需求很简单,是从一段文本中匹配出其中的超链接。基本的做法就是用正则表达式去匹配。但是有这样一个问题。
网上大部分的识别URL的正则表达式url末尾有空格的情况下可以正确识别。比如这样的情况:
"我是一段中文https://github.com/TinyQ 我还是一段中文"
但是如果去掉TinyQ 后面的空格。匹配到的将是 “https://github.com/TinyQ我还是一段中文” 是连上的。
最后替换过好多正则才得以解决。这里贴上代码:
NSString *regulaStr = @"\\bhttps?://[a-zA-Z0-9\\-.]+(?::(\\d+))?(?:(?:/[a-zA-Z0-9\\-._?,'+\\&%$=~*!():@\\\\]*)+)?";
这里做个更新。下面这个正则也是可以的。而且应该更好一些。
比如这种 "Explorerwww.chiphell.com/ "。 也是可以识别出 www.chjiphell.com 的
((http[s]{0,1}|ftp)://[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)|(www.[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)
完整代码如下:
+ (BOOL)isUrlType:(NSString *)string { if (!string || [string isKindOfClass:[NSNull class]] || string.length == 0 || [string isEqualToString:@""]) { return NO; } else{ NSError *error; NSString *regulaStr = @"((http[s]{0,1}|ftp)://[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)|(www.[a-zA-Z0-9\\.\\-]+\\.([a-zA-Z]{2,4})(:\\d+)?(/[a-zA-Z0-9\\.\\-~!@#$%^&*+?:_/=<>]*)?)"; NSRegularExpression *regex = [NSRegularExpression regularExpressionWithPattern:regulaStr options:NSRegularExpressionCaseInsensitive error:&error]; NSArray *arrayOfAllMatches = [regex matchesInString:string options:0 range:NSMakeRange(0, [string length])]; if (!arrayOfAllMatches || [arrayOfAllMatches isKindOfClass:[NSNull class]] || arrayOfAllMatches.count == 0 ) { return NO; } else { return YES; } /* //提取出 URL for (NSTextCheckingResult *match in arrayOfAllMatches) { NSString* substringForMatch = [string substringWithRange:match.range]; NSLog(@"%@",substringForMatch); return YES; } return NO; */ } }
以下是一些基础知识整理:
语法规则:https://msdn.microsoft.com/zh-cn/library/ae5bf541(VS.80).aspx
行定位符(^和$)
行定位符就是用来描述字串的边界。“^”表示行的开始;“$”表示行的结尾。如:
^tm
该表达式表示要匹配字串tm的开始位置是行头,如tm equal Tomorrow Moon就可以匹配,而Tomorrow Moon equal tm则不匹配。但如果使用
tm$
则后者可以匹配而前者不能匹配。如果要匹配的字串可以出现在字符串的任意部分,那么可以直接 写成
tm
这样两个字符串就都可以匹配了。
单词定界符(\b、\B)
单词分界符\b,表示要查找的字串为一个完整的单词。如:
\btm\b
还有一个大写的\B,意思和\b相反。它匹配的字串不能是一个完整的单词,而是其他单词或字串的一部分。如:
\Btm\B
字符类([ ])
正则表达式是区分大小写的,如果要忽略大小写可使用方括号表达式“[]”。只要匹配的字符出现在方括号内,即可表示匹配成功。但要注意:一个方括号只能匹配一个字符。例如,要匹配的字串tm不区分大小写,那么该表达式应该写作如下格式:
[Tt][Mm]
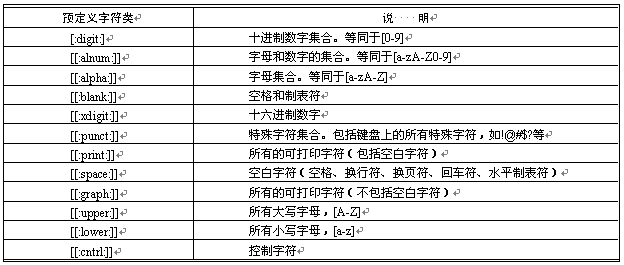
这样,即可匹配字串tm的所有写法。POSIX和PCRE都使用了一些预定义字符类。但表示方法略有不同。POSIX风格的预定义字符类如表所示。
选择字符(|)
还有一种方法可以实现上面的匹配模式,就是使用选择字符(|)。该字符可以理解为“或”,如上例也可以写成
(T|t)(M|m)
该表达式的意思是以字母T或t开头,后面接一个字母M或m。
连字符(-)
变量的命名规则是只能以字母和下划线开头。但这样一来,如果要使用正则表达式来匹配变量名的第一个字母,要写为
[a,b,c,d…A,B,C,D…]
这无疑是非常麻烦的,正则表达式提供了连字符“-”来解决这个问题。连字符可以表示字符的范围。如上例可以写成
[a-zA-Z]
排除字符([^])
上面的例子是匹配符合命名规则的变量。现在反过来,匹配不符合命名规则的变量,正则表达式提供了“^”字符。这个元字符在前面出现过,表示行的开始。而这里将会放到方括号中,表示排除的意思。例如:
[^a-zA-Z]
该表达式匹配的就是不以字母和下划线开头的变量名。
限定符(? * + {n,m})
对于重复出现字母或字串,可以使用限定符来实现匹配。限定符主要有6种,如表所示。

点号字符(.)
点字符(.)可以匹配出换行符外的任意一个字符。注意:是除了换行符外的、任意的一个字符。如匹配以s开头、t结尾、中间包含一个字母的单词。格式如下:
^s.t$
匹配的单词包括:sat、set、sit等。再举一个实例,匹配一个单词,它的第一个字母为r,第3个字母为s,最后一个字母为t。能匹配该单词的正则表达式为:
^r.s.*t$
转义字符(\)
正则表达式中的转移字符(\)和PHP中的大同小异,都是将特殊字符(如“.”、“?”、“\”等)变为普通的字符。举一个IP地址的实例,用正则表达式匹配诸如127.0.0.1这样格式的IP地址。如果直接使用点字符,格式为:
[0-9]{1,3}(.[0-9]{1,3}){3}
这显然不对,因为“.”可以匹配一个任意字符。这时,不仅是127.0.0.1这样的IP,连127101011这样的字串也会被匹配出来。所以在使用“.”时,需要使用转义字符(\)。修改后上面的正则表达式格式为:
[0-9]{1,3}(\.[0-9]{1,3}){3}
反斜线(\)
除了可以做转义字符外,反斜线还有其他一些功能。反斜线可以将一些不可打印的字符显示出来,如表所示。

还可以指定预定义字符集,如表所示。

反斜线还有一种功能,就是定义断言,其中已经了解过了\b、\B,其他如表所示。

括号字符(())
小括号字符的第一个作用就是可以改变限定符的作用范围,如“|”、“*”、“^”等。来看下面的一个表达式。
(thir|four)th
这个表达式的意思是匹配单词thirth或fourth,如果不使用小括号,那么就变成了匹配单词thir和fourth了。
小括号的第二个作用是分组,也就是子表达式。如(\.[0-9]{1,3}){3},就是对分组(\.[0-9]{1,3})进行重复操作。后面要学到的反向引用和分组有着直接的关系。
反向引用
反向引用,就是依靠子表达式的“记忆”功能来匹配连续出现的字串或字母。如匹配连续两个it,首先将单词it作为分组,然后在后面加上“\1”即可。格式为:
(it)\1
这就是反向引用最简单的格式。如果要匹配的字串不固定,那么就将括号内的字串写成一个正则表达式。如果使用了多个分组,那么可以用“\1”、“\2”来表示每个分组(顺序是从左到右)。如:
([a-z])([A-Z])\1\2
除了可以使用数字来表示分组外,还可以自己来指定分组名称。语法格式如下:
(?P…)
如果想要反向引用该分组,使用如下语法:
(?P=subname)
下面来重写一下表达式([a-z])([A-Z])\1\2。为这两个分组分别命名,并反向引用它们。正则表达式如下:
(?P[a-z])(?P[A-Z])(?P=fir)(?P=sec)
模式修饰符
模式修饰符的作用是设定模式。也就是规定正则表达式应该如何解释和应用。不同的语言都有自己的模式设置,PHP中的主要模式如表所示。

