python pytorch 超详细线性回归原理解析加代码实现-小白入门级
python 线性回归
答应老师做的一个系列教程,也是头一次花这吗大精力去写一篇基础的文档,里面虽然有不少的公式,但只要能顺着看下来会发现都是非常基础的公式都是特别简单的。
文章目录
- python 线性回归
-
-
- 计算回归任务的损失
- 梯度下降的原理
- 模型参数的更新过程
- python基础库实现
-
学习目标:
- 了解深度学学习的结构基本过程和原理
模型(函数): f ( x ) = w x + b f(x)=wx+b f(x)=wx+b
数据集:
| NO. | x | y |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 5 |
| 2 | 3 | 7 |
| 3 | 4 | 9 |
一个训练样本: 一组 ( x , y ) (x,y) (x,y) 例:第0组训练样本 ( x 0 , y 0 ) = ( 1 , 3 ) (x_0,y_0)=(1,3) (x0,y0)=(1,3)
x为输入数据,y为预测标签/目标值/希望被拟合的值
任务:寻找合适的 w w w和 b b b使得 f ( x ) = w x + b f(x)=wx+b f(x)=wx+b可以拟合上表中的数据
- 怎么具体描述拟合?
- 就是让所有训练样本中每个训练的样本的 x i x_i xi值经过模型(函数)之后的输出 f ( x i ) f(x_i ) f(xi)更接近其对应的 y i y_i yi看距离的变化,距离小证明拟合的效果越好,距离越大证明拟合的越差,在这个任务里我们选择用两个数据差的平方和也就是欧式距离来作为衡量指标,也被我们称为损失,那计算距离的函数也就被称作损失函数.
计算回归任务的损失
在 w w w, b b b已知的情况下,模型(函数)可表示为
f ( x ) = w x + b f(x)=wx+b f(x)=wx+b
定义一个训练样本损失的计算函数
L ( x ) = ( f ( x ) − y ) 2 L(x) = (f(x)-y)^2 L(x)=(f(x)−y)2
如果输入的数据为 x 0 x_0 x0,其对应的目标值为 y 0 y_0 y0则经过模型之后的损失可表示为:
L ( x 0 ) = ( f ( x 0 ) − y 0 ) 2 L(x_0) = (f(x_0)-y_0)^2 L(x0)=(f(x0)−y0)2
我们选择用数据集中的前三组数据来作为训练数据,为了让模型能更好的拟合所有的数据,所以希望的是所有训练样本损失变小,我们的总体损失函数 L o s s ( x ) Loss(x) Loss(x)可表示为
L o s s ( x ) = ∑ i = 0 k L ( x i ) k = 2 x = [ 1 , 2 , 3 ] y = [ 3 , 5 , 7 ] Loss(x) = \sum_{i=0}^{k} L(x_i)\quad k=2\quad x=[1,2,3]\quad y=[3,5,7] Loss(x)=i=0∑kL(xi)k=2x=[1,2,3]y=[3,5,7]
即:
L o s s ( x ) = L ( x 0 ) + L ( x 1 ) + L ( x 2 ) Loss(x) =L(x_0)+L(x_1)+L(x_2) Loss(x)=L(x0)+L(x1)+L(x2)
在输入数据和模型参数 w , b w,b w,b已知的情况下,模型的总体损失是一个固定值
接下来转换思路,现在训练样本 x x x已知,我们的目的是求 w , b w,b w,b使总体损失最小,则我们将 w , b w,b w,b作为自变量,构建一个随着 w , b w,b w,b变化的而变化的损失函数,然后去搜索使这个函数值最小的 w , b w,b w,b的值.
