YOLOv5训练自定义模型 训练
说明:
1、训练过程请参考官网:https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
2、本课使用的是YOLOv5 6.1版本,其他版本训练过程可能有不同,请以官网为准
3、硬件:Windows 11 、GPU GeForce 3070Ti(8G)
YOLOv5训练自定义模型
一、安装Pytorch 及 YOLO v5
1.1 安装pytorch GPU版
1.1.1 准备工作
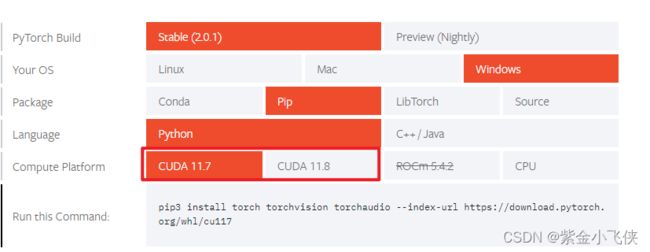
先去pytorch官网查看支持的最高CUDA版本;
pytorch
最新版:https://pytorch.org/get-started/locally/
历史版本:https://pytorch.org/get-started/previous-versions/
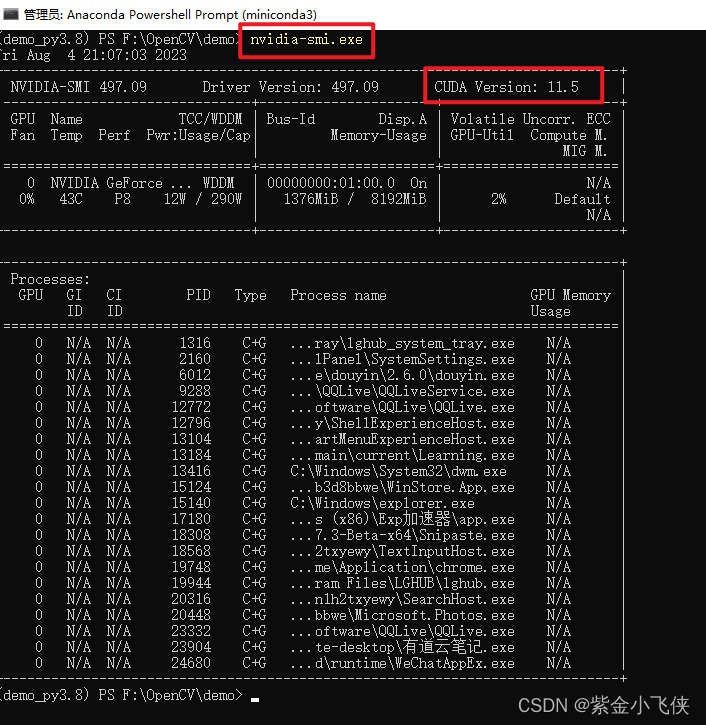
再查看所需CUDA版本对应的显卡驱动版本:
查看自己显卡最高支持的cuda 的版本
nvidia-smi.exe
我的显卡驱动版本是497.09 支持的cuda最高版本是11.5
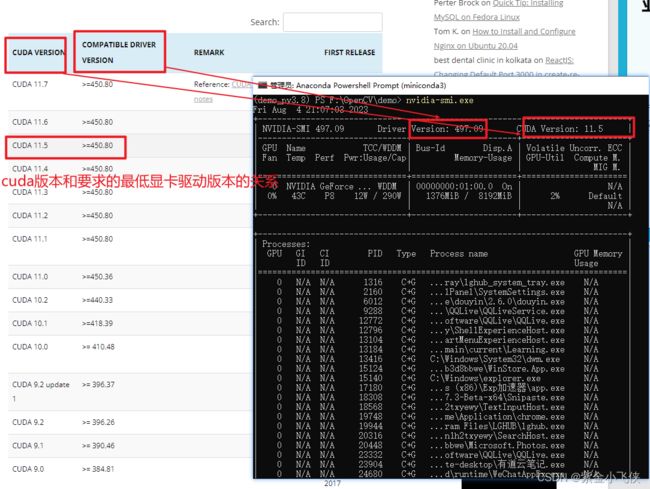
查看cuda版本和显卡驱动的对应关系:
https://tech.amikelive.com/node-930/cuda-compatibility-of-nvidia-display-gpu-drivers/
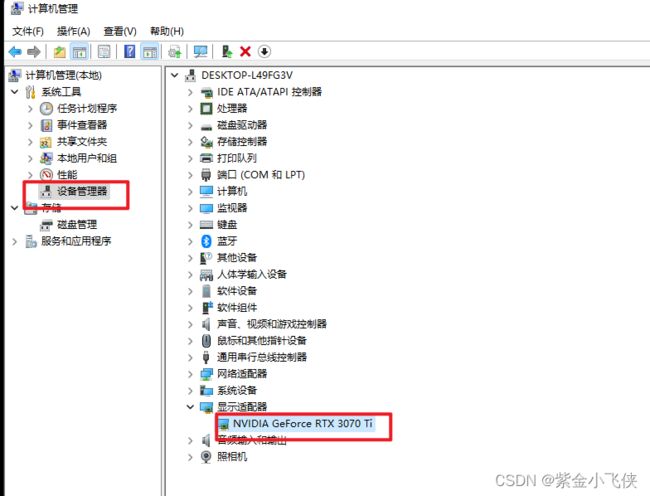
下载显卡对应版本驱动:
查看自己机器的显卡型号
最新版显卡驱动:https://www.nvidia.com/download/index.aspx
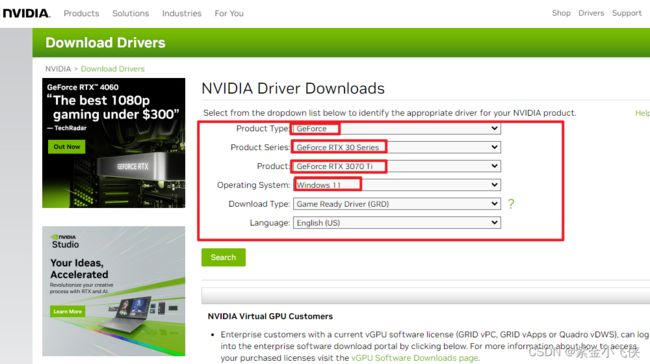
其他历史版本显卡驱动:https://www.nvidia.com/Download/Find.aspx
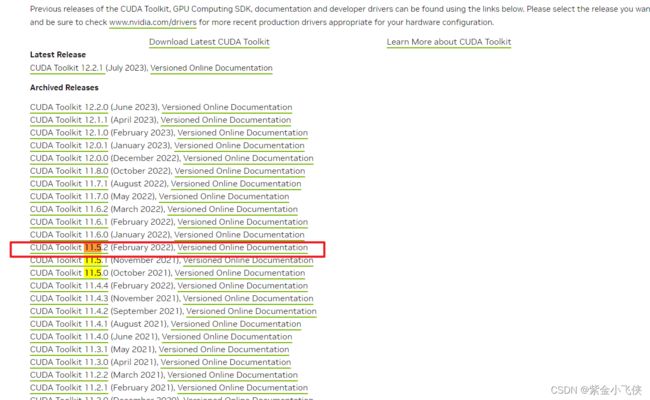
下载对应版本CUDA:
官网:https://developer.nvidia.com/cuda-toolkit-archive
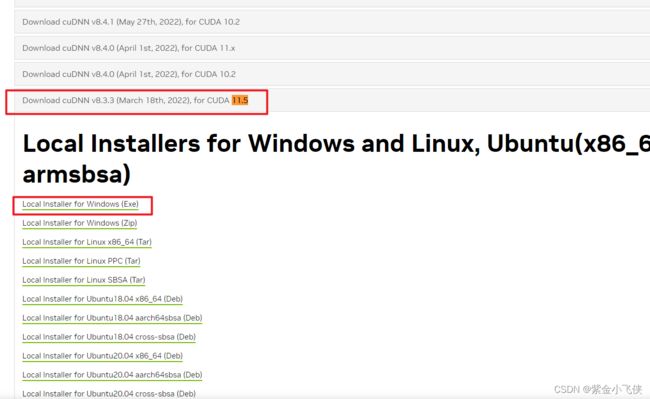
下载对应版本cuDNN
参考TensorFlow GPU支持CUDA列表:https://www.tensorflow.org/install/source_windows?hl=zh-cn
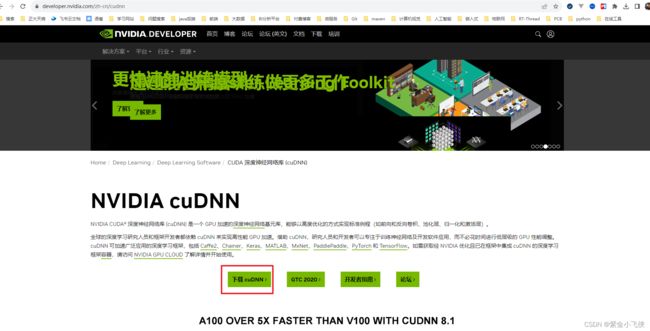
查看cuDNN和CUDA支持对应版本号
cudnn官网:https://developer.nvidia.com/zh-cn/cudnn
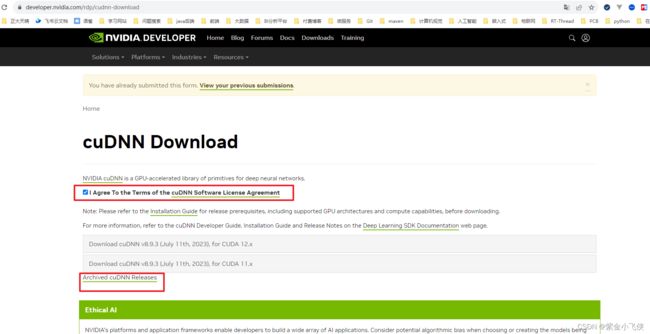
下载VS studio:https://visualstudio.microsoft.com/zh-hans/
-
VS studio:安装社区版即可
