Java8 Stream流使用
参考资料
- Java8 Stream:2万字20个实例,玩转集合的筛选、归约、分组、聚合
- 恕我直言你可能真的不会java系列
- 【java8分页排序】lambda的(多字段)分页和排序 comparing,thenComparing的区别

目录
- 一.管道流的转换
-
- 1.数组转换为管道流
- 2.集合类对象转换为管道流
- 3.文本文件转换为管道流
- 二.Stream的Filter与谓词逻辑
-
- 1.普通的filter函数过滤
- 2.谓词逻辑and的使用
- 3.谓语逻辑or的使用
- 4.谓语逻辑negate(取反)的使用
- 三.Stream的Map操作
-
- 1.集合元素转换成大写
- 2.集合元素类型的转换
- 3.对象数据格式转换
- 四.Stream的状态与并行操作
-
- 4.1.Limit与Skip管道数据截取
- 4.2.Distinct元素去重
- 4.3.Sorted排序
-
- 4.3.1字符串List排序
- 4.3.2整数类型List排序
- 4.3.3按对象字段对`List
- 4.3.4 对Map排序
-
- 4.3.4.1 HashMap的merge()函数
- 4.3.4.2 根据Map的key排序
- 4.3.4.3 根据Map的value排序
- 4.3.4.4 使用TreeMap按键排序
- 五.Stream的元素的匹配与查找
-
- 5.1 anyMatch()
- 5.2 allMatch()
- 5.3 noneMatch()
- 5.4 findFirst()
- 5.4 findAny()
- 六.Stream的元素归约
-
- 6.1 Integer类型归约
- 6.2 String类型归约
- 6.3 复杂对象归约
- 6.4 Combiner合并器的使用
- 七.Stream的元素聚合
-
- 7.1 max/min
- 7.2 summaryStatistics
- 八.管道流结果处理
-
- 8.1 ForEach和ForEachOrdered
- 8.2 元素的收集collect
-
- 8.2.1 收集为Set
- 8.2.2 收集为List
- 8.2.3 收集为Array
- 8.2.4 收集为Map
-
- 8.2.4.1 Map中的key和value反转
- 8.2.5 接合joining
- 8.2.6 分组收集groupingBy
-
- 8.2.6.1 按照属性分组
- 8.2.6.2 属性拼接分组
- 8.2.6.3 根据不同条件分组
- 8.2.6.4 多级分组
- 8.2.6.5 获取每组中的总种类量
- 8.2.6.6 获取每组中的总数量
- 8.2.6.7 获取每组中的数量最多的
- 8.2.6.8 联合其他收齐器
- 8.2.6.9 根据属性分组,收集为Map
- 8.2.6.10 案例
- 8.2.7 通用的收集方法
一.管道流的转换
- Java Stream就是一个数据流经的管道,并且在管道中对数据进行操作,然后流入下一个管道。
- 管道的功能包括:Filter(过滤)、Map(映射)、sort(排序)等,集合数据通过Java Stream管道处理之后,转化为另一组集合或数据输出。

1.数组转换为管道流
-
使用
Stream.of()方法,将数组转换为管道流。 -
使用
Arrays.stream()方法,将数组转换为管道流。
String[] array = {"Monkey", "Lion", "Giraffe", "Lemur"};
// 将数组转化为管道流
Stream<String> nameStrs2 = Stream.of(array);
Stream<String> nameStrs3 = Stream.of("Monkey", "Lion", "Giraffe", "Lemur");
String[] split = "hello".split("");
Stream<String> stream = Arrays.stream(split);
2.集合类对象转换为管道流
调用集合类的stream()方法,将集合类对象转换为管道流。
// List转换为管道流
List<String> list = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
Stream<String> streamFromList = list.stream();
// Set转换为管道流
Set<String> set = new HashSet<>(list);
Stream<String> streamFromSet = set.stream();
// Map转换到管道流
Map<String, Integer> codes = new HashMap<>();
codes.put("United States", 1);
Stream<Map.Entry<String, Integer>> stream = codes.entrySet().stream();
3.文本文件转换为管道流
通过Files.lines()方法将文本文件转换为管道流
Stream<String> lines = Files.lines(Paths.get("文本文件所在的路径"));
二.Stream的Filter与谓词逻辑
准备一个实体类Employee
import java.util.function.Predicate;
public class Employee {
private Integer id;
private Integer age;
private String gender;
private String firstName;
private String lastName;
// filter函数中lambda表达式为一次性使用的谓词逻辑。
// 若我们的谓词逻辑需要被多处、多场景、多代码中使用,通常将它抽取出来单独定义到它所限定的主语实体中。
public static Predicate<Employee> ageGreaterThan70 = x -> x.getAge() > 70;