在 x x x已知的情况下,模型(函数)表示为
f i ( w , b ) = w x i + b f_i(w,b)=wx_i+b fi(w,b)=wxi+b
则重新定义一个训练样本的损失计算函数
L i ( w , b ) = ( f i ( w , b ) − y i ) 2 L_i(w,b) = (f_i(w,b)-y_i)^2 Li(w,b)=(fi(w,b)−yi)2
则总体损失函数为:
L o s s ( w , b ) = ∑ i = 0 k L i ( w , b ) k = 2 x = [ 1 , 2 , 3 ] Loss(w,b) = \sum_{i=0}^{k} L_i(w,b)\quad k=2\quad x=[1,2,3] Loss(w,b)=i=0∑kLi(w,b)k=2x=[1,2,3]
将损失函数展开为:
L o s s ( w , b ) = L 0 ( w , b ) + L 1 ( w , b ) + L 2 ( w , b ) Loss(w,b) = L_0(w,b)+L_1(w,b)+L_2(w,b)\quad Loss(w,b)=L0(w,b)+L1(w,b)+L2(w,b)
将 L i ( w , h ) L_i(w,h) Li(w,h)替换
L o s s ( w , b ) = ( f 0 ( w , b ) − y 0 ) 2 + ( f 1 ( w , b ) − y 1 ) 2 + ( f 2 ( w , b ) − y 2 ) 2 Loss(w,b) = (f_0(w,b)-y_0)^2+(f_1(w,b)-y_1)^2+(f_2(w,b)-y_2)^2\quad Loss(w,b)=(f0(w,b)−y0)2+(f1(w,b)−y1)2+(f2(w,b)−y2)2
将 f i ( w , b ) f_i(w,b) fi(w,b)替换
L o s s ( w , b ) = ( w x 0 + b − y 0 ) 2 + ( w x 1 + b − y 1 ) 2 + ( w x 2 + b − y 2 ) 2 Loss(w,b) = (wx_0+b-y_0)^2+(wx_1+b-y_1)^2+(wx_2+b-y_2)^2\quad Loss(w,b)=(wx0+b−y0)2+(wx1+b−y1)2+(wx2+b−y2)2
梯度下降的原理
到这该思考怎么去搜索一组 w , b w,b w,b,为了理解的透彻我们举几个例子
先从一个最简单的问题上思考,已知一个有最小值点的函数 f ( x ) f(x) f(x),和一个初始值 x = x 0 x=x_0 x=x0,则 x x x朝着哪个方向移动会使函数值更接近最小值点.

挑一个最简单的函数
f ( x ) = x 2 f(x) = x^2 f(x)=x2
设置初始点为
x 0 = 0.5 则 y 0 = 0. 5 2 = 0.25 x_0 = 0.5\quad 则 \quad y_0=0.5^2=0.25 x0=0.5则y0=0.52=0.25
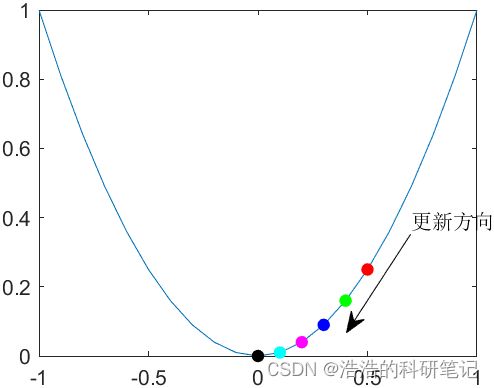
为了走向最小值点,我们的策略就是一直将 x x x往使函数值变小的方向一点点移动,那往哪个方向移动会使用使函数值见小呢根据简单的数学知识我们知道**如果 x x x朝着梯度(导数)的方向移动则函数值会增大,所以让 x x x朝着负梯度方向移动则函数值就会变小.因此先求在 x 0 = 0.5 x_0=0.5 x0=0.5处的梯度(导数)
f ′ ( x ) = 2 x f'(x)=2x f′(x)=2x
f ′ ( 0.5 ) = 2 ∗ 0.5 = 1 f'(0.5)=2*0.5=1 f′(0.5)=2∗0.5=1 因为在 x 0 x_0 x0点处的导数 f ′ ( 0.5 ) f'(0.5) f′(0.5)大于0梯度方向朝着x轴的正轴方向,所以 x x x如果向着正半轴移动则函数值会增大, x x x向负半轴移动函数值会减小,移动多少就由负梯度乘以一个步长来决定,通过让步长乘以负梯度的方式可以调节变量实际移动距离让 x x x点在接近最小值点也就是导数为0的点时移动的距离变小,在导数大的地方移动加快,提高收敛速度,假设步长为 0.1 0.1 0.1则 x x x在 x 0 x_0 x0点开始向右侧移动 0.1 ∗ f ′ ( 0.5 ) = 0.1 0.1*f'(0.5)=0.1 0.1∗f′(0.5)=0.1,我们将这次移动之后的位置记为 x 1 x_1 x1,则 x 1 = 0.4 f ( x 1 ) = 0.16 < f ( x 0 ) x_1=0.4 \quad f(x_1)=0.16
那如果有两个自变量呢假设我们要求最小值的函数为,初始点坐标 ( x 0 , y 0 ) = ( 1 , 1 ) (x_0,y_0)=(1,1) (x0,y0)=(1,1)
f ( x , y ) = x 2 + y 2 f(x,y) = x^2+y^2 f(x,y)=x2+y2
则在函数的初始值 ( x 0 , y 0 ) = ( 1 , 1 ) (x_0,y_0)=(1,1) (x0,y0)=(1,1)点的函数值 f ( x 0 , y 0 ) = 1 2 + 1 2 = 2 f(x_0,y_0)=1^2+1^2=2 f(x0,y0)=12+12=2,要想使三维空间中的点不断的逼近最小值那就是找,输入的二维坐标点的负梯度方向,对于多维函数,求梯度方向就是求每一个自变量的偏导数.