-
安装顺序:
-
VS studio:安装社区版即可
-
显卡驱动:安装完重启电脑可以使用
nvidia-smi查看显卡信息 -
CUDA:按流程安装即可
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5 -
cudnn:
-
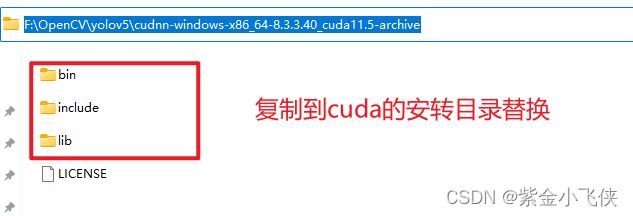
解压cudnn压缩文件:
-
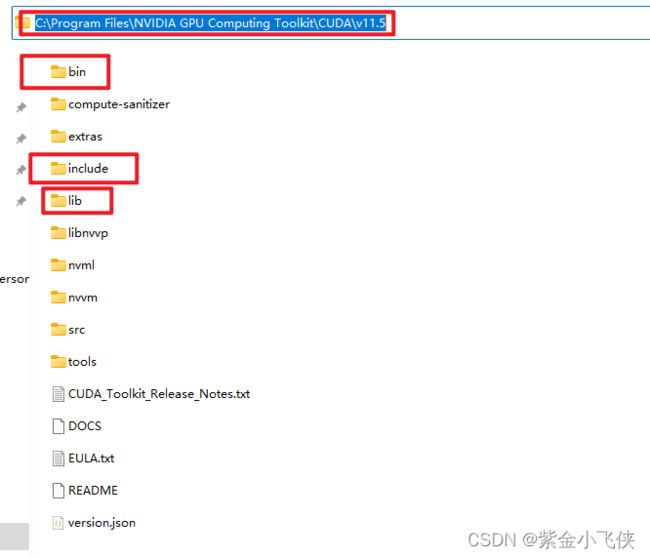
进入cuda目录,将cudnn所有文件复制并替换
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5
-
-
https://zhuanlan.zhihu.com/p/460806048
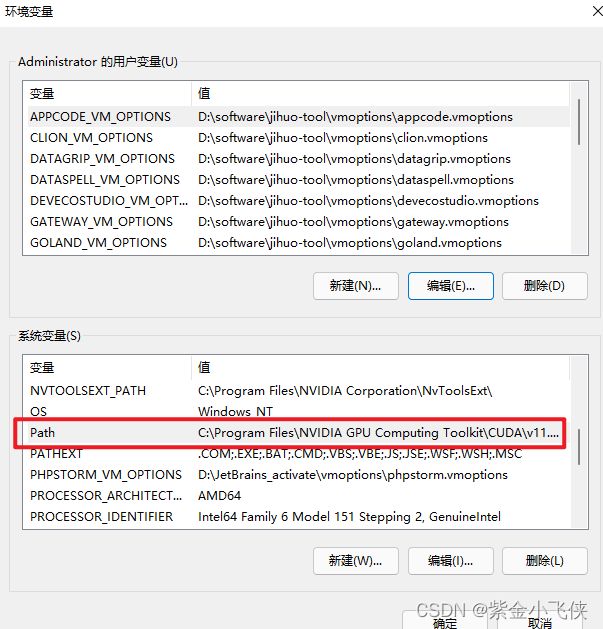
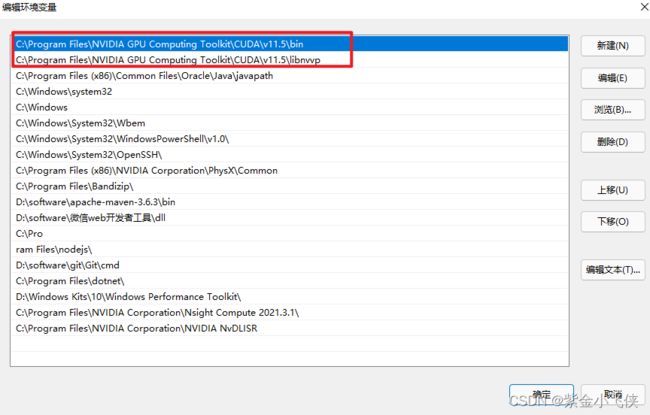
* 如我的cuda目录位置为:`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1`
* 更改环境变量:
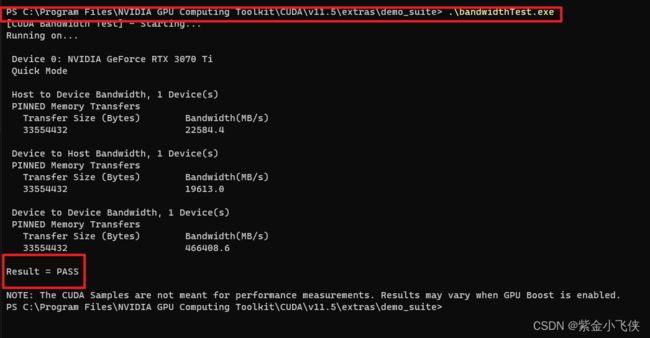
验证cuda是否安装成功
验证cuda是否安装成功,首先win+R启动cmd,进入到CUDA安装目录下的C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.5\extras\demo_suite然后分别运行bandwidthTest.exe和deviceQuery.exe,应该得到图28,返回Result=PASS表示cuda安装成功。图28中只运行了bandwidthTest.exe,同样运行deviceQuery.exe也可得到PASS。
* 双击path
 * 新建2个路径(cuda bin、libnvvp)
* 如我的路径为:`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin`和`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp`
* 新建2个路径(cuda bin、libnvvp)
* 如我的路径为:`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\bin`和`C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\libnvvp`

- 重启电脑
1.1.2 安装pytorch
创建conda虚拟环境,参考你选择的版本安装即可
- 最新版:https://pytorch.org/get-started/locally/
- 历史版本:https://pytorch.org/get-started/previous-versions/
pip install torch1.12.1+cu113 torchvision0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