public static Predicate<Employee> genderM = x -> x.getGender().equals("M");
// 省略构造方法,get,set方法,toString()方法
}
1.普通的filter函数过滤
List<Employee> employees = Arrays.asList("若干个Employee对象");
List<Employee> filtered = employees.stream()
// 由于使用了lambda表达式,此过滤逻辑只能在此处使用,如果想要在其他地方使用需要重新定义一遍
.filter(e -> e.getAge() > 70 && e.getGender().equals("M"))
.collect(Collectors.toList());
List<Person> filterList = persons.stream()
// 过滤出性别为1的person对象
.filter(p -> p.getSex().equals(1))
.collect(Collectors.toList());
2.谓词逻辑and的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.and(Employee.genderM))
.collect(Collectors.toList());
3.谓语逻辑or的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM))
.collect(Collectors.toList());
4.谓语逻辑negate(取反)的使用
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM).negate())
.collect(Collectors.toList());
三.Stream的Map操作
map函数的作用就是针对管道流中的每一个数据元素进行转换操作。
1.集合元素转换成大写
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
// 使用Stream管道流
List<String> collect = alpha
.stream()
// 使用map将集合中的每一个元素都转换为大写
.map(String::toUpperCase)
.collect(Collectors.toList());
// 上面使用了方法引用,和下面的lambda表达式语法效果是一样的
List<String> collect = alpha
.stream().map(s -> s.toUpperCase())
.collect(Collectors.toList());
2.集合元素类型的转换
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
List<Integer> lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); // [6, 4, 7, 5]
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);
// 将0和1的List转换为Boolean的List
List<String> alpha = Arrays.asList("1", "0", "0", "1");
List<Boolean> collect = alpha.stream()
.map(ele -> "1".equals(ele))
.collect(Collectors.toList());
3.对象数据格式转换
public static void main(String[] args){
// 准备一个List对象
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
// map的方式进行处理
List<Employee> maped = employees.stream()
.map(e -> {
// 将年龄全部+1
e.setAge(e.getAge() + 1);
// 对性别进行判断
e.setGender(e.getGender().equals("M") ? "male" : "female");
// 将处理后的对象返回
return e;
}).collect(Collectors.toList());
// peek的方式进行处理
List<Employee> maped = employees.stream()
// peek函数是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}
四.Stream的状态与并行操作
- 源操作:可以将数组、集合类、行文本文件转换成管道流Stream进行数据处理。
- 中间操作:对Stream流中的数据进行处理,比如:过滤、数据转换等等。
- 终端操作:作用就是将Stream管道流转换为其他的数据类型。
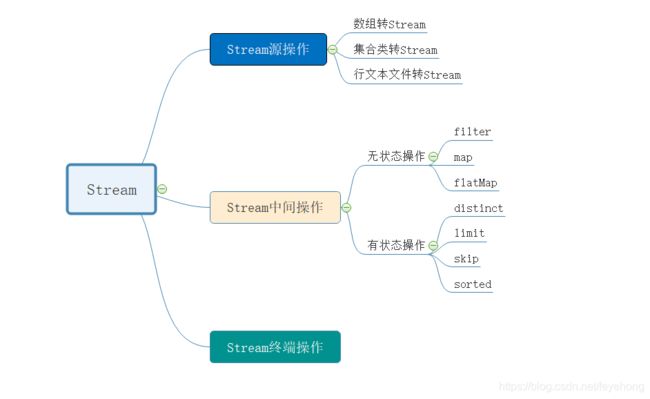
Stream中间操作
-
无状态:
filter与map操作,不需要管道流的前面后面元素相关,所以不需要额外的记录元素之间的关系。输入一个元素,获得一个结果。就像班级点名就是无状态的,喊到你你就答到就可以了。
-
有状态:
sorted是排序操作、distinct是去重操作。像这种操作都是和别的元素相关的操作,我自己无法完成整体操作。如果是班级同学按大小个排序,那就不是你自己的事了,你得和周围的同学比一下身高并记住,你记住的这个身高比较结果就是一种“状态”。所以这种操作就是有状态操作。
4.1.Limit与Skip管道数据截取
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
// limt方法传入一个整数n,用于截取管道中的前n个元素。
.limit(2)
.collect(Collectors.toList());
