机器学习中参数优化调试方法
1 超参数优化
调参即超参数优化,是指从超参数空间中选择一组合适的超参数,以权衡好模型的偏差(bias)和方差(variance),从而提高模型效果及性能。常用的调参方法有:
-
人工手动调参
-
网格/随机搜索(Grid / Random Search)
-
贝叶斯优化(Bayesian Optimization)
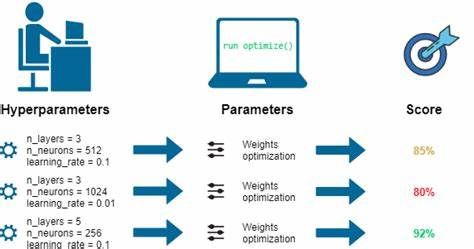
注:超参数 vs 模型参数差异 超参数是控制模型学习过程的(如网络层数、学习率);模型参数是通过模型训练学习后得到的(如网络最终学习到的权重值)。
2 人工调参
手动调参需要结合数据情况及算法的理解,选择合适调参的优先顺序及参数的经验值。
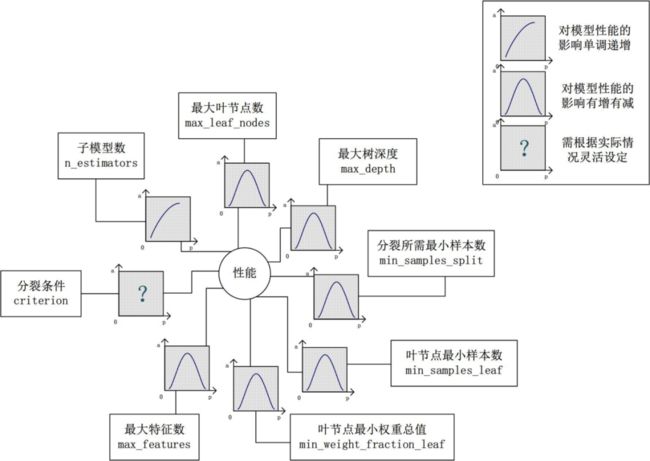
不同模型手动调参思路会有差异,如随机森林是一种bagging集成的方法,参数主要有n_estimators(子树的数量)、max_depth(树的最大生长深度)、max_leaf_nodes(最大叶节点数)等。(此外其他参数不展开说明) 对于n_estimators:通常越大效果越好。参数越大,则参与决策的子树越多,可以消除子树间的随机误差且增加预测的准度,以此降低方差与偏差。对于max_depth或max_leaf_nodes:通常对效果是先增后减的。取值越大则子树复杂度越高,偏差越低但方差越大。
3 网格/随机搜索
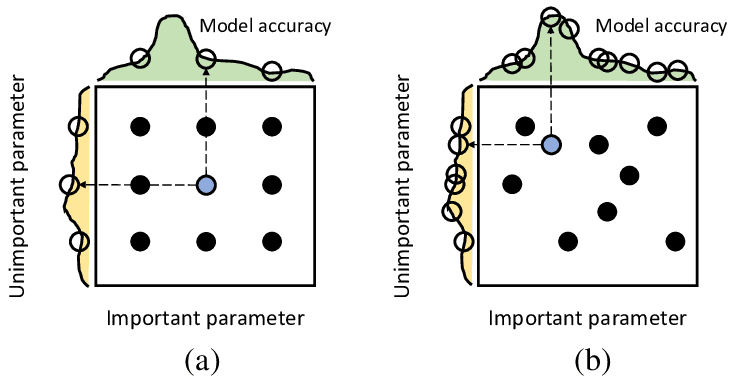
-
网格搜索(grid search),是超参数优化的传统方法,是对超参数组合的子集进行穷举搜索,找到表现最佳的超参数子集。
-
随机搜索(random search),是对超参数组合的子集简单地做固定次数的随机搜索,找到表现最佳的超参数子集。对于规模较大的参数空间,采用随机搜索往往效率更高。
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestClassifier
# 选择模型
model = RandomForestClassifier()
# 参数搜索空间
param_grid = {
'max_depth': np.arange(1, 20, 1),
'n_estimators': np.arange(1, 50, 10),
'max_leaf_nodes': np.arange(2, 100, 10)
}
# 网格搜索模型参数
grid_search = GridSearchCV(model, param_grid, cv=5, scoring='f1_micro')
grid_search.fit(x, y)
print(grid_search.best_params_)
print(grid_search.best_score_)
print(grid_search.best_estimator_)
# 随机搜索模型参数
rd_search = RandomizedSearchCV(model, param_grid, n_iter=200, cv=5, scoring='f1_micro')
rd_search.fit(x, y)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
4 贝叶斯优化
贝叶斯优化(Bayesian Optimization) 与网格/随机搜索最大的不同,在于考虑了历史调参的信息,使得调参更有效率。(但在高维参数空间下,贝叶斯优化复杂度较高,效果会近似随机搜索。)
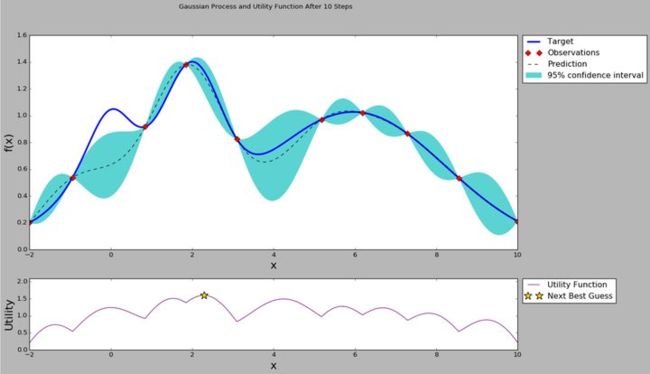
4.1 算法简介
贝叶斯优化思想简单可归纳为两部分:
-
高斯过程(GP):以历史的调参信息(Observation)去学习目标函数的后验分布(Target)的过程。
-
