互联网Java工程师面试题·Java 总结篇·第九弹
目录
75、阐述 JDBC 操作数据库的步骤。
76、Statement 和 PreparedStatement 有什么区别?哪个性 能更好?
77、使用 JDBC 操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
78、在进行数据库编程时,连接池有什么作用?
79、什么是 DAO 模式?
80、事务的 ACID 是指什么?
81、JDBC 中如何进行事务处理?
75、阐述 JDBC 操作数据库的步骤。
下面的代码以连接本机的 Oracle 数据库为例,演示 JDBC 操作数据库的步骤。
加载驱动:
Class.forName("oracle.jdbc.driver.OracleDriver");创建连接:
Connection con =
DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:orcl",
"scott", "tiger");创建语句:
PreparedStatement ps = con.prepareStatement("select * from emp where sal between ? and ?");
ps.setInt(1, 1000);
ps.setInt(2, 3000);执行语句:
ResultSet rs = ps.executeQuery();处理结果:
while(rs.next()) {
System.out.println(rs.getInt("empno") + " - " + rs.getString("ename"));
}关闭资源:
finally {
if(con != null) {
try {
con.close();
}
}
catch (SQLException e) {
e.printStackTrace();
}
}提示:关闭外部资源的顺序应该和打开的顺序相反,也就是说先关闭 ResultSet、再关闭 Statement、在关闭 Connection。上面的代码只关闭了 Connection(连接),虽然通常情况下在关闭连接时,连接上创建的语句和打开的游标也会关闭,但不能保证总是如此,因此应该按照刚才说的顺序分别关闭。此外,第一步加载驱动在 JDBC 4.0 中是可以省略的(自动从类路径中加载驱动),但是我们建议保留。
76、Statement 和 PreparedStatement 有什么区别?哪个性 能更好?
与 Statement 相比,①PreparedStatement 接口代表预编译的语句,它主要的优势在于可以减少 SQL 的编译错误并增加 SQL 的安全性(减少 SQL 注射攻击的可能性);②PreparedStatement 中的 SQL 语句是可以带参数的,避免了用字符串连接拼接 SQL 语句的麻烦和不安全;③当批量处理 SQL 或频繁执行相同的查询时,PreparedStatement 有明显的性能上的优势,由于数据库可以将编译优化后的SQL 语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)。
补充:为了提供对存储过程的调用,JDBC API 中还提供了 CallableStatement 接口。存储过程(Stored Procedure)是数据库中一组为了完成特定功能的 SQL 语句的集合,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。虽然调用存储过程会在网络开销、安全性、性能上获得很多好处,但是存在如果底层数据库发生迁移时就会有很多麻烦,因为每种数据库的存储过程在书写上存在不少的差别。
77、使用 JDBC 操作数据库时,如何提升读取数据的性能?如何提升更新数据的性能?
要提升读取数据的性能,可以指定通过结果集(ResultSet)对象的 setFetchSize()方法指定每次抓取的记录数(典型的空间换时间策略);要提升更新数据的性能可以使用 PreparedStatement 语句构建批处理,将若干 SQL 语句置于一个批处理中执行。
78、在进行数据库编程时,连接池有什么作用?
由于创建连接和释放连接都有很大的开销(尤其是数据库服务器不在本地时,每次建立连接都需要进行 TCP 的三次握手,释放连接需要进行 TCP 四次握手,造成的开销是不可忽视的),为了提升系统访问数据库的性能,可以事先创建若干连接置于连接池中,需要时直接从连接池获取,使用结束时归还连接池而不必关闭连接,从而避免频繁创建和释放连接所造成的开销,这是典型的用空间换取时间的策略(浪费了空间存储连接,但节省了创建和释放连接的时间)。池化技术在Java 开发中是很常见的,在使用线程时创建线程池的道理与此相同。基于 Java 的开源数据库连接池主要有:C3P0、Proxool、DBCP、BoneCP、Druid 等。
补充:在计算机系统中时间和空间是不可调和的矛盾,理解这一点对设计满足性能要求的算法是至关重要的。大型网站性能优化的一个关键就是使用缓存,而缓存跟上面讲的连接池道理非常类似,也是使用空间换时间的策略。可以将热点数据置于缓存中,当用户查询这些数据时可以直接从缓存中得到,这无论如何也快过去数据库中查询。当然,缓存的置换策略等也会对系统性能产生重要影响,对于这个问题的讨论已经超出了这里要阐述的范围。
79、什么是 DAO 模式?
DAO(Data Access Object)顾名思义是一个为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共 API 中。用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。DAO 模式实际上包含了两个模式,一是 DataAccessor(数据访问器),二是 Data Object(数据对象),前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
80、事务的 ACID 是指什么?
