【网络】用代码讲解协议 + 序列化和反序列化 + 守护进程 + jsoncpp
协议
- 前言
- 正式开始
-
- 简易网络版本计算器
-
- 稍有瑕疵的计算器
-
- 完整代码(Protocol.hpp最重要)
-
- Protocol.hpp
- sock.hpp
- TcpServer.hpp
- CalServer.cc
- CalClient.cc
- 运行测试
- 协议的体现
- 问题
- 优化协议
-
- 思路
- 代码
- 运行结果
- 守护进程
- json
-
- json的使用
- 用json进行服务器中数据的序列化和反序列化
前言
本篇重点讲解内容:
- 什么是协议
- 序列化和反序列化
- 守护进程
- jsoncpp
本篇涉及到的大部分套接字编程相关的接口我已经在我前面两篇博客中讲过了,不篇中不会再详谈这些接口的含义及其作用,如果遇到不懂的接口,请看我前两篇的博客:
【网络】网络编程入门篇——了解接口,快速上手,带你手搓简易UDP服务器和客户端(简易远端shell、简易群聊功能以及跨平台群聊)
【网络】网络编程——带你手搓简易TCP服务端(echo服务器)+客户端(四种版本)
如果有遇到新的接口我会再细讲。
正式开始
前面两篇无论是在手搓UDP的服务器还是手搓TCP的服务器,里面套接字相关的接口都是传输层经过TCP和UDP数据发送能力的包装,以文件的形式呈现给了我们,让我们能够进行应用层编程。也就是说前面两篇博客中写的套接字代码都是属于应用层编程。不过前面在编写代码的时候没有涉及到具体协议定制的问题,只是在用套接字进行数据的收发和测试。
那么本篇会基于前面TCP服务器添加一个协议,通过代码来具体的讲解协议是什么。
我前面的博客中讲过:协议是一种 “约定”。socket api的接口, 在读写数据时, 都是按 “字符串” 的方式来发送接收的。
但如果我们要传输一些"结构化的数据" 怎么办呢?
我这里通过一个例子来说说。
简易网络版本计算器
这里这个网络版本计算器主要是讲解一下协议在代码中的体现,我这里还是写简易服务器。通过这个服务器中的代码来体现出协议是什么。
例如, 我们需要实现一个服务器版的简易计算器。能进行+、-、*、/、%这几个简易运算。
我们需要客户端把要计算的两个数和一个运算符符发过去, 然后由服务器进行计算, 最后再把结果返回给客户端。
我们可以约定客户端发送数据的方式,而且可以约定很多种,这里就先只说说两种:
约定方案一:
- 客户端发送一个形如"1+1"的字符串;
- 这个字符串中有两个操作数, 都是整形;
- 两个数字之间会有一个字符是运算符, 运算符只能是上面的几个;
- 数字和运算符之间没有空格;
如:1+1或4*20等等。
约定方案二:
- 定义结构体来表示我们需要交互的信息;
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;
比如下面这个结构体:
struct Request {
int a; // 一个操作数
int b; // 另一个操作数
char op; // 操作符
};
如果要进行传输,客户端需要先将各个字段放到这个Request对象中,然后再将这个对象中的数据转成字符串交给服务端比如a是1,b是2,op是+,那么拼成字符串变成1 + 2,其中+两边有空格。这个将对象中的数据搞成字符串的过程就叫做序列化的过程。
那么为什么要序列化呢?
由于在系统底层,数据的传输形式是简单的字节序列形式传递,即在底层,系统不认识对象,只认识字节序列,而为了达到进程通讯的目的,需要先将数据序列化,而序列化就是将对象转化字节序列的过程。所以就是得传一个字符串,方便对方分析你发的是个啥。
服务端在接收到客户端发来的字符串后,需要对这个字符串进行解析,也就是把这个字符串拆开看看是要自己干啥,比如上面的1 + 2这个字符串,服务端分析的时候也就可以创建一个上面客户端的对象,然后将字符串分析成操作数1,运算符+,操作数2,这时候服务端就可以知道其要进行1和2的加法工作,并将这个三个东西放到对象内的成员中。而这个拆开字符串的过程就叫做反序列化。也就是当字节序列被运到相应的进程的时候,进程为了识别这些数据,就要将其反序列化,即把字节序列转化为对象。
这样的话,第一种方式相比第二种就稍微逊色一点了,第二种可以更方便的提取操作数、操作符,而第一种客户端发送的时候可能发送的不标准,但是第二种的话客户端只要把Request对象字段填充一
下,然后调用一下序列化的函数就行了,相对来说更标准,也更安全。
那么这里规定的发送格式和分析数据就是一种约定,约定客户端按照规定的方式发送数据,服务端按照规定的方式解析数据。这就是二者的协议。
所以这里我就来写写这个网络版的计算器。
稍有瑕疵的计算器
上面讲了客户端给服务端发送请求的过程,那么服务端也是要给客户端进行响应的。
比如客户端刚刚发了1 + 2,服务端得要回一个数据,也就是3,但是光回一个3的话有点问题,因为如果客户端发送了一个格式错误的请求那不就没有遵守前面的约定么,那么这时候就要回一个其没有遵守协议的消息,所以再添加一个发送的字段code,用来表示当前结果是否是一个正常的结果。
那么上面响应的时候返回数据也是不止一个字段,所以也是要一个结构体,这里给这个结构体起名为Response:
struct Response {
int result; // 运算的结果
int code; // 结果是否正常
};
其中code不光可以标记客户端是否遵守约定,还可以标记运算错误,比如说除零了,模零了等等问题。
服务端在进行相应发回消息的时候也是得要先定义一个Response对象,然后将这个对象中的数据进行序列化转成字符串发送给客户端,然后客户端也是要对服务端发回的字符串进行反序列化,这样就是一个相互的过程。
那么写之前再把整个思路捋一遍。
客户端 ⇒ 服务端
- 客户端请求时,先定义一个Request对象,然后把所有字段填好,序列化后发给服务端。
- 服务端接收时,先接收发来的字符串,然后进行反序列化,定义一个Request对象,将字符串反序列化的数据放到Request对象中。
服务端 ⇒ 客户端
- 服务端将Request对象中的数据进行运算,定义一个Response对象,将运算是否成功和结果填到Response对象中,然后再对Response对象进行序列化工作,并将序列化后的字符串发送给客户端。
- 客户端接收到服务端发送来的字符串后,定义一个Response对象,对字符串进行反序列化后,反序列化的结果放到Response对象中。
这样就是整个流程,其实也很简单。
由于我这里用的是C/C++混编的方式来写代码的,所以我可以直接在Request类中添加两个接口,一个来进行客户端数据序列化的接口,一个来进行服务端接收到服务端发来的字符串后进行反序列化的接口。同理Request也是搞两个接口。
这样服务端和客户端在发送和接收数据的时候就只创建一个对象,然后调用接口就行了,更方便。
我先把日志打印的代码给出来,这个代码已经在我的很多博客中存在了,不过肯定有同学是第一次看我的博客的,等会用到打印日志的时候不要觉得奇怪:
日志打印起来的效果大概是这样:

代码如下:
#pragma once
#include 完整代码(Protocol.hpp最重要)
本篇要写的代码加上前一篇中TCP的逻辑,总共写出如下文件:

也就是五个文件。
Protocol.hpp
先把本篇中最终要的Protocol.hpp给出:
#include "LogMessage.hpp"
#include 这个Protocol文件就是这里网络版计算器中客户端和服务端之间的协议,不过稍微有点问题,后面再为什么。
还有一个问题就是这里写的时候失误了,把日志打印的信息全放到.hpp中了,这样就会导致出问题时定位不准确,这会就当吃个教训吧。
sock.hpp
然后再来说其他的四个:
sock.hpp(对套接字接口的封装)
#include "LogMessage.hpp"
#include TcpServer.hpp
TcpServer.hpp(服务器接口封装)
#include "Sock.hpp"
#include CalServer.cc
CalServer.cc(服务端)
#include "TcpServer.hpp"
#include "Protocol.hpp"
using namespace FangZhang_Server;
// 服务端用法
void Usage(const char* flieName)
{
std::cout << "Usage:\n" << flieName << "port" << std::endl;
}
// /*测试代码*/
// void print(int sock)
// {
// while(1)
// {
// std::cout << "sock" << std::endl;
// sleep(1);
// }
// }
static Response Calculate(const Request& req)
{
Response res;
char op;
switch(req._op)
{
case '+':
res._result = req._x + req._y;
break;
case '-':
res._result = req._x - req._y;
break;
case '*':
res._result = req._x * req._y;
break;
case '/':
if(req._y == 0)
res._code = 1; // 不能除零
else
res._result = req._x / req._y;
break;
case '%':
if(req._y == 0)
res._code = 2; // 不能模零
else
res._result = req._x % req._y;
break;
default:
res._code = 3;//运算符不在范围内
break;
}
return res;
}
void Calculator(int sock)
{
std::string inBuff;
while(1)
{
// 服务端先接收字符串
int ret = Recv(sock, inBuff);
if(!ret) break; // 对端关闭连接
// 反序列化并填充Request对象
Request req;
req.DeserializeRequest(inBuff);
// 计算结果并填充Response对象
Response res = Calculate(req);
// 将Response对象序列化
std::string echo = res.SerializeResponse();
// 结果传给客户端
Send(sock, echo);
}
}
int main(int argc, char* argv[])
{
// 固定格式 文件名 + port
if(argc != 2)
{
Usage(argv[0]);
exit(1);
}
// 初始化时就直接前三步走完
Server server(atoi(argv[1]));
//这里添加任务
server.AddService(Calculator);
/*测试*/
//server.AddService(print);
// 这里进行通信
server.StartServer();
return 0;
}
CalClient.cc
CalClient.cc(客户端)
#include "LogMessage.hpp"
#include "Protocol.hpp"
#include "Sock.hpp"
#include 运行测试
服务端刚运行,没有连接:

连接一个客户端:

正常运行。
再来个除零的:

错误码为1,就表示的是除零错误。
剩下的就不演示了。
协议的体现
客户端在写代码的时候,如何知道是_x _op _y 还是 _y _op _x的呢?代码当中是没有体现出来的。
但是客户端和服务端都能知道怎么运算,这就是约定,所以约定不仅仅体现在能看到的结构化的_x,_y_op这些字段上,还体现在看不到的计算顺序上。
Response类中的_result、_code都代表什么。_code直接用数字表示,但是每个数字都有其特殊含义,这并不会在打印结果中直接显示出来每个数字的意思,但是客户端和服务端都知道,这也是协议。
发送数据时,对结构化的数据转成字节流发送,对方收到字节流后还要进行反序列化,无论是请求还是响应都是要进行序列化和反序列化的。
这里先手动写一点协议,只是为给大家演示一下,后面会有现成的协议用。毕竟我们自己手动写的协议总是多少有些漏洞的。
问题
上面给了Protocol代码后,我说了协议定制的有点问题,那么是什么问题呢?
我这里把客户端的代码改一下,改成每一秒自动发送2 + 3,再在加上条件编译,不打印DEBUG的日志,不然信息太多了,看不过来:

运行:

看着挺正常的。
但是有问题。
这里客户端每隔一秒发送一次数据,太慢了,如果我直接一个while循环去不断发送请求呢?
TCP是面向字节流的,客户端某一时间端内发多个请求,服务端是一次就能把所有的都读走的。就像我前面讲进程间通信的那篇博客中的管道一样,如果写端写的非常快但读端读的非常慢,最终导致的结果是读端一次会读出写端多次写入的数据。这里的TCP同理,如果客户端发的非常快,服务端接收的稍微慢一点,那么就可能出现服务端一次读了客户端发送来的很多次的请求。
也就是这里:

那么这时候服务端的recv如何保证读到的buff中是一个完整的请求呢?
比如说客户端发了3次请求后,服务端才进行读取,那么这时候是无法只读一次请求的,而是将三次请求都读到buff中。
没听懂同学的看图:

TCP叫做传输控制协议。为什么叫这个名字呢?
TCP通信的时候,发送用的是send/write,接收用的是recv/read。
这4个函数参数的第二个参数都是一个void*的指针,指向的就是我们用户自己定义的缓冲区,要么往这个缓冲区中写,要么从这个缓冲区中读。
send/write只是把buff中的数据拷贝到了发送缓冲区中,而并不是把数据直接就发送到了网络/对方主机中。recv/read也只是将接收缓冲区中的数据拷贝到了buff中。
所以IO接口(send/write、recv/read)本质上都是拷贝函数。
而TCP决定了什么时候发送缓冲区中的数据,发送多少,出错了怎么办的问题。这几点就体现出了其传输控制协议,可能write进行了好多次后才发过去的,发送的次数和接收的次数没有任何关系,称为面向字节流。
而UDP是面向数据报的,sendto发送一个,recvfrom读取一个。不会出现多个请求混在一块的情况。
那么这样的话,问题就来了,TCP客户端发送请求时,若服务端将3次请求都读到一块了,怎么正确的进行序列化呢?
所以这里单纯一个recv不能保证读到一个完整的"1234 + 5678",可能是"1234 + 56781234 + 56781234 + 56781234 + 5678"这样的数据。
所以这里就要对协议进一步进行定制,让发送的字节流变成这种形式:
- length\r\n_x _op _y\r\n
什么意思呢?举个例子:5\r\n1 + 2\r\n。
这里的5代表了1 + 2这个字符串的长度,也就是5。对应的就是length。
当读取到数据的时候先提取出前面的lenth,这时候就知道了中间有效的正文数据的长度了。比如这里的5\r\n1 + 2\r\n,先提取出5,那么就能知道正文长度应该是5了,这一串的有效字符提取的时候就按长度为5进行提取。
然后\r\n表示什么呢?
第一个\r\n区分正文和正文长度,正文长度可以看做是协议报头,正文可以看做是协议,但严格意义上讲length也是协议。当然\r\n也可以成其他的特殊字符,比如\a\b什么的,但是建议用\r\n,因为这样定制出来的协议可读性会更好一点。
第二个\r\n只是为了增加协议的可读性的,不加也可以,但是加上更好。
如何保证读取到一个完整的长度length呢?
通过\r\n,只要识别到\r\n时,在\r\n之前的就是长度,且长度字符串中只有数字,不会有\r\n等特殊字符。
所以后面收数据时可能是"length\r\n_x _op _y\r\nlength\r\n_x _op _y\r\nlength\r\n_x _op _y\r\n…",读取的时候就先提取length,丢弃第一个\r\n,再根据length读取后面的正文数据,再丢掉第二个\r\n,然后重复前面的工作即可。
所以Recv的时候不管格式全部读取就行。一口气读完再进行解析,解析出来几个正文就是几个正文。
优化协议
思路
说一下实现思路。
多搞两个函数接口:
- 一个Encode,负责任何一端发送数据前将发送的正文前面加上length和\r\n,后面加上\r\n。
- 一个Decode,负责任何一端接收数据后去掉接收数据中的length和两个\r\n。
大方向还是不变的,还是前面的那些步骤。不过发送和接收的时候要多做一点工作。
客户端 ⇒ 服务端
- 客户端发送给服务端请求前,还是先对Request对象进行序列化,再对序列化后的字符串进行Encode,然后发送。
服务端 ⇐ 客户端
- 服务端在接收到客户端的请求后,先将接收到的字符串进行Decode,然后再将Decode后得到的字符串进行反序列化并将数据填充在Request对象中。
服务端 ⇒ 客户端
- 通过计算将数据填充到Response对象中,然后再将Response对象序列化并将序列化后的字符串进行Encode,最后发送即可。没错服务端发送前也是要添加length\r\n和\r\n,比如说5\r\n5 0\r\n,这样的话一个函数Encode就既可以实现客户端发送请求前的Encode,也可以实现服务端发送前Encode。
客户端 ⇐ 服务端
- 客户端在接收服务端的响应后,先将接收到的字符串Decode,然后再将Decode的字符串进行反序列化并将数据填充在Response对象中,打印结果即可。
整个流程就是这样,不过是多了Decode和Encode。
