Jumpserver安全一窥:Sep系列漏洞深度解析
Jumpserver是中国国内公司开发的一个开源项目,在开源堡垒机领域一家独大。在2023年9月官方集中修复了一系列安全问题,其中涉及到如下安全漏洞:
JumpServer 重置密码验证码可被计算推演的漏洞,CVE编号为CVE-2023-42820
JumpServer 重置密码验证码可被暴力破解的漏洞,CVE编号为CVE-2023-43650
JumpServer 认证用户跨目录任意文件读取漏洞,CVE编号为CVE-2023-42819
JumpServer 全局开启公钥认证后,用户可以使用公钥创建访问Token的漏洞,CVE编号为CVE-2023-43652
JumpServer 认证用户开启MFA后,可以使用SSH公钥认证的逻辑缺陷漏洞,CVE编号为CVE-2023-42818
JumpServer 认证用户连接MongoDB数据库,可执行任意系统命令的远程执行漏洞,CVE编号为CVE-2023-43651
Jumpserver Session录像任意下载漏洞,CVE编号为CVE-2023-42442
虽然涉及到数个漏洞,也不乏高危严重问题,但对于一个商业化运营的国产开源项目来说,官方透明公开的态度还是值得点赞的。另外官方写的漏洞通告也很详细,那么我们就根据漏洞通告的内容依旧补丁来逐一解析一下这些漏洞的详情吧。
CVE-2023-42820:伪随机数种子泄漏造成用户接管漏洞
这个漏洞是这一系列漏洞里最严重的问题了,未授权的攻击者可以利用该漏洞推算出没有开启多因子验证(MFA)的账号的“重置密码Token”,进而修改该账号的密码。
这句话很绕,简单来说就是用户点击忘记密码时系统会生成一个随机字符串作为Token并发送到用户邮箱,但由于一个有趣的安全问题,导致这个随机字符串Token可以被推算出来,造成漏洞。
漏洞的核心是随机数种子泄露导致的,而这段逻辑并不是来自于Jumpserver,而是其依赖的一个第三方项目django-simple-captcha。
这个django-simple-captcha库和Django reCAPTCHA可以说是Django生态中唯二常用的验证码生成库了,但因为中国用户无法使用reCAPTCHA,所以它基本就是国内的唯一之选。包括我自己的博客也在使用其作为图形验证码依赖:
今年我写了一篇文章《用ChatGPT帮我检查广告评论》,起因就是当时遇到了大量垃圾评论,我怀疑是我的验证码被绕过了,但由于自己没有去看django-simple-captcha的代码,当时只猜测是攻击者“识别”了验证码内容,但现在看来也可能是由于随机数种子漏洞导致的。
对,使用django-simple-captcha后,你的进程随机数种子将泄露给用户。
我们来看看django-simple-captcha的工作流程。首先,开发者需要为需要验证码的Django表单(forms)增加一个CaptchaField字段:
class UserForm(forms.Form):
username = forms.CharField(...)
captcha = CaptchaField(widget=CustomCaptchaTextInput, label=_('Captcha'))
...渲染表单的时候,CaptchaField内部会生成随机的验证字符串(challenge)和答案(response)。challenge可以是传统的4个字符的文本,也可以是我博客或Jumpserver中使用的四则运算,这个通过配置来定义。
然后,challenge和response会按照如下算法生成一个唯一的hashkey:
randrange = random.SystemRandom().randrange
key_ = (
smart_text(randrange(0, MAX_RANDOM_KEY))
+ smart_text(time.time())
+ smart_text(self.challenge, errors="ignore")
+ smart_text(self.response, errors="ignore")
).encode("utf8")
self.hashkey = hashlib.sha1(key_).hexdigest()这个hashkey将返回给用户,用户通过这个hashkey和下面的captcha_image视图生成验证码图片。
在页面中展示验证码时,django-simple-captcha提供了一个captcha_image视图,开发者需要将其加入url routers中:

captcha_image视图只接收一个参数,即为用户传入的key:
def captcha_image(request, key, scale=1):
if scale == 2 and not settings.CAPTCHA_2X_IMAGE:
raise Http404
try:
store = CaptchaStore.objects.get(hashkey=key)
except CaptchaStore.DoesNotExist:
# HTTP 410 Gone status so that crawlers don't index these expired urls.
return HttpResponse(status=410)
random.seed(key) # Do not generate different images for the same key
#...这里的key就是前面计算的验证码hashkey,作用是通过它查找到数据库中对应的验证码。如果验证码存在,则将key传给random.seed函数并执行后续操作,后面的代码多次调用了伪随机数相关函数,用于给验证码图片生成旋转、噪点。
问题就出在这里了,开发者使用random.seed(key)的目的是将后续操作中的随机因素固定,保证key相同的情况下生成的验证码图片完全相同。但因为key是一个用户已知的值,那么用户就可以用于预测后续生成的所有的伪随机数。
这个过程中有两点值得注意:
我们并不可以“篡改”或“控制”随机数种子,而只可以“查看”随机数种子,因为key的生成过程是不可控的
在调用
random.seed(key)以前验证码就已经生成好了,这里设置随机数种子的目的只是为了让验证码图片中的旋转和噪点保持一致
这两点并不影响我们的漏洞利用,因为攻击者已知了此时的随机数种子,就可以预测后续所有的伪随机数生成函数的结果——不仅包括django-simple-captcha后续生成的验证码,也包括jumpserver中其他使用了伪随机数的场景。
这个漏洞的另一个核心点就是Jumpserver内部使用伪随机数来生成找回密码时的Token。虽然Python官方文档中明确申明不要以安全为目的使用random模块,并且在提供了secrets模块作为替代选项:
Warning The pseudo-random generators of this module should not be used for security purposes. For security or cryptographic uses, see the
secretsmodule.
但是不幸的是Jumpserver仍然使用的random模块来生成Token:
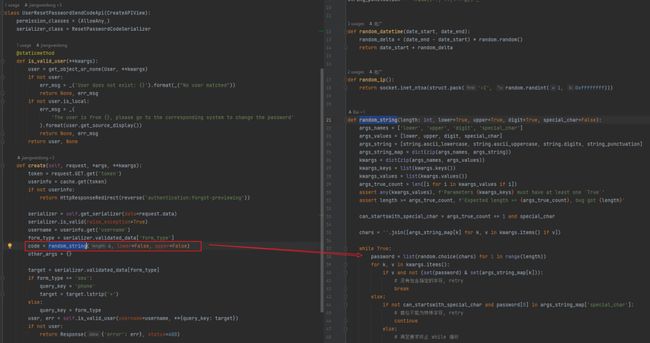
那么答案就呼之欲出了,使用第三方模块django-simple-captcha提供的方式获取固定在进程中的伪随机数种子,然后马上请求UserResetPasswordSendCodeApi生成找回密码使用的code,通过预测这个code修改目标用户密码。
漏洞利用过程没有太复杂,只是需要注意几个点:
Jumpserver以多进程负债均衡的方式运行,而每次请求只会固定当前进程的伪随机数种子,所以我们需要尝试发送数个相同的请求将所有进程中的种子固定
进入找回密码步骤本身也需要输入验证码,如果编写自动化程序,也可以尝试使用这个方法来预测验证码
为了让读者更加理解漏洞的本质,我编写了半自动的脚本来简化步骤,这部分内容已上线Vulhub:https://github.com/vulhub/vulhub/tree/master/jumpserver/CVE-2023-42820,可以参阅复现。
这里再说下修复方法,我推荐如下三种情况:
如果不关注原
random_string函数函数中的功能,可以简单将其替换成Django内置的django.utils.crypto.get_random_string如果仍想保留原
random_string函数函数中的功能,也可以将函数中的random模块换成secrets模块,但需要Python版本3.6及以上如果想兼容3.6以下的Python,可以使用操作系统提供的随机数发生器
random.SystemRandom()
当然,现在官方使用的修复方案在大部分情况下也没什么问题:

将伪随机数种子设置成None背后发生的事情,以及如何调试CPython底层C代码来理解其运行原理,可以参考我在星球的这篇帖子:《CPython底层调试 - random.seed背后发生了什么》。
CVE-2023-43650:重置密码Token可爆破漏洞
这个漏洞和上一个漏洞略有不同。我们在进入重置密码页面的时候,需要输入一次验证码:

输入成功后会跳转到第二个页面,用于找回密码:
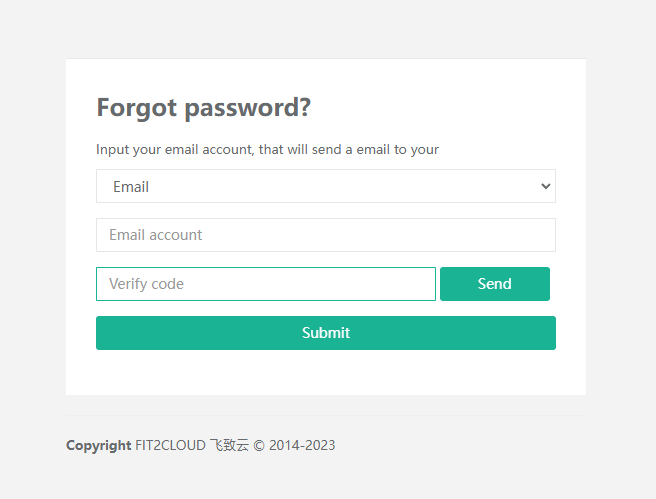
如果你看过Vulhub中复现CVE-2023-42820的过程,你应该记得这两个步骤——用户在第一个页面输入账号和验证码后,会生成一个随机的Token附于跳转URL中:
class UserForgotPasswordPreviewingView(FormView):
template_name = 'users/forgot_password_previewing.html'
form_class = forms.UserForgotPasswordPreviewingForm
@staticmethod
def get_redirect_url(token):
return reverse('authentication:forgot-password') + '?token=%s' % token
def form_valid(self, form):
username = form.cleaned_data['username']
user = get_object_or_none(User, username=username)
...