验证 PyTorch是否安装成功
打开Anaconda prompt命令窗口,激活环境,输入python,进入python开发环境中
1.import torch
2.torch.cuda.is_available()
1.True

1.2 安装YOLO v5
- 安装
https://github.com/ultralytics/yolov5
# 克隆地址
git clone https://github.com/ultralytics/yolov5.git
# 如果下载速度慢,参考课程附件:
Windows软件/yolov5-master.zip
# 进入目录
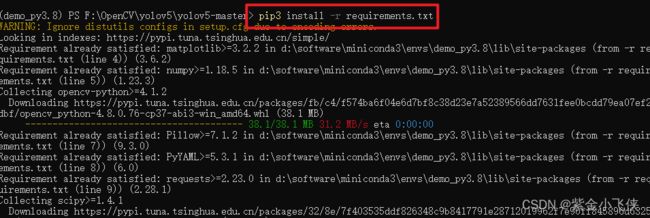
在yolov5-master目录中执行下面命令
# 安装依赖
pip3 install -r requirements.txt
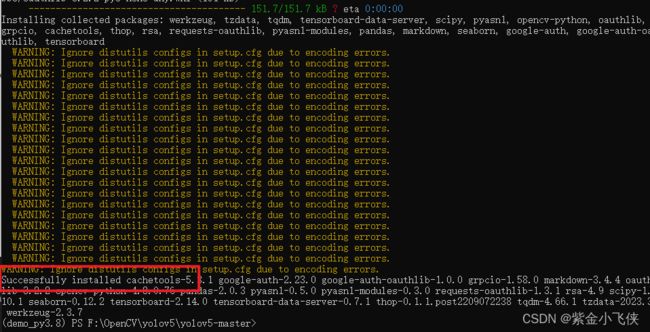
- 下载预训练权重文件
下载地址:https://github.com/ultralytics/yolov5/releases
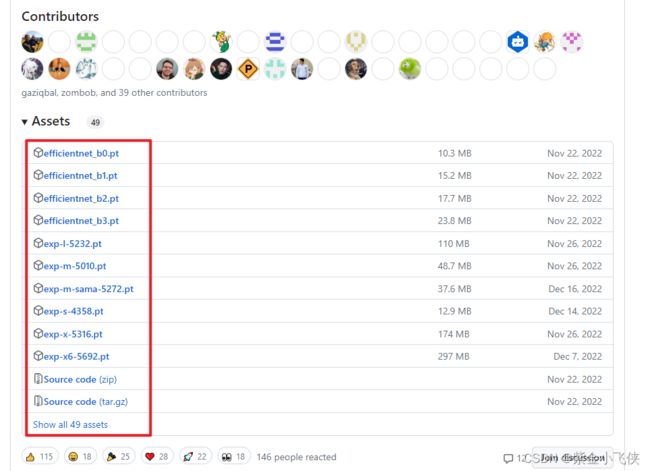
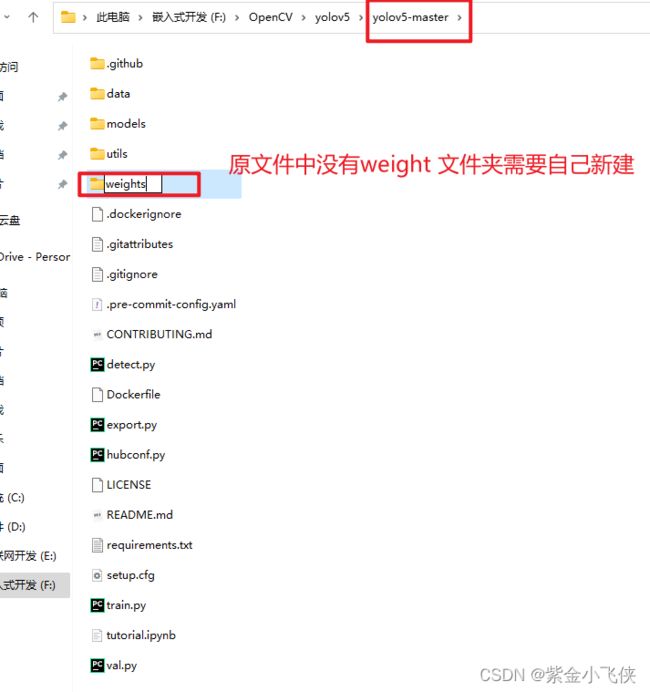
在yolov5-master新建weights文件夹, 将下载权重文件放到weights文件夹中

- 测试安装
在yolov5-master目录中执行下面命令
python detect.py --source ./data/images/ --weights weights/yolov5s.pt --conf-thres 0.4
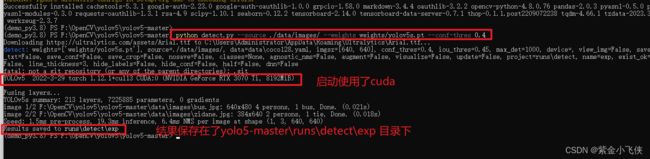
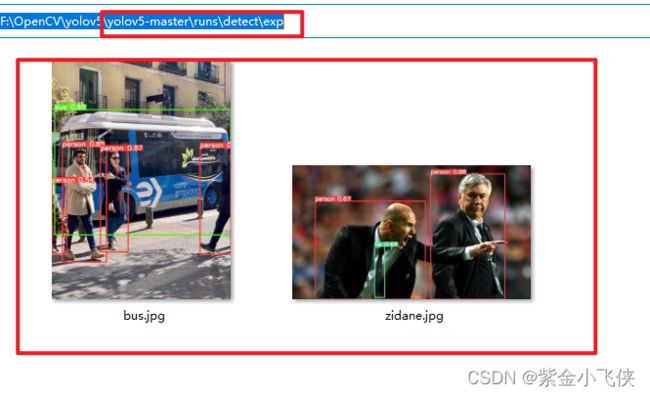
到此说明环境安装成功
二、YOLO v5训练自定义数据
2.1 准备数据集
2.1.1 创建 dataset.yaml
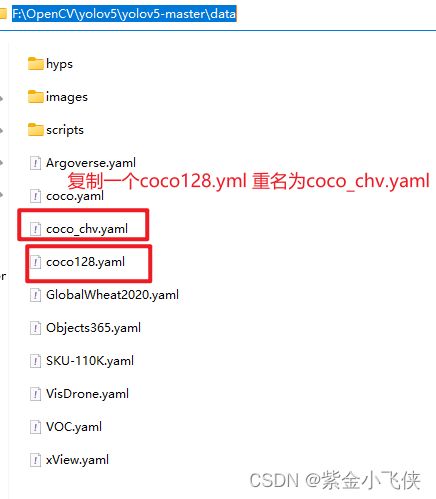
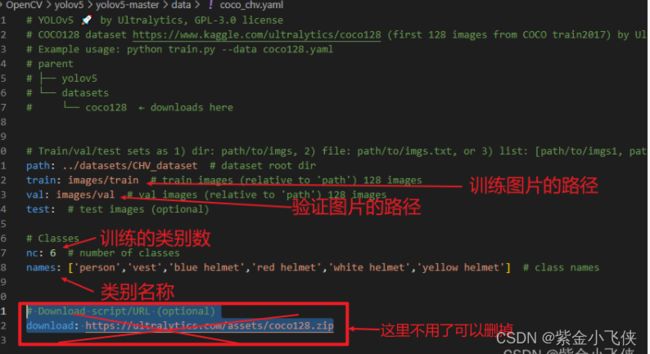
复制yolov5-master/data/coco128.yaml一份,比如为coco_chv.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
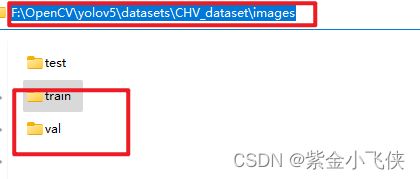
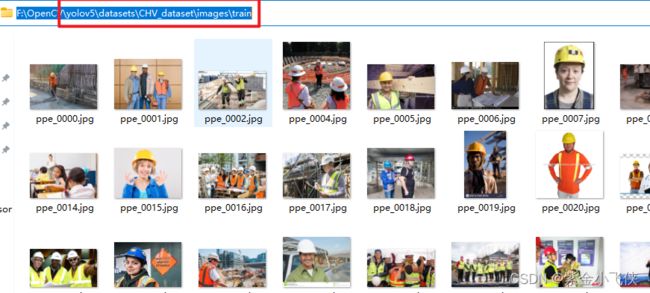
path: ../datasets/CHV_dataset # 数据所在目录
train: images/train # 训练集图片所在位置(相对于path)
val: images/val # 验证集图片所在位置(相对于path)
test: # 测试集图片所在位置(相对于path)(可选)
# 类别
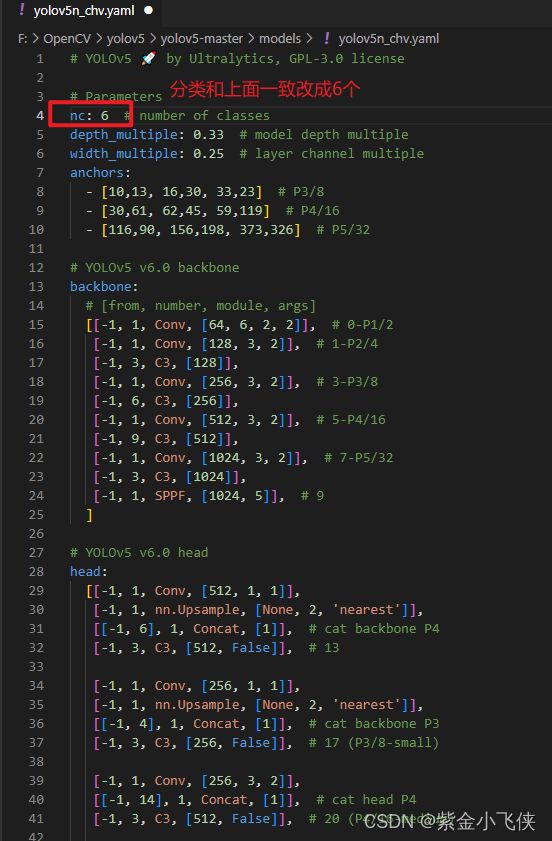
