python logistic回归_基于python的logistic回归建模预测

1、背景
泰坦尼克号是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉 。然而不幸的是,在它的处女航中,泰坦尼克号便遭厄运。1912年4月10日,泰坦尼克号从英国南安普敦(Southampton)出发,途经法国瑟堡-奥克特维尔(Cherbourg-Octeville)以及爱尔兰昆士敦(Queenstown),驶向美国纽约。1912年4月14日23时40分左右,泰坦尼克号与一座冰山相撞,造成右舷船艏至船中部破裂,五间水密舱进水。次日凌晨2时20分左右,泰坦尼克船体断裂成两截后沉入大西洋底3700米处。2224名船员及乘客中,逾1500人丧生。这么多人遇难的原因之一是没有准备足够的救生艇。
2、.提出问题
研究的问题:什么样的人在泰坦尼克号中更容易存活?
3.理解数据
3.1采集数据
从Kaggle泰坦尼克号项目页面下载数据:Titanic: Machine Learning from Disasterwww.kaggle.com
3.2查看官网上对变量的解释:


这里有个大致了解即可。
3.3理清分析思路和需求
【a】提出问题
【b】理解数据:导入数据—理解数据—数据集信息
【c】数据清洗:数据预处理(删除重复值、填充缺失值)— 特征提取 — 特征选择
【d】构建模型
【e】提交预测
3.4数据理解、准备、数据清洗
3.4.1导入数据查看数据集大小


train.csv比test.csv多了一列Survived,即是否生存,这正是我们要解决的问题:本文即是通过对train.csv的机器学习,来预测test.csv的Survived水平。因此,后面会基于train.csv提取特征并结合其Survived数据来预测,则test.csv的数据特征在预测的时候一定要与train.cs的特征数据一致。只有test.csv的特征与训练数据train.csv的特征一致时才能直接应用训练模型进行预测,这样才保证test.csv的特征数据可直接带入进行预测。所以要将二者合并起来一起清洗
3.4.2数据集信息


结论:1309行,12列,与前两个数据集的行之和、列数相符,说明合并成功。
3.4.3删除重复值

3.4.4查看数据集信息和缺失值情况


3.4.5理解数据缺失值
在前面理解数据阶段,我们发现数据总共有1309行。
数据类型列:年龄(Age)、船票价格(Fare)里面有缺失数据;而生成情况(Survived)这一列是标签,要预测的数据标签是未知的,不需要处理这一列
字符串列:船舱号(Cabin)和登船港口(Embarked)里面有缺失数据。
这为我们下一步数据清洗指明了方向,只有知道哪些字段缺失数据,我们才能有针对性的处理。很多机器学习算法为了训练模型,要求所传入的特征中不能有空值。
3.4.6处理缺失值
常见方法主要是:
如果是数值类型,用平均值取代;如果是分类数据,用最常见的类别取代;使用模型预测缺失值,例如:KNN。
(a)首先我们对数值型字段进行查看和处理,步骤如下:

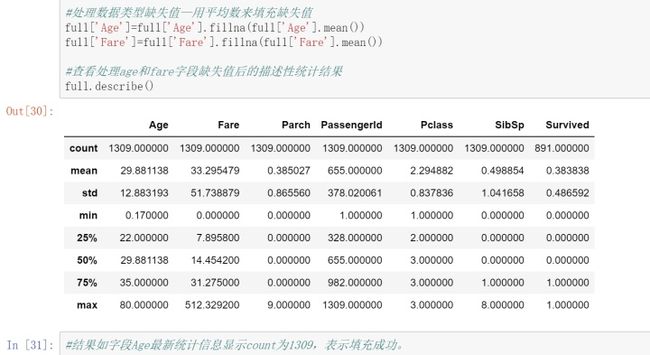
结果显示与前文分析的缺失值一致,表示目前是进程正确,下面进行数据清洗部分
依据处理数据类型缺失值—用平均数来填充缺失值的办法对数值型数据缺失值进行填充
(b)其次我们对字符串类型字段进行查看和处理,步骤如下:
依据处理字符串类型缺失值—用最常见的类别取代的办法对分类型数据缺失值进行填充
处理船舱号(Cabin)这列的缺失值:船舱号(Cabin)这列的缺失值很多,缺失值填充为U,表示未知(Unknow)

处理登船港口(Embarked)这列的缺失值:登船港口(Embarked)这列总数1307,缺失了2条数据,缺失很少,找出最常见的类别,用其填充

从结果来看,登船港口(Embarked)列,S类别最常见。 我们将缺失值填充为最频繁出现的值:S=英国南安普顿Southampton,并检查处理后的数据情况

(c)生成情况(Survived)这一列是标签,要预测的数据标签是未知的,不需要处理这一列
4、特征工程
数据分析、机器学习中,最重要的就是选取合适的数据特征,供模型算法训练。若训练的特征相关性高,则能事半功倍,故而特征工程是整个项目的核心所在,这一步做得好后面模型的正确率就高。那么什么是特征工程?特征工程就是最大限度地从原始数据中提取能表征原始数据的特征,以供机器学习算法和模型使用。下面,结合本例中的变量,先对其进行分类,然后逐个提取特征。
4.1特征提取
4.1.1一般步骤:原始数据—数据分类处理—特征提取(或特征降维后特征提取)—特征选择—构建模型;其中主要是特征提取(降维)和特征选择。
其中对各个变量分类后的处理办法如下:
(a)数值类型—直接使用
(b)分类数据—用数值代替类别one-hot编码
(c)序列数据—转成单独的年、月、日
4.1.2根据前文的info可知,可分类数据--解读如1)、其他类型数据—解读如2)
1)分类数据:
乘客性别(Sex):男性male,女性female
登船港口(Embarked):出发地点:S=英国南安普顿Southampton,途径地点1:C=法国瑟堡市Cherbourg,出发地点2:Q=爱尔兰昆士敦Queenstown
客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
2)数值、字符串类型数据: 乘客编号(PassengerId),年龄(Age),船票价格(Fare),同代直系亲属人数(SibSp),不同代直系亲属人数(Parch),客舱号(Cabin)、姓名(Name),船票(Ticket);
4.1.3对以上字段提取特征,具体过程如下:
船票(Ticket)表示的是船票号,由于我们会对乘客的等级做特征处理,故这里不需要处理Ticket数据,剩余字段数据特征提取思路如下:

[a]性别(Sex)
处理性别sex,数据Sex在原数据中填充的是female、male,为了方便后面模型训练,将其转换成数值型的0、1:

如上所示,转换成功。到这里,完成了sex列数据特征的提取。这里要特别注意的是map函数,其表示把其之前的对象按后面的规则逐个映射一遍,后面也将用到map函数,要特别掌握。
[b]登船港口(Embarked)
处理登录港口Embarked,首先看Embarked数据的前五行,了解数据列内容分布情况:

Embarked显示的是乘客在那个港口登陆,而这又是类别数据,这时可用one-hot编码对这一列数据进行降维。即:给登陆港口C、S、Q分别建一列,如果是在该港口登陆则值为1,否则为0。这样每个乘客,即每一行,只会在三列中的一列为1,其余为0,这就实现了类别数据向数值型数据的额转化,且也实现了数据降维。
具体可用pandas的get_dummies方法实现,使用get_dummies进行one-hot编码,产生虚拟变量(dummy variables),列名前缀是Embarked



如上EmbarkedDF就是转换后的Embarked数据,将其添加到full中,并删除原full中的Embarked列,到这里,完成了Embarked列数据特征的提取。
需要强调的一点是,contact具有合并数据的功能(axis=1表示按列合并),但python中并不是只有这一个函数具有合并功能,各个函数合并的特点各异,详见下面两篇文章:
PANDAS 数据合并与重塑(concat篇)blog.csdn.net
PANDAS 数据合并与重塑(join/merge篇)blog.csdn.net
[c]客舱等级(Pclass)
处理船舱等级Pclass,官网中介绍Pclass分为高中低,数值分别对应为1、2、3,与Embarked数据一致,也对其用get_dummies方法实现one-hot编码
首先看Pclass数据的前五行,并了解数据列内容分布情况:

对pclass列数据内容进行降维,并查看降维后的结果


到这里,完成了Pclass列数据特征的提取。
[d]姓名(Name)中提取头衔
先看Name数据列内容和内容分布情况:

仔细观察发现,每一个Name中都含有称谓,如Mr,Mrs,Miss等,可用split分割字符串提取出来,其中,可用strip方法去除称谓的前缀、后缀,本文中的前后缀是空格。接下来定义函数,把Name列的所有元素都按上述方法处置:

得到这些称谓如上图所示,对提取后的称谓进行统计,看有多种,每种出现的次数分别是多少?

如上所示,这些称谓很多,有些出现的次数很少,这不足以将人群分类。有没有更加简洁的分类,将上述称谓分类,以便更加直观的反应乘客的社会地位?经网上查西方人对头衔的分类,可将头衔分为6类Officer,Royalty,Master,Mr,Mrs,Miss六种,这样将大大的简化乘客身份的分类。所以,定义字典,并用map函数完成上述转换,如下:


接下来,将titleDF更新到full中,以便后面继续分析用:

到这里,完成了Name列数据特征的提取。
[e]客舱号(Cabin)中提取客舱类别
先看cabin数据列内容和内容分布情况:


仔细观察可见,Cabin数据列并不规整,但也不是全无规律可循,可取每个元素的首字母进行填充,然后用新的首字母进行one-hot编码生存特征数据CabinDF,最后更新到full中。

这里要重点注意一个重要的知识点匿名函数lambda,上图代码中"lambda c:c[0]"表示返回c的第一个元素,再结合map函数,表示对"full['Cabin']"中的每一个元素都应用一下该匿名函数,即返回首字母,从而实现提取首字母的目的。关于匿名函数lambda,这里不再详述。这是个重要的知识点,在python中经常用到,其能用一行代码实现函数定义,非常实用。
继续用get_dummies方法实现one-hot编码,如下:

将CabinDF更新到full中,并删除full中的Cabin列,则船舱号Cabin数据特征也准备好了,如下

到这里,完成了cabin列数据特征的提取。
[f] Parch,SibSp--建立家庭人数和家庭类别
先理解下这两个数据是什么意思:
SibSp:表示船上兄弟姐妹数和配偶数量,理解为同代直系亲属数量,
Parch:表示船上父母数和子女数,理解为不同代直系亲属数量。
据此,这两个数据可用来衡量乘客的家庭大小,而家庭的大小规模 会影响乘客的生还几率,因此可创建衡量家庭规模的变量familySize。familySize应等于:同代直系亲属数量SibSp+不同代直系亲属数量Parch+乘客本人,则有:

如上图所示,可计算出乘客在船上的家庭人数familySize,但此时的familySize各不相同,没有标准,这并不能直接反应出家庭的规模,因此根据familySize的大小将家庭数量分为大、中、小三种,当familySize为1时,认定其为小型家庭;当人数为2至4人时认定其为中等家庭;当人数大于等于5人时认定其为大型家庭。如下:


到这里,可将FamilyDF添加到full中,而Parch,SibSp数据可以删除也可不删除,本文没有删除,后面计算相关系数的时候再看,并不影响后面的分析。至此,Parch,SibSp数据特征准备好了。
数值型数据有Age,Fare,PassengerId列,其中PassengerId表示乘客的编号,在提交文件中有涉及,不适合做特征;Age,Fare的数值可直接作为数据特征使用。所以,至此完成了所有数据特征的提取。
4.2特征确认:
我们看一下此时的full,都有哪些特征。



