Parquet文件测试(一)——使用Java方式生成Parqeut格式文件并直接入库的Hive中
生成Parquet格式文件并同步到Hive中
验证目标
- Parquet格式是否可以直接将上传到Hdfs中的文件,加载到目标数据表中(Hive)。
- 生成Parquet格式文件,并上传到Hdfs中。
创建测试表
表信息如下(注意stored as parquet默认为orcfile):
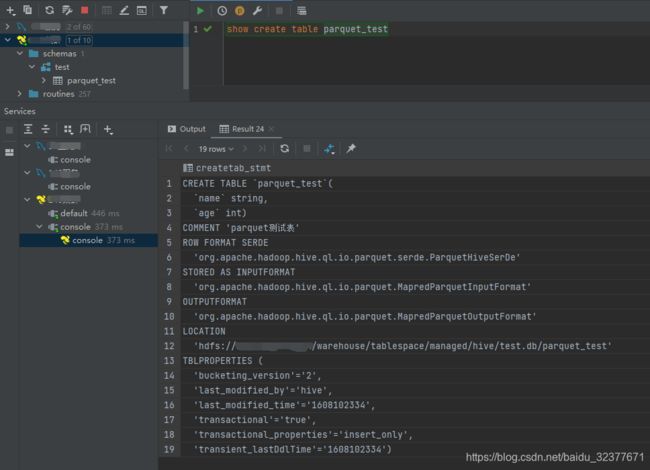
建表语句如下:
create table parquet_test
(
name string,
age int
)
comment 'parquet测试表'
stored as parquet ;
验证一:Hive直接加载Parquet格式文件
添加测试数据
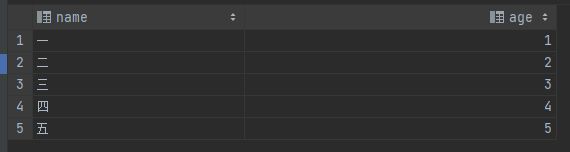
先在parquet_test表中添加几条测试数据:
查看文件保存的位置
查看parquet_test表对应的hdfs目录:

可以使用hadoop fs -cat /warehouse/tablespace/managed/hive/test.db/parquet_test/delta_0000005_0000005_0000/000000_0命令查看该文件,不出意外是乱码,但是对应的是一条数据。
![]()
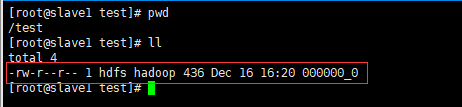
拉取文件到本地
hadoop fs -get /warehouse/tablespace/managed/hive/test.db/parquet_test/delta_0000005_0000005_0000/000000_0 /test/。将指定文件保存到根目录test文件夹下。需要提前创建文件夹并授权mkdir test && chmod 777 test/。
![]()
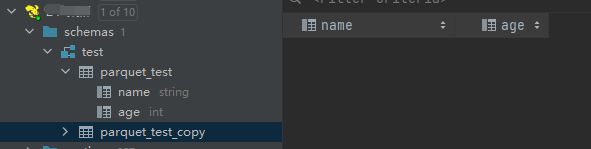
创建空表上传文件
创建一张与parquet_test表结构一致的表parquet_test_copy用来验证Hive是否可以直接加载Hdfs中的Parquet格式文件。
上传文件到parquet_test_copy表的hdfs目录下。

查看parquet_test_copy表的hdfs目录下是否有上传文件。
![]()
查看结果
目前可以看到数据可以在hive中查到。基本可以证明Parquet格式文件可以被hive直接从hdfs中加载,与textfile类似。
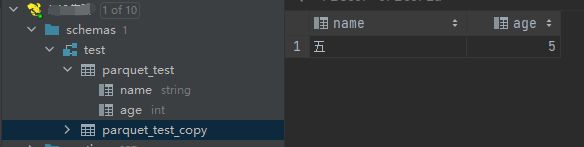
0: jdbc:hive2://slave2:2181,master:2181,slave> select * from parquet_test_copy;
INFO : Compiling command(queryId=hive_20201216164419_b5ddbf13-6668-4911-80ba-e6995b261238): select * from parquet_test_copy
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:parquet_test_copy.name, type:string, comment:null), FieldSchema(name:parquet_test_copy.age, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20201216164419_b5ddbf13-6668-4911-80ba-e6995b261238); Time taken: 0.081 seconds
INFO : Executing command(queryId=hive_20201216164419_b5ddbf13-6668-4911-80ba-e6995b261238): select * from parquet_test_copy
INFO : Completed executing command(queryId=hive_20201216164419_b5ddbf13-6668-4911-80ba-e6995b261238); Time taken: 0.005 seconds
INFO : OK
+-------------------------+------------------------+
| parquet_test_copy.name | parquet_test_copy.age |
+-------------------------+------------------------+
| 五 | 5 |
+-------------------------+------------------------+
验证二:生成Parquet格式文件导入到HIVE
创建测试表
添加一个时间戳字段(该类型写入比较麻烦,此处记录一下)
create table parquet_with_time
(
name string,
age int,
create_time timestamp
)
comment 'parquet测试表'
stored as parquet ;
主要使用到的依赖
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-columnartifactId>
<version>1.11.0version>
dependency>
<dependency>
<groupId>org.apache.parquetgroupId>
<artifactId>parquet-hadoopartifactId>
<version>1.11.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.joddgroupId>
<artifactId>jodd-coreartifactId>
<version>5.1.5version>
dependency>
<dependency>
<groupId>joda-timegroupId>
<artifactId>joda-timeartifactId>
<version>2.10.5version>
dependency>
编写测试用例
主要步骤就是按照Hive表结构设置文件写入的结构,然后再根据表字段的类型写入对应的数据。
import jodd.time.JulianDate;
import lombok.Data;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.column.ParquetProperties;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetFileWriter;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.example.ExampleParquetWriter;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.io.api.Binary;
import org.apache.parquet.schema.LogicalTypeAnnotation;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.PrimitiveType;
import org.apache.parquet.schema.Types;
import org.joda.time.DateTime;
import org.joda.time.DateTimeZone;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZonedDateTime;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;
public class Test {
//表结构
private static final MessageType FILE_SCHEMA;
private static final String TABLE_NAME = "parquet_with_time";
static {
//定义表结构
Types.MessageTypeBuilder messageTypeBuilder = Types.buildMessage();
messageTypeBuilder
.optional(PrimitiveType.PrimitiveTypeName.BINARY)
.as(LogicalTypeAnnotation.stringType())
.named("name")
.optional(PrimitiveType.PrimitiveTypeName.INT32)
.named("age")
.optional(PrimitiveType.PrimitiveTypeName.INT96)
.named("create_time");
FILE_SCHEMA = messageTypeBuilder.named(TABLE_NAME);
}
/**
* 主函数
*
* @param args
*/
public static void main(String[] args) throws IOException {
System.out.println("测试");
//获取数据数据
List<TestItem> testData = getTestData();
//写入数据
writeToFile(testData);
}
/**
* 写入数据
*/
private static void writeToFile(List<TestItem> testItems) throws IOException {
//获取文件写入的目录
String filePath = "/warehouse/tablespace/managed/hive/test.db/parquet_with_time/p_" + System.currentTimeMillis();
//查看多条数据是否可以一次性写入一个Parquet文件
ParquetWriter<Group> writer = getWriter(filePath);
SimpleGroupFactory simpleGroupFactory = new SimpleGroupFactory(FILE_SCHEMA);
//校验目录
for (TestItem testItem : testItems) {
Group group = simpleGroupFactory.newGroup();
group.append("name", testItem.getName());
group.append("age", testItem.getAge());
group.append("create_time", Binary.fromConstantByteArray(getTimestamp(testItem.getCreateTime())));
writer.write(group);
}
writer.close();
}
/**
* Parquet写入配置
* @param filePath
* @return
* @throws IOException
*/
private static ParquetWriter<Group> getWriter(String filePath) throws IOException {
Path path = new Path(filePath);