nc: 6 # 类别数量
names: ['person','vest','blue helmet','red helmet','white helmet','yellow helmet'] # 类别标签名
2.1.2 标注图片
使用LabelImg等标注工具标注图片(需要支持YOLO格式)
LabelImg下载地址 https://github.com/tzutalin/labelImg)
百度网盘:
链接:https://pan.baidu.com/s/1V_T65uKo9r445NZ2FwLvZA
提取码:forc
使用參考教程:
https://zhuanlan.zhihu.com/p/550021453
labelimg的标注模式分为VOC和YOLO两种,两种模式下生成的标注文件分别为.xml文件和.txt文件,因此在进行标注前需要优先选择好标注的模式。

YOLO格式标签:

- 一个图一个txt标注文件(如果图中无所要物体,则无需txt文件);
- 每行一个物体;
- 每行数据格式:
类别id、x_center y_center width height; - xywh必须归一化(0-1),其中
x_center、width除以图片宽度,y_center、height除以画面高度; - 类别id必须从0开始计数
2.1.3 组织目录结构
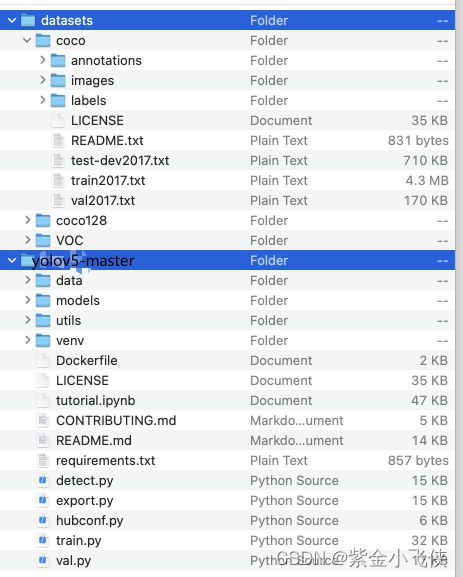
datasets与yolov5-master同级目录;- YOLO会自动将
../datasets/CHV_dataset/images/train/ppe_1106.jpg中的/images/替换成/labels/以寻找它的标签,如../datasets/CHV_dataset/labels/train/ppe_1106.txt,所以根据这个原则,我们一般可以:images文件夹下有train和val文件夹,分别放置训练集和验证集图片;labels文件夹有train和val文件夹,分别放置训练集和验证集标签(yolo格式);
2.2 选择合适的预训练模型
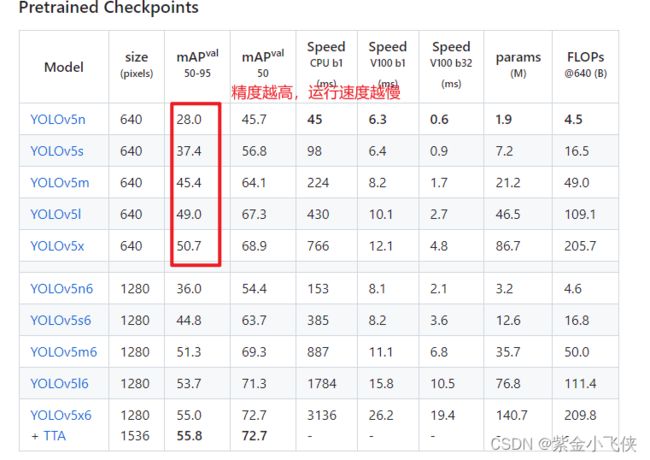
根据你的设备,选择合适的预训练模型,具体模型比对如下:
模型下载地址
https://github.com/ultralytics/yolov5
复制models下对应模型的yaml文件,重命名,并修改其中:
nc: 6 # 类别数量
2.3 训练
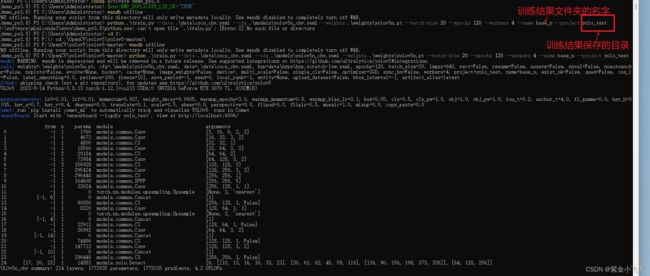
下载对应的预训练模型权重文件,可以放到weights目录下,设置本机最好性能的各个参数,即可开始训练,课程中训练了以下参数:
# yolov5n
python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5n_chv.yaml --weights .\weights\yolov5n.pt --batch-size 20 --epochs 120 --workers 4 --name base_n --project yolo_test