limitN.forEach(System.out::println); // [Monkey, Lion]
List<String> skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
// skip方法用于跳过前n个元素,截取从n到末尾的元素。
.skip(2)
.collect(Collectors.toList());
skipN.forEach(System.out::println); // [Giraffe, Lemur]
4.2.Distinct元素去重
List<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());
// 去重结果
["Monkey", "Lion", "Giraffe", "Lemur"]
4.3.Sorted排序
默认的情况下,sorted是按照字母的自然顺序进行排序。
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
// 去重结果
["Giraffe", "Lemur", "Lion", "Monkey"]
4.3.1字符串List排序
List<String> cities = Arrays.asList(
"Milan",
"london",
"San Francisco",
"Tokyo",
"New Delhi"
);
// 没有排序
System.out.println(cities); // [Milan, london, San Francisco, Tokyo, New Delhi]
// String.CASE_INSENSITIVE_ORDER(字母大小写不敏感)的规则排序
cities.sort(String.CASE_INSENSITIVE_ORDER);
System.out.println(cities); // [london, Milan, New Delhi, San Francisco, Tokyo]
// Comparator.naturalOrder()字母自然顺序排序
cities.sort(Comparator.naturalOrder());
System.out.println(cities); // [Milan, New Delhi, San Francisco, Tokyo, london]
// 使用Stream()的sorted的方式进行排序
cities.stream().sorted(Comparator.naturalOrder()).forEach(System.out::println);
//Milan
//New Delhi
//San Francisco
//Tokyo
//london
4.3.2整数类型List排序
List<Integer> numbers = Arrays.asList(6, 2, 1, 4, 9);
System.out.println(numbers); // [6, 2, 1, 4, 9]
numbers.sort(Comparator.naturalOrder()); // 自然排序
System.out.println(numbers); // [1, 2, 4, 6, 9]
numbers.sort(Comparator.reverseOrder()); // 倒序排序
System.out.println(numbers); // [9, 6, 4, 2, 1]
4.3.3按对象字段对List排序
准备数据
public class Employee {
private Integer id;
private Integer age;
private String gender;
private String firstName;
private String lastName;
// 省略get和set和toString()
}
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
升序
- 按照对象中的年龄进行排序(默认是升序)
- 都是正序 ,不加reversed
employees.sort(Comparator.comparing(Employee::getAge));
employees.forEach(System.out::println);
降序
- 按照对象中的年龄进行排序(指定排序方式为降序)
- 都是倒序,最后面加一个reserved
employees.sort(Comparator.comparing(Employee::getAge).reversed());
先升序后降序
- 需要降序的属性添加
Comparator.reverseOrder()
employees.sort(
// 先按照性别的正序排序
Comparator.comparing(Employee::getGender)
// 然后再按照年龄的倒叙排序
.thenComparing(Employee::getAge, Comparator.reverseOrder())
);
employees.forEach(System.out::println);
// 打印结果
Employee{id=7, age=68, gender='F', firstName='Melissa', lastName='Roy'}
Employee{id=5, age=19, gender='F', firstName='Cristine', lastName='Maria'}
Employee{id=9, age=15, gender='F', firstName='Neetu', lastName='Singh'}
Employee{id=2, age=13, gender='F', firstName='Martina', lastName='Hengis'}
Employee{id=8, age=79, gender='M', firstName='Alex', lastName='Gussin'}