则用 f ( x , y ) f(x,y) f(x,y)对 x , y x,y x,y求偏导
∂ f ∂ x = 2 x ∂ f ∂ y = 2 y \frac{ \partial f }{ \partial x }=2x\quad\frac{ \partial f }{ \partial y }=2y ∂x∂f=2x∂y∂f=2y
则在 ( x 0 , y 0 ) (x_0,y_0) (x0,y0) 点处的偏导数值为 ( 2 , 2 ) (2,2) (2,2)
∂ f ∂ x = 2 ∂ f ∂ y = 2 \frac{ \partial f }{ \partial x }=2\quad\frac{ \partial f }{ \partial y }=2 ∂x∂f=2∂y∂f=2
因此如果 ( x , y ) (x,y) (x,y)分别朝着导数方向则函数值会增大,为了让函数值减小则同理 ( x , y ) (x,y) (x,y)同时向这负梯度方向则可以减小,同样设置步长为 0.1 0.1 0.1,则 x 1 = x 0 + 0.1 ∗ ( − 2 ) = 0.8 y 1 = y 0 + 0.1 ∗ ( − 2 ) = 0.8 f ( x 1 , y 1 ) < f ( x 0 , y 0 ) x_1=x_0+0.1*(-2)=0.8\quad y_1=y_0+0.1*(-2)=0.8 \quad f(x_1,y_1)

到这里其实可以明确一个概念深度学习的本质就是求函数的最小值
模型参数的更新过程
好回到之前回归任务求 w , b w,b w,b是自变量,沿着负梯度方向不断更新 w , b w,b w,b使下面这个函数值最小
L o s s ( w , b ) = ( w x 0 + b − y 0 ) 2 + ( w x 1 + b − y 1 ) 2 + ( w x 2 + b − y 2 ) 2 Loss(w,b) = (wx_0+b-y_0)^2+(wx_1+b-y_1)^2+(wx_2+b-y_2)^2 Loss(w,b)=(wx0+b−y0)2+(wx1+b−y1)2+(wx2+b−y2)2
接下来求函数对 w w w的导数,先将损失函数转换成未完全展开的模式.