原子性(Atomic):事务中各项操作,要么全做要么全不做,任何一项操作的失败都会导致整个事务的失败;
一致性(Consistent):事务结束后系统状态是一致的;
隔离性(Isolated):并发执行的事务彼此无法看到对方的中间状态;
持久性(Durable):事务完成后所做的改动都会被持久化,即使发生灾难性的失败。通过日志和同步备份可以在故障发生后重建数据。
补充:关于事务,在面试中被问到的概率是很高的,可以问的问题也是很多的。首先需要知道的是,只有存在并发数据访问时才需要事务。当多个事务访问同一数据时,可能会存在 5 类问题,包括 3 类数据读取问题(脏读、不可重复读和幻读)和 2 类数据更新问题(第 1 类丢失更新和第 2 类丢失更新)。脏读(Dirty Read):A 事务读取 B 事务尚未提交的数据并在此基础上操作,而 B事务执行回滚,那么 A 读取到的数据就是脏数据。
|
时间
|
转账事务 A
|
取款事务 B
|
|
T1
|
开始事务
|
|
|
T2
|
开始事务
|
|
|
T3
|
查询账户余额为 1000 元
|
|
|
T4
|
取出 500 元余额修改为 500 元
|
|
|
T5
|
查询账户余额为 500 元(脏读)
|
|
|
T6
|
撤销事务余额恢复为 1000 元
|
|
|
T7
|
汇入 100 元把余额修改为 600 元
|
|
|
T8
|
提交事务
|
不可重复读(Unrepeatable Read):事务 A 重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务 B 修改过了。
|
时间
|
转账事务 A
|
取款事务 B
|
|
T1
|
开始事务
|
|
|
T2
|
开始事务
|
|
|
T3
|
查询账户余额为 1000 元
|
|
|
T4
|
查询账户余额为 1000 元
|
|
|
T5
|
取出 100 元修改余额为 900 元
|
|
|
T6
|
提交事务
|
|
|
T7
|
查询账户余额为 900 元(不可重复读)
|
幻读(Phantom Read):事务 A 重新执行一个查询,返回一系列符合查询条件的行,发现其中插入了被事务 B 提交的行。
|
时间
|
转账事务 A
|
取款事务 B
|
|
T1
|
开始事务
|
|
|
T2
|
开始事务
|
|
|
T3
|
统计总存款为 10000 元
|
|
|
T4
|
新增一个存款账户存入 100 元 | |
|
T5
|
提交事务
|
|
|
T6
|
再次统计总存款为 10100 元(幻读)
|
第 1 类丢失更新:事务 A 撤销时,把已经提交的事务 B 的更新数据覆盖了。
|
时间
|
转账事务 A
|
取款事务 B
|
|
T1
|
开始事务
|
|
|
T2
|
开始事务
|
|
|
T3
|
查询账户余额为 1000 元
|
|
|
T4
|
查询账户余额为 1000 元
|
|
|
T5
|
汇入 100 元修改余额为 1100 元
|
|
|
T6
|
提交事务
|
|
|
T7
|
取出 100 元将余额修改为 900 元
|
|
|
T8
|
撤销事务
|
|
|
T9
|
余额恢复为 1000 元(丢失更新)
|
第 2 类丢失更新:事务 A 覆盖事务 B 已经提交的数据,造成事务 B 所做的操作丢失。
|
时间
|
转账事务 A
|
取款事务 B
|
|
T1
|
开始事务 | |
|
T2
|
开始事务 | |
|
T3
|
查询账户余额为 1000 元 | |
|
T4
|
查询账户余额为 1000 元 | |
|
T5
|
取出 100 元将余额修改为 900 元
|
|
|
T6
|
提交事务
|
|
|
T7
|
汇入 100 元修改余额为 1100 元
|
|
|
T8
|
提交事务 | |
|
T9
|
余额恢复为 1100 元(丢失更新)
|
数据并发访问所产生的问题,在有些场景下可能是允许的,但是有些场景下可能就是致命的,数据库通常会通过锁机制来解决数据并发访问问题,按锁定对象不同可以分为表级锁和行级锁;按并发事务锁定关系可以分为共享锁和独占锁,具体的内容大家可以自行查阅资料进行了解。直接使用锁是非常麻烦的,为此数据库为用户提供了自动锁机制,只要用户指定会话的事务隔离级别,数据库就会通过分析 SQL 语句然后为事务访问的资源加上合适的锁,此外,数据库还会维护这些锁通过各种手段提高系统的性能,这些对用户来说都是透明的(就是说你不用理解,事实上我确实也不知道)。ANSI/ISOSQL 92 标准定义了 4 个等级的事务隔离级别,如下表所示:
|
隔离级别
|
脏读
|
不可重复读
|
幻读
|
第一类丢失更新
|
第二类丢失更新
|
|
READ
UNCOMMITED
|
允许
|
允许
|
允许
|
不允许
|
允许
|
|
READ
COMMITTED
|
不允许
|
允许
|
允许
|
不允许
|
允许
|
|
REPEATABLE
READ
|
不允许
|
不允许
|
允许
|
不允许
|
不允许
|
|
SERIALIZABLE
|
不允许
|
不允许
|
不允许
|
不允许
|
不允许
|
需要说明的是,事务隔离级别和数据访问的并发性是对立的,事务隔离级别越高并发性就越差。所以要根据具体的应用来确定合适的事务隔离级别,这个地方没有万能的原则。
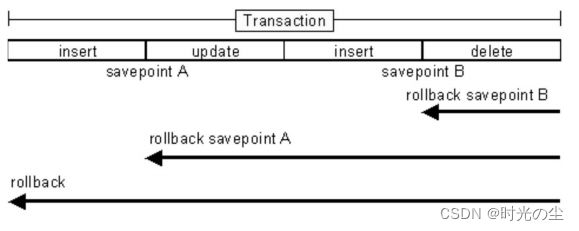
81、JDBC 中如何进行事务处理?
Connection 提供了事务处理的方法,通过调用 setAutoCommit(false)可以设置手动提交事务;当事务完成后用 commit()显式提交事务;如果在事务处理过程中发生异常则通过 rollback()进行事务回滚。除此之外,从 JDBC 3.0 中还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点。
要想了解更多:
千题千解·Java面试宝典_时光の尘的博客-CSDN博客