Employee{id=10, age=45, gender='M', firstName='Naveen', lastName='Jain'}
Employee{id=3, age=43, gender='M', firstName='Ricky', lastName='Martin'}
Employee{id=4, age=26, gender='M', firstName='Jon', lastName='Lowman'}
Employee{id=1, age=23, gender='M', firstName='Rick', lastName='Beethovan'}
Employee{id=6, age=15, gender='M', firstName='David', lastName='Feezor'}
4.3.4 对Map排序
- 将Map或List等集合类对象转换为Stream对象
- 使用Streams的
sorted()方法对其进行排序 - 最终将其返回为
LinkedHashMap(可以保留排序顺序)
sorted()方法以aComparator作为参数,从而可以按任何类型的值对Map进行排序。
4.3.4.1 HashMap的merge()函数
该函数应用场景就是当Key重复的时候,如何处理Map的元素值。
- 参数一:向map里面put的键
- 参数二:向map里面put的值
- 参数三:如果键发生重复,如何处理值.可以是一个函数,也可以写成lambda表达式。
String k1 = "key";
String k2 = "key";
String k3 = "key3";
// 初始化一个HashMap,并向其中放入值
HashMap<String, Integer> map = new HashMap<String, Integer>() {{
put(k1, 1);
}};
// 由于k1和k2的值都是key,因此key发生冲突的时候,就启用参数三的lambda表达式
map.merge(k2, 2, (oldVal, newVal) -> oldVal + newVal);
map.merge(k3, 2, (oldVal, newVal) -> oldVal + newVal);
System.out.println(map);
// 打印结果
{
key3=2,
key=3
}
4.3.4.2 根据Map的key排序
-
请注意使用
LinkedHashMap来存储排序的结果以保持顺序。 -
默认情况下,
Collectors.toMap()返回HashMap。HashMap不能保证元素的顺序。
// 创建一个Map,并放入数据
Map<String, Integer> codes = new HashMap<String, Integer>(){{
// 在初始化的时候,就放入数据
put("United States", 1);
put("Germany", 49);
put("France", 33);
put("China", 86);
put("Pakistan", 92);
}};
// 根据Map的键进行排序
Map<String, Integer> sortedMap = codes.entrySet().stream()
// 根据Map的key进行排序
.sorted(Map.Entry.comparingByKey())
.collect(
// 把Stream流排序后的结果收集为Map
Collectors.toMap(
// 使用Map原本的key和value
Map.Entry::getKey,
Map.Entry::getValue,
// 当主键有相同的情况,发生主键冲突的时候,使用旧主键所对应的值
(oldVal, newVal) -> oldVal,
// 收集之后的Map值一个LinkedHashMap类型(有顺序的Map)
LinkedHashMap::new
)
);
sortedMap.entrySet().forEach(System.out::println);
// 打印结果
China=86
France=33
Germany=49
Pakistan=92
United States=1
4.3.4.3 根据Map的value排序
Map<String, Integer> sortedMap2 = codes.entrySet().stream()
// 根据Map的value进行排序
.sorted(Map.Entry.comparingByValue())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new));
sortedMap2.entrySet().forEach(System.out::println);
// 打印结果
China=86
France=33
Germany=49
Pakistan=92
United States=1
4.3.4.4 使用TreeMap按键排序
TreeMap内的元素是有顺序的,所以利用TreeMap排序也是可取的一种方法。您需要做的就是创建一个TreeMap对象,并将数据从HashMapput到TreeMap中
// 将HashMap转为TreeMap
Map<String, Integer> sorted = new TreeMap<>(codes);
sorted.entrySet().forEach(System.out::println);
// 打印结果
China=86
France=33
Germany=49
Pakistan=92
United States=1
五.Stream的元素的匹配与查找
在我们对数组或者集合类进行操作的时候,经常会遇到这样的需求,比如:
- 是否包含某一个“匹配规则”的元素
- 是否所有的元素都符合某一个“匹配规则”
- 是否所有元素都不符合某一个“匹配规则”
- 查找第一个符合“匹配规则”的元素
- 查找任意一个符合“匹配规则”的元素
5.1 anyMatch()
判断Stream流中是否包含某一个“匹配规则”的元素,返回一个布尔值.
// 判断employees列表中,是否有年龄 > 72岁的对象存在
boolean isExistAgeThan72 = employees.stream().anyMatch(e -> e.getAge() > 72);
5.2 allMatch()
判断是够Stream流中的所有元素都符合某一个"匹配规则",返回一个布尔值
// 判断employees列表中,是否所有的对象的年龄 > 10岁
boolean isExistAgeThan10 = employees.stream().allMatch(e -> e.getAge() > 10);
5.3 noneMatch()
判断是否Stream流中的所有元素都不符合某一个"匹配规则",返回一个布尔值
// 判断employees列表中,是否有年龄 < 18岁的对象存在
boolean isExistAgeLess18 = employees.stream().noneMatch(e -> e.getAge() < 18);
5.4 findFirst()
查找第一个符合“匹配规则”的元素,返回值为Optional
// 返回第一个年龄 > 40岁的对象(可能有若干个这样的对象,但是只返回第一个)
Optional<Employee> employeeOptional
= employees.stream().filter(e -> e.getAge() > 40).findFirst();
System.out.println(employeeOptional.get());
5.4 findAny()
查找任意一个符合“匹配规则”的元素,返回值为Optional
Optional<Employee> employeeOptional
= employees.stream().filter(e -> e.getAge() > 40).findAny();
System.out.println(employeeOptional.get());
六.Stream的元素归约
Stream API为我们提供了Stream.reduce用来实现集合元素的归约。reduce函数有三个参数:
- Identity标识:一个元素,它是归约操作的初始值,如果流为空,则为默认结果。
- Accumulator累加器:具有两个参数的函数:归约运算的部分结果和流的下一个元素。
- Combiner合并器(可选):当归约并行化时,或当累加器参数的类型与累加器实现的类型不匹配时,用于合并归约操作的部分结果的函数。
6.1 Integer类型归约
// 1 + 2 + 3 + 4 + 5 + 6
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
int result = numbers
.stream()
// 参数1为0,代码累加的初始值
// 参数2为一个函数,表示元素累加
.reduce(0, (subtotal, element) -> subtotal + element);
System.out.println(result); // 21
int result = numbers
.stream()
// 进行归约
.reduce(0, Integer::sum);
System.out.println(result); // 21
6.2 String类型归约
不仅可以归约Integer类型,只要累加器参数类型能够匹配,可以对任何类型的集合进行归约计算。
List<String> letters = Arrays.asList("a", "b", "c", "d", "e");
String result = letters
.stream()
// 初始值是一个空字符串
.reduce("", (partialString, element) -> partialString + element);
System.out.println(result); // abcde
String result = letters
.stream()
.reduce("", String::concat);
System.out.println(result); // abcde
6.3 复杂对象归约
准备数据
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
计算列表中所有对象的年龄的和
Integer total = employees.stream()
// 先获取出所有对象的年龄
.map(Employee::getAge)
// 对所有的年龄进行归约,求和
.reduce(0,Integer::sum);
System.out.println(total); // 346
6.4 Combiner合并器的使用
- 除了使用map函数实现类型转换后的集合归约,我们还可以用Combiner合并器来实现,这里第一次使用到了Combiner合并器。
- 因为Stream流中的元素是Employee,累加器的返回值是Integer,所以二者的类型不匹配。这种情况下可以使用Combiner合并器对累加器的结果进行二次归约,相当于做了类型转换。
Integer total3 = employees.stream()
// 没有使用map来获取对象中的年龄,所以Stream流中的数据实际上是employe对象
// 注意这里reduce方法有三个参数
.reduce(0,(totalAge,emp) -> totalAge + emp.getAge(),Integer::sum);
System.out.println(total); // 346
并行流数据归约(使用合并器)
对于大数据量的集合元素归约计算,更能体现出Stream并行流计算的威力。

在进行并行流计算的时候,可能会将集合元素分成多个组计算。为了更快的将分组计算结果累加,可以使用合并器。
Integer total2 = employees
.parallelStream()
.map(Employee::getAge)
// 注意这里reduce方法有三个参数
.reduce(0,Integer::sum,Integer::sum);
System.out.println(total); //346
七.Stream的元素聚合
7.1 max/min
⏹获取最长的字符串
List<String> list = Arrays.asList("abc", "egjsdfhkj", "sdf", "xbasefwefefngd", "eeeeeeeeeeeeeee");
String str = list.stream().max(Comparator.comparing(String::length)).orElse("");
System.out.println(str); // eeeeeeeeeeeeeee
⏹获取最大的数值
// Java9的数组创建方式
List<Integer> integers = List.of(7, 6, 9, 4, 11, 6);
integers.stream().max(Integer::compareTo).ifPresent(System.out::println); // 11
⏹获取工资最高的人
// 获取工资最高的人
List<Person> personList = new ArrayList<>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));
Optional<Person> maxPerson = personList.stream().max(Comparator.comparingInt(Person::getSalary));
maxPerson.ifPresent(System.out::println);
// Person{name='Owen', salary=9500, age=25, sex='male', area='New York'}
7.2 summaryStatistics
参考这篇博客: https://blog.csdn.net/feyehong/article/details/125640378
八.管道流结果处理