L o s s ( w , b ) = L 0 ( w , b ) + L 1 ( w , b ) + L 2 ( w , b ) Loss(w,b) = L_0(w,b)+L_1(w,b)+L_2(w,b)\quad Loss(w,b)=L0(w,b)+L1(w,b)+L2(w,b)
先观察其中一个 L o s s Loss Loss中的分量 L 0 ( w , b ) L_0(w,b) L0(w,b)
L 0 ( w , b ) = ( f 0 ( w , b ) − y 0 ) 2 = ( w x 0 + b − y 0 ) 2 L_0(w,b)=(f_0(w,b)-y_0)^2=(wx_0+b-y_0)^2 L0(w,b)=(f0(w,b)−y0)2=(wx0+b−y0)2
然后我们观察这个定义这个分量的原函数
L i ( w , b ) = ( f i ( w , b ) − y i ) 2 L_i(w,b) = (f_i(w,b)-y_i)^2 Li(w,b)=(fi(w,b)−yi)2
要求 L i ( w , b ) L_i(w,b) Li(w,b)对 w w w的导数则需要求 L i ( w , b ) L_i(w,b) Li(w,b)对 f i ( w , b ) f_i(w,b) fi(w,b)的导数,然后求 f i ( w , b ) f_i(w,b) fi(w,b)对 w w w的导数,通过链式求导法则最终得到
L i ( w , b ) L_i(w,b) Li(w,b)对 w w w的导数
∂ L i ( w , b ) ∂ w = ∂ L i ( w , b ) ∂ f i ( w , b ) × ∂ f i ( w , b ) ∂ w \frac{ \partial L_i(w,b) }{ \partial w }= \frac{ \partial L_i(w,b) }{ \partial f_i(w,b) }×\frac{ \partial f_i(w,b) }{ \partial w } ∂w∂Li(w,b)=∂fi(w,b)∂Li(w,b)×∂w∂fi(w,b)
根据
f i ( w , b ) = w x i + b f_i(w,b)=wx_i+b fi(w,b)=wxi+b
先求
∂ f i ( w , b ) ∂ w = x i \frac{ \partial f_i(w,b) }{ \partial w }=x_i ∂w∂fi(w,b)=xi
然后根据
L i ( w , h ) = ( f i ( w , b ) − y i ) 2 L_i(w,h) = (f_i(w,b)-y_i)^2 Li(w,h)=(fi(w,b)−yi)2
求得
∂ L i ( w , b ) ∂ f i ( w , b ) = 2 × ( f i ( w , h ) − y i ) \frac{ \partial L_i(w,b) }{ \partial f_i(w,b) }=2×(f_i(w,h)-y_i) ∂fi(w,b)∂Li(w,b)=2×(fi(w,h)−yi)
所以可以算出
∂ L i ( w , b ) ∂ w = 2 × ( f i ( w , h ) − y i ) × x i = 2 × ( w x i + b − y i ) × x i \frac{ \partial L_i(w,b) }{ \partial w }= 2×(f_i(w,h)-y_i)×x_i=2×(wx_i+b-y_i)×x_i ∂w∂Li(w,b)=2×(fi(w,h)−yi)×xi=2×(wxi+b−yi)×xi
同理我们去求 L i ( w , b ) L_i(w,b) Li(w,b)对 b b b的导数
∂ L i ( w , b ) ∂ b = ∂ L i ( w , b ) ∂ f i ( w , b ) × ∂ f i ( w , b ) ∂ b \frac{ \partial L_i(w,b) }{ \partial b }= \frac{ \partial L_i(w,b) }{ \partial f_i(w,b) }×\frac{ \partial f_i(w,b) }{ \partial b } ∂b∂Li(w,b)=∂fi(w,b)∂Li(w,b)×∂b∂fi(w,b)
L i ( w , b ) L_i(w,b) Li(w,b)对 f i ( w , b ) f_i(w,b) fi(w,b)的导数不变,只需要再去求一下 f i ( w , b ) f_i(w,b) fi(w,b)对 b b b的导数
∂ f i ( w , b ) ∂ b = 1 \frac{ \partial f_i(w,b) }{ \partial b }=1 ∂b∂fi(w,b)=1
则最终求出来的 L i ( w , b ) L_i(w,b) Li(w,b)对 b b b的导数为
∂ L i ( w , b ) ∂ b = 2 × ( f i ( w , h ) − y i ) × 1 = 2 ( w x i + b − y i ) \frac{ \partial L_i(w,b) }{ \partial b }= 2×(f_i(w,h)-y_i)×1=2(wx_i+b-y_i) ∂b∂Li(w,b)=2×(fi(w,h)−yi)×1=2(wxi+b−yi)
最终我们得到了学习参数过程中最重要的梯度计算公式
