众所周知,基础数据平台的迁移非常复杂。今天起,我们将陆续为大家推送系列干货内容——《如何从Oracle迁移到Greenplum》,详细介绍产品对比,迁移场景,迁移步骤,以及一些特殊场景的注意点,手把手教大家做迁移。从传统的单机数据库迁移到分布式数据库,这些原则也仍然适用,很多用户都成功的从Oracle、Teradata、DB2、Sybase IQ、Hadoop等平台迁移到了Greenplum。
1
综述
1)成本
Greenplum 相比Teradata、Oracle Exadata等一体机设备,不需要够买专有硬件设备,有明显的成本优势。
2)性能
Greenplum 相比传统关系型数据库有明显的性能提升,多个用户从Oracle、DB2迁移到Greenplum后,性能有几十倍的提升
3)易用性
Greenplum 相比Hadoop平台,SQL表达能力更为突出,应用改造成本要小很多
Greenplum在网络层面做了特殊的优化,用UDPIFC协议代替TCP做为内部数据交互的协议,UDPIFC全称User Datagram Protocol Interconnect with flow control,是Greenplum为了提升数据通信的性能和通信的可靠性,在传统UDP通信协议的基础上实现了可靠的通信并实现了流控和防阻塞机制,本质上是一种RUDP协议(Reliable UDP)。理论上单集群规模可以达到1000个节点以上,国内现在有不少用户集群规模超过一百台,压缩后数据规模达到几PB;从扩展性上来说,Hadoop(1000个节点以上)>MPP(100~1000个节点)>Oracle RAC(32个节点以内),从SQL兼容性上来说:Oracle RAC和Greenplum底层都采用传统的关系型数据库,Greenplum底层基于Postgresql,与Oracle语法兼容性非常高,虽然近年来SQL On Hadoop的技术不断发展,但在SQL兼容性和性能(尤其是复杂业务场景下的复杂SQL)上相比传统的MPP关系型数据库,还有不小的差距。
如下图所示,目前除了几大互联网公司,绝大部分企业里的数据量多在TB到PB级之间,MPP类数据库和Oracle RAC产品仍然是OLAP领域的主要产品,由于Oracle Exadata一体机高昂的硬件成本和扩展性等问题,越来越多的用户把Greenplum当作数据仓库的首选平台,并从Oracle RAC 等数据平台迁移到了Greenplum,接下来的章节会重点介绍下如何从Oracle迁移到Greenplum。
| 产品名称 |
集群规模 |
数据量 |
| Oracle RAC |
32节点以内 |
TB级 |
| Greenplum |
1000节点以内 |
PB级 |
| Hadoop |
1000节点以上 |
EB级 |
产品支撑数据规模对比
2
产品体系架构对比
Oracle数据库从1979年发布第一个版本至今已有将近40年的历史,在OLTP领域仍然处于领导地位,近些年,随着互联网、社交网络、物联网的兴起,越来越多的企业开始使用MySQL和PostgreSQL等开源数据库,但Oracle在传统的企业市场仍然有庞大的用户规模,短期内很难被替换掉;在OLAP领域,Oracle自2001年首次发布其RAC产品,到现在有将近20年的历史,产品已经稳定成熟。但由于其本身基于共享存储的架构和限制,在数据规模比较大时,如节点数超过32个,数据量超过50TB时,使用RAC就会有点力不从心。即使使用Oracle Exadata 一体机部署RAC,扩展性和性能也会触及到天花板,并且要投入高昂的硬件和软件成本。
如下图所示,Oracle RAC 是典型share everything的架构, 即所有数据文件,控制文件,SPFILE和重做日志文件都必须驻留在支持群集的共享磁盘上,以便所有群集数据库实例都可以访问这些存储组件。由于Oracle RAC数据库使用share everything体系结构,Oracle RAC需要用集群感知存储,而集中化存储往往成为性能的主要瓶颈点。
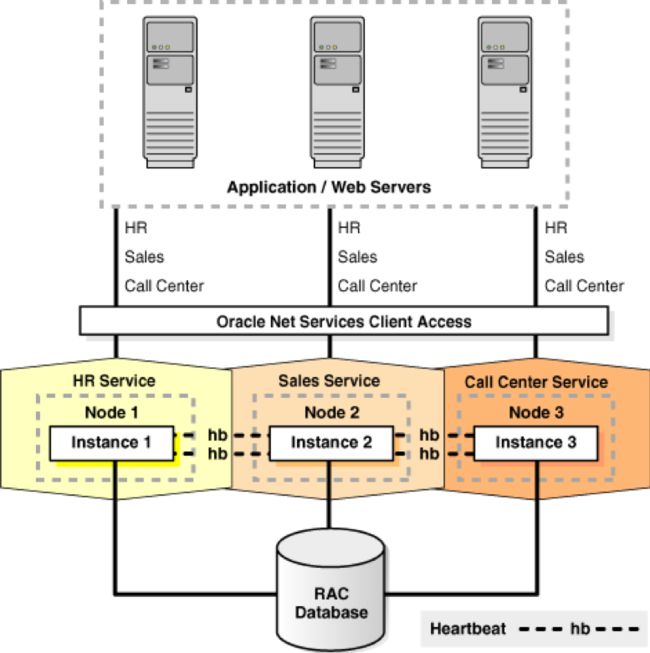
Oracle RAC典型应用场景架构
