C++初阶--缺省参数与函数重载
我们上篇文章讲了 << 流插入操作符 与 >>流提取操作符,现在我们再来回顾一下。
#include
using namespace std;
struct Student
{
char name[20];
int age;
};
int main()
{
// <<流插入
cout << "hello world" << endl;
const char* str = "hello world";
cout << str << endl;
int i = 1;
double d = 3.16;
cout << i << d << endl;
printf("%d%.2lf\n", i, d);
struct Student s = { "张三", 18 };
cout << "姓名:" << s.name << endl;
cout << "年龄:" << s.age << endl << endl;
printf("姓名:%s\n年龄:%d\n", s.name, s.age);
// >>流提取
cin >> s.name >> s.age;
cout << "姓名:" << s.name << endl;
cout << "年龄:" << s.age << endl << endl;
scanf("%s%d", s.name, &s.age);
printf("姓名:%s\n年龄:%d\n", s.name, s.age);
return 0;
} 这里我们不难看出,有时候用c语言中的scanf、printf更方便。因此,我们要学会灵活控制。
接下来我们开始学习今天的知识点--缺省参数。顾名思义,缺省参数也可以叫做默认参数,当我们给一个缺省值,那么当我们不传这个参数的时候,就用这个缺省参数。举一个简单例子
void Func(int a = 10)
{
cout << a << endl;
}
int main()
{
Func(1); // 1
Func(); // 10
return 0;
}缺省参数又分为全缺省与半缺省(缺省一部分)
//全缺省
void Func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func();
Func(1);
Func(1, 2);
Func(1, 2, 3);
return 0;
}我们需要注意的是,现在我们传参不能把第一个参数空下来传第二个。
//半缺省 缺省部分参数 必须从右往左缺省,必须连续缺省
//void Func(int a, int b = 20, int c = 30)
void Func(int a, int b, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func(1, 2);
Func(1, 2, 3);
return 0;
}我们需要注意的是,缺省参数是从右往左缺省,且是连续的。
那么缺省参数有什么用呢?我们举一个简单的例子:
struct Stack
{
int* a;
int top;
int capacity;
};
void StackInit(struct Stack* ps, int capacity = 4)
{
ps->a = (int*)malloc(sizeof(int)*capacity);
//判断
ps->top = 0;
ps->capacity = capacity;
}
int main()
{
struct Stack st;
//StackInit(&st); //不知道栈最多存多少数据,可以不传capacity 用缺省值初始化
StackInit(&st, 100); //知道栈最多存100数据,显示传值。可以减少增容次数,提高效率
return 0;
}下一个知识点:函数重载
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数、类型或顺序)不同,常用来处理实现功能类似数据类型不同的问题。
//1.参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}//2.参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}//3.参数顺序不同
void f(int a, char b)
{
cout << "f(int a, char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}我们要牢记这以上这三种情况。
下面我们来看看一些容易错的:
返回值不同,不能构成重载 调用的时候不能区分
//int f(double d)
//{
//}
//void f(double d)
//{
//}缺省值不同,不能构成重载
//void f(int a)
//{
// cout << "f()" << endl;
//}
//
//void f(int a = 0)
//{
// cout << "f(int a)" << endl;
//}构成重载,但使用时会有问题 f()调用存在歧义
//void f()
//{
//}
//void f(int a = 0)
//{
//}下面我们来讲讲函数重载的原理,我们在Linux系统下创建三个文件



当我们用gcc去编的时候会报错,当我们g++的编译器去编的时候就没问题。
在VS下,VS是根据文件后缀名去调用编译器,.c就调用c语言的编译器,.cpp就调用c++的编译器。
那么为什么c语言不支持函数重载而c++支持函数重载呢?c++是如何支持的?
我们来回顾一下编译器编译这个程序的过程:
func.h func.c test.c
1.预处理 --> 头文件展开,宏替换,条件编译,注释删除
func.i test.i
2.编译 --> 把c翻译成汇编代码,语法分析、词法分析、语义分析、符号汇总...
func.s test.s
3.汇编 --> 把汇编代码转换成二进制机器码 形成符号表
func.o test.o
4.链接 --> 合并段表,符号表的合并与重定位
.obj
机器码不方便看,我们用汇编来代替
c语言不支持重载,编译的时候,两个重载函数,函数名相同,在func.o符号表中存在冲突,链接的时候也存在冲突,因为他们都是使用函数名去标识和查找,而重载函数,函数名相同。
如果当前文件有函数的定义,那么编译是就填上地址,如果只有函数的声明,那么定义就在其他xxx.cpp中,编译的时候没有地址,只能链接的时候去xxx.o的符号表中根据函数名(函数修饰名字)去找。
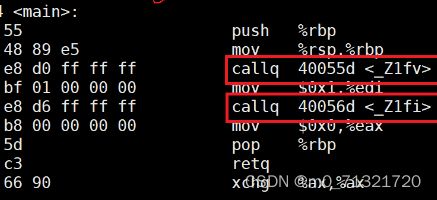
test.o
g++的修饰函数名规则(不同编译器对函数名的修饰规则不同):_Z+函数名长度+参数首字母,上面的函数修饰后是这样的,符号表中也是这样的
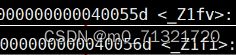
func.o
gcc编译后是这样的:
![]()
func.o
C++的目标文件符号表不是直接用函数名来标识和查找函数(c语言是按照函数名的),有了这个规则,链接的时候,test.o的main的函数里面去调用两个重载的函数查找地址时,也是明确的。
我们再来熟悉一下函数名修饰规则,下面这个函数名修饰后是:<_Z4funciPi>