∂ L i ( w , b ) ∂ w = 2 × ( w x i + b − y i ) × x i ∂ L i ( w , b ) ∂ b = 2 ( w x i + b − y i ) \frac{ \partial L_i(w,b) }{ \partial w }=2×(wx_i+b-y_i)×x_i \\\frac{ \partial L_i(w,b) }{ \partial b }= 2(wx_i+b-y_i) ∂w∂Li(w,b)=2×(wxi+b−yi)×xi∂b∂Li(w,b)=2(wxi+b−yi)
根据总体损失的公式
L o s s ( w , b ) = ∑ i = 0 k L i ( w , b ) k = 3 x = [ 1 , 2 , 3 ] y = [ 3 , 5 , 7 ] Loss(w,b) = \sum_{i=0}^{k} L_i(w,b)\quad k=3\quad x=[1,2,3]\quad y=[3,5,7] Loss(w,b)=i=0∑kLi(w,b)k=3x=[1,2,3]y=[3,5,7]
我们也就能算出 L o s s ( w , b ) Loss(w,b) Loss(w,b)对 w , b w,b w,b的梯度
∂ L o s s ( w , b ) ∂ w = ∑ i = 0 k ∂ L i ( w , b ) ∂ w = ∑ i = 0 k 2 × ( w x i + b − y i ) × x i k = 2 ∂ L o s s ( w , b ) ∂ b = ∑ i = 0 k ∂ L i ( w , b ) ∂ b = ∑ i = 0 k 2 × ( w x i + b − y i ) k = 2 \frac{ \partial Loss(w,b) }{ \partial w } = \sum_{i=0}^{k} \frac{ \partial L_i(w,b) }{ \partial w }=\sum_{i=0}^{k} 2×(wx_i+b-y_i)×x_i\quad k=2\quad \\ \frac{ \partial Loss(w,b) }{ \partial b } = \sum_{i=0}^{k} \frac{ \partial L_i(w,b) }{ \partial b }=\sum_{i=0}^{k} 2×(wx_i+b-y_i)\quad k=2\quad ∂w∂Loss(w,b)=i=0∑k∂w∂Li(w,b)=i=0∑k2×(wxi+b−yi)×xik=2∂b∂Loss(w,b)=i=0∑k∂b∂Li(w,b)=i=0∑k2×(wxi+b−yi)k=2
有了更新公式之后,我们只需要设置一个初始的就可以根据梯度公式不断的更新 w , b w,b w,b我们设置步长 λ = 0.01 \lambda=0.01 λ=0.01
则可以写出 w , b w,b w,b的更新公式
w i + 1 = w i + λ × ( − ∂ L o s s ( w , b ) ∂ w ) b i + 1 = b i + λ × ( − ∂ L o s s ( w , b ) ∂ b ) w_{i+1} = w_i+\lambda ×(-\frac{ \partial Loss(w,b) }{ \partial w })\\b_{i+1} = b_i+\lambda ×(-\frac{ \partial Loss(w,b) }{ \partial b }) wi+1=wi+λ×(−∂w∂Loss(w,b))bi+1=bi+λ×(−∂b∂Loss(w,b))
接下来我们模拟一步更新过程
根据一开始的表个我们的训练数据 ( x , y ) (x,y) (x,y)分别为
x = [ 1 , 2 , 3 ] y = [ 3 , 5 , 7 ] x= [1,2,3] \\ y= [3,5,7] x=[1,2,3]y=[3,5,7]
假设初始值
w 0 = 1 b 0 = 0 w_0=1\quad b_0=0 w0=1b0=0
根据下面的这个式子去算一下损失
L o s s ( w , b ) = ( w x 0 + b − y 0 ) 2 + ( w x 1 + b − y 1 ) 2 + ( w x 2 + b − y 2 ) 2 Loss(w,b) = (wx_0+b-y_0)^2+(wx_1+b-y_1)^2+(wx_2+b-y_2)^2\quad Loss(w,b)=(wx0+b−y0)2+(wx1+b−y1)2+(wx2+b−y2)2
将 w = 1 , b = 0 x 0 = 1 , x 1 = 2 , x 2 = 3 y 0 = 3 , y 1 = 5 , y 2 = 7 w=1,b=0 \quad x_0=1,x_1=2,x_2=3 \quad y_0=3,y_1=5,y_2=7 w=1,b=0x0=1,x1=2,x2=3y0=3,y1=5,y2=7带入
L o s s ( 1 , 0 ) = ( 1 × 1 + 0 − 3 ) 2 + ( 1 × 2 + 0 − 5 ) 2 + ( 1 × 3 + 0 − 7 ) 2 = 29 Loss(1,0) = (1×1+0-3)^2+(1×2+0-5)^2+(1×3+0-7)^2 = 29 Loss(1,0)=(1×1+0−3)2+(1×2+0−5)2+(1×3+0−7)2=29
接下来计算损失函数对 w , b w,b w,b的梯度
