gradio推理命令:
python tools/inference/gradio_inference.py \
--weights results/padim/mvtec/bottle/run/weights/model.ckpt \
--metadata results/padim/mvtec/bottle/run/openvino/metadata.json \ # 可选
--share # 可选,用于共享UI
5.6 超参数优化
要运行超参数优化,请使用以下命令:
python tools/hpo/sweep.py \
--model padim --model_config ./path_to_config.yaml \
--sweep_config tools/hpo/sweep.yaml
5.7 基准测试
要收集各种基准测试数据,如跨类别的吞吐量,使用以下命令:
python tools/benchmarking/benchmark.py \
--config /.yaml
5.8 实验管理
Anomalib与各种实验追踪库集成,如Comet、tensorboard和wandb,通过PyTorch Lightning日志记录器。
以下是如何启用超参数、指标、模型图以及在测试数据集中的图像预测的日志示例:
visualization:
log_images: True # log images to the available loggers (if any)
mode: full # options: ["full", "simple"]
logging:
logger: [comet, tensorboard, wandb]
log_graph: True