return ExampleParquetWriter.builder(path)
.withWriteMode(ParquetFileWriter.Mode.CREATE)
.withWriterVersion(ParquetProperties.WriterVersion.PARQUET_1_0)
.withCompressionCodec(CompressionCodecName.SNAPPY)
.withConf(getHdfsConfiguration())
.withType(FILE_SCHEMA).build();
}
/**
* 测试的表结构数据
*/
@Data
private static class TestItem {
private String name;
private int age;
private Date createTime;
}
/**
* 测试数据
*
* @return
*/
private static List<TestItem> getTestData() {
DateTime now = DateTime.now();
List<TestItem> testItems = new ArrayList<>();
IntStream.range(1, 6).forEach(i -> {
TestItem testItem = new TestItem();
testItem.setName("hdfs_" + i);
testItem.setAge(i + 10);
testItem.setCreateTime(now.minusHours(i).toDate());
testItems.add(testItem);
});
return testItems;
}
/**
* 将Date转换成时间戳
* @param date
* @return
*/
private static byte[] getTimestamp(Date date){
DateTime dateTime = new DateTime(date, DateTimeZone.UTC);
byte[] bytes = new byte[12];
LocalDateTime localDateTime = LocalDateTime.of(dateTime.getYear(), dateTime.getMonthOfYear(), dateTime.getDayOfMonth(),
dateTime.getHourOfDay(), dateTime.getMinuteOfHour(), dateTime.getSecondOfMinute());
//转纳秒
long nanos = dateTime.getHourOfDay() * TimeUnit.HOURS.toNanos(1)
+ dateTime.getMinuteOfHour() * TimeUnit.MINUTES.toNanos(1)
+ dateTime.getSecondOfMinute() * TimeUnit.SECONDS.toNanos(1);
//转儒略日
ZonedDateTime localT = ZonedDateTime.of(localDateTime, ZoneId.systemDefault());
ZonedDateTime utcT = localT.withZoneSameInstant(ZoneId.of("UTC"));
JulianDate julianDate = JulianDate.of(utcT.toLocalDateTime());
//写入INT96时间戳
ByteBuffer buffer = ByteBuffer.wrap(bytes);
buffer.order(ByteOrder.LITTLE_ENDIAN)
.putLong(nanos)//8位
.putInt(julianDate.getJulianDayNumber());//4位
return bytes;
}
/**
* hdfs配置
* @return
*/
public static Configuration getHdfsConfiguration() {
//设置操作用户为hdfs用户
Configuration configuration = new Configuration();
System.setProperty("HADOOP_USER_NAME", "hdfs");
//配置连接
configuration.set("fs.defaultFS", "hdfs://192.168.11.240:8020");
return configuration;
}
}
如果不想直接将文件上传到Hdfs中,只需要注释掉Hdfs的配置并添加一个本地的文件路径即可。(HADOOP_USER_NAME可以在环境变量中配置)
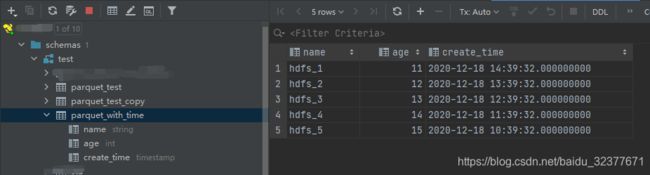
运行测试用例查看结果
此处要查看两个问题:
- Hive表是否能正常加载上传到Hdfs中的Parquet文件(用来验证生成的Parquet文件格式是否正确)
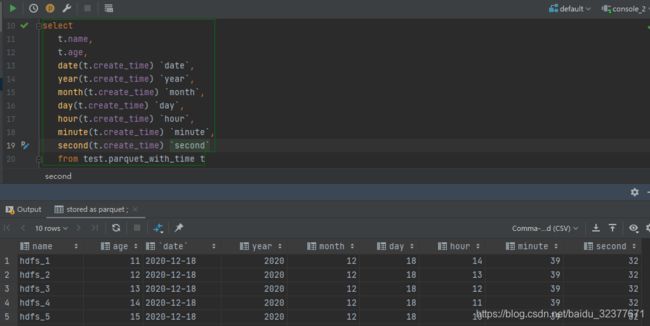
- HIve表中的时间戳字段是否能正常显示且时间是否显示正确(不转换成儒略日时间戳字段日期显示不正确,不转换成纳秒值时间戳时间显示不正确)
使用timestamp类型比string类型更加方便(跟Mysql类似,HIve也有时间日期操作的函数)
参考
- Parquet文件写入:https://www.cnblogs.com/ulysses-you/p/7985240.html
- Hive文件格式讲解:https://blog.csdn.net/resin_404/article/details/106639736
- 时间戳转换:https://www.cnblogs.com/itboys/p/13726957.html