∂ L o s s ( w 0 , b 0 ) ∂ w = ∑ i = 0 k ∂ L i ( w 0 , b 0 ) ∂ w = ∑ i = 0 k 2 × ( w 0 x i + b 0 − y i ) × x i k = 2 = 2 × ( w 0 x 0 + b 0 − y 0 ) × x 0 + 2 × ( w 0 x 1 + b 0 − y 1 ) × x 1 + 2 × ( w 0 x 2 + b 0 − y 2 ) × x 2 = 2 × ( 1 × 1 + 0 − 3 ) × 1 + 2 × ( 1 × 2 + 0 − 5 ) × 2 + 2 × ( 1 × 3 + 0 − 7 ) × 3 = − 40 \frac{ \partial Loss(w_0,b_0) }{ \partial w } = \sum_{i=0}^{k} \frac{ \partial L_i(w_0,b_0) }{ \partial w }=\sum_{i=0}^{k} 2×(w_0x_i+b_0-y_i)×x_i\quad k=2\quad\\=2×(w_0x_0+b_0-y_0)×x_0+2×(w_0x_1+b_0-y_1)×x_1+2×(w_0x_2+b_0-y_2)×x_2 \\=2×(1×1+0-3)×1+2×(1×2+0-5)×2+2×(1×3+0-7)×3=-40 ∂w∂Loss(w0,b0)=i=0∑k∂w∂Li(w0,b0)=i=0∑k2×(w0xi+b0−yi)×xik=2=2×(w0x0+b0−y0)×x0+2×(w0x1+b0−y1)×x1+2×(w0x2+b0−y2)×x2=2×(1×1+0−3)×1+2×(1×2+0−5)×2+2×(1×3+0−7)×3=−40
∂ L o s s ( w , b ) ∂ b = ∑ i = 0 k ∂ L i ( w , b ) ∂ b = ∑ i = 0 k 2 × ( w x i + b − y i ) k = 2 = 2 × ( w 0 x 0 + b 0 − y 0 ) + 2 × ( w 0 x 1 + b 0 − y 1 ) + 2 × ( w 0 x 2 + b 0 − y 2 ) = 2 × ( 1 × 1 + 0 − 3 ) + 2 × ( 1 × 2 + 0 − 5 ) + 2 × ( 1 × 3 + 0 − 7 ) = − 18 \frac{ \partial Loss(w,b) }{ \partial b } = \sum_{i=0}^{k} \frac{ \partial L_i(w,b) }{ \partial b }=\sum_{i=0}^{k} 2×(wx_i+b-y_i)\quad k=2\quad\\=2×(w_0x_0+b_0-y_0)+2×(w_0x_1+b_0-y_1)+2×(w_0x_2+b_0-y_2) \\=2×(1×1+0-3)+2×(1×2+0-5)+2×(1×3+0-7)=-18 ∂b∂Loss(w,b)=i=0∑k∂b∂Li(w,b)=i=0∑k2×(wxi+b−yi)k=2=2×(w0x0+b0−y0)+2×(w0x1+b0−y1)+2×(w0x2+b0−y2)=2×(1×1+0−3)+2×(1×2+0−5)+2×(1×3+0−7)=−18
接下来使用更新公式对 w , b w,b w,b进行更新
w 1 = w 0 + λ × ( − ∂ L o s s ( w 0 , b 0 ) ∂ w ) = 1 + 0.01 × 40 = 1.4 b 1 = b 0 + λ × ( − ∂ L o s s ( w 0 , b 0 ) ∂ b ) = 0 + 0.01 × 18 = 0.18 w_1 = w_0+\lambda ×(-\frac{ \partial Loss(w_0,b_0) }{ \partial w })=1+0.01×40=1.4\\b_1 = b_0+\lambda ×(-\frac{ \partial Loss(w_0,b_0) }{ \partial b })=0+0.01×18=0.18 w1=w0+λ×(−∂w∂Loss(w0,b0))=1+0.01×40=1.4b1=b0+λ×(−∂b∂Loss(w0,b0))=0+0.01×18=0.18
接下来我们将新的参数带入进损失函数
L o s s ( w 1 , b 1 ) = ( w 1 x 0 + b 1 − y 0 ) 2 + ( w 1 x 1 + b 1 − y 1 ) 2 + ( w 1 x 2 + b 1 − y 2 ) 2 = ( 1.4 × 1 + 0.18 − 3 ) 2 + ( 1.4 × 2 + 0.18 − 5 ) 2 + ( 1.4 × 3 + 0.18 − 7 ) 2 = 12.9612 Loss(w_1,b_1) = (w_1x_0+b_1-y_0)^2+(w_1x_1+b_1-y_1)^2+(w_1x_2+b_1-y_2)^2\\=(1.4×1+0.18-3)^2+(1.4×2+0.18-5)^2+(1.4×3+0.18-7)^2=12.9612 Loss(w1,b1)=(w1x0+b1−y0)2+(w1x1+b1−y1)2+(w1x2+b1−y2)2=(1.4×1+0.18−3)2+(1.4×2+0.18−5)2+(1.4×3+0.18−7)2=12.9612
可喜可贺损失变小了,接下来就是重复上面的步骤设置学习次数,学习到损失几乎不再下降为止.