如上所示,共有37列。
接下来我我们将获取这些特征之间的相关性,并敲定选取哪些特征作为样本训练的特征。
5.获取特征相关性
第四章中获取的众多数据特征,互相之间的是否相关?更进一步,是否生存Survived与哪些特征相关?这是本章要解决的问题。
5.1 首先获取corr矩阵
用dataframe的corr方法,获取full中所有元素之间的相关性矩阵corrDF:

图片很大,这里没能全部显示。然而我们的重点是获取Survived与各个元素之间的相关性,则提取Survived与各个数据的相关系数,并按降序排列,如下:


5.2特征选择
各个相关系数如上,根据正负相关性强弱,根据各个特征与生成情况(Survived)的相关系数大小,选择下列几个特征作为模型的输入:头衔(titleDf)、客舱等级(pclassDf)、家庭大小(familyDf)、船票价格(Fare)、船舱号(cabinDf)、登船港口(embarkedDf)、性别(Sex),年龄(Age),至此,根据相关性选取特征也准备好了。

6,准备建模数据
这里有个重要的问题要理清楚,就是各个数据集的作用。
- 首先,就是要分清楚用于训练的特征数据source_x和标签数据source_y,这俩必须含有上述特征和标签Survived数据;
- 同时full中还含有test.csv的数据,这一部分数据没有Survived列。本文正是要预测这一部分Survived情况,因此将full中test.csv部分提取出来,重命名为预测数据特征pre_x,以备后面预测用。
- 建立训练数据集和测试数据集,用训练数据和某个机器学习算法得到机器学习模型,用测试数据评估模型。
理清了思路之后,开始准备各个数据集:

- 样本特征数据是用于模型训练的,应含完整的选中特征,即28列数据;
- 样本标签数据是用于模型根据样本特征数据的特征与样本标签数据的一一对应关系来训练模型用的,故只有Survived列数据这一列,但其行数一定与样本特征数据的行数一致;
- 预测特征数据是后面带入到预测模型进行预测其预测标签的,故其形式一定要与样本特征数据一致,否则后面一定会出错。如果你做到这一步发现二者不一致,立刻停下来检查,否则后面走不通。
这一步至关重要,一定要理解清楚。这里整通了之后,后面完成后就可用train_test_split拆分样本数据为训练数据train和测试数据test,其中训练数据train用于模型训练,而测试数据test用于测试该训练的效果。

此时,可放慢脚步,两个数据集的特征和标签,对应样本特征数据和样本特征标签再进一步理解下,一定要理清思路再往后做,这样后面才能心如明镜。准备好上述这些数据后,就可以开始建立模型,并训练了。
7.构建模型
选择逻辑回归算法建立模型
用sklearn的linear_model的逻辑回归算法建立模型,并开始用拆分好的数据进行训练:

8.模型的评估、预测
8.1 模型正确率评估
用模型model的score方法,查看其正确率,看看该模型预测的test_y与预留的test_y对比后,正确的比例有多少:

模型的正确率为79.3%,表明拟合的相对理想,正确率高,可以使用来预测。
8.2 用模型进行预测
将前面准备的预测数据特征pre_x,用模型的predict方法预测生存数据pre_y,并整理成整数型int数据:

8.3 按项目要求收集数据
第一章中下载好的三个数据集中的''gender_submission.csv''根据官网释义,这个是要提交的预测数据的要求格式,则我们上传的数据应与这个样式数据完全一致,其中的列名“PassengerId”“Survived”的大小写也应完全一致,否则系统会因无法读取数据而报错。 使用预测数据集得到预测结果,并保存到csv文件中,上传到Kaggle中,就可以看到得分。


将预测结果上传到Kaggle,得分为0.7655。
至此,本项目已经全部做完了。后续再优化项目,用其他模型预测.