分布式Trace:横跨几十个分布式组件的慢请求要如何排查?
目录
前言
一、问题的出现?
二、一体化架构中的慢请求排查如何做
三、分布式 Trace原理
四、如何来做分布式 Trace
前言
在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
处理一个Web请求要调用的多个服务,为了能更方便的查询哪个环节的服务出现了问题,现在常用的解决方案是为整个系统引入分布式链路跟踪。
一、问题的出现?
通过监控发现,系统的核心下单接口在晚高峰的时候,会有少量的慢请求,用户也投诉在 APP 上下单时,等待的时间比较长。而下单的过程可能会调用多个RPC 服务,或者使用多个资源,一时之间,你很难快速判断,究竟是哪个服务或者资源出了问题,从而导致整体流程变慢,于是,你和你的团队开始想办法如何排查这个问题。
二、一体化架构中的慢请求排查如何做
因为在分布式环境下,请求要在多个服务之间调用,所以对于慢请求问题的排查会更困难,我们不妨从简单的入手,先看看在一体化架构中,是如何排查这个慢请求的问题的。
最简单的思路是:打印下单操作的每一个步骤的耗时情况,然后通过比较这些耗时的数据,找到延迟最高的一步,然后再来看看这个步骤要如何的优化。如果有必要的话,你还需要针对步骤中的子步骤,再增加日志来继续排查,简单的代码就像下面这样:
long start = System.currentTimeMillis();
processA();
Logs.info("process A cost " + (System.currentTimeMillis() - start));// 打印 A 步
start = System.currentTimeMillis();
processB();
Logs.info("process B cost " + (System.currentTimeMillis() - start));// 打印 B 步
start = System.currentTimeMillis();
processC();
Logs.info("process C cost " + (System.currentTimeMillis() - start));// 打印 C 步这是最简单的实现方式,打印出日志后,我们可以登录到机器上,搜索关键词来查看每个步骤的耗时情况。
虽然这个方式比较简单,但你可能很快就会遇到问题:由于同时会有多个下单请求并行处理,所以,这些下单请求的每个步骤的耗时日志,是相互穿插打印的。你无法知道这些日志,哪些是来自于同一个请求,也就不能很直观地看到,某一次请求耗时最多的步骤是哪一步了。那么,你要如何把单次请求,每个步骤的耗时情况串起来呢?
一个简单的思路是:给同一个请求的每一行日志,增加一个相同的标记。这样,只要拿到这个标记就可以查询到这个请求链路上,所有步骤的耗时了,我们把这个标记叫做requestId,我们可以在程序的入口处生成一个 requestId,然后把它放在线程的上下文中,这样就可以在需要时,随时从线程上下文中获取到 requestId 了。简单的代码实现就像下面这样:
String requestId = UUID.randomUUID().toString();
//requestId 存储在线程上下文中
ThreadLocal tl = new ThreadLocal() {
@Override
protected String initialValue() {
return requestId; }
};
long start = System.currentTimeMillis();
processA();
Logs.info("rid : " + tl.get() + ", process A cost " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
processB();
Logs.info("rid : " + tl.get() + ", process B cost " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
processC();
Logs.info("rid : " + tl.get() + ", process C cost " + (System.currentTimeMillis() - start)); 有了 requestId,你就可以清晰地了解一个调用链路上的耗时分布情况了。于是,你给你的代码增加了大量的日志,来排查下单操作缓慢的问题。很快, 你发现是某一个数据库查询慢了才导致了下单缓慢,然后你优化了数据库索引,问题最终得到了解决。
正当你要松一口气的时候,问题接踵而至:又有用户反馈某些商品业务打开缓慢;商城首页打开缓慢。你开始焦头烂额地给代码中增加耗时日志,而这时你意识到,每次排查一个接口就需要增加日志、重启服务,这并不是一个好的办法,于是你开始思考解决的方案。
其实,从我的经验出发来说,一个接口响应时间慢,一般是出在跨网络的调用上,比如说请求数据库、缓存或者依赖的第三方服务。所以,我们只需要针对这些调用的客户端类,做切面编程,通过插入一些代码打印它们的耗时就好了。
一次请求可能要打印十几条日志,如果你的电商系统的 QPS 是 10000 的话,就是每秒钟会产生十几万条日志,对于磁盘 I/O 的负载是巨大的,那么这时,你就要考虑如何减少日志的数量。
你可以考虑对请求做采样,采样的方式也简单,比如你想采样 10% 的日志,那么你可以只打印“requestId%10==0”的请求。
有了这些日志之后,当给你一个 requestId 的时候,你发现自己并不能确定这个请求到了哪一台服务器上,所以你不得不登陆所有的服务器,去搜索这个 requestId 才能定位请求。这样无疑会增加问题排查的时间。