# yolov5s
python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5s_chv.yaml --weights .\weights\yolov5s.pt --batch-size 16 --epochs 120 --workers 4 --name base_s --project yolo_test
# yolov5m
python .\train.py --data .\data\coco_chv.yaml --cfg .\models\yolov5m_chv.yaml --weights .\weights\yolov5m.pt --batch-size 12 --epochs 120 --workers 4 --name base_m --project yolo_test
# yolov5n6 1280
python .\train.py --data .\data\coco_chv.yaml --img-size 1280 --cfg .\models\yolov5n6_chv.yaml --weights .\weights\yolov5n6.pt --batch-size 20 --epochs 120 --workers 4 --name base_n6 --project yolo_test
更多参数见train.py;
训练结果在runs/train/中可见,一般训练时间在几个小时以上。
开始训练
训练时不要
训练完成
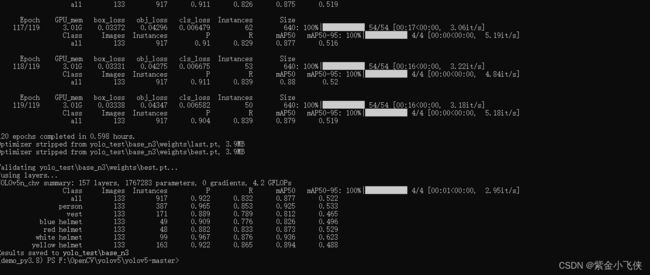
训练结果
2.4 可视化
2.4.1 wandb
YOLO官网推荐使用https://wandb.ai/。
-
使用
pip install wandb安装扩展包;
153f2c145f0b461849d0a587e2ac2200151130be

-
去官网注册账号;
-
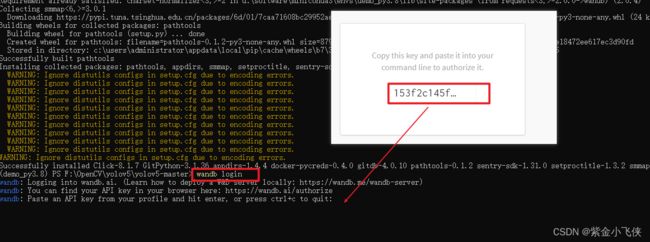
训练的时候填写
key秘钥,地址:
-
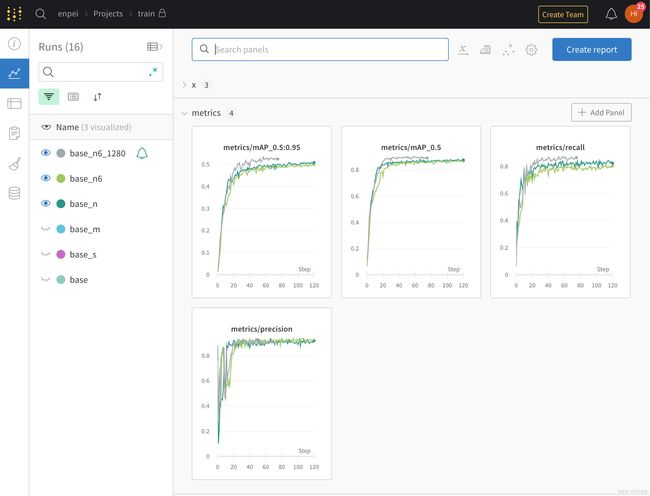
打开网站即可查看训练进展。
关闭wandb
wandb offline
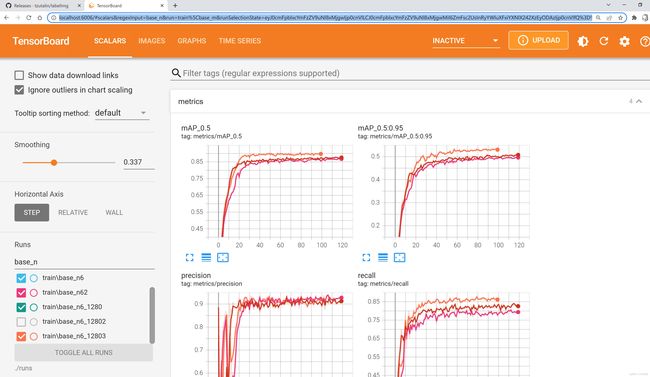
2.4.2 Tensorboard
tensorboard --logdir=./runs
2.3 测试评估模型
2.3.1 测试
Usage - sources:
$ python path/to/detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
# 如
python detect.py --source ./test_img/img1.jpg --weights runs/train/base_n/weights/best.pt --conf-thres 0.3
# 或
python detect.py --source 0 --weights runs/train/base_n/weights/best.pt --conf-thres 0.3