接下来用python的基础库模拟出这个过程
python基础库实现
先初始化需要用到的变量
# 训练数据
train_data = [1,2,3]
# 训练标签
train_label = [3,5,7]
# 测试数据
test_data = [4]
# 测试标签
test_label = [9]
# 初始化权重
w = 1
b = 0
# 迭代次数/训练次数
iter = 10000
# 设置步长
lamb = 0.01
然后定义模型
# 回归模型
def f(x):
return w*x + b
定义用到的损失函数
# 计算一个样本的损失函数
def L(data,label):
return (data-label)**2
# 总体损失函数
def Loss(x,y):
loss = 0
k = len(x)
for i in range(k):
loss += L(f(x[i]),y[i])
return loss
定义计算梯度函数
# 计算梯度
def gradient(w,b,x,y):
dw,db = 0,0
k = len(x)
for i in range(k):
dw += 2*(w*x[i]+b-y[i])*x[i]
db += 2*(w*x[i]+b-y[i])
return dw,db
训练部分
# 训练
for i in range(iter):
dw,db = gradient(w,b,train_data, train_label)
w = w - lamb*dw
b = b - lamb*db
最后加上绘图代码最终的完整代码如下
import matplotlib.pyplot as plt
import numpy as np
# 训练数据
train_data = [1,2,3]
# 训练标签
train_label = [3,5,7]
# 测试数据
test_data = [4]
# 测试标签
test_label = [9]
# 初始化权重
w = 1
b = 0
# 迭代次数/训练次数
iter = 1000
# 设置步长
lamb = 0.01
# 回归模型
def f(x):
return w*x + b
# f = lambda x: w*x + b
# 计算一个样本的损失函数
def L(data,label):
return (data-label)**2
# 总体损失函数
def Loss(x,y):
loss = 0
k = len(x)
for i in range(k):
loss += L(f(x[i]),y[i])
return loss
# 计算梯度
def gradient(w,b,x,y):
dw,db = 0,0
k = len(x)
for i in range(k):
dw += 2*(w*x[i]+b-y[i])*x[i]
db += 2*(w*x[i]+b-y[i])
return dw,db
# 训练
for i in range(iter):
dw,db = gradient(w,b,train_data, train_label)
w = w - lamb*dw
b = b - lamb*db
# 打开网格
plt.grid()
# 绘制训练集点
plt.scatter(train_data,train_label,c='blue')
# 回执测试集点
plt.scatter(test_data,test_label,c='red')
#设置绘图范围
plt.xlim([0,5])
plt.ylim([0,10])
#绘制拟合直线
x = np.linspace(0,5,1000)
y = f(x)
plt.scatter(x,y,c='black',s=1)
plt.show()
#打印学习之后的w,b值
print('w=',w)
print('b=',b)
最终拟合的直线结果如下

最终训练之后的 w , b w,b w,b值为
w= 2.000148389025502
b= 0.9996626768662412
稍微变动一下数据让数据不都在一条线上,看一下最终的拟合结果会是什么样的
# 训练数据
train_data = [1,1.5,3]
# 训练标签
train_label = [3,5,7]
# 测试数据
test_data = [4]
# 测试标签
test_label = [9]

w= 1.846223184751381
b= 1.6152357121183563