token = random_string(36)
user_map = {'username': user.username, 'phone': user.phone, 'email': user.email}
cache.set(token, user_map, 5 * 60)
return redirect(self.get_redirect_url(token))这个Token会保存在缓存里,过期时间是5分钟。也就是说,5分钟内使用这个Token访问第二个密码找回的页面,都不需要再次输入验证码。
而第二个页面中会生成6位数字的Verify Code,所以我们可以直接爆破这个Code。
官方对于这个漏洞的修复方法是,在验证Verify Code的时候限制次数,超过三次则强制过期这个Code:

但我理解这个修复方法其实不能解决本质问题,因为本质问题是前面的验证码Token没有过期,而非这个Verify Code没有过期。换句话说,最新版本的代码中,攻击者仍然可以爆破Verify Code——只需不断生成新的Verify Code,然后用同一个Code(如123456)来尝试,总能遇到某次生成的Verify Code与123456相等,最后修改用户密码。
CVE-2023-42819:Playbook任意文件读取/写入漏洞
Jumpserver使用ansible来管理主机,playbook是ansible中用于管理主机的机制,使用者可以通过编写基于YAML的配置文件来下发任务到主机中。
我们在进入Jumpserver后台以后,有很多地方可以用来执行命令或读写文件。但我们需要区分这个命令是在哪个机器上执行的:用户推送命令到自己管理的主机中执行,这个是符合预期的行为,但是如果用户在Jumpserver这台堡垒机服务器上执行了任意命令或读写任意文件,这就是非预期的漏洞了。
这个漏洞就是后者,但它其实和playbook没啥关系,主要问题还是出在Jumpserver本身的代码中。Jumpserver支持用户在Web页面中上传、下载、浏览playbook模板文件,比如ops.api.playbook.PlaybookFileBrowserAPIView这个视图:
class PlaybookFileBrowserAPIView(APIView):
def get(self, request, **kwargs):
playbook_id = kwargs.get('pk')
playbook = get_object_or_404(Playbook, id=playbook_id)
work_path = playbook.work_dir
file_key = request.query_params.get('key', '')
if file_key:
file_path = os.path.join(work_path, file_key)
with open(file_path, 'r') as f:
try:
content = f.read()
except UnicodeDecodeError:
content = _('Unsupported file content')
return Response({'content': content})
else:
expand_key = request.query_params.get('expand', '')
nodes = self.generate_tree(playbook, work_path, expand_key)
return Response(nodes)这里在获取用户输入file_key后直接使用os.path.join(work_path, file_key)来拼接路径并读取文件。那么就可以直接使用../../../../../etc/passwd或/etc/passwd进行目录穿越并读取任意文件。
为什么可以直接使用
/etc/passwd而不需要../,请参考我在2017年分享在星球的帖子:https://t.zsxq.com/122oWQ0a2
尝试复现这个漏洞,我们需要先创建一个Playbook。位置在“工作台 -> 作业中心 -> 模板管理 -> Playbook管理 -> 创建Playbook”,创建后会获得一个uuid格式的id:
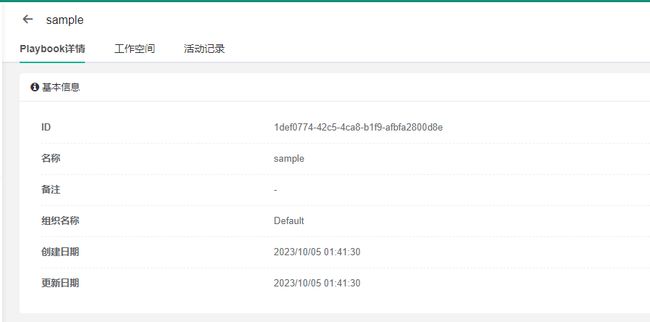
然后直接访问http://your-ip:8080/api/v1/ops/playbook/[uuid]/file/?key=/etc/passwd即可读取到passwd文件:
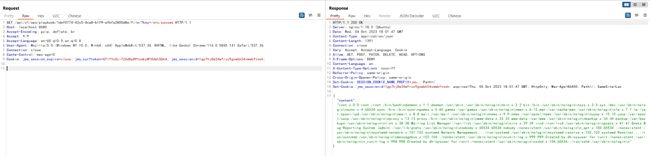
写文件也在同一个视图中,只不过是POST方法:

我在这里向/etc/cron.d中写入了一个文件,文件名是rce,内容是计划任务。
文件写入成功后,即可看到touch /tmp/success已成功执行:

值得注意的有两个问题:
由于这个数据包是POST方法,所以需要增加CSRF头
X-CSRFToken,只需要让其值和Cookie中的jms_csrftoken相同即可(关于Django中的Cookie based CSRF的原理,可以参考我的这篇文章《Cookie-Form型CSRF防御机制的不足与反思》)计划任务需要以空白行结尾,增加一个
\n即可
利用CVE-2023-42820和CVE-2023-42819两个漏洞,我们就可以实现从一个无权限的游客到最后Getshell的完整过程。
CVE-2023-43652:公钥信任逻辑造成用户接管漏洞
这也是一个比较有趣的问题。
讲清楚这个问题前,需要先简单了解一下Jumpserver的架构。完整的社区版Jumpserver包含下面这些组件:
Core 组件是 JumpServer 的核心组件,其他组件依赖此组件启动
Lina是Core的前端
Koko 是服务于类 Unix 资产平台的组件,通过 SSH、Telnet 协议提供字符型连接
Luna是Koko的前端
Lion 是图形协议的组件,用于 Web 端访问 RDP、VNC 等服务
其底层依赖于Apache Guacamole Server
Magnus 数据库网关,用于用户连接访问常见数据库
Chen 数据库Web管理组件,用户可以使用Web端管理各种数据库
Kael 连接GPT资产的组件(实际上和堡垒机项目没啥关系了)
Celery 是处理异步任务的组件,用于执行 JumpServer 相关的自动化任务
Nginx Web网关
其中,Koko提供了对于SSH的支持。用户连接上Koko的SSH终端后,会进入一个一个主机选择的页面,我们在其中选择实际要连接的目标服务器,这就是堡垒机的核心功能之一:
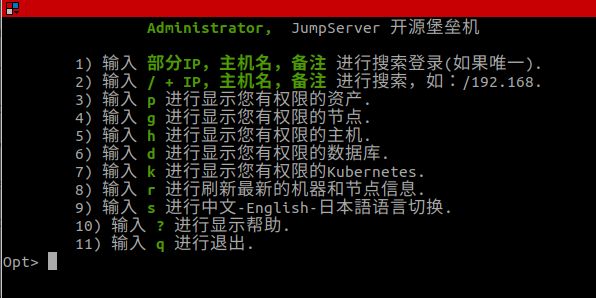
在Jumpserver的架构中,只有Core服务会连接数据库,那么对于Koko这样的组件,就需要通过使用Core提供的API来进行用户身份的鉴权。
Koko是Go开发的组件,其ssh终端服务基于github.com/gliderlabs/ssh:
import "github.com/gliderlabs/ssh"
func NewSSHServer(jmsService *service.JMService) *Server {
...
sshHandler := handler.NewServer(termCfg, jmsService)
srv := &ssh.Server{
Addr: addr,
KeyboardInteractiveHandler: auth.SSHKeyboardInteractiveAuth,
PasswordHandler: sshHandler.PasswordAuth,
PublicKeyHandler: sshHandler.PublicKeyAuth,
...
}
return &Server{srv, sshHandler}
}其中两个配置函数PasswordHandler和PublicKeyHandler用于校验用户身份,用户连接SSH端口并输入密码后,会调用PasswordHandler来验证密码是否正确,对于密钥的认证则是使用PublicKeyHandler:
func (s *Server) PasswordAuth(ctx ssh.Context, password string) ssh.AuthResult {
ctx.SetValue(ctxID, ctx.SessionID())
tConfig := s.GetTerminalConfig()
if !tConfig.PasswordAuth {
logger.Info("Core API disable password auth auth")
return ssh.AuthFailed
}
sshAuthHandler := auth.SSHPasswordAndPublicKeyAuth(s.jmsService)
return sshAuthHandler(ctx, password, "")
}
func (s *Server) PublicKeyAuth(ctx ssh.Context, key ssh.PublicKey) ssh.AuthResult {
ctx.SetValue(ctxID, ctx.SessionID())
tConfig := s.GetTerminalConfig()
if !tConfig.PublicKeyAuth {
logger.Info("Core API disable publickey auth")
return ssh.AuthFailed
}
sshAuthHandler := auth.SSHPasswordAndPublicKeyAuth(s.jmsService)
value := string(gossh.MarshalAuthorizedKey(key))
return sshAuthHandler(ctx, "", value)
}跟进可以发现,这两个函数实际上都是使用HTTP请求Core组件提供的API来验证用户身份。那我们回到Core的代码看看身份的验证的过程是怎样的。
默认情况下,Django使用数据库中提供的User模型来验证用户,但开发者也可以编写自己的用户身份验证后端,比如使用LDAP、OpenID等来实现统一身份认证协议。
在Jumpserver的配置中,我们可以看到它支持多个认证后端:
RBAC_BACKEND = 'rbac.backends.RBACBackend'
AUTH_BACKEND_MODEL = 'authentication.backends.base.JMSModelBackend'
AUTH_BACKEND_PUBKEY = 'authentication.backends.pubkey.PublicKeyAuthBackend'
AUTH_BACKEND_LDAP = 'authentication.backends.ldap.LDAPAuthorizationBackend'
AUTH_BACKEND_OIDC_PASSWORD = 'authentication.backends.oidc.OIDCAuthPasswordBackend'
AUTH_BACKEND_OIDC_CODE = 'authentication.backends.oidc.OIDCAuthCodeBackend'
AUTH_BACKEND_RADIUS = 'authentication.backends.radius.RadiusBackend'
AUTH_BACKEND_CAS = 'authentication.backends.cas.CASBackend'
AUTH_BACKEND_SSO = 'authentication.backends.sso.SSOAuthentication'
AUTH_BACKEND_WECOM = 'authentication.backends.sso.WeComAuthentication'
AUTH_BACKEND_DINGTALK = 'authentication.backends.sso.DingTalkAuthentication'
AUTH_BACKEND_FEISHU = 'authentication.backends.sso.FeiShuAuthentication'
AUTH_BACKEND_AUTH_TOKEN = 'authentication.backends.sso.AuthorizationTokenAuthentication'
AUTH_BACKEND_SAML2 = 'authentication.backends.saml2.SAML2Backend'
AUTH_BACKEND_OAUTH2 = 'authentication.backends.oauth2.OAuth2Backend'
AUTH_BACKEND_TEMP_TOKEN = 'authentication.backends.token.TempTokenAuthBackend'
AUTH_BACKEND_CUSTOM = 'authentication.backends.custom.CustomAuthBackend'
AUTHENTICATION_BACKENDS = [
# 只做权限校验
RBAC_BACKEND,
# 密码形式
AUTH_BACKEND_MODEL, AUTH_BACKEND_PUBKEY, AUTH_BACKEND_LDAP, AUTH_BACKEND_RADIUS,
# 跳转形式
AUTH_BACKEND_CAS, AUTH_BACKEND_OIDC_PASSWORD, AUTH_BACKEND_OIDC_CODE, AUTH_BACKEND_SAML2,
AUTH_BACKEND_OAUTH2,
# 扫码模式
AUTH_BACKEND_WECOM, AUTH_BACKEND_DINGTALK, AUTH_BACKEND_FEISHU,
# Token模式
AUTH_BACKEND_AUTH_TOKEN, AUTH_BACKEND_SSO, AUTH_BACKEND_TEMP_TOKEN,
]用户在登录时调用django.contrib.auth.authenticate(),Django内部会遍历AUTHENTICATION_BACKENDS配置中所有的认证后端,逐一进行尝试。如果第一个身份验证方法失败,Django 将尝试第二个身份验证方法,依此类推,直到尝试完所有后端。
所以,只要某一个认证后端认证成功,用户即可认证成功。
Koko在请求Core组件时,使用到的后端是authentication.backends.base.JMSModelBackend和authentication.backends.pubkey.PublicKeyAuthBackend。前者继承传统的数据库认证后端,传入账号、密码后进行校验;后者则使用公钥进行认证,相关代码如下:
class JMSBaseAuthBackend:
...
def user_can_authenticate(self, user):
return True
class PublicKeyAuthBackend(JMSBaseAuthBackend):
...
def authenticate(self, request, username=None, public_key=None, **kwargs):
if not public_key:
return None
if username is None:
username = kwargs.get(UserModel.USERNAME_FIELD)
try:
user = UserModel._default_manager.get_by_natural_key(username)
except UserModel.DoesNotExist:
return None
else:
if user.check_public_key(public_key) and \
self.user_can_authenticate(user):
return user
class AuthMixin:
...
@staticmethod
def get_public_key_body(key):
for i in key.split():
if len(i) > 256:
return i
return key
def check_public_key(self, key):
if not self.public_key:
return False
key = self.get_public_key_body(key)
key_saved = self.get_public_key_body(self.public_key)
if key == key_saved:
return True
else:
return False可见,PublicKeyAuthBackend后端认证时只要check_public_key和user_can_authenticate函数均返回true则认证成功,而这两个函数的作用就是简单的比对一下用户传入的公钥是否和数据库中保存的公钥相等。
也就是说,对于公钥认证后端PublicKeyAuthBackend来讲,攻击者只要知道一个用户的用户名和公钥,即可通过PublicKeyAuthBackend后端的认证。
很离谱,我们来复现一下这个漏洞。首先,以正常用户登录控制台,来到右上角个人中心->更新SSH密钥页面,将你的公钥粘贴到页面中保存:
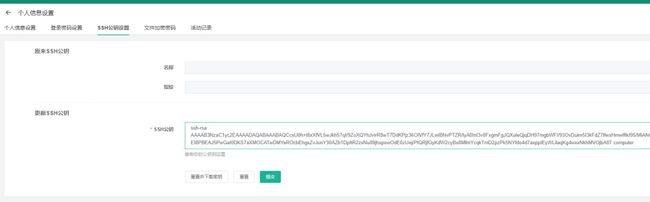
这样,你以后就可以直接通过公钥认证的方式来登录堡垒机SSH了。
然后我们直接发送包含用户名和公钥的请求给/api/v1/authentication/tokens/,可见已成功认证并返回用户Token和详细信息:
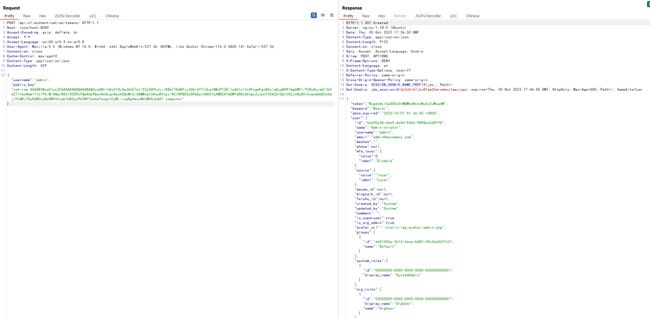
使用这个Token即可以用户正常身份访问所有有权限的API接口:
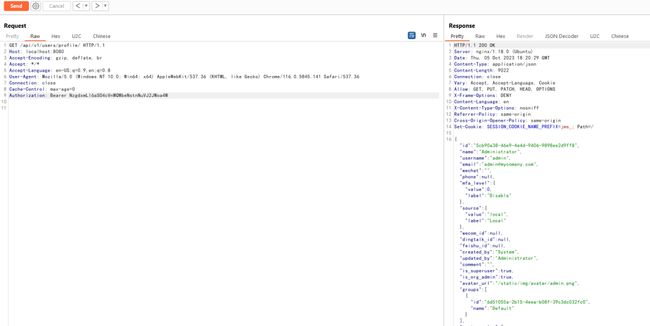
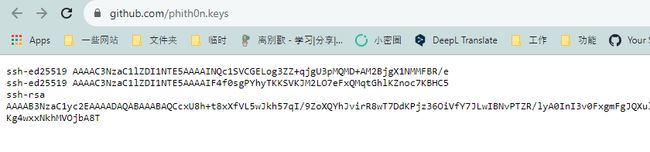
那么,最后一个问题,我们怎么获得用户的公钥呢?既然是公钥,理论上我们就可以认为是公开的。比如,我们可以通过Github拿到任意一个用户的所有公钥,如https://github.com/phith0n.keys:
CVE-2023-42818:SSH服务端认证绕过漏洞
经过对前一个漏洞的分析,我们已经大致了解了Jumpserver堡垒机的架构,其中最重要的两个模块就是Core和Koko,前者提供Web服务相关逻辑,后者提供SSH服务相关逻辑。
要准确理解本章节的内容,最好是先了解一下SSH握手认证的过程,但这里面涉及的篇幅过长,又可以单独写一篇文章来介绍了,所以只能略过详情。我们只需知道一点,传统SSH服务基于公钥认证时,客户端会将用户的公钥传输给服务端,服务端去~/.ssh/authorized_keys文件中匹配,如果能够匹配上才会执行后续签名验证的过程。
在Jumpserver中,用户使用ssh客户端连接koko以后,koko会从ssh协议的握手包中取到用户的公钥,然后使用Core服务提供的API来校验这个用户的公钥是否存在,此时Core服务提供的API取代的就是~/.ssh/authorized_keys文件的功能。
前面的CVE-2023-43652漏洞就是将Core的这个API给攻击者任意调用所导致的,官方最后的修复方法是给公钥认证后端PublicKeyAuthBackend中增加一层额外的Token头校验,只允许Koko来调用。
CVE-2023-42818漏洞和前面这个漏洞很像,都是攻击者只需要知道目标用户的公钥即可伪造其身份,但其实原理还是不太一样的。CVE-2023-42818漏洞的原理实际上是一个逻辑Bug,其核心出现在Koko依赖的一个库https://github.com/LeeEirc/crypto中。
Koko为了实现SSH登录的二次认证,魔改了下面两个项目:
replace (
github.com/gliderlabs/ssh => github.com/LeeEirc/ssh v0.1.2-0.20220323091501-23b956e1e5a8
golang.org/x/crypto => github.com/LeeEirc/crypto v0.0.0-20230406074824-78021579524f
)gliderlabs/ssh模块用于启动ssh服务,而签名认证相关算法是在golang.org/x/crypto模块中。
官方魔改这两个库代码时引入了一处逻辑错误:当使用Core API校验公钥成功但用户开启二次认证(MFA)时,会返回一个ErrPartialSuccess错误,外部代码遇到该错误则会进入到下一次验证过程,也就是MFA;但对于golang.org/x/crypto模块来讲,只要遇到错误就不会进行私钥签名的校验。
那么造成的一个后果就是,私钥签名认证不会执行,只要MFA的验证能够通过,则最后SSH认证就能够成功。
要复现这个漏洞需要魔改自己的SSH客户端,因为常规的SSH客户端无法指定用户公钥,感兴趣的朋友可以自己编写代码来实现这个POC。
CVE-2023-43651:MongoDB Proxy任意代码执行漏洞
Jumpserver堡垒机除了提供SSH的管理外,还提供了各种其他服务的代理。管理员在后台增加了这些资产后,用户就可以在Koko的Web端连接并管理,和SSH类似。
对于Koko支持的服务,这里分为几种情况:
如果是Telnet、SSH等服务,Koko将调用Go library来进行连接
如果是Magnus支持的数据库,Jumpserver会使用Magnus提供的Web页面来管理
MySQL 5.7/8.0+
MariaDB
PostgreSQL (X-Pack)
Oracle (X-Pack)
对于其他数据库(如MongoDB、redis、clickhouse等),Jumpserver会使用相对应的命令行客户端来连接,并将标准输入输出重定向到Web端
MongoDB使用
mongoshRedis使用
redis-cliClickhouse使用
clickhouse-client
CVE-2023-43651漏洞原理其实很简单,当Koko连接MongoDB时,会调用mongosh这个命令行工具。而mongosh提供的交互式控制台中,支持直接使用JavaScript执行任意代码,这部分代码将会在客户端也就是mongosh所在的机器上执行。
我们在本文前面也提到过下面这个很重要的概念:
在进入Jumpserver后台以后,有很多地方可以用来执行命令或读写文件。但我们需要区分这个命令是在哪个机器上执行的:用户推送命令到自己管理的主机中执行,这个是符合预期的行为,但是如果用户在Jumpserver这台堡垒机服务器上执行了任意命令或读写任意文件,这就是非预期的漏洞了。
这里很明显是后者,所以是一个命令执行漏洞。
复现方法是,在Jumpserver后台增加MongoDB资产并来到Web Terminal模块连接数据库,即可在交互式命令行中执行JavaScript代码:
console.log(require("child_process").execSync("id").toString())
官方对于该漏洞的修复方式是限制Linux主机上各种命令的执行权限:

对于这个修复方法我只能说保留意见。
CVE-2023-42442:Session录像任意下载漏洞
CVE-2023-42442漏洞是一个组合洞,包含Jumpserver中的两个Bug:一是API未授权访问导致泄露session信息;二是目录权限绕过导致录像文件被下载。
Jumpserver的Core模块基于Django开发,其中包含两种类型的后端视图:
基于原生Django与模板渲染的视图
基于Django Rest Framework(DRF)的API视图
对于后者,Jumpserver直接使用了DRF的权限模型来验证用户权限。关于Django Rest Framework的权限体系的介绍,可以参考我2017年写的一篇文章《从Pwnhub诞生聊Django安全编码》。
DRF的Permission基础权限接口存在两个函数:
has_permission判断列表相关方法的权限has_object_permission判断数据库对象相关方法的权限
在Jumpserver中,IsSessionAssignee继承了基础权限类:
from rest_framework import permissions
class IsSessionAssignee(permissions.BasePermission):
def has_object_permission(self, request, view, obj):
try:
return obj.ticket_relation.first().ticket.has_all_assignee(request.user)
except:
return False但其只实现了has_object_permission函数,没有实现has_permission函数。这意味着list相关与对象无关的方法将不会有权限校验,可以直接被游客访问。
全局搜索IsSessionAssignee,可见有一个视图使用了这个类:
class SessionViewSet(OrgBulkModelViewSet):
model = Session
serializer_classes = {
'default': serializers.SessionSerializer,
'display': serializers.SessionDisplaySerializer,
}
search_fields = [
"user", "asset", "account", "remote_addr",
"protocol", "is_finished", 'login_from',
]
filterset_class = SessionFilterSet
date_range_filter_fields = [
('date_start', ('date_from', 'date_to'))
]
extra_filter_backends = [DatetimeRangeFilter]
rbac_perms = {
'download': ['terminal.download_sessionreplay']
}
permission_classes = [RBACPermission | IsSessionAssignee]
...这个视图用于展示所有连接过的session列表。比如,用户不论从SSH还是从Web Terminal访问堡垒机中的服务器,都会建立一个Session,我们可以通过这个接口来访问:
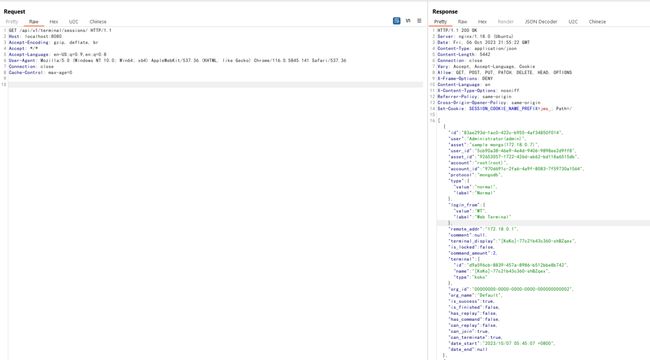
可见成功拉取到session列表,并获得所有详情信息。
如果想要下载某个session的录像,我们需要访问media中对应的文件。在jumpserver/urls.py中可以看到静态文件相关的路由:
urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
urlpatterns += [
# Protect media
path('media/', include(private_storage.urls)),
]这里使用了django-private-storage这个第三方模块来管理静态文件,这个模块的作用就是保证静态文件只允许被有权限的用户下载访问。其权限校验相关回调函数在PRIVATE_STORAGE_AUTH_FUNCTION中,我们全局搜索一下这个配置:
PRIVATE_STORAGE_ROOT = MEDIA_ROOT
PRIVATE_STORAGE_AUTH_FUNCTION = 'jumpserver.rewriting.storage.permissions.allow_access'跟进jumpserver.rewriting.storage.permissions.allow_access:
path_perms_map = {
'xpack': '*',
'settings': '*',
'replay': 'default',
'applets': 'terminal.view_applet',
'playbooks': 'ops.view_playbook'
}
def allow_access(private_file):
request = private_file.request
request_path = private_file.request.path
path_list = str(request_path)[1:].split('/')
path_base = path_list[1] if len(path_list) > 1 else None
path_perm = path_perms_map.get(path_base, None)
if not path_perm:
return False
if path_perm == '*' or request.user.has_perms([path_perm]):
return True
if path_perm == 'default':
return request.user.is_authenticated and request.user.is_staff
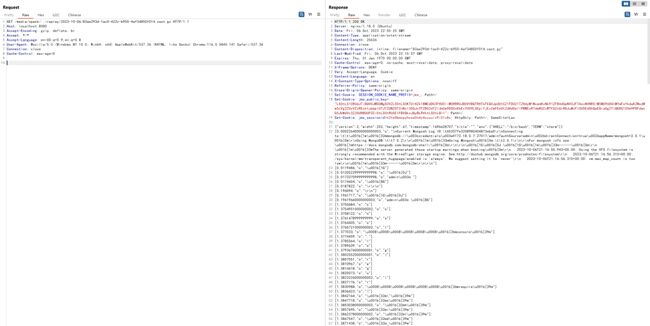
return False分析这个函数的逻辑可以发现,这里是使用request.path来进行权限判断,当path是以xpack/或settings/开头的情况下,直接返回True。
那么,如果我们访问xpack/../就可以绕过权限验证,下载到replay文件,这是一个很经典的逻辑Bug:
不光可以下载到replay文件,只要是data/media/目录下的文件都可以下载,比如applets下的代码文件等:
总结
本文介绍了Jumpserver在9月份修复的数个安全漏洞,其中相对比较严重的是伪随机数泄露导致的用户劫持漏洞和Session录像下载漏洞。利用前者我们可以修改任意用户密码,再集合playbook目录穿越漏洞即可Getshell。
Jumpserver官方对于漏洞十分公开透明,所有上述漏洞都申请了CVE编号并发布了漏洞告警,值得被部分国产软件学习。
相信在阅读本文后,你会对Jumpserver的架构有一定了解。文章中还留有一些坑等你来填,有兴趣可以深入研究,并欢迎在『代码审计』知识星球内分享。

喜欢这篇文章,点个在看再走吧~