2.3.2 评估
# n
# python val.py --data ./data/coco_chv.yaml --weights runs/train/base_n/weights/best.pt --batch-size 12
# 4.3 GFLOPs
Class Images Labels P R [email protected] [email protected]:.95
all 133 1084 0.88 0.823 0.868 0.479
person 133 450 0.899 0.808 0.877 0.484
vest 133 217 0.905 0.788 0.833 0.468
blue helmet 133 44 0.811 0.75 0.803 0.489
red helmet 133 50 0.865 0.9 0.898 0.425
white helmet 133 176 0.877 0.807 0.883 0.467
yellow helmet 133 147 0.922 0.885 0.917 0.543
Speed: 0.2ms pre-process, 4.7ms inference, 3.9ms NMS per image at shape (12, 3, 640, 640)
# s
# python val.py --data ./data/coco_chv.yaml --weights runs/train/base_s/weights/best.pt --batch-size 12
# 15.8 GFLOPs
Class Images Labels P R [email protected] [email protected]:.95
all 133 1084 0.894 0.848 0.883 0.496
person 133 450 0.915 0.84 0.887 0.508
vest 133 217 0.928 0.834 0.877 0.501
blue helmet 133 44 0.831 0.75 0.791 0.428
red helmet 133 50 0.9 0.899 0.901 0.473
white helmet 133 176 0.884 0.858 0.91 0.496
yellow helmet 133 147 0.908 0.905 0.93 0.567
Speed: 0.2ms pre-process, 8.3ms inference, 3.9ms NMS per image at shape (12, 3, 640, 640)
# m
# python val.py --data ./data/coco_chv.yaml --weights runs/train/base_m/weights/best.pt --batch-size 12
# 48.0 GFLOPs
Class Images Labels P R [email protected] [email protected]:.95
all 133 1084 0.928 0.845 0.886 0.512