代码
那么我现在就把代码改改。
先来改改服务端:
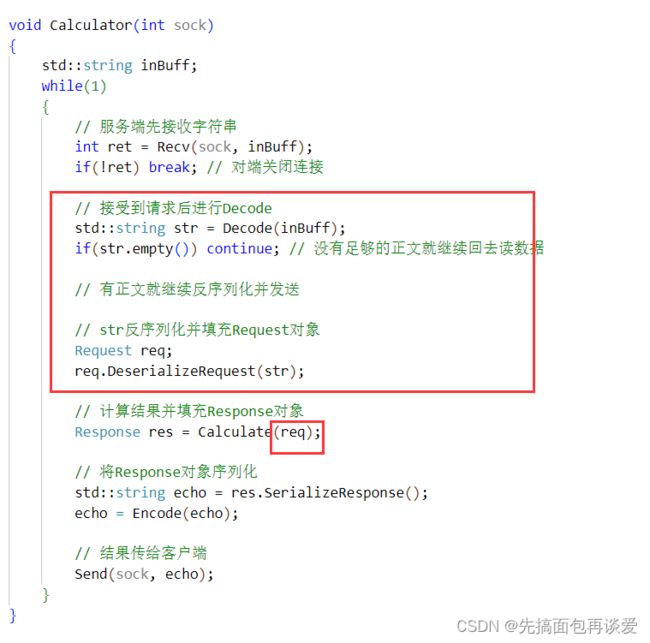
就只有红框的是变化的。
再来说客户端:
int main(int argc, char* argv[])
{
if(argc != 3)
{
Usage(argv[0]);
exit(1);
}
// 找服务端IP和Port
uint16_t serverPort = atoi(argv[2]);
std::string serverIp = argv[1];
// 创建套接字
std::unique_ptr<Sock> sock(new Sock);
int sockfd = sock->Socket();
// 连接服务器
if(!sock->Connect(sockfd, serverIp, serverPort))
{
LogMessage(FATAL, _F, _L, "client connect fail");
exit(2);
}
bool quit = false;
while(!quit)
{
// 定义Request对象,填充字段
Request req;
std::cout << "请输入左操作数 #";
std::cin >> req._x;
std::cout << "请输入右操作数 #";
std::cin >> req._y;
std::cout << "请输入操作符 #";
std::cin >> req._op;
// Request对象序列化
std::string reqString = req.SerializeRequest();
// 发送前先Encode
reqString = Encode(reqString);
// 发送请求(发送序列化的字符串)
Send(sockfd, reqString);
// 专门接收报文的字符串
std::string buff;
while(1)
{
// 接收服务端的响应
int ret = Recv(sockfd, buff);
if(!ret)
{
quit = true;
break;
}
std::string package = Decode(buff);
if(package.empty()) continue;//如果获得空串,说明报文不完整,上去重新读取再Decode
// 将服务端的字符串反序列化到Response对象中
Response res;
res.DeserializeResponse(package);
// 打印运算结果
std::cout << "server echo ==>" << " code::" << res._code << "\tresult::" << res._result << std::endl;
// 一定要记着break,没有写这个搞得我我调试了一个多小时才发现的问题
break;
}
}
close(sockfd);
return 0;
}
上面的Encode和Decode
// 对序列化后的字符串添加length\r\n 和 \r\n
std::string Encode(const std::string &str)//此处str为1 + 2,即正文
{
// 局部string对象
std::string res;
// 添加length
res = std::to_string(str.size());
// 添加第一个\r\n
res += SEP;
// 添加正文str
res += str;
// 添加最后的\r\n
res += SEP;
// 到这里res = length\r\nstr\r\n
return res;
}
// 对接收到的字符串去掉length\r\n 和 \r\n
std::string Decode(std::string &str)/*这里的str是Recv读取到的inbuff,在这里读取出一个正文就去掉一个报文,Recv中还可以接着读*/
{
// 局部string对象
std::string res;
// 以5\r\n1 + 2\r\n为例
/*下标01 2 345678 9*/
// 先找到str中的第一个\r\n
std::size_t pos = str.find(SEP);
// 读取到length的值并去掉length和第一个\r\n
size_t len = std::stoi(str.substr(0, pos)); // len为5
str.erase(0, pos + SEP_LEN); // 此处剩str下1 + 2\r\n
//下标为012345 6
// 通过len拿到正文并将str中的正文和第二个\r\n
res = str.substr(0, len);
str.erase(0, len + SEP_LEN);
// 此处res = 1 + 2,str去掉了一个完整报文
return res;
}
运行结果
运行:
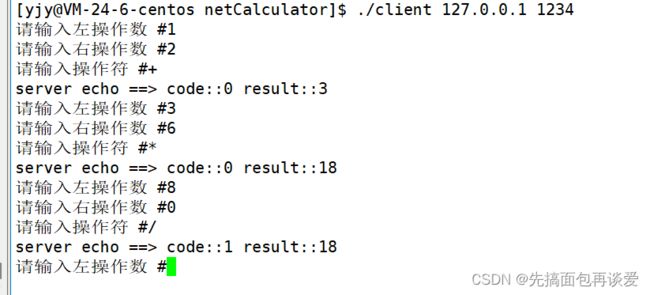
服务端运行起来打印有点怪:

ok的。
我这里改一改客户端打印的格式:
然后运行:
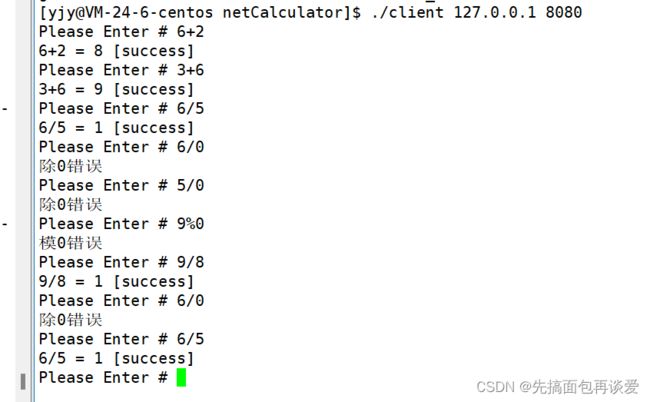
想把日志打印到文件中也可以,在LogMessage.hpp中改一下就行:

运行:
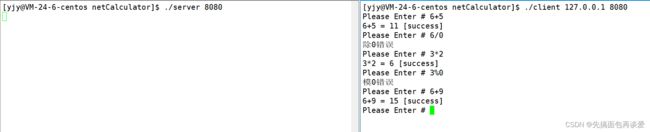
文件:

守护进程
下面来说说守护进程这个概念。为啥突然说个和进程相关的东西呢?
肯定是有用嘛。
前面的博客和我现在这篇博客写的服务器进程都是在前台跑的,所以都是前台进程,啥叫前台进程?
课本上是这么说的:和终端相关联的进程就叫做前台进程。
但是新手完全就听不懂啊,有些教材老是不说人话,很叫人讨厌。
我来说说,判断一个进程是否是前台进程,你就看你运行起来这个进程后,你输入命令有用没有,如果没有用就是前台进程,如果有用就是后台进程。
比如说我现在写一个死循环运行起来:

我输什么命令都没用,这就是前台的。
如果我把这个进程调到后台,他就不会占用终端(输入输出,你可以看做就是显示器、键盘和鼠标):

后面加个&就会让进程到后台跑去,但是这里想要和前台进程优点区别的话,我再来改改,让进程一秒打印一个hello world:

上面是前台的,下面是后台的:
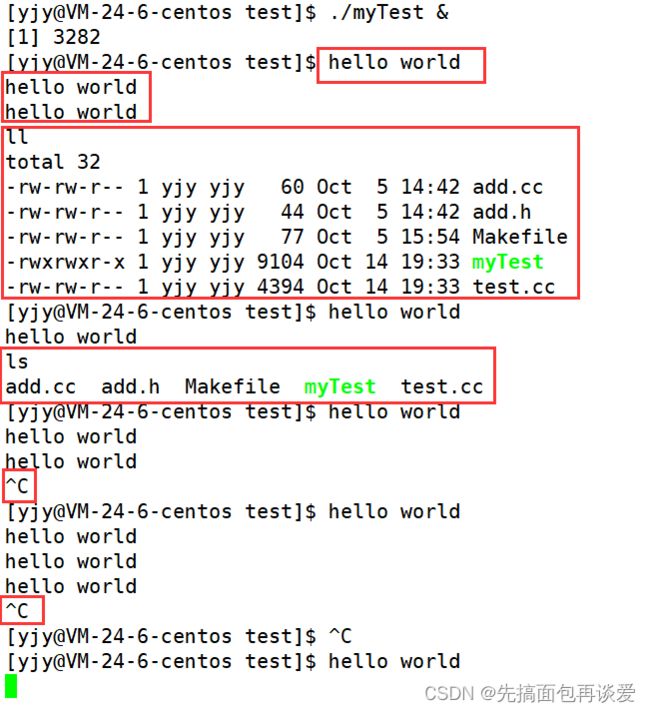
可以看到输入命令有用,想要关闭这个进程的话只能是调到前台或者kill关。
这就是前台和后台。
-
任何xshell登录,只允许一个前台进程和多个后台进程。所以永远只能有一个进程能进行输入,也就是那个前台进程。
-
除了进程有自己的PID、PPID,还有一个组ID
看图:
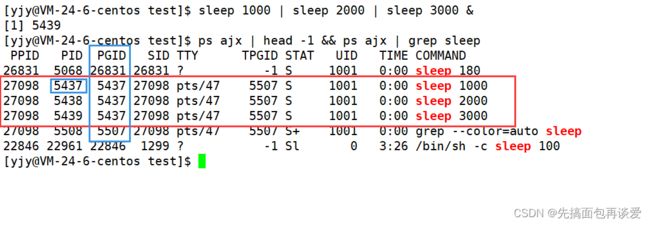
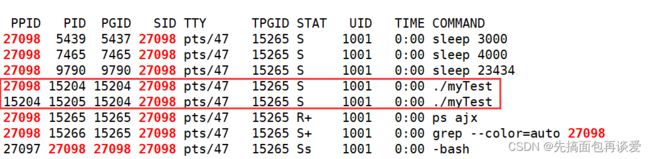
我上面用sleep创建了三个后台进程,然后用ps进行查看,可以看到三个进程的组id都是5437,而5437就是第一个进程的PID。也就是说三个进程属于一个组的,而且这个组的组长是第一个创建的进程。 -
命令行上运行起来的进程父进程都是bash,所以三个进程的父进程都是bash:

那么同时用管道启动的多个进程之间的关系是兄弟关系,所以上面的三个进程都是兄弟进程。父进程都是bash,所以兄弟进程可以用匿名管道进行通信。
那么我再创建一个后台的:
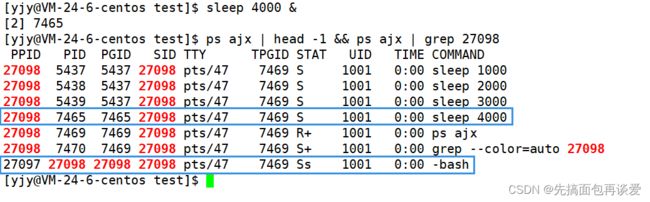
可以看到和前面三个不是同一个组的。自成一个组,组长就是自己。
-
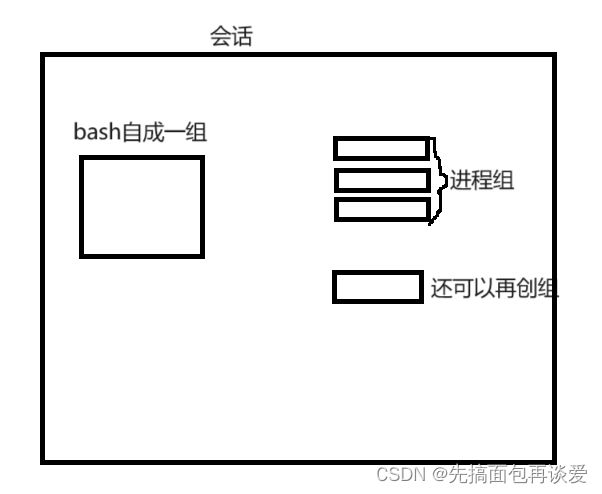
用户自己可以启动很多进程或者进程组,给用户提供服务的进程或者用户自己启动的所有进程或服务,整体都属于一个会话机制中。
看图:
-
当退出登录时,会话中的所有进程有可能退出(不同os下情况不同,也有可能不退,但是我这会退),这也是为什么各位电脑有点卡的时候可以先注销一下,Windows下的注销就相当于是退出登录,一退出就会关掉很多进程,这样能稍微缓解一下,如果还是很卡那就重启一下。
再来看:
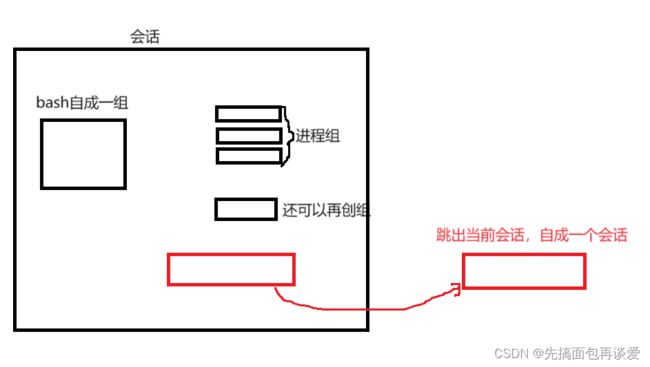
SID都是27098,也是bash的PID,所有的都是一个回话的。
但是如果我这一篇写的服务器想要永远不退出,是否可以做到?
当然可以,不然那么多公司的服务器如何常年不关的。
只需要将一个进程不属于当前会话,自成一个会话就不再受登录和退出的影响了,这个自成一组的进程就叫做守护进程:
那么如何实现这个守护进程呢?
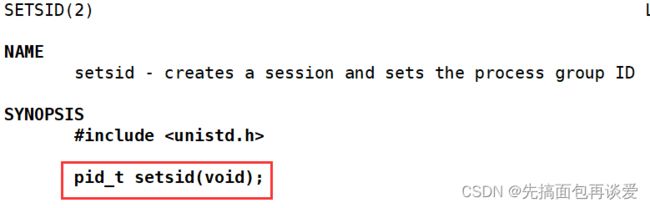
很简单,调用setsid函数就行:
我来吧man中对该函数的介绍拿出来:
- setsid() creates a new session if the calling process is not a process group leader. The calling process is the leader of the new session, the process group leader of the new process group, and has no controlling terminal. The process group ID and session ID of the calling process are set to the PID of the calling process. The calling process will be the only process in this new process group and in this new session.
意思就是:
- 如果调用这个函数的进程不是进程组组长,则创建一个新会话。调用这个函数的进程是新会话的领导者,也就相当于是新会话中的bash,也是新进程组的组长,并且没有控制终端。调用进程的进程组ID和会话ID被设置为调用进程的PID。调用进程将是此新进程组和此新会话中的唯一进程。
所以setsid想要调用成功,必须保证当前进程不是当前会话中某一个进程组的组长,组长丢了组就散了,只有手底下的人才行。
如何保证一个进程不是进程组的组长呢?
fork创建子进程就行。
代码就不给了,直接看运行:
这里两个父子进程,PGID都是父进程的PID,所以用fork创建了子进程后,再让子进程调用setsid就行。
那么如何在Linux中正确的写一个让进程守护化的代码?
光调用setsid是不够的,还得做点其他事情。
四条:
- 忽略一些信号,比如说SIGPIPE、SIGCHLD等,SIGPIPE可以说是服务器最常见的信号了,得把这些信号屏蔽到,防止这些信号给进程干掉了,那服务器就挂了。
- 不要让当前进程成为组长。
- 跳出当前会话。
- 标准输入、标准输出、标准错误的重定向。守护进程不能直接向显示器打印消息,因为终端是和回话关联的,而守护进程已经和回话没有关系了,所以不能通过终端进行IO,一旦守护进程往终端打印了就可能暂停/停止(取决于系统)。
那么挨个说一下策略。
- 使用signal函数,对信号进行SIG_IGN。
- 创建子进程。
- 调用setsid。
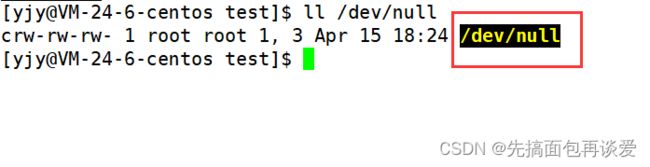
- /dev/null中有一个文件:
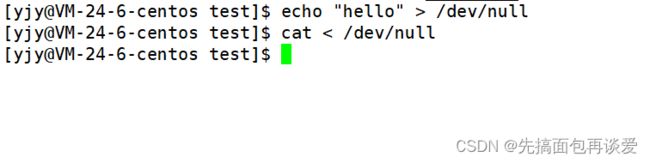
当你将数据输出到这个文件中时,所有的数据都会自动丢弃,当你从这个文件中读数据的时候也不会读到任何东西,就是一个文件黑洞。
可以看到啥也没。
那么我来写一个接口,就实现上面的功能。
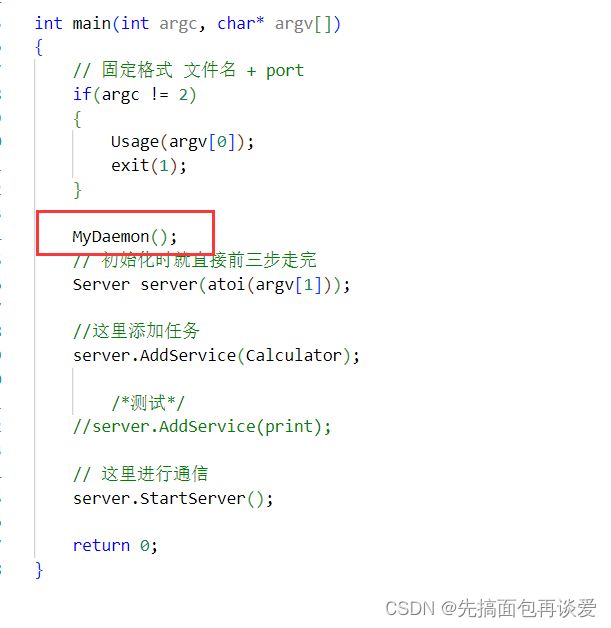
void MyDaemon()
{
signal(SIGPIPE, SIG_IGN);
signal(SIGCHLD, SIG_IGN);
if(fork() > 0) exit(0);
setsid();
int devnull = open("/dev/null", O_RDONLY | O_WRONLY);
if(devnull > 0)
{
dup2(devnull, 0); // 标准输出重定向到devnull文件中
dup2(devnull, 1); // 标准输入重定向到devnull文件中
dup2(devnull, 2); // 标准错误重定向到devnull文件中
close(devnull); // 这里打开文件有引用计数,此时四个都指向了devnull这个文件,关掉一个
// 不然浪费了
}
}
然后我在服务端调用一下这个函数:
运行:
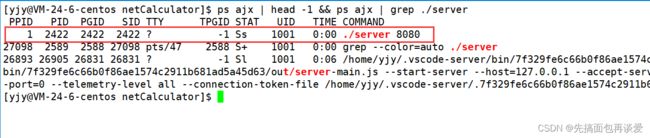
这里可以看到服务端PPID为1,也就是os,成孤儿了,PID、PGID、SID相同,自成一组,自成一个会话,TTY代表当前进程是否和当前终端有关,这里是一个?,就是无关。
所以守护进程本质上也是孤儿进程的一种,不过孤儿进程还是在当前会话中的,守护进程不在。
就算我此时退出登录,这里服务器也还是在跑着的,目前大部分公司的服务器就是这样跑的。
再启动一个客户端:

看一下日志:
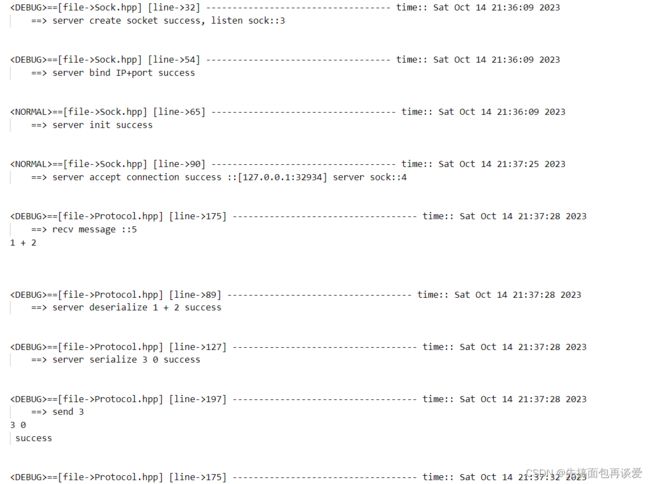
完全OK。
因为这里0、1、2都重定向到了/dev/null这个文件中,所以标准的输入输出没用,必须得用fprintf或者write、read这样的接口并通过文件描述来进行输入输出。
像我这里就是用日志打印,用的就是fprintf,通过新建一个文件来进行写入。
json
json可以完成序列化和反序列化的工作。
json是一种网络通信的格式。C++中也是有json的,所以上面的那些序列化和反序列化我是完全没必要写的,不过只是为了给各位见见猪跑,看看协议到底是啥才写的。
C++中用json得先用yum安装jsoncpp:命令行上输入yum install jsoncpp-devel就行。
安装好后就放在固定路径下了:
头文件:

库文件:

引用的时候像这样:
#include 库文件去掉前缀lib,去掉后缀.so,得到的即文件名jsoncpp,所以编译时要加上链接选项 -ljsoncpp。
这里的这些知识在我前面的博客中也有,不懂的同学看:【Linux】基础文件IO、动静态库的制作和使用。
json的使用
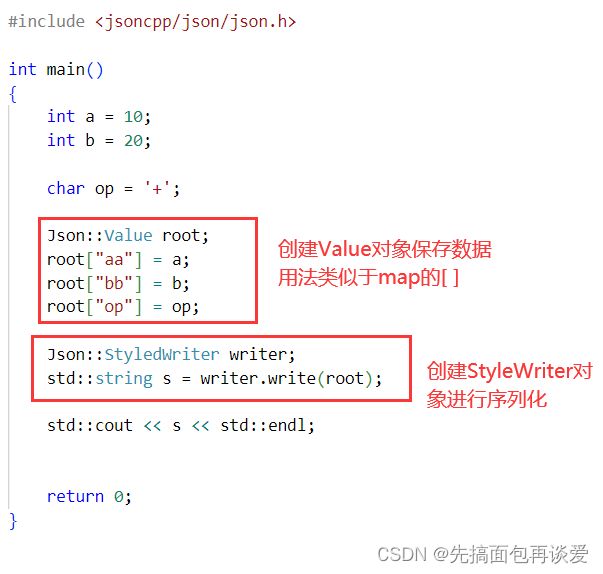
非常简单,直接定义几个json中的类对象,然后调用对象中的接口就行。
这里要用到这几个类:Value、StyleWriter、FastWriter和Reader。
Value是用来存放数据的。
StyleWriter和FastWriter是用来进行序列化的。
Reader是用来进行反序列化的。
下面我来单独开一个文件来演示一下。
就这样就序列化好了,运行:
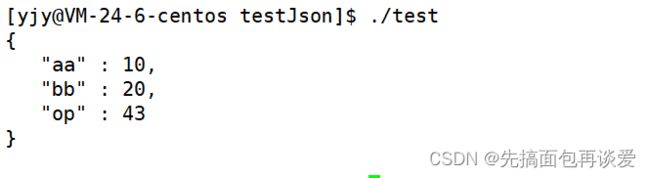
直接就能打印出很完美的格式。自动就转换成了KV的格式,这里op是按照ASCII转的,+就是43。这里的换行就是\r\n。
但是这里的StyleWriter一般是Debug版本下用的,Release版本下一般用的是FastWriter:

运行:

这样打印出来的是一整行。
用Json不比我前面写那一大堆协议强。非常方便。
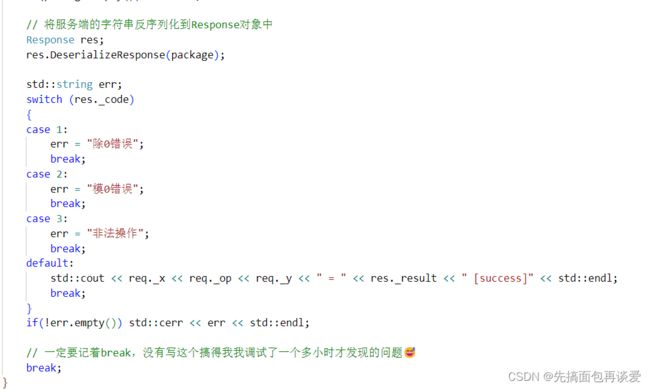
反序列化就是还是创建对象调用接口:
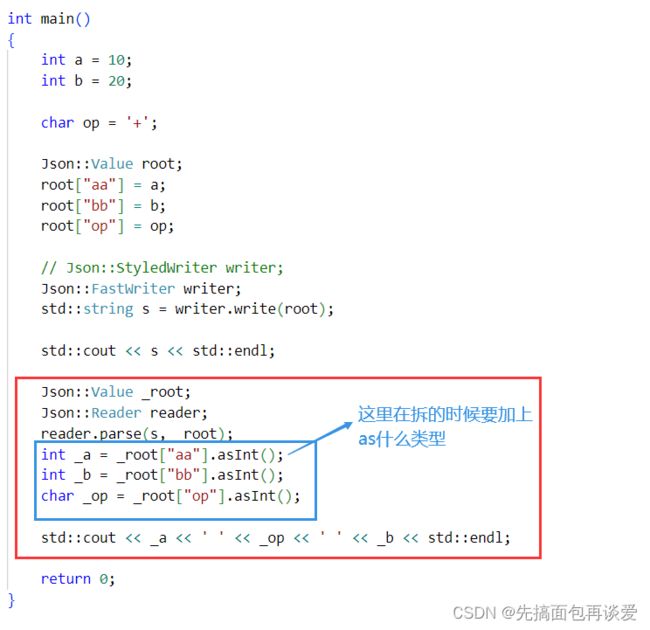
因为这里反序列化的时候一般是另一端接收,所以要另一端要创建一个对象来接收拆开的数据。
其中我框起来的:
拿数据的时候就按照同样的K取出来V就行。
运行:

那么该介绍的都介绍了,下面就来改改我前面服务器中序列化的地方。
用json进行服务器中数据的序列化和反序列化
其实就改一下Protocol.hpp中的内容就行,更准确的说是改一下Request和Response中的序列化和反序列化就行:
// 客户端发送请求,服务端接收
class Request
{
public:
// 供服务端用的构造
Request()
{}
// 供客户端用的构造
Request(int x, int y, char op)
: _x(x)
, _y(y)
, _op(op)
{}
// 序列化
std::string SerializeRequest()
{
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["op"] = _op;
Json::FastWriter writer;
std::string res = writer.write(root);
return res;
}
// 反序列化
bool DeserializeRequest(const std::string& str)
{
Json::Value root;
Json::Reader reader;
reader.parse(str, root);
_x = root["x"].asInt();
_y = root["y"].asInt();
_op = root["op"].asInt();
return true;
}
public:
// 格式:_x _op _y
int _x;
int _y;
char _op;
};
// 服务端回复数据,客户端接收
class Response
{
public:
// 客户端用的构造
Response()
:_result(0)
,_code(0)
{}
// 服务端用的构造
Response(int result, int code)
: _result(result)
, _code(code)
{}
// 序列化 _result _code
std::string SerializeResponse()
{
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter writer;
std::string res = writer.write(root);
return res;
}
// 反序列化 _result _code
bool DeserializeResponse(const std::string& str)
{
Json::Value root;
Json::Reader reader;
reader.parse(str, root);
_result = root["result"].asInt();
_code = root["code"].asInt();
return true;
}
public:
int _result; // 运算结果
int _code; // 相当于错误码
};
这样发送和接收的逻辑就会非常简单,不必在意其中的细节,直接调用接口就行,如果想要进行扩展,比如说Response类中想要添加一个字段用来和code对应,那就只需要Value对象添加一个字段就行,很方便。
运行:


到此结束。。。