关于Oracle RAC主要应用场景是在OLAP还是OLTP,网上有不少讨论。官方的说法是两者都可以,但从实际的应用来看,主要应用场景还是在OLAP领域,RAC用在OLTP领域并不能降低单个事务的响应时间,一般通过应用水平拆分,将不同的应用分散在不同的实例,以降低对全局锁的争用,从而实现水平扩展,提升整体的吞吐能力。在OLAP领域,本来数据就要共享,很难做业务上的拆分,这样可以使用 Oracle并行计算的能力,既可以节点内并行,也可以跨节点并行,从而提升在OLAP的计算能力,但由于OLAP和OLTP本身业务的侧重点不同,在技术实现上也会有较大差别,如下图所示:
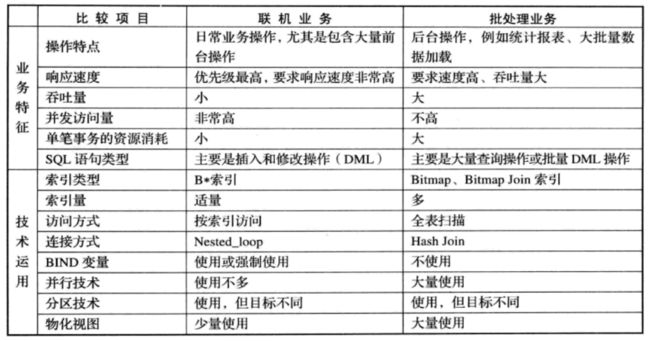
OLTP与OLAP比较
(来源:https://www.cnblogs.com/andy6/p/6011959.html)
OLTP场景一般是高并发低时延,OLAP一般为低并发吞吐量大,在产品层面,往往有些参数也需要根据相应的场景进行调整,但参数方面的调整有些是相互矛盾的,这也给一套RAC解决OLAP和OLTP带来了不小程度的挑战,虽然可以通过Instance Caging 、数据库资源管理器、并行语句队列、IO资源管理器等手段对系统资源的使用进行控制,但需要投入较大的精力进行整合优化,也做不到完全的资源隔离,还是会存在大的OLAP场景影响OLTP应用的情况。但如果用户数据量不大,比如在10TB以内,并且应用上有明显的分时特点,比如白天跑OLTP,晚上跑OLAP,使用RAC也是不错的选择。
关于RAC 更适合跑OLAP还是OLTP应用,可以参考itpub上的2008年的一篇讨论:http://www.itpub.net/thread-1089050-1-1.html,里面有淘宝老一代DBA的精彩分析,现在读来还十分具有参考意义。
而Greenplum是Shared nothing的架构,数据量和计算能力可以随着物理节点数的增加呈类线型的增长,不会因为存储的瓶颈造成整个集群的扩展和性能问题,所以更适合大数据量的分析型场景,如果有基于索引并发小查询场景,Greenplum也可以很好的支撑,在5.0版本之后,通过Resource Group对物理资源做了更细粒度的控制,在CPU、内存、并发控制等方面都做了较大的改进。另外社区版本已经将heap表上update和delete操作原先的表锁机制降为行锁,并增加了在分布式环境死锁的检测机制,增加了复制表,在后续发布的版本中,随着和PostgreSQL的不断整合,会对事务型操作有更进一步的增强,对HTAP类的场景会有更好的支撑。
目前有不少用户从Oracle迁移到了Greenplum。下面我们来分析一下主要原因。
Oracle的主要痛点
Oracle主要有以下几方面痛点:
在应对海量数据的分析型场景时性能较差
Oracle并不是专门为分析型场景设计,其体系架构主要是应对数据经常变动的OLTP高并发,低时延场景。
扩展性较差
在分析型场景中,体系架构较老,在性能和功能上无法完全满足新型的分析场景,如深度学习和流式计算场景。
软件使用授权费用昂贵,Oracle用户需要为高级的特性支付额外的使用费用。
Greenplum的产品优势
原生的shared nothing MPP架构
当单台机器无法满足性能要求时,可以通过增加机器的方式方式进行水平扩展,理论上可以支持上千个节点以上的集群规模,在真实的生产环境,我们国内有多个用户其集群规模超过100节点,国外有超过200节点,压缩后的数据量达到PB级别。
优秀的查询性能
其分析性能随着节点的增加呈类线型增长,一般在Oracle上跑数小时的分析型应用,在Greenplum上只用数分钟或者秒级别返回。
支持多种场景
在支持传统BI分析型应用的基础上,同时支持机器学习、图计算、全文检索、地理位置分析等场景,无需为这些高级特性支持额外的授权费用。
产品生命力强
产品开源,完全基于PostgreSQL生态。
无硬件绑定
100%纯软件产品,用户可以自由选择硬件搭配,可以跑在各种云化环境或私有数据中心中。
总成本低
不需要昂贵的专有设备和服务。
下图给出了Oracle RAC/Exadata和Greenplum的比较。
| 对比分类 |
Oracle RAC/Exadata |
Greenplum |