person 133 450 0.935 0.794 0.895 0.529
vest 133 217 0.922 0.813 0.868 0.508
blue helmet 133 44 0.916 0.818 0.812 0.464
red helmet 133 50 0.9 0.9 0.892 0.488
white helmet 133 176 0.932 0.841 0.899 0.511
yellow helmet 133 147 0.964 0.905 0.948 0.574
Speed: 0.4ms pre-process, 18.8ms inference, 4.6ms NMS per image at shape (12, 3, 640, 640)
# n6 1280 :
# python val.py --data ./data/coco_chv.yaml --weights runs/train/base_n6_1280/weights/best.pt --batch-size 12 --img-size 1280
# 4.3 GFLOPs
Class Images Labels P R [email protected] [email protected]:.95
all 133 1084 0.906 0.858 0.901 0.507
person 133 450 0.903 0.831 0.887 0.503
vest 133 217 0.922 0.816 0.86 0.486
blue helmet 133 44 0.843 0.795 0.828 0.465
red helmet 133 50 0.899 0.92 0.954 0.507
white helmet 133 176 0.921 0.865 0.925 0.515
yellow helmet 133 147 0.947 0.918 0.954 0.566
Speed: 1.5ms pre-process, 14.1ms inference, 2.2ms NMS per image at shape (12, 3, 1280, 1280)
三、得到最优的训练结果
参考:https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results
3.1 数据:
- 每类图片:建议>=1500张;
- 每类实例(标注的物体):建议>=10000个;
- 图片采样:真实图片建议在一天中不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(爬虫抓取、手动采集、不同相机源)等场景下采集;
- 标注:
- 所有图片上所有类别的对应物体都需要标注上,不可以只标注部分;
- 标注尽量闭合物体,边界框与物体无空隙,所有类别对应物体不能缺少标签;
- 背景图:背景图用于减少假阳性预测(False Positive),建议提供0~10%样本总量的背景图,背景图无需标注;
3.2 模型选择
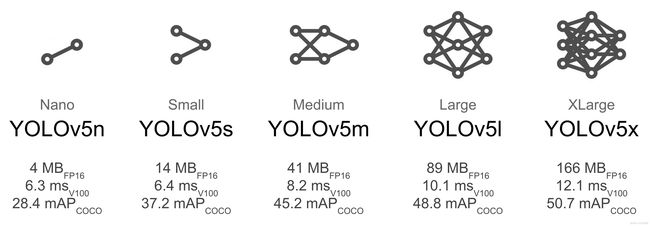
模型越大一般预测结果越好,但相应的计算量越大,训练和运行起来都会慢一点,建议:
- 在移动端(手机、嵌入式)选择:YOLOv5n/s/m
- 云端(服务器)选择:YOLOv5l/x
3.3 训练
- 对于小样本、中样本,建议试用预训练模型开始训练:
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt
- 对于大样本,建议从0开始训练(无需预训练模型):
# --weights ''
python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml
- Epochs:初始设定为300,如果很早就过拟合,减少epoch,如果到300还没过拟合,设置更大的数值,如600, 1200等;
- 图像尺寸:训练时默认为
--img 640,如果希望检测出画面中的小目标,可以设为--img 1280(检测时也需要设为--img 1280才能起到一样的效果) - Batch size:选择你硬件能承受的最大
--batch-size; - 超参数(Hyperparameters):初次训练暂时不要改,具体参见https://github.com/ultralytics/yolov5/issues/607
- 更多:官网建议 查看http://karpathy.github.io/2019/04/25/recipe/
错误
-
OpenMP错误: 日志中多次提到
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.,这是一个与OpenMP并行框架有关的错误。出现这个错误的原因可能是因为您的环境中有多个版本的OpenMP。您可以尝试设置环境变量KMP_DUPLICATE_LIB_OK=TRUE来解决这个问题,但这只是一个临时的解决方法。最佳的做法是确保只有一个OpenMP运行时链接到进程中。 -
SSL错误: 日志中提到了
SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1131)')),这是与SSL连接有关的错误。可能的原因包括:服务器或中间代理意外关闭了连接、网络问题、证书问题等。这个问题可能需要更多的调查。
针对上述问题,我提供以下建议:
-
解决OpenMP错误:
- 在启动Python脚本之前,尝试设置环境变量:
或在Windows下:export KMP_DUPLICATE_LIB_OK=TRUE$env:KMP_DUPLICATE_LIB_OK="TRUE"
- 在启动Python脚本之前,尝试设置环境变量:
-
解决SSL错误:
- 如果您在某个特定网络环境下工作,例如公司网络,尝试更换网络或使用VPN。
- 确保您使用的Python和相关的库是最新的。尤其是
requests和urllib3这两个库,它们经常因为SSL问题被更新。 - 如果您尝试连接的是一个您知道的安全的服务器,但仍然收到SSL错误,您可以考虑禁用SSL证书验证(尽管这样做会带来安全风险)。例如,如果您使用的是
requests库,您可以在请求中设置verify=False。
希望上述建议对您有所帮助。如果您有其他问题或需要进一步的帮助,请随时告诉我。