- 第一阶段(图中蓝色):将集合、数组、或行文本文件转换为
java管道流 - 第二阶段(图中虚线部分):管道流式数据处理操作,处理管道中的每一个元素。上一个管道中的输出元素作为下一个管道的输入元素。
- 第三阶段(图中绿色):管道流结果处理操作,最后的处理部分
8.1 ForEach和ForEachOrdered
若只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,
我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);
parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。
8.2 元素的收集collect
java Stream 最常见的用法就是:
-
将集合类转换成管道流。
-
对管道流数据处理。
-
将管道流处理结果在转换成集合类。
collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
8.2.1 收集为Set
Set<String> collectToSet = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.collect(Collectors.toSet());
// 最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
8.2.2 收集为List
List<String> collectToList = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.collect(Collectors.toList());
// 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
2022/07/06 补充
Java17 对收集为List做了进一步简化,不需要使用 .collect()进行收集,直接使用.toList()进行转换即可
List<String> collectToList = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion").toList();
// 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
8.2.3 收集为Array
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.toArray(String[]::new);
// 最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
8.2.4 收集为Map
-
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。
-
我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数
distinct()来确保Map键值的唯一性。
Map<String, Integer> toMap =
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toMap(
// 元素输入就是输出,作为key
Function.identity(),
// 输入元素的不同的字母个数,作为value
s -> (int) s.chars().distinct().count()
)
);
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}
⏹收集为Map方式
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
// 1.⏹对象List收集为Map
Map<String, String> collect = personList.stream()
.collect(
Collectors.toMap(
// name作为key
Person::getName,
// sex作为value
Person::getSex
)
);
System.out.println(collect);
// 2.⏹对象List收集为Map
Map<String, Person> personMap = personList.stream()
.collect(
Collectors.toMap(
// person中的name作为key
Person::getName,
//person实体类原封不动的作为value
item -> item
)
);
System.out.println(personMap);
// {Tom=Person{name='Tom', salary=8900, age=23, sex='male', area='New York'}, Anni=Person{name='Anni', salary=8200, age=24, sex='female', area='New York'}, ...省略...}
8.2.4.1 Map中的key和value反转
Map<Integer, String> genderValNameMap = new HashMap<>() {
{
put(1, "男");
put(0, "女");
}
};
System.out.println(genderValNameMap); // {0=女, 1=男}
Map<String, Integer> genderNameValMap = genderValNameMap.entrySet().stream().collect(
Collectors.toMap(
Map.Entry::getValue,
Map.Entry::getKey
)
);
System.out.println(genderNameValMap); // {女=0, 男=1}
8.2.5 接合joining
将流中的元素,用指定的连接符拼接起来
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string); // 拼接后的字符串:A-B-C
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
String names = personList.stream()
.map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names); // Tom,Jack,Lily
8.2.6 分组收集groupingBy
准备数据
import java.math.BigDecimal;
public class Product {
// 商品id
private Long id;
// 商品数量
private Integer num;
// 商品价格
private BigDecimal price;
// 商品名称
private String name;
// 商品种类
private String category;
public Product(Long id, Integer num, BigDecimal price,
String name, String category) {
this.id = id;
this.num = num;
this.price = price;
this.name = name;
this.category = category;
}
// 省略get和set和toString()
}
// 创建若干个对象,然后放到List中
Product prod1 = new Product(1L, 1, new BigDecimal("15.5"), "面包", "零食");
Product prod2 = new Product(2L, 2, new BigDecimal("20"), "饼干", "零食");
Product prod3 = new Product(3L, 3, new BigDecimal("30"), "月饼", "零食");