你可以考虑的解决思路是:把日志不打印到本地文件中,而是发送到消息队列里,再由消息处理程序写入到集中存储中,比如 Elasticsearch。这样,你在排查问题的时候,只需要拿着 requestId 到 Elasticsearch 中查找相关的记录就好了。在加入消息队列和Elasticsearch 之后,我们这个排查程序的架构图也会有所改变:

三、分布式 Trace原理
在分布式链路跟踪中有两个重要的概念:跟踪(trace)和 跨度( span)。trace 是请求在分布式系统中的整个链路视图,span 则代表整个链路中不同服务内部的视图,span 组合在一起就是整个 trace 的视图。
在整个请求的调用链中,请求会一直携带 traceid 往下游服务传递,每个服务内部也会生成自己的 spanid 用于生成自己的内部调用视图,并和traceid一起传递给下游服务。
traceid 在请求的整个调用链中始终保持不变,所以在日志中可以通过 traceid 查询到整个请求期间系统记录下来的所有日志。请求到达每个服务后,服务都会为请求生成spanid,而随请求一起从上游传过来的上游服务的 spanid 会被记录成parent-spanid或者叫 pspanid。当前服务生成的 spanid 随着请求一起再传到下游服务时,这个spanid 又会被下游服务当做 pspanid 记录。
通过在访问日志和业务日志里记录的traceid、spanid 和 pspanid 能完整的还原出整个请求的调用链路视图,对错误排查能起到很大的帮助。
上面就是分布式链路跟踪的原理,我们可以自己实现,也可以依赖 opentracing 这种开源的解决方案。一般是在请求到达网关的开始,生成本次请求的traceid 和 在网关服务内的spanid ,将他们放在HTTP 请求头或者RPC调用的元数据里,在调用下游服务时继续向下传递。下游的RESTful API服务的全局路由中间件和RPC服务的拦截器里会接收请求携带的traceid 和生成当次请求在服务内部的spanid,从上游接收到的 spanid 在这里会被转换成 pspanid。除此之外我们甚至可以把 traceid 和 spanid 注入到一些数据库连接池应用里,让记录的慢SQL日志里同样能打上 traceid 和 spanid 信息,为请求的响应过慢提供有效的分析数据。
四、如何来做分布式 Trace
你可能会问:题目既然是“分布式 Trace:横跨几十个分布式组件的慢请求要如何排查?”,那么我为什么要花费大量的篇幅,来说明在一体化架构中如何排查问题呢?这是因为在分布式环境下,你基本上也是依据上面,我提到的这几点来构建分布式追踪的中间件的。
在一体化架构中,单次请求的所有的耗时日志,都被记录在一台服务器上,而在微服务的场景下,单次请求可能跨越多个 RPC 服务,这就造成了,单次的请求的日志会分布在多个服务器上。
当然,你也可以通过 requestId 将多个服务器上的日志串起来,但是仅仅依靠 requestId很难表达清楚服务之间的调用关系,所以从日志中,就无法了解服务之间是谁在调用谁。因此,我们采用 traceId + spanId 这两个数据维度来记录服务之间的调用关系(这里traceId 就是 requestId),也就是使用 traceId 串起单次请求,用 spanId 记录每一次RPC 调用。说起来可能比较抽象,我给你举一个具体的例子。
比如,你的请求从用户端过来,先到达 A 服务,A 服务会分别调用 B 和 C 服务,B 服务又会调用 D 和 E 服务。
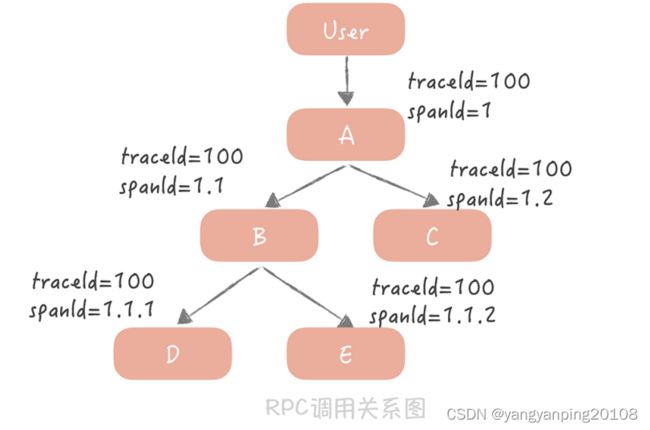
我来给你讲讲图中的内容:
用户到 A 服务之后会初始化一个 traceId 为 100,spanId 为 1;A 服务调用 B 服务时,traceId 不变,而 spanId 用 1.1 标识,代表上一级的 spanId 是1,这一级的调用次序是 1;A 调用 C 服务时,traceId 依然不变,spanId 则变为了 1.2,代表上一级的 spanId 还是 1,而调用次序则变成了 2,以此类推。
通过这种方式,我们可以在日志中,清晰地看出服务的调用关系是如何的,方便在后续计算中调整日志顺序,打印出完整的调用链路。那么 spanId 是何时生成的,又是如何传递的呢?
首先,A 服务在发起 RPC 请求服务 B 前,先从线程上下文中获取当前的 traceId 和spanId,然后,依据上面的逻辑生成本次 RPC 调用的 spanId,再将 spanId 和 traceId 序列化后,装配到请求体中,发送给服务方 B。
服务方 B 获取请求后,从请求体中反序列化出 spanId 和 traceId,同时设置到线程上下文中,以便给下次 RPC 调用使用。在服务 B 调用完成返回响应前,计算出服务 B 的执行时间发送给消息队列。
当然,在服务 B 中,你依然可以使用切面编程的方式,得到所有调用的数据库、缓存、HTTP 服务的响应时间,只是在发送给消息队列的时候,要加上当前线程上下文中的spanId 和 traceId。
这样,无论是数据库等资源的响应时间,还是 RPC 服务的响应时间就都汇总到了消息队列中,在经过一些处理之后,最终被写入到 Elasticsearch 中以便给开发和运维同学查询使用。
而在这里,你大概率会遇到的问题还是性能的问题,也就是因为引入了分布式追踪中间件,导致对于磁盘 I/O 和网络 I/O 的影响,而我给你的“避坑”指南就是:如果你是自研的分布式 trace 中间件,那么一定要提供一个开关,方便在线上随时将日志打印关闭;如果使用开源的组件,可以开始设置一个较低的日志采样率,观察系统性能情况再调整到一个合适的数值。