| 体系架构 |
Shared storage |
Shared Nothing |
| 优势场景 |
OLTP |
OLAP |
| 硬件搭配 |
SAN存储+光纤网络 |
本地磁盘+以太网 |
| 扩展能力 |
理论上可以到100个节点,生产上一般在2~10个,虽然所有节点可以同时读写,一般通过应用层sharding扩展其写的能力,读取能力可以水平扩展 |
生产上多在32节点以上,超过100节点以上的有多个用户,理论上可以支撑3000个以上物理节点 |
| 典型扩展方式 |
Scale up |
Scale out |
| 库内编程能力 |
支持PL/SQL库内过程语言和自定义函数,如果要使用R语言等其他分析语言,需要购买额外的高级分析特性 |
支持PL/pgSQL等过程语言,集成Apache MADlib(机器学习、Apache Solr(全文检索、PostGIS(地理空间分析、Python、JAVA、Perl、MapReduce计算框架和其他分析Lib库,如Tensorflow,通过PXF、Spark connector、kafka connector可以方便与Hadoop生态集成 |
| 云上部署 |
支持AWS等但相比Oracle自家的云产品需要支付更高的授权费用 |
支持多云化部署,可以无差异部署在AWS、GCP、Azure、阿里云、腾讯云等公有云环境,也可以选择部署在企业私有云环境当中、有专门的Greenplum for Kubernetes版本 |
| 开源策略 |
纯商业产品,完全闭源 |
100%开源,集成原生PostgreSQL生态 |
| 软件开发效率 |
开发周期较长 |
小版本1个月发布一次,大版本一年,2019年发布基于PostgreSQL9.x版本的Geenplum产品 |
| 数据格式扩展 |
支持半结构化数据 |
支持Json、Hstore等半结构化数据 |
Greenplum与Oracle RAC主要维度对比
如何从Oracle迁移到Greenplum
如下图所示,从Oracle迁移到Greenplum一般要经过规划->安装部署->实施->UAT验证->投产五个阶段, 中间涉及数据库厂商、应用开发商、用户等多个部门和组织的配合,为了保证迁移项目的成功,每一个环节都要仔细分析并充分验证。迁移效果的几个关键因素的影响。
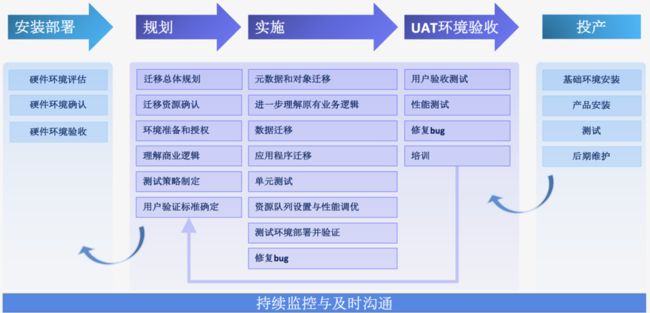
迁移流程
1. 硬件选择
目前市面上主流的x86服务器,都可以作为Greenplum的生产运行环境,下面通过几个实例说明硬件选择中需要注意的问题。
RAID卡没有硬件cache
某用户在Greenplum扩容时,新加机器选取了更多磁盘的机器,但新加机器RAID卡无硬件cache,导致新加机器写IO能力只有300MB/s,扩容后性能反而变差。
建议:选用2GB或以上cache的硬件RAID卡。
选用千兆网络
为了硬件利旧,客户用千兆网络环境构建Greenplum集群,结果四台机器的性能反而不如一台。
建议:使用万兆网络环境搭建Greenplum集群。
服务器重启后,网卡降为百兆
某用户开启了交换机与网卡自动协商,服务器故障重启后,网卡由万兆降为百兆,集群性能下降严重。
建议:禁止网卡自动协商,强制为万兆模式。
交换机屏蔽指定UDP端口
多个用户都遇到过交换机屏蔽指定UDP端口,导致SQL执行过程中 Hang死或者超时的情况出现。
建议:交换机允许UDP通信,操作系统层面屏蔽指定UDP端口。
2. 集群构建
Greenplum通过多实例的方式实现并行化,一般primary segment实例数选择为4~8个,现有2u*12core以上的服务器建议可采用每台服务器8个primary实例的方式进行构建。
我们将在下篇内容中从 迁移场景、迁移过程、特殊场景三个方面简单介绍如何从Oracle迁移到Greenplum。
本文摘录自Greenplum官方教材《Greenplum:从大数据战略到实现》,点击阅读原文获取购买链接。

本文分享自微信公众号 - Greenplum中文社区(GreenplumCommunity)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。