Product prod4 = new Product(4L, 3, new BigDecimal("10"), "青岛啤酒", "啤酒");
Product prod5 = new Product(5L, 10, new BigDecimal("15"), "百威啤酒", "啤酒");
List<Product> prodList = Arrays.asList(prod1, prod2, prod3, prod4, prod5);
8.2.6.1 按照属性分组
// 按照category进行分类
Map<String, List<Product>> categoryMap = prodList.stream().collect(Collectors.groupingBy(Product::getCategory));
System.out.println(categoryMap);
// 打印结果
{
啤酒=[Product{id=4, num=3, price=10, name='青岛啤酒', category='啤酒'},
Product{id=5, num=10, price=15, name='百威啤酒', category='啤酒'}],
零食=[Product{id=1, num=1, price=15.5, name='面包', category='零食'},
Product{id=2, num=2, price=20, name='饼干', category='零食'},
Product{id=3, num=3, price=30, name='月饼', category='零食'}]
}
8.2.6.2 属性拼接分组
// 按照属性拼接分组
Map<String, List<Product>> categoryMap1 = prodList.stream().collect(Collectors.groupingBy(item -> {
return item.getCategory() + "_" + item.getName();
}));
System.out.println(categoryMap1);
// 打印结果
{
零食_月饼=[Product{id=3, num=3, price=30, name='月饼', category='零食'}],
零食_面包=[Product{id=1, num=1, price=15.5, name='面包', category='零食'}],
啤酒_百威啤酒=[Product{id=5, num=10, price=15, name='百威啤酒', category='啤酒'}],
啤酒_青岛啤酒=[Product{id=4, num=3, price=10, name='青岛啤酒', category='啤酒'}],
零食_饼干=[Product{id=2, num=2, price=20, name='饼干', category='零食'}]
}
8.2.6.3 根据不同条件分组
// 商品数量是否小于3进行分组
Map<String, List<Product>> categoryMap2 = prodList.stream().collect(Collectors.groupingBy(item -> {
return item.getNum() < 3 ? "小于3" : "other";
}));
System.out.println(categoryMap2);
// 打印结果
{
other=[
Product{id=3, num=3, price=30, name='月饼', category='零食'},
Product{id=4, num=3, price=10, name='青岛啤酒', category='啤酒'},
Product{id=5, num=10, price=15, name='百威啤酒', category='啤酒'}],
小于3=[
Product{id=1, num=1, price=15.5, name='面包', category='零食'},
Product{id=2, num=2, price=20, name='饼干', category='零食'}
]
}
8.2.6.4 多级分组
要实现多级分组,我们可以使用一个由双参数版本的Collectors.groupingBy工厂方法创 建的收集器,它除了普通的分类函数之外,还可以接受collector类型的第二个参数。
要进 行二级分组的话,我们可以把一个内层groupingBy传递给外层groupingBy,并定义一个为流 中项目分类的二级标准。
Map<String, Map<String, List<Product>>> categoryMap3 =
prodList.stream().collect(
// 分组
Collectors.groupingBy(
// 先根据产品类型分组
Product::getCategory,
// 然后再根据产品数量是否小于3进行分组
Collectors.groupingBy(item -> {
return item.getNum() < 3 ? "小于3" : "other";
})
)
);
System.out.println(categoryMap3);
// 打印结果
{
啤酒={
other=[
Product{id=4, num=3, price=10, name='青岛啤酒', category='啤酒'},
Product{id=5, num=10, price=15, name='百威啤酒', category='啤酒'}
]
},
零食={
other=[
Product{id=3, num=3, price=30, name='月饼', category='零食'}
],
小于3=[
Product{id=1, num=1, price=15.5, name='面包', category='零食'},
Product{id=2, num=2, price=20, name='饼干', category='零食'}
]
}
}
8.2.6.5 获取每组中的总种类量
// 求种类的总数
Map<String, Long> mapCount = prodList.stream().
collect(
Collectors.groupingBy(
// 根据种类型进行分组
Product::getCategory,
// 计算每个种类的数量
Collectors.counting()
)
);
System.out.println(mapCount);
// 打印结果
{
// 一共有两种啤酒
啤酒=2,
// 一共有三种零食
零食=3
}
8.2.6.6 获取每组中的总数量
// 根据种类求总的数量
Map<String, Integer> mapAllCount = prodList.stream()
.collect(
Collectors.groupingBy(
// 根据类型进行分组
Product::getCategory,
// 计算每个类型的总的数量
Collectors.summingInt(Product::getNum)
)
);
System.out.println(mapAllCount);
// 打印结果
{
// 啤酒一共有13个(10个百威啤酒,3个青岛啤酒)
啤酒=13,
// 零食一共有6个(1个面包,2个饼干,3个月饼)
零食=6
}
8.2.6.7 获取每组中的数量最多的
// 每种商品中数量最多的
Map<String, Product> collect = prodList.stream()
.collect(
Collectors.toMap(
// 根据商品种类进行分组
Product::getCategory,
// 元素输入就是输出
Function.identity(),
// 根据商品的数量进行比较,取数量最多的商品
BinaryOperator.maxBy(Comparator.comparingInt(Product::getNum)
)
)
);
System.out.println(collect);
// 打印结果
{