正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? />
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧没有能力为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如 0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$ //匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
英文字母:[a-zA-Z]
数字:[0-9]
匹配中文,英文字母和数字及_:
^[\u4e00-\u9fa5_a-zA-Z0-9]+$
同时判断输入长度:
[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10}
^[\w\u4E00-\u9FA5\uF900-\uFA2D]*$ 1、一个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:
^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$ 其中:
^ 与字符串开始的地方匹配
(?!_) 不能以_开头
(?!.*?_$) 不能以_结尾
[a-zA-Z0-9_\u4e00-\u9fa5]+ 至少一个汉字、数字、字母、下划线
$ 与字符串结束的地方匹配
放在程序里前面加@,否则需要\\进行转义 @"^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$"
(或者:@"^(?!_)\w*(?
2、只含有汉字、数字、字母、下划线,下划线位置不限:
^[a-zA-Z0-9_\u4e00-\u9fa5]+$
3、由数字、26个英文字母或者下划线组成的字符串
^\w+$
4、2~4个汉字
@"^[\u4E00-\u9FA5]{2,4}$";
5、
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
用:(Abc)+ 来分析: XYZAbcAbcAbcXYZAbcAb
XYZ AbcAbcAbcXYZ AbcAb6、
[^\u4E00-\u9FA50-9a-zA-Z_]
34555#5' -->34555 #5 '
[\u4E00-\u9FA50-9a-zA-Z_] eiieng_89_ ---> eiieng_89_
_';'eiieng_88&*9_ --> _';'eiieng_88&*9_
_';'eiieng_88_&*9_ --> _';'eiieng_88_&*9_
最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式
^[\u4e00-\u9fa5]{1,7}$|^[\dA-Za-z_]{1,14}$
///----------2014.10.07 再次编辑----------------
匹配月份的正则表达式
^[1-9]$|^1[0-2]$
注:个位数月份匹配方式 前面不能加 0。
^0?[1-9]$|^1[0-2]$
注:个位数月份前可以加0或者不加。
匹配年份19**或者20**
^(19|20)[0-9]{2}$
- + (BOOL)isEmailAddress:(NSString*)candidate
- {
- NSString* emailRegex = @"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4}";
- NSPredicate* emailTest = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", emailRegex];
- return [emailTest evaluateWithObject:candidate];
- }
- -(NSNumber *)asNumber;{
- NSString *regEx = @"^-?\\d+.?\\d?";
- NSPredicate * pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regEx];
- BOOL isMatch = [pred evaluateWithObject:self];
- if (isMatch) {
- return [NSNumber numberWithDouble:[self doubleValue]];
- }
- return nil;
- }
- //摘自NSString+BeeExtension.mm
- - (BOOL)isUserName
- {
- NSString * regex = @"(^[A-Za-z0-9]{3,20}$)";
- NSPredicate * pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
- return [pred evaluateWithObject:self];
- }
- - (BOOL)isPassword
- {
- NSString * regex = @"(^[A-Za-z0-9]{6,20}$)";
- NSPredicate * pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
- return [pred evaluateWithObject:self];
- }
- - (BOOL)isEmail
- {
- NSString * regex = @"[A-Z0-9a-z._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4}";
- NSPredicate * pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
- return [pred evaluateWithObject:self];
- }
- - (BOOL)isUrl
- {
- NSString * regex = @"http(s)?:\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- .\\/?%&=]*)?";
- NSPredicate * pred = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regex];
- return [pred evaluateWithObject:self];
- }
- - (BOOL)isTelephone
- {
- NSString * MOBILE = @"^1(3[0-9]|5[0-35-9]|8[025-9])\\d{8}$";
- NSString * CM = @"^1(34[0-8]|(3[5-9]|5[017-9]|8[278])\\d)\\d{7}$";
- NSString * CU = @"^1(3[0-2]|5[256]|8[56])\\d{8}$";
- NSString * CT = @"^1((33|53|8[09])[0-9]|349)\\d{7}$";
- NSString * PHS = @"^0(10|2[0-5789]|\\d{3})\\d{7,8}$";
- NSPredicate *regextestmobile = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", MOBILE];
- NSPredicate *regextestcm = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", CM];
- NSPredicate *regextestcu = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", CU];
- NSPredicate *regextestct = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", CT];
- NSPredicate *regextestphs = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", PHS];
- return [regextestmobile evaluateWithObject:self] ||
- [regextestphs evaluateWithObject:self] ||
- [regextestct evaluateWithObject:self] ||
- [regextestcu evaluateWithObject:self] ||
- [regextestcm evaluateWithObject:self];
- }
正则表达式学习链接: 55分钟学会正则表达式