采集函数(AC):由学习的目标函数进行采样评估,分为两种过程:1、开采过程:在最可能出现全局最优解的参数区域进行采样评估。2、勘探过程:兼顾不确定性大的参数区域的采样评估,避免陷入局部最优。
4.2 算法流程
for循环n次迭代:
采集函数依据学习的目标函数(或初始化)给出下个开采极值点 Xn+1;
评估超参数Xn+1得到表现Yn+1;
加入新的Xn+1、Yn+1数据样本,并更新高斯过程模型;

"""
随机森林分类Iris使用贝叶斯优化调参
"""
import numpy as np
from hyperopt import hp, tpe, Trials, STATUS_OK, Trials, anneal
from functools import partial
from hyperopt.fmin import fmin
from sklearn.metrics import f1_score
from sklearn.ensemble import RandomForestClassifier
def model_metrics(model, x, y):
""" 评估指标 """
yhat = model.predict(x)
return f1_score(y, yhat,average='micro')
def bayes_fmin(train_x, test_x, train_y, test_y, eval_iters=50):
"""
bayes优化超参数
eval_iters:迭代次数
"""
def factory(params):
"""
定义优化的目标函数
"""
fit_params = {
'max_depth':int(params['max_depth']),
'n_estimators':int(params['n_estimators']),
'max_leaf_nodes': int(params['max_leaf_nodes'])
}
# 选择模型
model = RandomForestClassifier(**fit_params)
model.fit(train_x, train_y)
# 最小化测试集(- f1score)为目标
train_metric = model_metrics(model, train_x, train_y)
test_metric = model_metrics(model, test_x, test_y)
loss = - test_metric
return {"loss": loss, "status":STATUS_OK}
# 参数空间
space = {
'max_depth': hp.quniform('max_depth', 1, 20, 1),
'n_estimators': hp.quniform('n_estimators', 2, 50, 1),
'max_leaf_nodes': hp.quniform('max_leaf_nodes', 2, 100, 1)
}
# bayes优化搜索参数
best_params = fmin(factory, space, algo=partial(anneal.suggest,), max_evals=eval_iters, trials=Trials(),return_argmin=True)
# 参数转为整型
best_params["max_depth"] = int(best_params["max_depth"])
best_params["max_leaf_nodes"] = int(best_params["max_leaf_nodes"])
best_params["n_estimators"] = int(best_params["n_estimators"])
return best_params
# 搜索最优参数
best_params = bayes_fmin(train_x, test_x, train_y, test_y, 100)
print(best_params)