// 啤酒类商品中,百威啤酒最多,有10瓶
啤酒=Product{id=5, num=10, price=15, name='百威啤酒', category='啤酒'},
// 零食类商品中,月饼最多,有3个
零食=Product{id=3, num=3, price=30, name='月饼', category='零食'}
}
8.2.6.8 联合其他收齐器
Map<String, Set<String>> prodMap = prodList.stream()
.collect(
Collectors.groupingBy(
// 根据商品的种类进行分组
Product::getCategory,
// 对商品的名称进行遍历,使用Set进行去重
Collectors.mapping(Product::getName, Collectors.toSet())
)
);
System.out.println(prodMap);
// 打印结果
{
啤酒=[青岛啤酒, 百威啤酒],
零食=[面包, 饼干, 月饼]
}
8.2.6.9 根据属性分组,收集为Map>
需求:根据国家地区code进行分组,将消息code和消息放入Map中
⏹实体类
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class I18MessageEnttiy {
// 消息code
private String code;
// 国家地区码
private String locale;
// 消息
private String item;
}
List<I18MessageEnttiy> allLocaleMessage = Arrays.asList(
new I18MessageEnttiy("M001", "zh", "姓名"),
new I18MessageEnttiy("M001", "ja", "名前"),
new I18MessageEnttiy("M002", "zh", "邮箱"),
new I18MessageEnttiy("M002", "ja", "メールアドレス"),
new I18MessageEnttiy("M003", "zh", "电视"),
new I18MessageEnttiy("M003", "ja", "テレビ"),
new I18MessageEnttiy("M004", "zh", "中文系统"),
new I18MessageEnttiy("M004", "ja", "日本語システム")
);
// 将查询到的国际化资源转换为 Map<地区码, Map> 的数据格式
Map<String, Map<String, String>> localeMsgMap = allLocaleMessage
// stream流
.stream()
// 分组
.collect(Collectors.groupingBy(
// 根据国家地区分组
I18MessageEnttiy::getLocale,
// 收集为Map,key为code,value为信息
Collectors.toMap(
I18MessageEnttiy::getCode
, I18MessageEnttiy::getItem
)
));
System.out.println(localeMsgMap);
/*
{
ja={
M004=日本語システム
, M003=テレビ
, M002=メールアドレス
, M001=名前
}
, zh={
M004=中文系统
, M003=电视
, M002=邮箱
, M001=姓名
}
}
*/
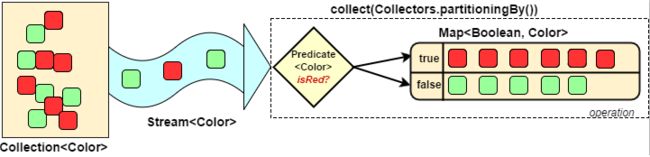
8.2.6.10 案例
实体类List
List<Person> personList = new ArrayList<>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
⏹将员工按薪资是否高于8000分组
Map<Boolean, List<Person>> part = personList.stream()
.collect(
Collectors.partitioningBy(item -> item.getSalary() > 8000)
);
System.out.println(part);
/*
{
false=[
Person{name='Jack', salary=7000, age=25, sex='male', area='Washington'},
Person{name='Lily', salary=7800, age=21, sex='female', area='Washington'}
],
true=[
Person{name='Tom', salary=8900, age=23, sex='male', area='New York'},
Person{name='Anni', salary=8200, age=24, sex='female', area='New York'}
]
}
*/
⏹将员工按性别分组
Map<String, List<Person>> group = personList.stream()
.collect(
Collectors.groupingBy(Person::getSex)
);
System.out.println(group);
/*
{
female=[
Person{name='Lily', salary=7800, age=21, sex='female', area='Washington'},
Person{name='Anni', salary=8200, age=24, sex='female', area='New York'}
],
male=[
Person{name='Tom', salary=8900, age=23, sex='male', area='New York'},
Person{name='Jack', salary=7000, age=25, sex='male', area='Washington'}
]
}
*/
⏹将员工先按性别分组,再按地区分组
Map<String, Map<String, List<Person>>> group2 = personList.stream()
.collect(
// 进行分组收集
Collectors.groupingBy(
// 先按照性别分组
Person::getSex,
// 然后再按照区域收集
Collectors.groupingBy(Person::getArea)
)
);
System.out.println(group2);
/*
{
female={
New York=[
Person{name='Anni', salary=8200, age=24, sex='female', area='New York'}
],
Washington=[
Person{name='Lily', salary=7800, age=21, sex='female', area='Washington'}
]
},
male={
New York=[
Person{name='Tom', salary=8900, age=23, sex='male', area='New York'}
],
Washington=[
Person{name='Jack', salary=7000, age=25, sex='male', area='Washington'}
]
}
}
*/
8.2.7 通用的收集方法
可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList<String> collectToCollection = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
).collect(Collectors.toCollection(LinkedList::new));
// 最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]