CUDA编程入门系列(二) GPU硬件架构综述
一、Fermi GPU
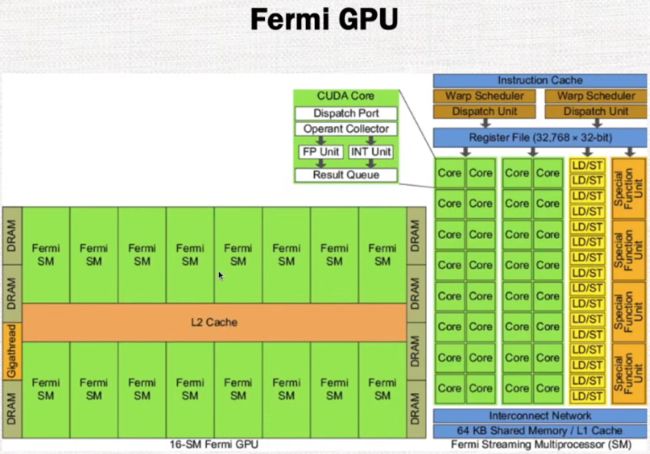
Fermi GPU如下图所示,由16个SM(stream multiprocessor)组成,不同的SM之间通过L2 Cache和全局内存进行相连。整个架构大致分为两个层次,①总体架构由多个SM组成 ②每个SM由多个SP core(stream processor)组成。SP之间通过互连的网络和L1 Cache和Warp Scheduler等结构进行相连。
二、GT200体系架构
下图为GT200体系架构,整体由10个TPC组成,每个TPC包含有三个SM

三、专业术语
SPA: Streaming Processor Array 流处理器阵列
TPC/GPC:Texture/Graphics Processor Cluster 纹理/图像 处理簇,相当于把多个SM作为一个小组形成一个簇。
SM: Streaming Multiprocessor(每个SM包含32个Streaming Processor),是cuda线程块处理的基本单元。
SP:Streaming Processor ,为CUDA的core
四、Streaming MultiProcessor(SM)
整体结构由32个SP和4个SFU(Special Function Units)组成,不同的SP之间通过互连网络interconnected network,L1 Cache和warp Scheduler等结构进行相连。
warp是一个特殊的概念,实际中GPU上有多个线程,每32个线程称为一个warp,warp是并行结构中基本的运算单元,warp里面的所有线程都执行相同的命令。
在实际CUDA编程时,通常把线程按照grid,block,thread来组织,其中grid的大小相对没有限制,而block的大小限制根据不同的GPU结构有所不同,一般来说上限为1024。块中的每32个线程称为一个warp,每个warp中的线程共享指令,如果每个线程执行的指令不同,会影响执行效率,所以在实际设计的时候,要保持每个warp执行相同的指令,以此来提高效率。
SM中的 共享内存shared memory / L1 cache大小一般为64KB

五、 GPU程序架构
当我们书写一个核函数时,我们把所有的线程称为一个网格grid,每个网格由多个块组成,每个块由多个线程组成(1024上限)。由于warp为32个线程的特殊结构,所以块的大小最好为32的倍数。 在实际执行中,同一个block块在同一个SM上进行,不会跨SM进行处理。


六、 内存类型
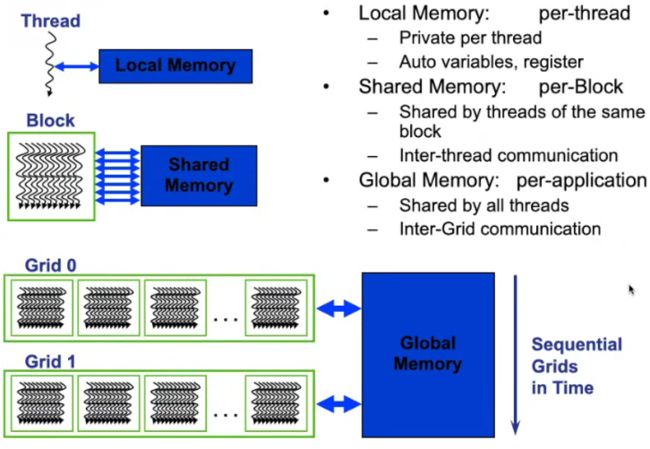
每一个线程都有自己的local memory局部内存。
每个块存在共享内存,这个共享内存的对象为同一个块内的所有线程,用于线程间的通信。共享内存的访问速度要远大于全局内存。
运行一个GPU程序的话,存在一个全局内存,这个全局内存是所有线程都可以进行访问的,但是访问全局内存的速度要远大于访问共享内存的速度。
不同的GPU含有不同大小的寄存器,寄存器的大小是固定的,如果每一个块需要的寄存器大小越大,那么活跃的块数量就会减少,这就使得并行度会下降,所以在设计程序的时候,要减少寄存器的使用。

共享内存是位于块内的,大小约为64KB。共享内存是有自己的划分方式的,每4个字节或者32个比特为一个bank。

以一个warp里面16个线程访问16个bank为例,如果每一个线程都访问不同的bank,那么这样的访问效率是最高的。如果16个线程中, 有不同的线程访问同一个bank,这就会造成bank conflict(我这里先初步理解为不同的线程访问同一个bank,要按照串行的方式进行访问,即一个线程访问完,另一个线程才能访问),串行的访问方式就会使得访问效率变低。
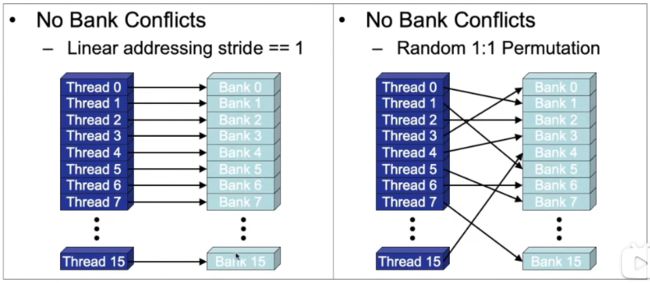

所以在设计GPU程序的时候,如果要使用共享内存,那么则要尽量避免多个线程访问同一个bank的情况,避免串行访问,从而提高并行度。

Bank Conflicts 的例子 - 向量求和的规约

假如我们用串行的方式进行向量求和,那么代码就是一个for循环,
for(int i = 0; i < nums.size(); i++){ sum += nums[i]}
但如果这个向量的长度较长,使用串行的方式就会大大的影响运行速度。使用并行计算的话则会提高运行速度,这里图中的方法为二叉树算法。但上图存在bank conflict,因为不同的线程可能会访问同一个bank。其解决方法如下图所示:
