学习Django
@Django
一个小白的自学之路
这是我在CSDN上的第一篇文章,主要是为了记录自己自学一个框架的过程,整个过程都会一直更新,主要为了督促自己可以更好的去学习,如果我的学习过程可以帮到你,那我会很高兴。
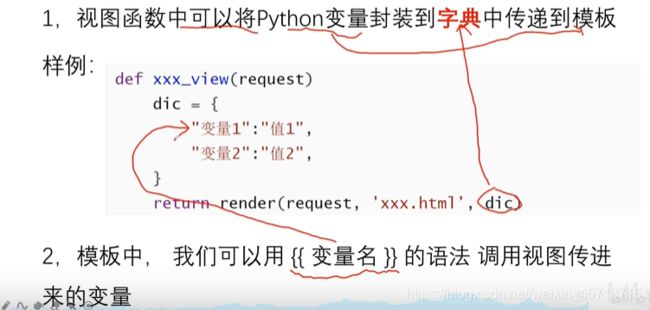
学习中经常取得成功可能会导致更大的学习兴趣,并改善学生作为学习的自我概念。
为什么学?
这个篇文章的写作时间是2021年7月,也就是我毕业的时间,这个时间比较尴尬,很多公司招人都着了差不多了,所以招的人数和工资都会被压缩,每天都在看各种招聘信息,感觉自己缺少的东西真的太多了,因此想丰富一下自己的知识结构。
要学习的主要原因有以下几个点:
- 工作目标 ,我的大学本科是计算机科学与技术一个很尴尬的专业,这个专业啥都学,但是啥都不深,再一次偶然的机会我接触到了Python,知识接触到了很少的一部分,但是慢慢的发现自己喜欢上了这个语言;
- 自我劝说,为啥叫自我劝说呢?因为我想到了这个词,对就是这么任性,这个主也是一个偶然的机会,我在大三期间有一个课程,需要写一篇文章,我文章叙述点是编程语言的发展,其中就有Python,然后我也慢慢了解到了Python的发展速度,这应该就是让我继续学Python的一个关键节点吧;
- 入坑指南,前面说了,我开始知识接触到了一点点的Python,然后呢我就开始了自己的自学Python之旅,从基本的数据类型,到各种方法的应用,然后到了爬虫,慢慢的自己也逐渐接受了这个快速的开发语言;
- 第一个项目,也不能说是一个项目吧,其实就是一个简单的毕设,我大学毕设题目的选题是一个人脸识别,这个也是要是自己之前学了一段时间想看看自己学的咋样,因此,就选择Python作为开发语言,做了一个人脸识别,用的算法是OpenCV,整个项目做完感觉还是可以的,这个可能是我坚持做Python的一个因素吧;
- 专业培训,计算机专业的很多人都知道有计算机培训机构,我去了一段时间,待了2天,为什么没有继续待下去呢,主要原因是我这边确实有些事情需要处理一下,所以就放弃了,说一下自己的感受吧,我听了两天的课,对,你没听错,我去了第一天就去上课了,虽然很累我还是很开心,培训机构讲的一下知识确实很细,但是呢这是在我学过的前提下,我的专业课老师曾经告诉过我,学校和培训机构的最大区别就是学校会告诉你为什么,教育机构会告诉你记住这么用就行了;这次学习吧,感觉还可以,虽然只有2天;
- Django,我之前自学过爬虫,虽然都是很低级的,但是爬点
美女图片还是可以的,然后自己在找工作过程中发现确实有很多公司需要你去会这个框架,因此想自学一下。
学习路径
万能的哔哩哔哩。
学习过程
在这就开始记录自己的学习过程了,记录下自己学到的每一个知识点,如果你还在读大学,没准期末考试会看到。
安装软件
别问我什么自学了这么久你还没有软件,我做毕设,然后以防我们的bug10出问题,所以我就半年甚至一年多没更新过系统,又一次忘记点中断更新了,然后他就更新了,然后系统有个文件就有问题了,然后我就傻了,每天写论文都是提心吊胆,每天论文都会进行备份,程序也会备份,所以在毕设过程结束后我就重装了电脑,对于软件的安装就不过多叙述了,下载软件,就一直next就行了,我这里给一个我自己用的版本和一个文件(懂的都懂):提取码:28qj
Python安装教程在此不再赘述了,大家可以自行去Python官网进行下载,如果Python官网没有你想用的Python版本,可以去问问度娘。
开始学习
现在开始记录我的学习过程,可能会不全,那就是还在学习过程中,正在持续更新中…
python版本:3.6(提取码:f7j4)(3.6/3.7/3.8/3.9都有)
Django版本:2.2.12(使用pip,然后修改等号后面的版本即可)
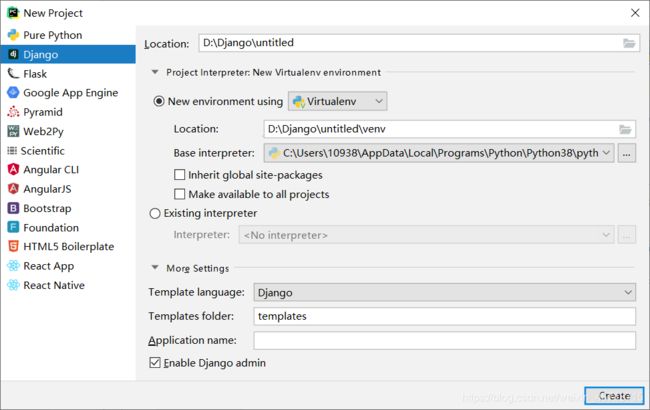
安装框架
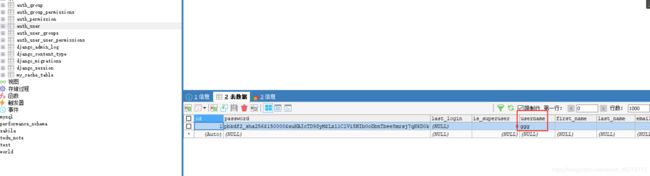
我是直接用pycharm里面的自带安装插件之间安装的,选用的版本呢是2.2.12,为什么选择这个版本呢,不是因为最新的就是这个版本,我写文章的时候最新的版本是3.2.5,差了1个大版本,选择这个版本的原因是2.2.12是LTS版本(什么是LTS?目前那个是LTS);具体内容请看链接,以及适合你当看到这个文章时候的LTS版本可能会新一些,具体怎么安装呢?
图片介绍如上。
创建第一个项目
很多人都用的是命令创建,我用的pycharm直接创建的,在这里给一个大佬们的创建方式:

我的创建方式:
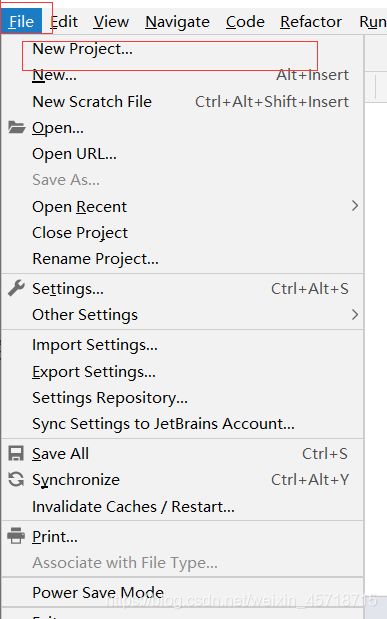
创建好了,然后他就报错了。
惊不惊喜意不意外!报错如下
Traceback (most recent call last):
File "D:/Django/mysite1/manage.py", line 22, in <module>
main()
File "D:/Django/mysite1/manage.py", line 18, in main
execute_from_command_line(sys.argv)
File "D:\Django\mysite1\venv\lib\site-packages\django\core\management\__init__.py", line 381, in execute_from_command_line
utility.execute()
File "D:\Django\mysite1\venv\lib\site-packages\django\core\management\__init__.py", line 325, in execute
settings.INSTALLED_APPS
File "D:\Django\mysite1\venv\lib\site-packages\django\conf\__init__.py", line 79, in __getattr__
self._setup(name)
File "D:\Django\mysite1\venv\lib\site-packages\django\conf\__init__.py", line 66, in _setup
self._wrapped = Settings(settings_module)
File "D:\Django\mysite1\venv\lib\site-packages\django\conf\__init__.py", line 157, in __init__
mod = importlib.import_module(self.SETTINGS_MODULE)
File "C:\Users\10938\AppData\Local\Programs\Python\Python38\lib\importlib\__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "" , line 1014, in _gcd_import
File "" , line 991, in _find_and_load
File "" , line 975, in _find_and_load_unlocked
File "" , line 671, in _load_unlocked
File "" , line 783, in exec_module
File "" , line 219, in _call_with_frames_removed
File "D:\Django\mysite1\mysite1\settings.py", line 58, in <module>
'DIRS': [os.path.join(BASE_DIR, 'templates')]
NameError: name 'os' is not defined
大概意思就是没定义os,我打开了相关的文件:
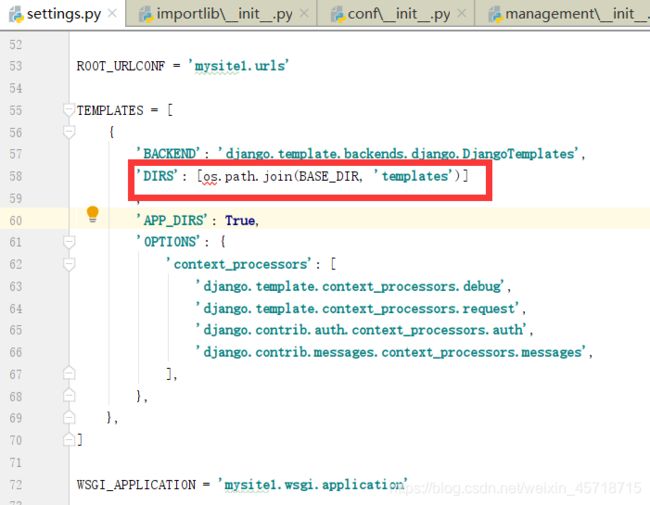
修改方法:
导入os模块:
import os
然后在运行:
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
July 16, 2021 - 21:21:07
Django version 2.2.15, using settings 'mysite1.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
第一行是报红的,原因是版本过高或过低,但是问题不大,然后我就打开了他给的链接:http://127.0.0.1:8000/,至此第一个项目运行成功!
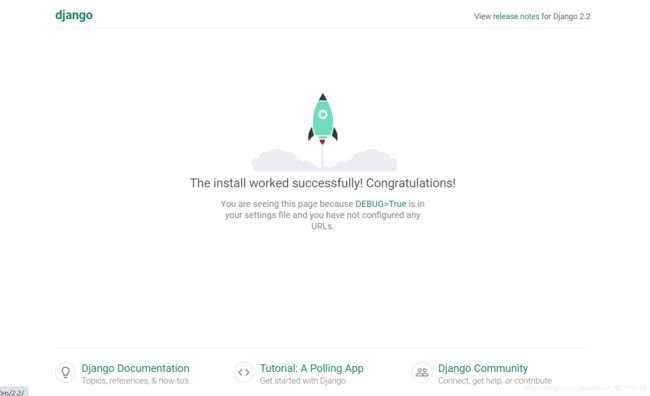
你以为这就结束了?为了解决这个
Watching for file changes with StatReloader
我去查了很多资料,说法也不一样,我使用了一种方法进行修正,就是版本不匹配问题,然后我就又去差了Django所匹配的Python版本,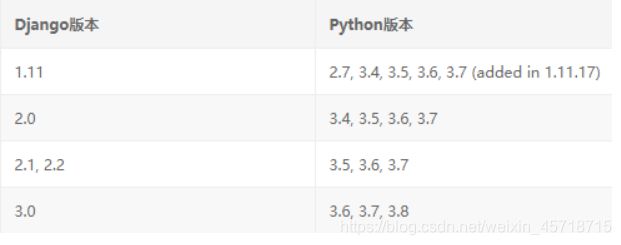
我一看心中暗喜,我用的Python版本是3.8,我以为是自己的版本不对导致的,所以我就找了一个很匹配的版本,也就是Python3.6,我就把原来的版本卸载,又卸载了pycharm,然后重新搞了一遍,然后运行发现还是有那个错,具体原因我也不知为啥,但是这个错不影响我运行,然后我把浏览器关了,停止了项目,当我再打开项目再次运行的时候,又出错了,
Performing system checks...
Watching for file changes with StatReloader
System check identified no issues (0 silenced).
Exception in thread django-main-thread:
Traceback (most recent call last):
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\threading.py", line 916, in _bootstrap_inner
self.run()
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "D:\Django\mysite1\venv\lib\site-packages\django\utils\autoreload.py", line 54, in wrapper
fn(*args, **kwargs)
File "D:\Django\mysite1\venv\lib\site-packages\django\core\management\commands\runserver.py", line 120, in inner_run
self.check_migrations()
File "D:\Django\mysite1\venv\lib\site-packages\django\core\management\base.py", line 453, in check_migrations
executor = MigrationExecutor(connections[DEFAULT_DB_ALIAS])
File "D:\Django\mysite1\venv\lib\site-packages\django\db\migrations\executor.py", line 18, in __init__
self.loader = MigrationLoader(self.connection)
File "D:\Django\mysite1\venv\lib\site-packages\django\db\migrations\loader.py", line 49, in __init__
self.build_graph()
File "D:\Django\mysite1\venv\lib\site-packages\django\db\migrations\loader.py", line 212, in build_graph
self.applied_migrations = recorder.applied_migrations()
File "D:\Django\mysite1\venv\lib\site-packages\django\db\migrations\recorder.py", line 73, in applied_migrations
if self.has_table():
File "D:\Django\mysite1\venv\lib\site-packages\django\db\migrations\recorder.py", line 56, in has_table
return self.Migration._meta.db_table in self.connection.introspection.table_names(self.connection.cursor())
File "D:\Django\mysite1\venv\lib\site-packages\django\db\backends\base\base.py", line 256, in cursor
return self._cursor()
File "D:\Django\mysite1\venv\lib\site-packages\django\db\backends\base\base.py", line 233, in _cursor
self.ensure_connection()
File "D:\Django\mysite1\venv\lib\site-packages\django\db\backends\base\base.py", line 217, in ensure_connection
self.connect()
File "D:\Django\mysite1\venv\lib\site-packages\django\db\backends\base\base.py", line 195, in connect
self.connection = self.get_new_connection(conn_params)
File "D:\Django\mysite1\venv\lib\site-packages\django\db\backends\sqlite3\base.py", line 194, in get_new_connection
conn = Database.connect(**conn_params)
TypeError: argument 1 must be str, not WindowsPath
大致错误是这个
TypeError: argument 1 must be str, not WindowsPath
错误原因呢是因为值得接收有问题,修改方法如下:
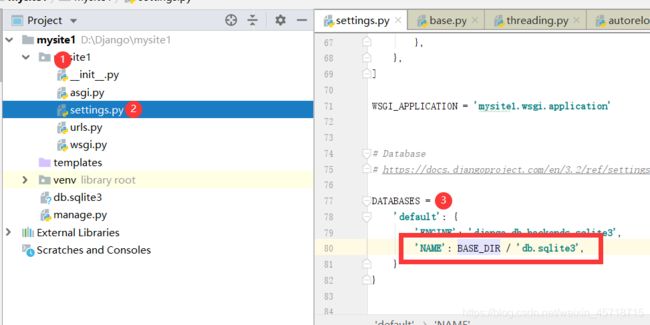
这里是错误的,修改如下:
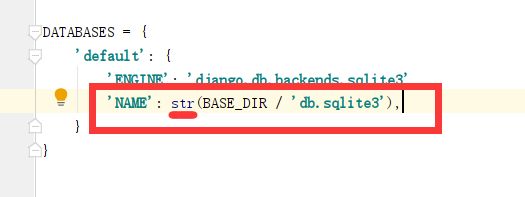
把传回的数据类型转为str就可以了。
在这里说一下,如果你想更换你的端口号,可以使用以下命令:

这个命令是将端口号改为5000,可以根据自己需要进行端口号的修改。
如果修改不成功,可以查看一下,是不是python3不是你的批处理命令,可以再试试:
python manage.py runserver 5000
修改成功会出现以下提示:
(venv) D:\Django\mysite1>python manage.py runserver 5000
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
July 17, 2021 - 07:50:30
Django version 2.2.12, using settings 'mysite1.settings'
Starting development server at http://127.0.0.1:5000/
Quit the server with CTRL-BREAK.
如果你用的是pycharm不知道在哪执行这个批处理命令,如下图:
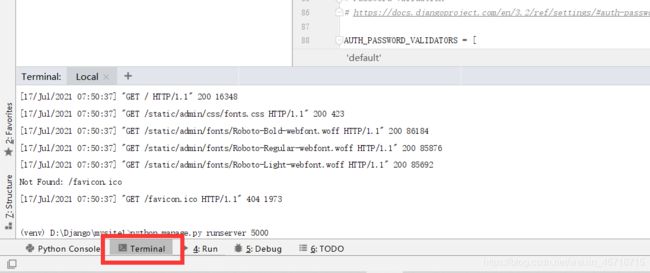
如果启动时候出现了端口占用,可以这样做:

报错小结
起初以为不可运行错误均是代码错误,经过多个版本测试,发现是3.x版本问题,当我将3.2.x版本卸载之后,给电脑默认安装了2.2.12版本之后,发现之前的错全部消失了。
项目结构

-
db.sqlite3文件:项目首次运行后生成的文件,是Django的默认数据库
-
manage.py文件:命令存储,

-
项目的同名文件夹:

sttings.py配置文件

首先解读一下这个句话,BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(file)))
使用print直接输出一下os.path.abspath(file),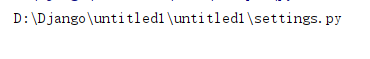

我们得到了该sttings文件的路径。
继续看os.path.dirname(os.path.abspath(file)),我们继续用print输出查看:
![]()
发现os.path.dirname该方法就是返回参数的上一级目录,也就是说BASE_DIR存放的是项目的绝对路径。
DEBUG = True
启动模式
-
True - 调试模式
检测代码改动后,立刻重启服务
报错页面 -
False - 正式启动模式/上线模式
出错了不会进行多余提示,只会告诉你错了
ALLOWED_HOSTS = []
请求头 HOST头
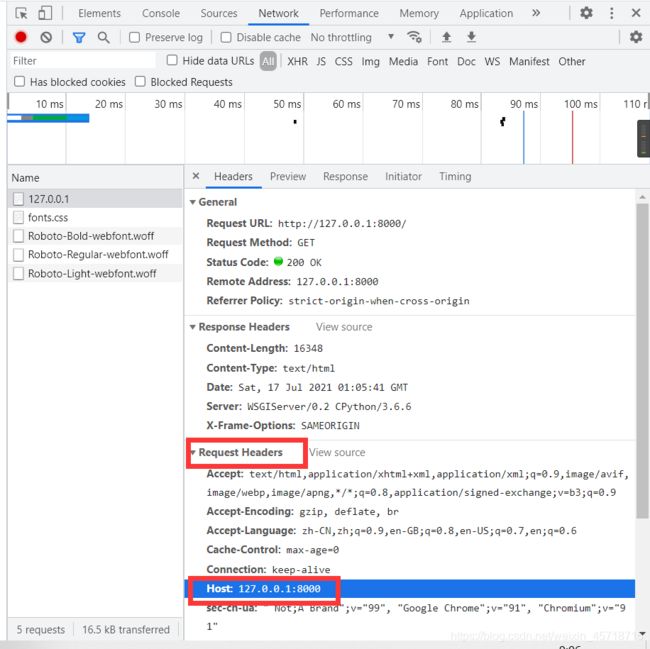
主要在上线以后的过滤访问使用。

在虚拟机上启动项目,然后使用我们的Windows去访问,需要将内网IP添加到ALLOWED_HOSTS中。
ROOT_URLCONF = ‘untitled1.urls’
Django访问的主路由,一般情况下不会变。
DATABASES = {
‘default’: {
‘ENGINE’: ‘django.db.backends.sqlite3’,
‘NAME’: os.path.join(BASE_DIR, ‘db.sqlite3’),
}
}
数据库配置,后面会换成MySQL。
LANGUAGE_CODE = ‘en-us’
语言设置,改成中文:
LANGUAGE_CODE = ‘zh-Hans’
TIME_ZONE = ‘UTC’
时区,UTC标准时间,如果运行日志中时间不对,原因是中国国内时间差8个时区,修改方法:
TIME_ZONE = ‘Asia/Shanghai’
小总结





URL
定义:统一资源定位符
作用:用来表示互联网上某个资源的地址
如下图:

详细解释各个部分:


http默认是80,一般不写
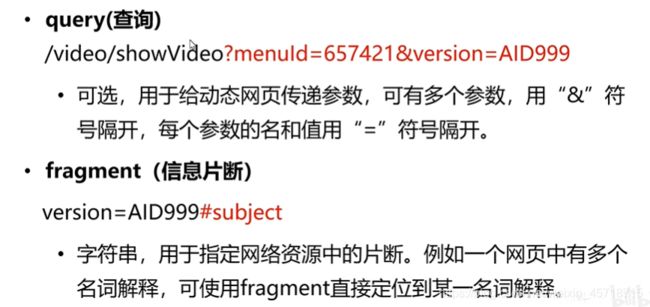
‘?’后面都是查询字符串,‘&’并。格式为key=value
‘#’后面就是锚点,锚点可以帮我直接定位到网页上的具体位置。
Django处理URL请求
模拟如下:


path(‘page/2003’,views.page_2003),
views.page_2003是视图
视图函数
定义:

注意第一个参数是request
返回值必须是HttpResponse对象
样例:

具体操作:
这部分主要是我们想加一个网页访问时,我们需要如何添加一个新的地址访问,首先我们要找到我们的主路由文件:
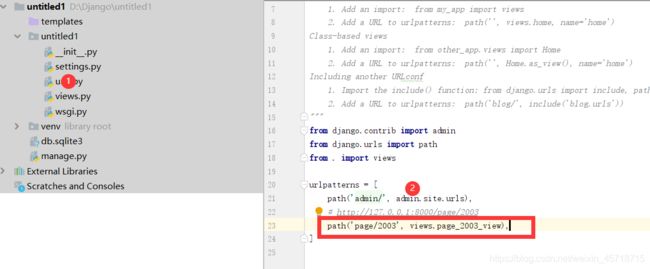
其中admin是默认生成的,我们无需修改,然后我们添加如下代码:
path('page/2003', views.page_2003_view),
注意后面的逗号
这句话也就是为我们的网站添加一个跳转,也就是127.0.0.1:8000/page/2003/,当用户访问我们的page/2003路由时,Django会查询
views.page_2003_view
的相关视图。
当我们添加相关的跳转之后,还需要我们去添加这个视图,添加方法如下:

新建python文件views.py,该文件里面创建相关的方法,导入HttpResponse方法。
def page_2003_view(request)
此处的方法名要和路由配置里面的视图方法名一致
默认第一个参数为request,必须有第一个参数。
详细代码如下:
from django.http import HttpResponse
def page_2003_view(request):
html = "这是我的第一个页面
"
return HttpResponse(html)
返回路由配置文件,添加导入方法。
# . 表示当目录下
from . import views
网页运行结果如下:
![]()

路由配置

views不能添加括号,添加括号之后就是讲函数的结果引用过来了,两者完全不同
小练习


代码如下:
urls.py
from django.contrib import admin
from django.urls import path
# . 表示当目录下
from . import views
urlpatterns = {
path('admin/', admin.site.urls),
# http://127.0.0.1:8000/page/2003
path('page/2003', views.page_2003_view),
path('',views.page_k),
path('page/1',views.page_1),
path('page/2',views.page_2),
}
views.py
from django.http import HttpResponse
def page_2003_view(request):
html = "这是我的第一个页面
"
return HttpResponse(html)
def page_k(request):
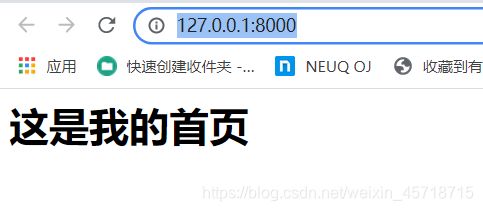
html = "这是我的首页
"
return HttpResponse(html)
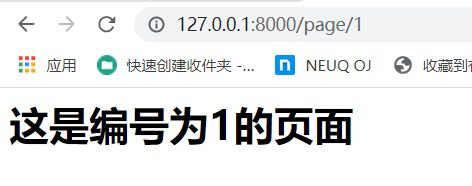
def page_1(request):
html = "这是编号为1的页面
"
return HttpResponse(html)
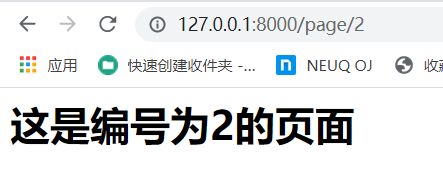
def page_2(request):
html = "这是编号为2的页面
"
return HttpResponse(html)
当你的老板抽风的时候:

怎么解决呢?
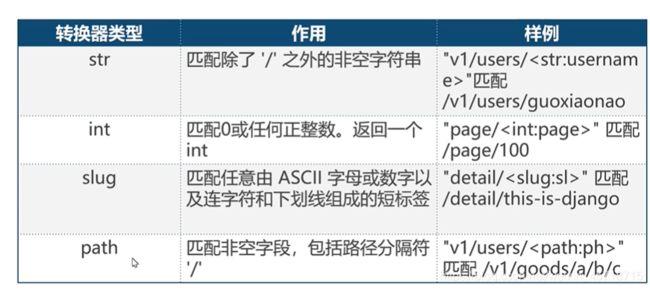
path转换器

转换器类型及作用:
然后来解决你老板的问题,访问100的网页:
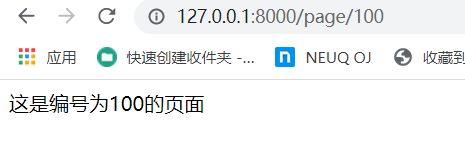
代码修改如下:
views.py
def page_view(request, pg):
html = f"这是编号为{str(pg)}的页面"
return HttpResponse(html)
urls.py
path('page/' , views.page_view)
这里说一下path的匹配顺序,这里面的匹配顺序是从上到下以此匹配的,
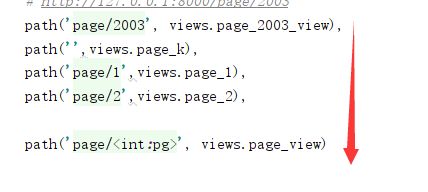
就算后面有对应的匹配项,也是按照前面已经匹配成功的执行。
小练习

练习结果如下:
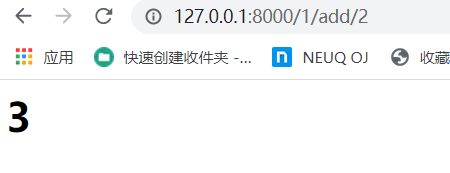
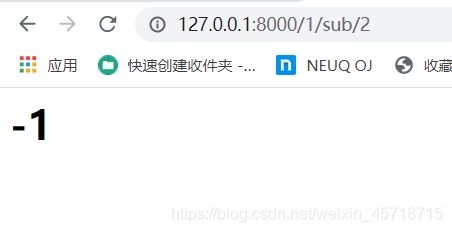
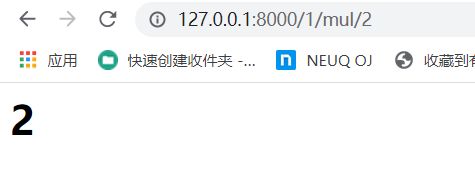
代码修改如下:
views.py
def reckon(request, pg1, st, pg2):
if st == 'add':
k = pg1 + pg2
elif st == 'sub':
k = pg1 - pg2
elif st == 'mul':
k = pg1 * pg2
else:
k = '错误!'
html = f'{str(k)}
'
return HttpResponse(html)
urls.py
path('//' , views.reckon),
re_path()
场景假设,假设你的老板告诉你,说你做的这个太强大了,咱们公司免费的只能计算两位数的结果,去修改吧。
这时候我们的path解释器就很难完成了。re_path就来了。


解释一下这个正则表达式:
^ 代表开头
& 代表结束
P 代表正则匹配
代表我们给他命名为x
\d 匹配数字
{1,2} 匹配1-2位
\w+ 匹配字符串
最终实现:
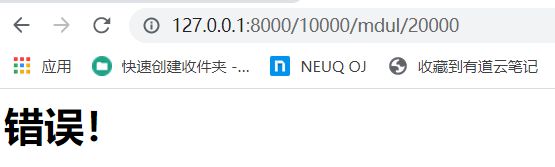
代码修改如下:
views.py
from django.http import HttpResponse
def page_2003_view(request):
html = "这是我的第一个页面
"
return HttpResponse(html)
def page_k(request):
html = "这是我的首页
"
return HttpResponse(html)
def page_1(request):
html = "这是编号为1的页面
"
return HttpResponse(html)
def page_2(request):
html = "这是编号为2的页面
"
return HttpResponse(html)
def page_view(request, pg):
html = f"这是编号为{str(pg)}的页面"
return HttpResponse(html)
def reckon(request, pg1, st, pg2):
if st == 'add':
k = pg1 + pg2
elif st == 'sub':
k = pg1 - pg2
elif st == 'mul':
k = pg1 * pg2
else:
k = '错误!'
html = f'{str(k)}
'
return HttpResponse(html)
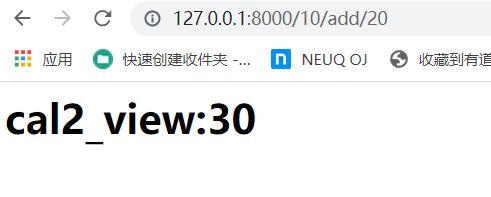
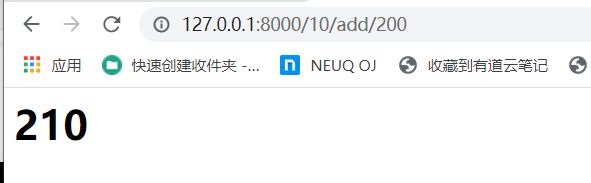
def cal2_view(request,x,op,y):
if op == 'add':
k = int(x) + int(y)
elif op == 'sub':
k = int(x) - int(y)
elif op == 'mul':
k = int(x) * int(y)
else:
k = '错误!'
html = f'cal2_view:{str(k)}
'
return HttpResponse(html)
urls.py
"""untitled1 URL Configuration
The `urlpatterns` list routes URLs to views. For more information please see:
https://docs.djangoproject.com/en/2.2/topics/http/urls/
Examples:
Function views
1. Add an import: from my_app import views
2. Add a URL to urlpatterns: path('', views.home, name='home')
Class-based views
1. Add an import: from other_app.views import Home
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
Including another URLconf
1. Import the include() function: from django.urls import include, path
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
"""
from django.contrib import admin
from django.urls import path, re_path
# . 表示当目录下
from . import views
urlpatterns = {
path('admin/', admin.site.urls),
# http://127.0.0.1:8000/page/2003
path('page/2003', views.page_2003_view),
path('', views.page_k),
path('page/1', views.page_1),
path('page/2', views.page_2),
path('page/' , views.page_view),
re_path(r'^(?P\d{1,2})/(?P\w+)/(?P\d{1,2})$' , views.cal2_view),
path('//' , views.reckon),
}
练习

运行结果:
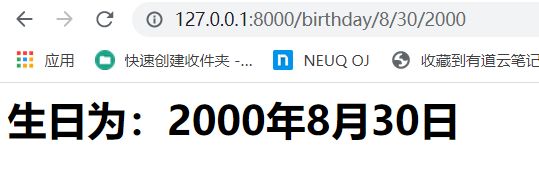
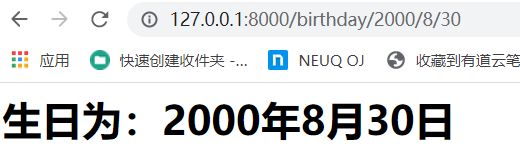
代码修改如下:
views.py
def birthday_one(request, x, y, z):
html = f"生日为:{x}年{y}月{z}日
"
return HttpResponse(html)
def birthday_two(request, x, y, z):
html = f"生日为:{x}年{y}月{z}日
"
return HttpResponse(html)
urls.py
re_path(r'^birthday/(?P\d{4})/(?P\d{1,2})/(?P\d{1,2})$' ,views.birthday_one),
re_path(r'^birthday/(?P\d{1,2})/(?P\d{1,2})/(?P\d{4})$' ,views.birthday_two),
注意共同部分birthday填写到^后
小结
两种匹配方式,当十分严格时使用re_path,一般的匹配使用path即可,re_path书写格式注意,注意正则表达式的写法。
请求和响应
Django主要做的是网页,而请求和响应是网页十分重要的一个东西。
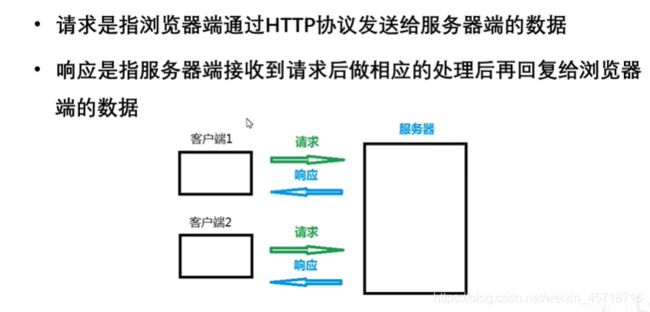
请求
请求样例如下:
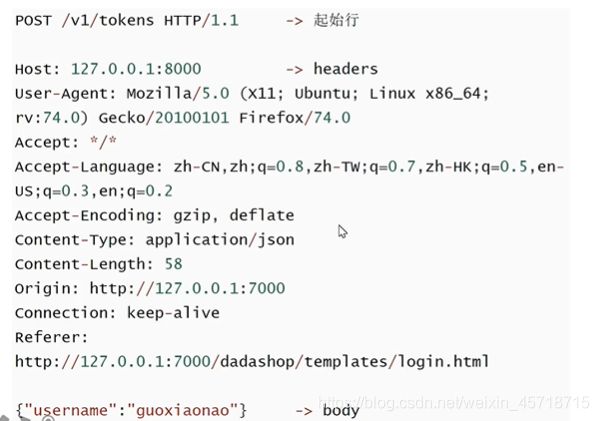
请求方式



大部分时候使用get和post请求。
Django中的请求

请求的属性:


测试method:
代码修改如下:
urls.py
path('test_request',views.test_request),
views.py
print('path info is', request.path_info)
print('method is ', request.method)
return HttpResponse('test qeruest ok')
浏览器运行结果如下:
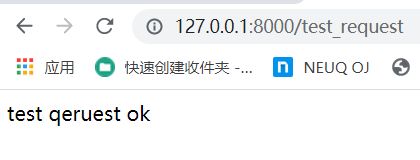
pycharm运行结果如下:

获取了我们访问的路由地址和请求方式。
GET和POST,是获取我们访问地址的查询字符串,测试如下:
views.py修改如下:
print('querystring is ',request.GET)
网页运行结果如下:
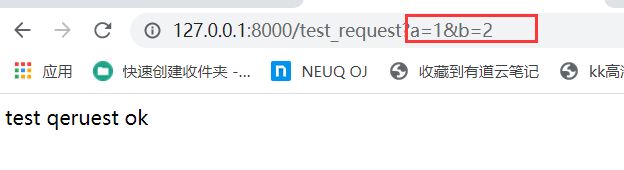
pycharm运行结果如下:

响应
响应样例:
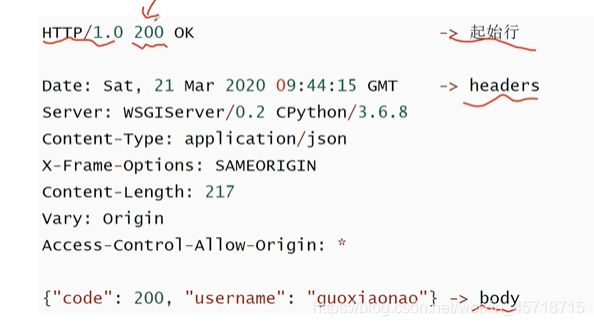
响应状态码

状态码的分类:

构造函数格式:

常用的Content-Type:

HTTPResponse子类:
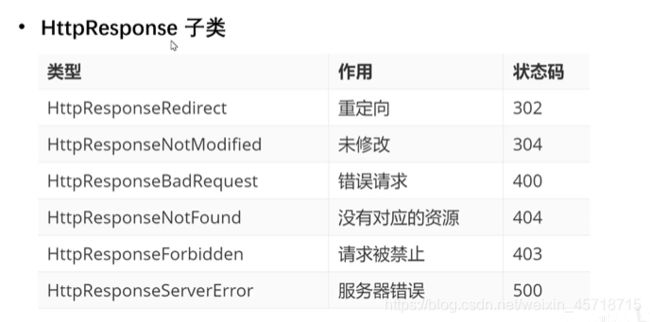
HttpResponseRedirect使用测试:
修改views.py文件:
def test_request(request):
print('path info is', request.path_info)
print('method is ', request.method)
print('querystring is ',request.GET)
# return HttpResponse('test qeruest ok')
return HttpResponseRedirect('/page/1')
在浏览器中访问如下地址:
http://127.0.0.1:8000/test_request
得到如下结果:
结果表示原网页被重定向了。
GET和POST请求

def test_get_post(request):
if request.method == 'GET':
pass
elif request.method == 'POST':
pass
else:
pass
return HttpResponse('--test get post is ok--')
GET处理



测试如下:
修改代码:
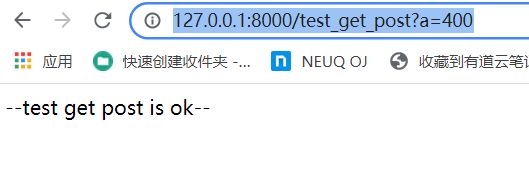
views.py
def test_get_post(request):
if request.method == 'GET':
print(request.GET['a'])
print(request.GET.get('c', 'no c'))
pass
elif request.method == 'POST':
pass
else:
pass
return HttpResponse('--test get post is ok--')
urls.py
path('test_get_post',views.test_get_post),
浏览器地址访问:
http://127.0.0.1:8000/test_get_post?a=400
浏览器运行结果如下:
pycharm运行结果如下:

由于传递的参数中不包含c,所以查询c时会补充我们设置的默认值no c。
当我们把a去除以后:
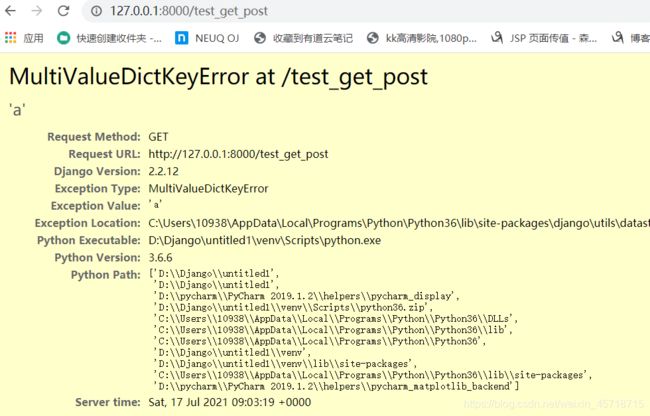
request.GET比较暴力,在不确定的情况下使用request.GET.get比较合适。
当我们提交多个信息并且有重复的值时,例如:
http://127.0.0.1:8000/test_get_post?a=400&a=100&a=500
这时会发现浏览器并没有报错,
当我们直接用GET取值时会发现和地址中的值有所不同:
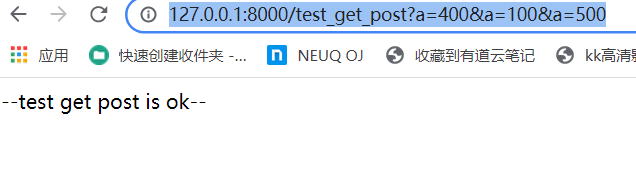
print(request.GET)

当我们只调用a时:
print(request.GET['a'])
运行结果如下:

此时我们只能得到最后一个值,这并不是我们要的结果,所以就需要使用getlist,
def test_get_post(request):
if request.method == 'GET':
print(request.GET)
print(request.GET['a'])
print(request.GET.getlist('a'))
print(request.GET.get('c', 'no c'))
pass
elif request.method == 'POST':
pass
else:
pass
return HttpResponse('--test get post is ok--')
http://127.0.0.1:8000/test_get_post?a=400&a=100&a=500
运行结果如下

思考

POST处理

服务端接收参数:


测试一下,定义一个全局变量:
POST_FROM = '''
'''
修改方法:
def test_get_post(request):
if request.method == 'GET':
print(request.GET)
print(request.GET['a'])
print(request.GET.getlist('a'))
print(request.GET.get('c', 'no c'))
return HttpResponse(POST_FROM)
pass
elif request.method == 'POST':
print('uname is',request.POST['uname'])
return HttpResponse('post is ok')
pass
else:
pass
return HttpResponse('--test get post is ok--')
直接刷新页面,然后就会出现我们定义好的页面。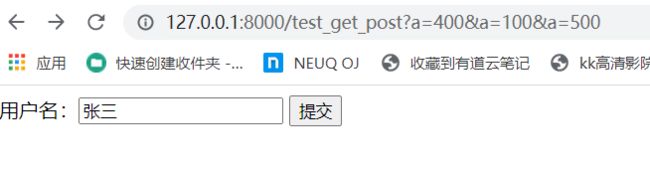
然后点击提交,
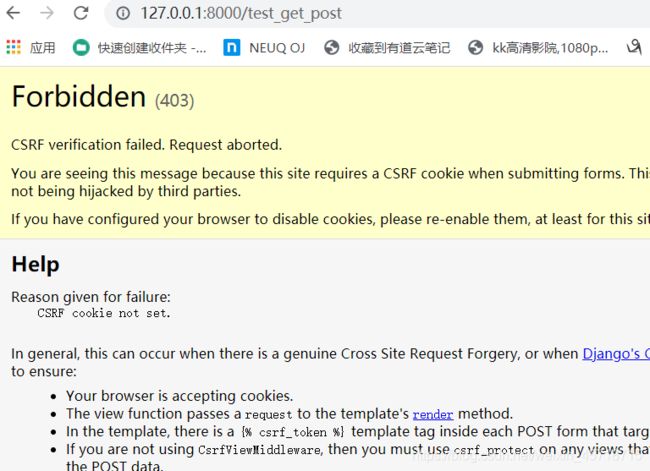
就会报错,报错原因就是那一行红字,需要取消csrf。
取消csrf

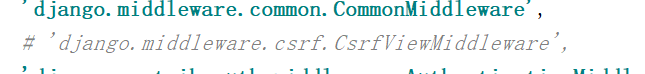
再提交,
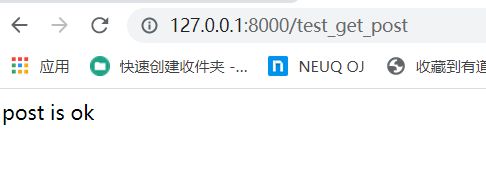
成功,pycharm运行结果如下:
![]()
小结

Django设计模式及模板层
MVC
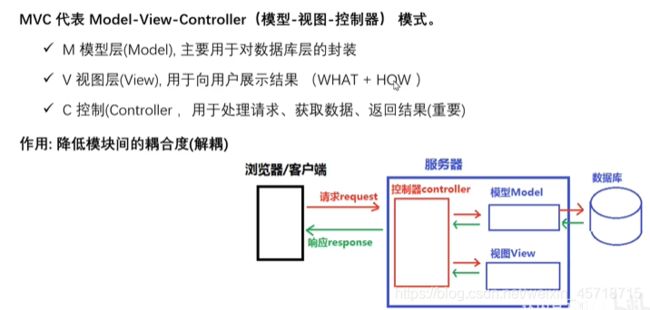
MTV
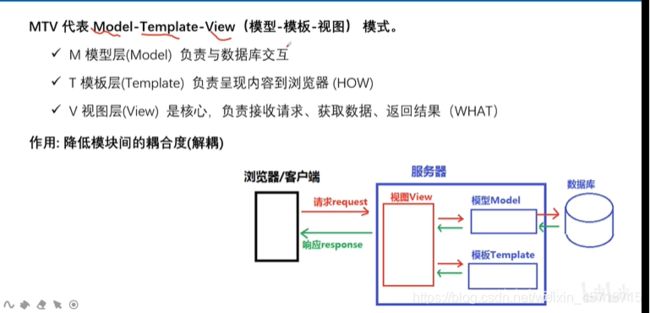
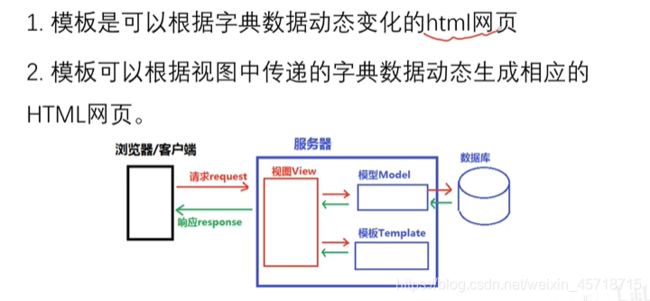
模板层1
什么是模板?
模板配置:


模板的加载方式:
方式一

加载模板测试:
修改文件:
views.py
def test_html(request):
from django.template import loader
t = loader.get_template('test_html.html')
html = t.render()
return HttpResponse(html)
urls.py
path('test_html',views.test_html)
创建HTML文件test_html.html
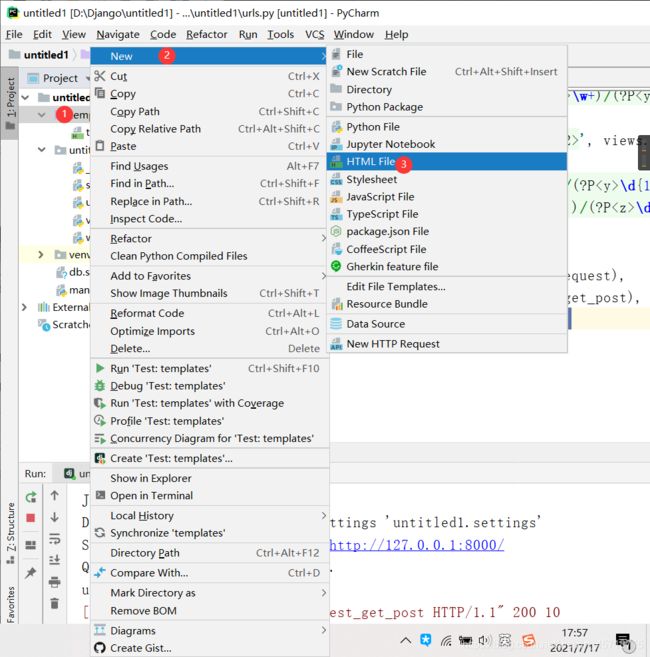
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h3>我是模板层的</h3>
</body>
</html>
网页访问以下地址:
http://127.0.0.1:8000/test_html
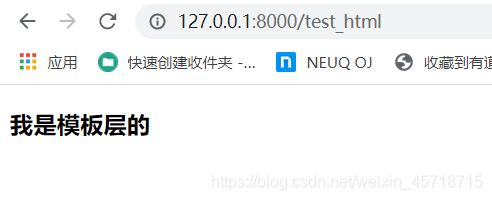
模板层加载成功。
方式二

字典数据可有可无
修改代码如下:
views.py
def test_html(request):
# 方案一
# from django.template import loader
#
# t = loader.get_template('test_html.html')
# html = t.render()
# return HttpResponse(html)
# 方案二
from django.shortcuts import render
return render(request,'test_html.html')
运行结果如图所示:

视图层与模板层之间的交互
动手操作如下:
views.py
def test_html(request):
# 方案一
# from django.template import loader
#
# t = loader.get_template('test_html.html')
# html = t.render()
# return HttpResponse(html)
# 方案二
from django.shortcuts import render
dic = {'username':'zhangsan','age':18}
return render(request,'test_html.html',dic)
test_html.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h3>{{ username }}是模板层的</h3>
</body>
</html>
运行结果如下:
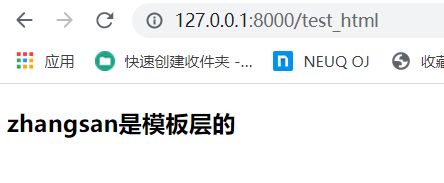
小结
MTV的框架模式,即模型M,视图V和模版T,MTV是将MVC中的V拆成了T和V,并且弱化了C成了主流文件。
模板层2
变量
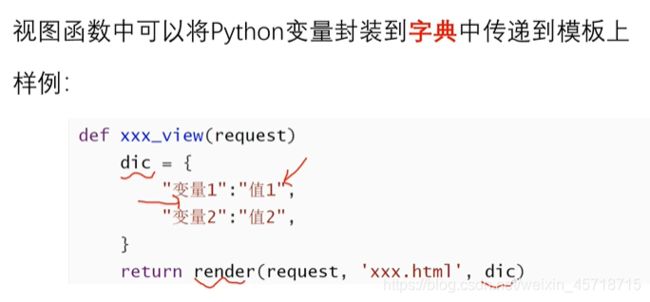

模板中使用变量语法:
 各种变量方法使用测试:
各种变量方法使用测试:
views.py
def test_html_param(request):
dic = {}
dic['int'] = 88
dic['str'] = 'zhangsan'
dic['lst'] = ['Tom', 'Jack', 'Lily']
dic['dict'] = {'a': 9, 'b': 8}
dic['func'] = say_hi
dic['class_obj'] = Dog()
return render(request, 'test_html_param.html', dic)
def say_hi():
return 'hahha'
class Dog:
def say(self):
return 'wangwang'
urls.py
path('test_html_param',views.test_html_param),
test_html_param.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h3>int 是 {{ int }}</h3>
<h3>str 是 {{ str }}</h3>
<h3>lst 是 {{ lst }}</h3>
<h3>lst 是 {{ lst.0 }}</h3>
<h3>dict 是 {{ dict }}</h3>
<h3>dict['a'] 是 {{ dict.a }}</h3>
<h3>function 是 {{ func }}</h3>
<h3>class_obj 是 {{ class_obj.say }}</h3>
</body>
</html>
网页访问地址:
http://127.0.0.1:8000/test_html_param
运行结果如下:

模板中的标签

if标签


if的使用测试
views.py
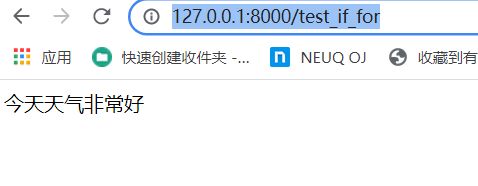
def test_if_for(request):
dic = {}
dic['x'] = 10
return render(request,'test_if_for.html',dic)
urls.py
path('test_if_for',views.test_if_for),
test_if_for.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试 if和for</title>
</head>
<body>
{% if x > 10 %}
今天天气很好
{% else %}
今天天气非常好
{% endif %}
</body>
</html>
浏览器访问地址:
http://127.0.0.1:8000/test_if_for
运行结果如图所示:
练习
相关代码如下:
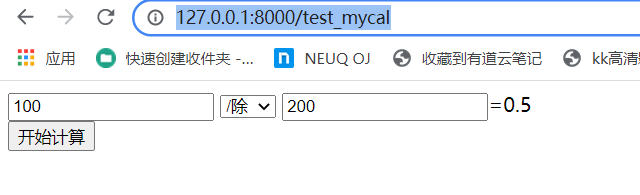
test_mycal.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="/test_mycal" method="post">
<input type="text" name="x" value="{{ x }}">
<select name="op">
<option value="add" {% if op == 'add'%}selected{% endif %}>+加</option>
<option value="sub" {% if op == 'sub'%}selected{% endif %}>-减</option>
<option value="mul" {% if op == 'mul'%}selected{% endif %}>*乘</option>
<option value="div" {% if op == 'div'%}selected{% endif %}>/除</option>
</select>
<input type="text" name="y" value="{{ y }}">=<span>{{ result }}</span>
<div>
<input type="submit" value="开始计算">
</div>
</form>
</body>
</html>
action="/test_mycal" 等号后面的 /test_mycal 是视图地址
views.py
def test_mycal(request):
if request.method == 'GET':
return render(request, 'test_mycal.html')
elif request.method == 'POST':
# 处理计算
x = int(request.POST['x'])
y = int(request.POST['y'])
op = request.POST['op']
if op == 'add':
result = x+y
elif op == 'sub':
result = x-y
elif op == 'mul':
result = x*y
elif op == 'div':
result = x/y
# locals 可以帮助我们自动将上面的参数生成字典
return render(request, 'test_mycal.html', locals())
此处注意locals这个方法,很好用
urls.py
path('test_mycal',views.test_mycal),
这里的 test_mycal 就是以前说的对应的视图地址
浏览器访问地址:
http://127.0.0.1:8000/test_mycal
运行结果如下:
for标签

内置变量:

测试如下:
views.py文件修改如下:
def test_if_for(request):
dic = {}
dic['x'] = 10
dic['lst'] = {'Tom', 'Jack', 'Lily'}
return render(request,'test_if_for.html',dic)
test_if_for.html文件修改如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试 if和fortitle>
head>
<body>
{% if x > 10 %}
今天天气很好
{% else %}
今天天气非常好
{% endif %}
<br>
{% for name in lst %}
{% if forloop.first %} $$$$${% endif %}
<p>{{ forloop.counter }} {{ name }}p>
{% if forloop.last %} ===={% endif %}
{% empty %}
当前无数据
{% endfor %}
body>
html>
body>
html>
浏览器访问地址:
http://127.0.0.1:8000/test_if_for
运行结果如下:

小结
注意网页中的地址,最好保持一致,防止自己弄混,标签语法一定要写结束符。
模板层-过滤器和继承
过滤器
什么是过滤器呢?

注意语法,是双大括号
常用过滤器:
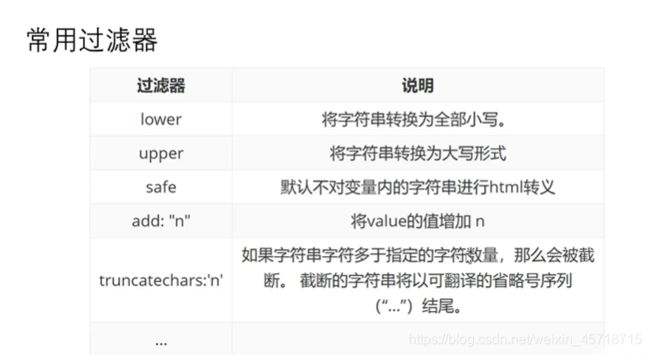
upper过滤器的使用
体验一下upper过滤器的使用,我们修改我们之前的test_html_param.html文件,修改文件如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<h3>int 是 {{ int }}h3>
<h3>str 是 {{ str|upper }}h3>
<h3>lst 是 {{ lst }}h3>
<h3>lst 是 {{ lst.0 }}h3>
<h3>dict 是 {{ dict }}h3>
<h3>dict['a'] 是 {{ dict.a }}h3>
<h3>function 是 {{ func }}h3>
<h3>class_obj 是 {{ class_obj.say }}h3>
body>
html>
运行结果如下:

upper过滤器将我们的zhangsan转换成了ZHANGSAN,全部为大写字母。
add过滤器的使用
同样修改我们的test_html_param.html文件,修改文件如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<h3>int 是 {{ int|add:'2' }}h3>
<h3>str 是 {{ str|upper }}h3>
<h3>lst 是 {{ lst }}h3>
<h3>lst 是 {{ lst.0 }}h3>
<h3>dict 是 {{ dict }}h3>
<h3>dict['a'] 是 {{ dict.a }}h3>
<h3>function 是 {{ func }}h3>
<h3>class_obj 是 {{ class_obj.say }}h3>
body>
html>
运行结果如下:

可以很清晰的看到,我们原来的值由88加到了90。
safe过滤器的使用
首先我们需要在我们的视图函数中修改我们的代码,修改代码如下:
def test_html_param(request):
dic = {}
dic['int'] = 88
dic['str'] = 'zhangsan'
dic['lst'] = ['Tom', 'Jack', 'Lily']
dic['dict'] = {'a': 9, 'b': 8}
dic['func'] = say_hi
dic['class_obj'] = Dog()
dic['script'] = ''
return render(request, 'test_html_param.html', dic)
我们为test_html_param添加了一个新的字段
dic[‘script’] = ‘’
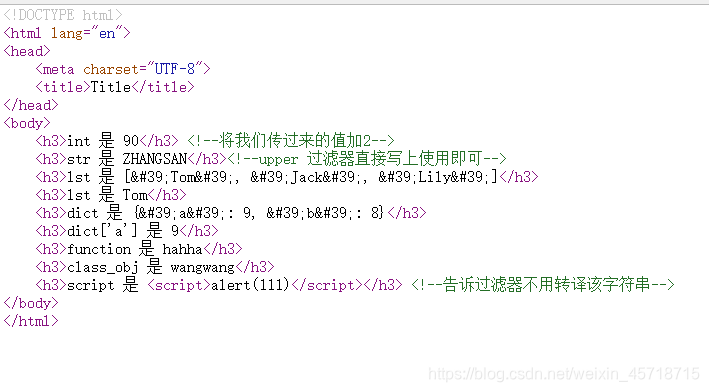
这很明显是一个html语句,然后在我们的test_html_param.html中添加新的语句,去显示我们传过来的值:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<h3>int 是 {{ int|add:'2' }}h3>
<h3>str 是 {{ str|upper }}h3>
<h3>lst 是 {{ lst }}h3>
<h3>lst 是 {{ lst.0 }}h3>
<h3>dict 是 {{ dict }}h3>
<h3>dict['a'] 是 {{ dict.a }}h3>
<h3>function 是 {{ func }}h3>
<h3>class_obj 是 {{ class_obj.say }}h3>
<h3>script 是 {{ script }}h3>
body>
html>
然后运行查看:
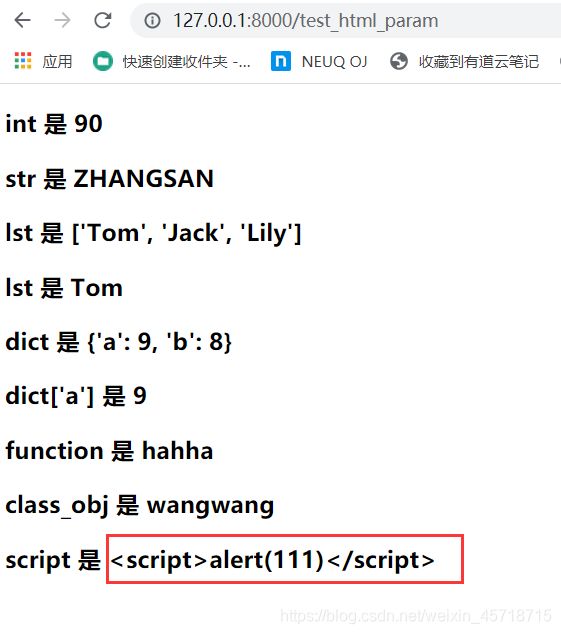
很明显Django这是把我们的html语句当做了字符串处理,我们右击我们的页面,查看我们的源代码:
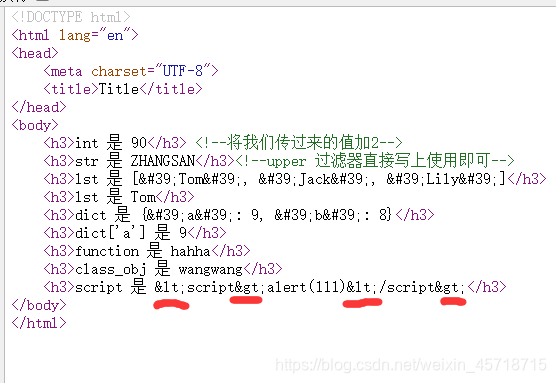
这些多的东西都是html的转译,Django默认开启了html的转译,当我们就想把他当成html时,我们可以使用我们的safe过滤器。
修改test_html_param.html文件如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<h3>int 是 {{ int|add:'2' }}h3>
<h3>str 是 {{ str|upper }}h3>
<h3>lst 是 {{ lst }}h3>
<h3>lst 是 {{ lst.0 }}h3>
<h3>dict 是 {{ dict }}h3>
<h3>dict['a'] 是 {{ dict.a }}h3>
<h3>function 是 {{ func }}h3>
<h3>class_obj 是 {{ class_obj.say }}h3>
<h3>script 是 {{ script|safe }}h3>
body>
html>
运行结果如下:
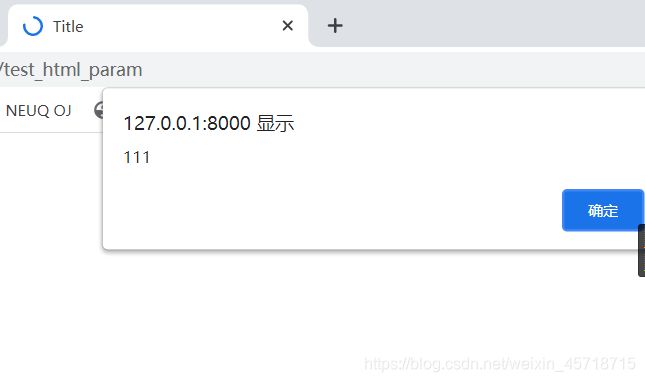

我们写的弹框显示出来了,后面的字符串显示也消失了,此时我们的网页源码变成了:
继承
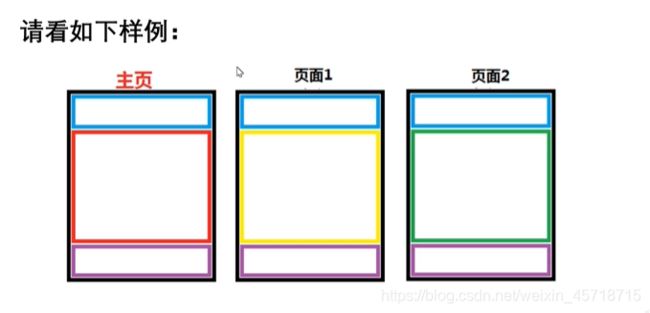
很多页面头和尾都是一样了,这就是继承常见的应用场景。举个例子:
我们虽然切换了页面,但是我们的首部是一样的。


关于继承的测试:
首先我们设计一个场景,我们有一个电视台,电视台网页上一共就有3个页面,主页、音乐频道和体育频道,其中呢三个页面内的头尾一样,只有里面的显示内容不一样,因此,我们可以使用我们的继承来实现这个逻辑,实现过程如下:
首先创建我们的主页,
base.html
<html lang="en">
<head>
<meta charset="UTF-8">
{% block mytitle %}
<title>主页title>
{% endblock %}
head>
<body>
<a href="/music_index">音乐频道a>
<a href="/sport_index">体育频道a>
<br>
{% block info %}
这是主页
{% endblock %}
<br>
<h3>有任何问题联系110h3>
body>
html>
解释一下上面的代码:我们让音乐频道和体育频道来继承我们的主页,前面说了头尾相同只是中间的部分不同,因此我们需要将不同的部分使用block包围:

主页编写完成以我们需要让我们的其他页面去继承我们的主页;
music.html
{% extends 'base.html' %}
{% block mytitle %}
<title>音乐频道title>
{% endblock %}
{% block info %}
欢迎来到音乐频道
{% endblock %}
sport.html
{% extends 'base.html' %}
{% block mytitle %}
<title>体育频道title>
{% endblock %}
{% block info %}
欢迎来到体育频道
{% endblock %}
两个文件相同,首先要继承我们的主页,然后在使用 block 修改不同的地方。

最后为我们的页面添加视图函数:
views.py
def base_view(request):
return render(request, 'base.html')
def music_view(request):
return render(request, 'music.html')
def sport_view(request):
return render(request, 'sport.html')
再添加相关的路由:
urls.py
path('bse_index',views.base_view),
path('music_index',views.music_view),
path('sport_index',views.sport_view),
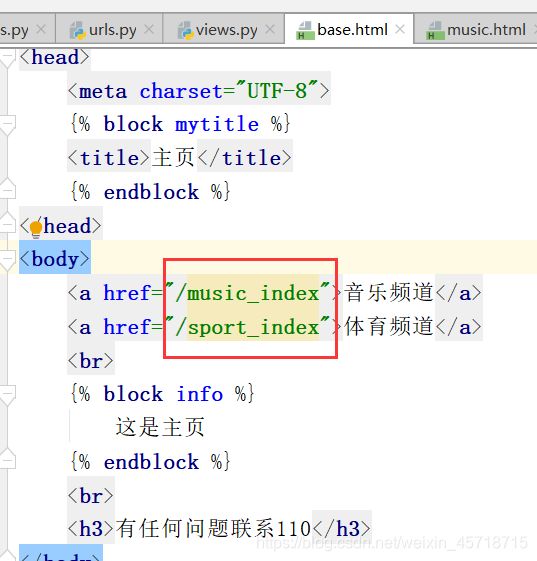
后两个路由的定义是需要相互对应的,运行结果如下图所示:
主页:
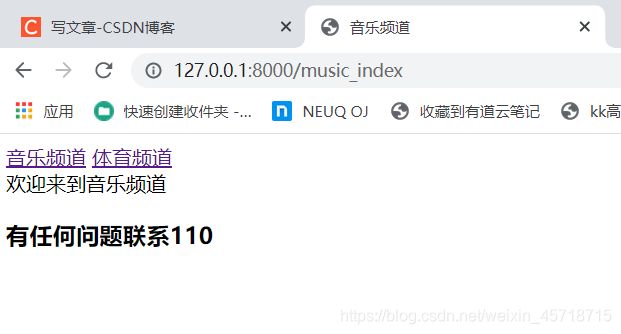
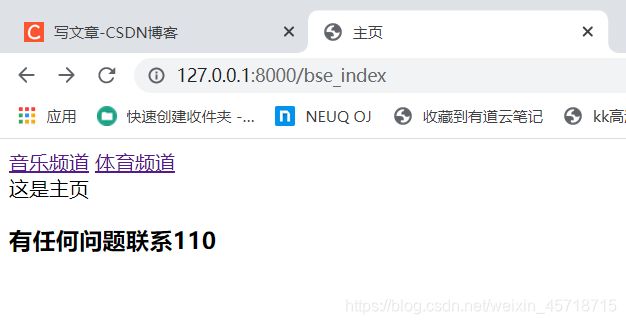 音乐频道:
音乐频道:
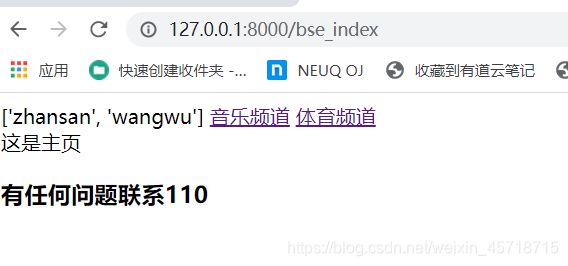
体育频道:
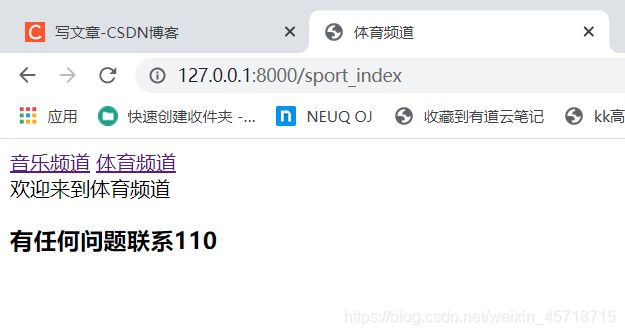
可以看到只有我们想让他变的地方变了。
注意:

传的变量无法继承
例子如下:
修改我们的视图层函数:
def base_view(request):
lst = ['zhansan','wangwu']
return render(request, 'base.html',locals())
再修改我们的base.html的公共部分:
<html lang="en">
<head>
<meta charset="UTF-8">
{% block mytitle %}
<title>主页title>
{% endblock %}
head>
<body>
{{ lst }}
<a href="/music_index">音乐频道a>
<a href="/sport_index">体育频道a>
<br>
{% block info %}
这是主页
{% endblock %}
<br>
<h3>有任何问题联系110h3>
body>
html>
运行结果如下:
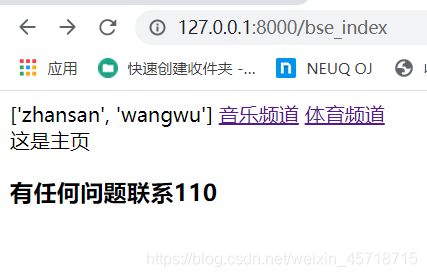
主页显示正常,
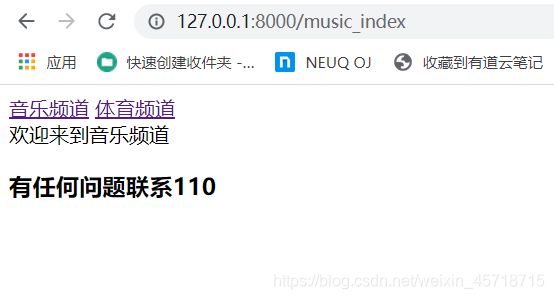
音乐频道无显示,
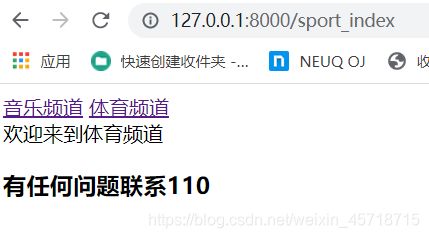
体育频道也没有显示。
小结

url反向解析
再谈URL
代码中的url:

url书写规范


代码测试:
创建视图函数:
def test_url(request):
return render(request,'test_url.html')
def test_url_result(request):
return HttpResponse('test url is ok')
创建跳转的页面:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<a href="http://127.0.0.1:8000/test_url_result">绝对地址a>
<a href="/test_url_result">带‘/’的相对地址a>
<a href="test_url_result">不带‘/’的相对地址a>
body>
html>
创建路由:
path('test/url', views.test_url),
path('test_url_result', views.test_url_result),
地址栏访问:
http://127.0.0.1:8000/test/url
观察页面解析的地址:



前两个地址的由来就不做过多的解释了,最后一个看官方的解析文档,当没有‘/’的时候,先对当前的地址栏的地址进行解析:
从后往前找‘/得到如下的地址
127.0.0.1:8000/test/ + url
然后会将前半部分地址和我们给的不带‘/’的地址进行拼接,得到如下的地址:
127.0.0.1:8000/test/test_url_result
但是我们并没有配置该路由地址,所以点击会出错!
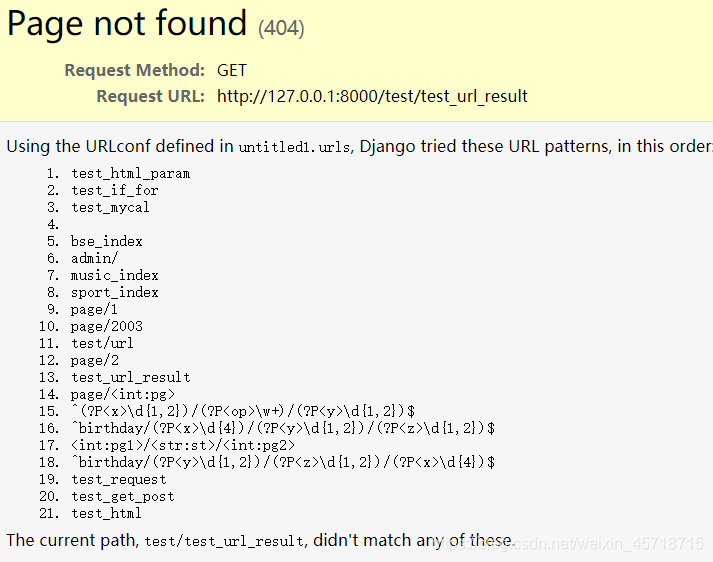
建议使用带 ‘/’
url反向解析


代码测试:
修改代码如下:
urls.py
path('test_url_result', views.test_url_result, name='tr'),
起了一个别名叫做tr。
test_url.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<a href="http://127.0.0.1:8000/test_url_result">绝对地址a>
<a href="/test_url_result">带‘/’的相对地址a>
<a href="test_url_result">不带‘/’的相对地址a>
<br>
<a href="{% url 'tr' %}">url反向解析版本a>
body>
html>
这时候浏览器访问会报错!报错原因是这个:
‘set’ object is not reversible
解决方法:
把{ }换成[ ]就行了,详细原因不详,修正后运行结果如下:

直接根据我们起的别名找到了地址。
当有值传递的时候,修改代码如下:
启用path转化器修改urls.py
path('test_url_result/' , views.test_url_result, name='tr'),
修改test_url.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<a href="http://127.0.0.1:8000/test_url_result">绝对地址a>
<a href="/test_url_result">带‘/’的相对地址a>
<a href="test_url_result">不带‘/’的相对地址a>
<br>
<a href="{% url 'tr' '100' %}">url反向解析版本a>
body>
html>
修改 views.py中的test_url_result函数:
def test_url_result(request,age):
return HttpResponse(f'test url is ok ,age is {age}')
访问网址:
http://127.0.0.1:8000/test/url
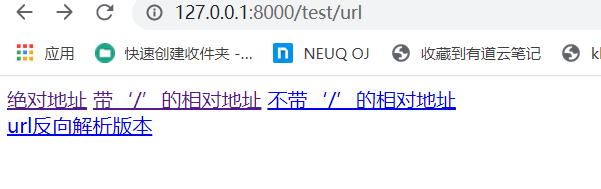

可以看到我们在模板层的参数值作为了参数进行传递,访问结果为:
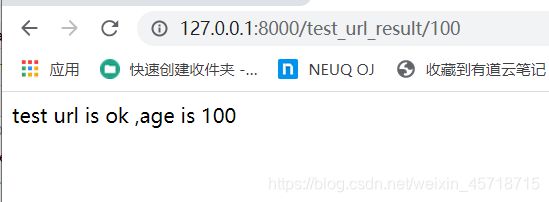
访问和传值均成功。
可以看出使用反向解析可以很好帮我们动态修改地址,当我们修改urls里面的地址时,也不会影响我们的访问,例子如下:
修改urls.py:
path('test_urls_result/' , views.test_url_result, name='tr'),
这里把url修改成了urls
我们再去刷新页面查看:

反向解析的地址会跟着变,而没有修改过的其他地址呢?

并没有改变,从这点可以看出,反向解析可以动态的修改地址,保证了地址的准确性。
在视图中使用反向解析:

代码体验:
修改路由:
path('bse_index', views.base_view, name='bse_index'),
这个是之前的那个首页,直接加了个别名
修改视图函数:
def test_url_result(request,age):
# 302跳转
from django.urls import reverse
url = reverse('bse_index')
return HttpResponseRedirect(url)
# return HttpResponse(f'test url is ok ,age is {age}')
这里使用的是302跳转
浏览器访问地址:
http://127.0.0.1:8000/test/url

跳转完成,此处的反向解析url是在视图函数中进行的,和之前的略有不同。
小结:
注意那个{ }和[ ]的报错。
静态文件
静态文件配置

指定路径:

代码练习:
新的项目目录结构:
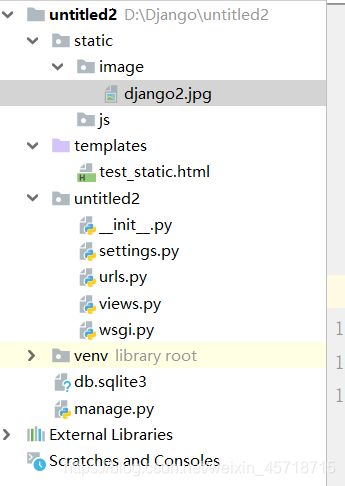
修改setings.py:
注释掉csrf
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
# 'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
添加DIRS路径
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')]
,
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
修改语言和时区
LANGUAGE_CODE = 'zh-Hans'
TIME_ZONE = 'Asia/Shanghai'
添加静态文件目录
STATIC_URL = '/static/' # 这个是默认生成的,显示图片用的,前面有解释
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'), # 这个后面的名字和你创建的名字统一
)
创建views.py文件并添加视图函数:
from django.shortcuts import render
def test_static(request):
return render(request, 'test_static.html')
创建test_static.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试静态文件title>
head>
<body>
<img src="http://127.0.0.1:8000/static/image/django2.jpg" width="200px" height=" 200px ">
<img src="/static/image/django2.jpg" width="200px" height="200px">
body>
html>
创建访问路由:
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('test_static', views.test_static),
]
浏览器地址访问:
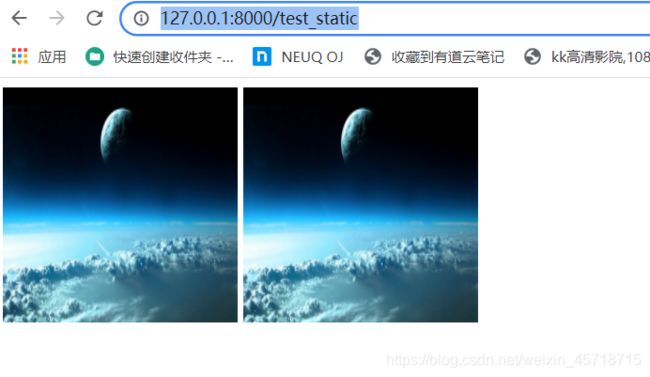
http://127.0.0.1:8000/test_static
运行结果如下:
在模板中访问静态文件

注意这个路径
修改代码如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试静态文件title>
head>
<body>
<img src="http://127.0.0.1:8000/static/image/django2.jpg" width="200px" height=" 200px ">
<img src="/static/image/django2.jpg" width="200px" height="200px">
{% load static %}
<img src="{% static 'image/django2.jpg' %}" width="200px" height="200px">
body>
html>
网页运行结果如下:
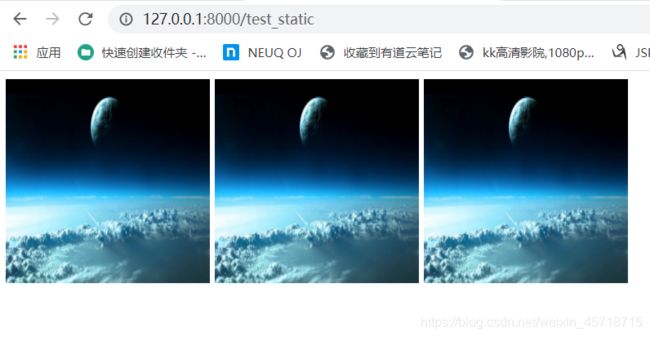
推荐使用第三种方式
当我们无意之间修改了strings文件中的 STATIC_URL = ‘/static/’ 时,比如修改成了 STATIC_URL = ‘/statics/’ 那此时如果使用的前两种方式,直接报错。
小结
注意静态文件的创建和配置文件的修改,静态文件访问建议使用第三种
Django应用及分布式路由
这个好像挺重要的
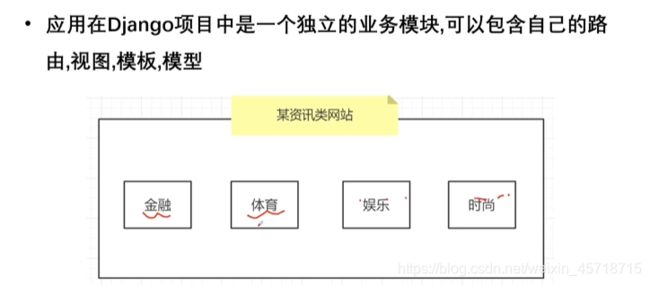
应用
什么是应用
创建应用
strings.py配置样例

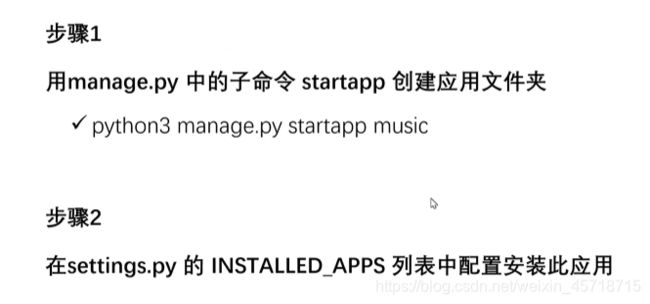
开始创建一个应用。
使用以下命令进行相关的创建:
python manage.py startapp music
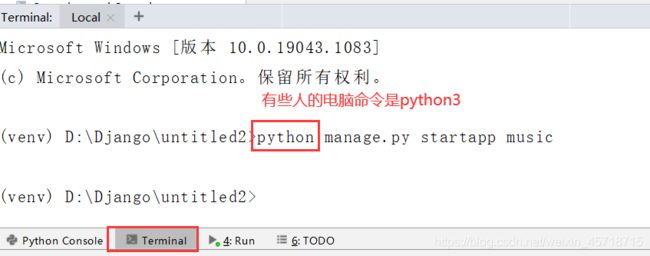
此时我们的项目目录会发生变化:
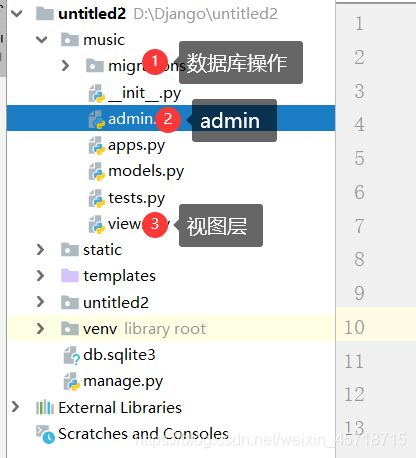
我们创建的一个应用其实就类似于一个小的MTV。
修改settings.py文件:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'music',
]
最后一行添加我们创建的应用
分布式路由
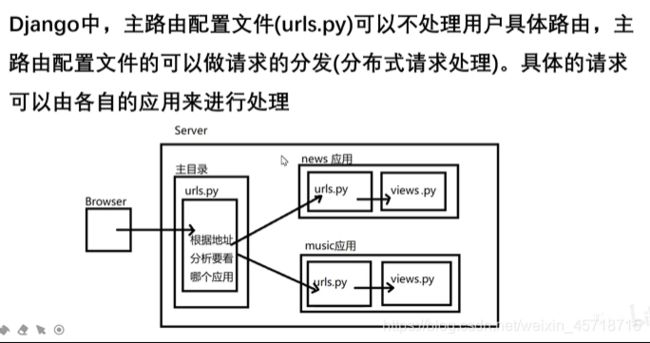
配置分布式路由


代码测试:
为项目中的路由创建一个新的转发地址:
from django.contrib import admin
from django.urls import path, include
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('test_static', views.test_static),
# http://127.0.0.1:8000/music/index
path('music/', include('music.urls')), # 转给music应用
]
为musci应用和粗昂艰难urls.py文件:
from django.urls import path
from . import views
urlpatterns = [
# http://127.0.0.1:8000/music/index
path('index',views.index_view),
]
在music的视图层创建新的视图函数:
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index_view(request):
return HttpResponse("这是音乐频道")
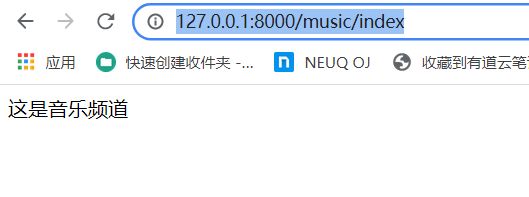
浏览器访问地址为:
http://127.0.0.1:8000/music/index
运行结果如下:
练习

解答过程:
首先创建这两个应用:
python manage.py startapp sport
python manage.py startapp news

在项目的settings.py文件中“注册”一下两个应用:
'sport',
'news',

为两个文件创建自己的urls.py文件

在整个项目中的urls.py文件中添加这两个应用的转发:
# http://127.0.0.1:8000/sport/index
path('sport/', include('sport.urls')), # 转给sport应用
# http://127.0.0.1:8000/news/index
path('news/', include('news.urls')), # 转给news应用
修改我们的两个应用的中的urls.py文件:
from django.urls import path
from . import views
urlpatterns = [
# http://127.0.0.1:8000/sport/index
path('index', views.index_view),
]
from django.urls import path
from . import views
urlpatterns = [
# http://127.0.0.1:8000/news/index
path('index',views.index_view),
]
再为两个应用创建相关的视图函数:
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index_view(request):
return HttpResponse('这是新闻频道')
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index_view(request):
return HttpResponse("这是体育频道")
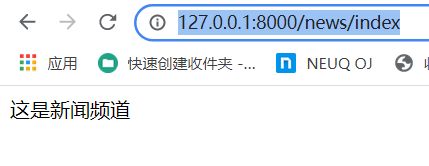
浏览器访问地址:
http://127.0.0.1:8000/news/index
http://127.0.0.1:8000/sport/index
运行结果如下:
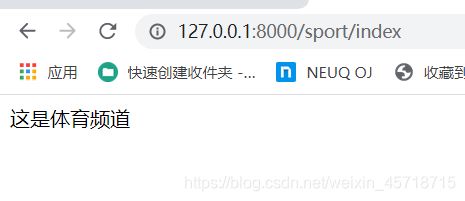
课堂测试完成。
应用下的模板

测试代码:
在news文件夹下创建templates文件夹并在templates文件夹中创建一个模板文件index.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>新闻频道title>
head>
<body>
我是新闻首页
body>
html>
修改news中的视图函数,使用render跳转到模板,
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index_view(request):
#return HttpResponse('这是新闻频道')
return render(request,'index.html')
浏览器访问地址:
http://127.0.0.1:8000/news/index
运行结果如图所示:
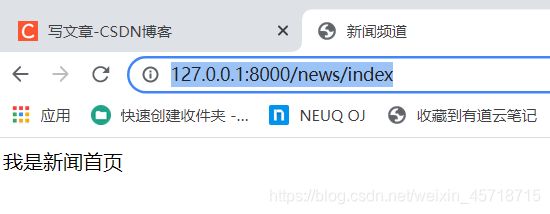
如果我们项目的templates中也创建一个index.html:
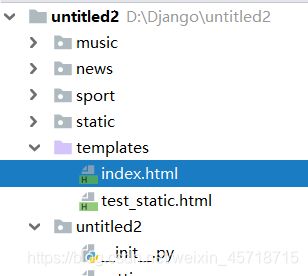
<html lang="en">
<head>
<meta charset="UTF-8">
<title>外层title>
head>
<body>
我是外层的index
body>
html>
此时再去访问之前的网址:
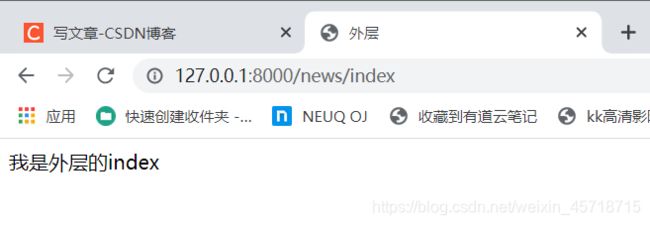
所以,当外层出现和引用内的模板重复时,会使用外层的模板。
当我们其他应用中也有index.html文件时。
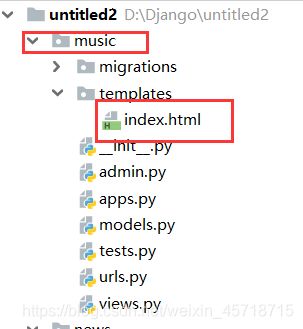
我们将项目外层的index.html修改名称:
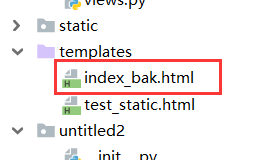
我们再去访问之前的地址:
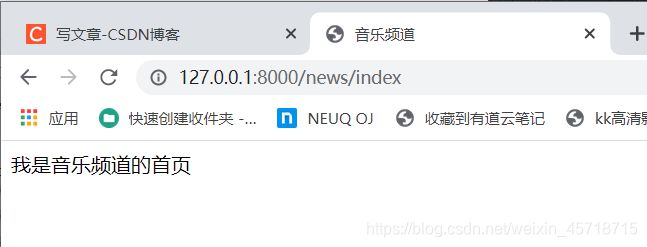
出现了一个我们意想不到的错误,这个情况产生的原因在我们的settings文件中。

具体原因在下方。
查找规则

解决方法:
在应用下的templates文件夹下创建一个和应用名称相同的文件夹,将之前的index.html移动到该文件夹下:
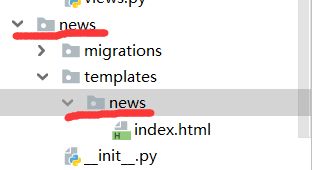
再去修改我们的视图函数:
from django.shortcuts import render
from django.http import HttpResponse
# Create your views here.
def index_view(request):
#return HttpResponse('这是新闻频道')
return render(request,'news/index.html')
访问之前的地址:
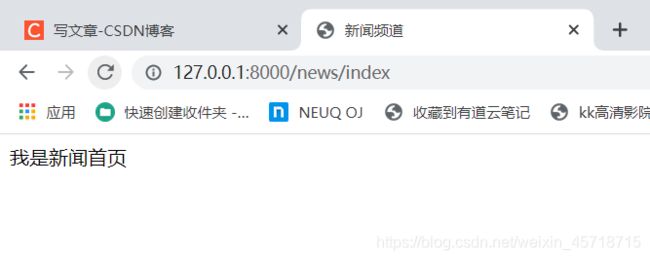
访问成功。
小结
应用创建只有之后需要进行去settings中进行注册,为了解决主路由工作量过大问题,使用了分布式路由,分布式路由的方式需要注意。
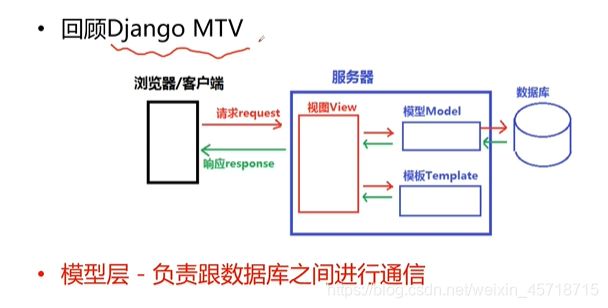
模型层及ORM介绍
模型层
Django配置mysql

pycharm直接安装即可。


在数据库中创建一个数据库,最好以当前项目名命名,修改settings中的配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 链接的是谁mysql 直接改最后的名字就行
'NAME': 'mysite3', # 数据库的名字
'USER': 'root', # 链接用的用户名
'PASSWORD': '123456789', # 数据库密码
'HOST': '127.0.0.1', # 数据库地址
'PORT': '3306', # 访问数据库的端口号
}
}

可以根据自己数据库引擎进行更换,具体的配置可以百度一下。
什么是模型

一个类对应着一张表
ORM框架

ORM框架优点:

ORM框架缺点:

ORM映射图
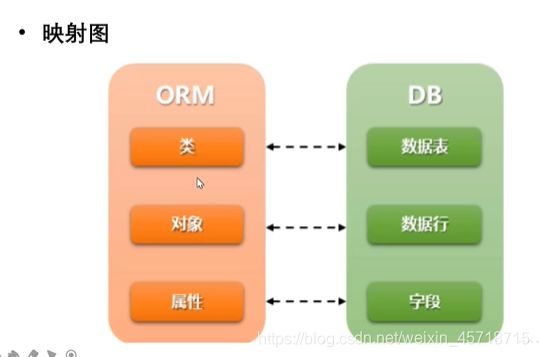
示例


代码如下:
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField("书名", max_length=50, default='')
price = models.DecimalField('定价', max_digits=7, decimal_places=2,
default=0.0)
每一个类代表一张表,每一个属性代表一个字段
但是此时数据库中并没有创建这个表。

python manage.py makemigrations

python manage.py migrate
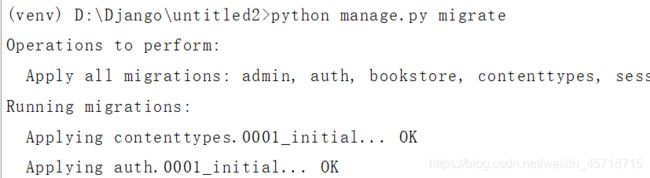
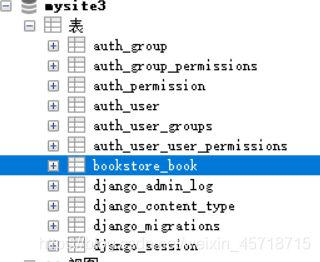
创建完成。
回忆创建过程

小结
注意创建的过程,先改到mysql,然后在应用的models.py文件中写创建数据库的各个字段,再去命令窗口生成一个迁移文件,使用的命令是:
python manage.py makemigrations
迁移文件创建成功之后,使用命令在数据库中创建相关的表格,使用的命令是:
python manage.py migrate
创建出来的表的命名规则:应用名_类名(类名的首个字母转换成小写)
ORM-基础字段及选项
ORM映射图

创建流程


代码如下:
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField("书名", max_length=50, default='')
price = models.DecimalField('定价', max_digits=7, decimal_places=2,
default=0.0)
info = models.CharField("信息", max_length=100, default='')
然后执行之前的迁移命令和创建命令。
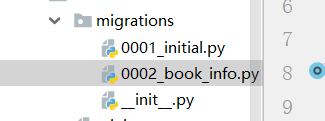
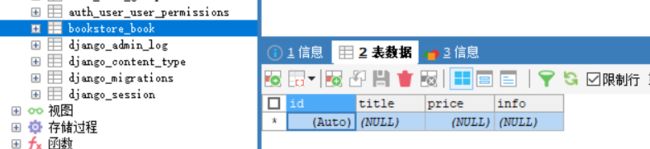
字段类型



DateTimeField的可用参数和DateField相同,且也是三选一




练习

代码如下:
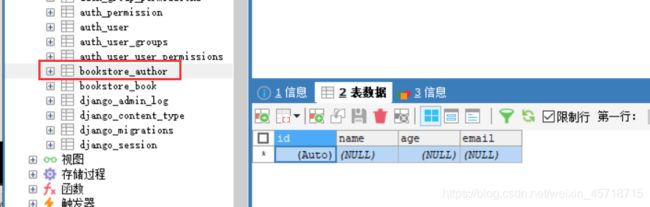
class Author(models.Model):
name = models.CharField("名字", max_length=11,default="")
age = models.IntegerField("年龄", default="")
email = models.EmailField("邮箱", default="")
python manage.py makemigrations
python manage.py migrate
小结
多练习创建模型类的流程,字段类型。
ORM-基础字段及选项2
模型类定义

模型类-字段选项





模型类-Meta类
控制表的属性

代码测试:
修改我们之前Book类:
class Book(models.Model):
title = models.CharField("书名", max_length=50, default='')
price = models.DecimalField('定价', max_digits=7, decimal_places=2,
default=0.0)
info = models.CharField("描述", max_length=100, default='')
class Meta:
db_table = 'book'
使用命令创建迁移文件:
python manage.py makemigrations
再执行:
python manage.py migrate
数据库查看结果:
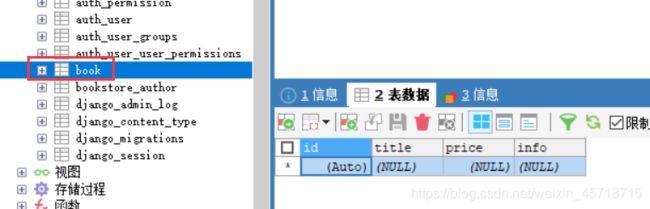
表名已经被修改完成。
课堂练习

测试代码:
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField("书名", max_length=50, default='',unique=True)
pub = models.CharField("出版社", max_length=100,default='')
price = models.DecimalField('定价', max_digits=7, decimal_places=2,
default=0.0)
market_price = models.DecimalField("零售价", max_digits=7,decimal_places=2,default=0.0)
info = models.CharField("描述", max_length=100, default='')
class Meta:
db_table = 'book'
class Author(models.Model):
name = models.CharField("名字", max_length=11)
age = models.IntegerField("年龄", default=1)
email = models.EmailField("邮箱", null=True)
Django创建表格是默认为非空,即默认null=False
运行指令:
python manage.py makemigrations
python manage.py migrate
运行结果:
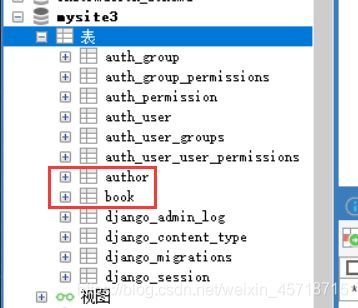
小结
注意字段类型,和修改表名。
ORM-基本操作-创建数据
常见问题汇总



问题2:


ORM-创建数据




Django Shell

代码测试:
输入指令:
python manage.py shell
进入shell界面,输入以下指令:
from bookstore.models import Book
b1 = Book.objects.create(title=‘Python’,pub=‘清华大学出版社’,price=20,market_price=25)
然后去数据库中查看数据是否插入成功:
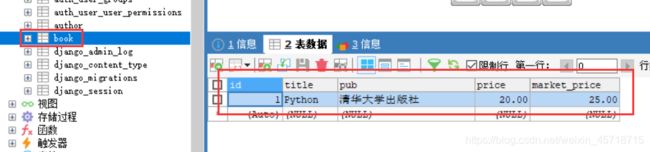
数据插入成功。
方法二测试:
使用指令:
b2 = Book(title=‘Django’,pub=‘清华大学出版社’,price=70,market_price=75)
使用完该指令以后并不会将数据成功插入,

此时需要另一条指令将数据插入到数据库中:
b2.save()
此时才能插入成功:

练习
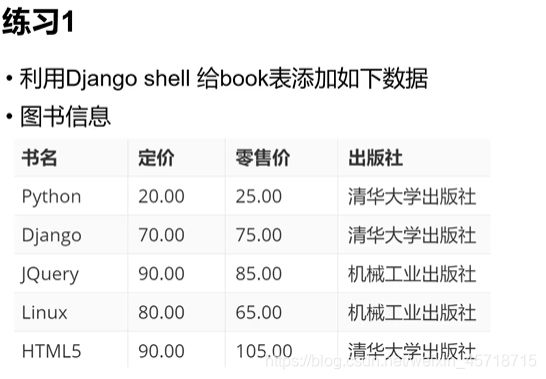
练习1代码:
>>> b2 = Book(title='JQuery',pub='机械工业出版社',price=90,market_price=85)
>>> b2.save()
>>> b2 = Book(title='Linux',pub='机械工业出版社',price=80,market_price=65)
>>> b2.save()
>>> b2 = Book(title='HTML5',pub='清华大学出版社',price=90,market_price=105)
>>> b2.save()
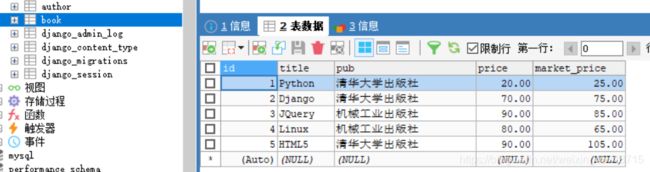
运行结果:
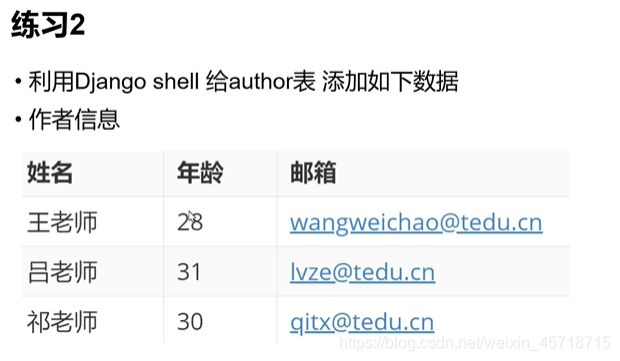
练习2代码
>>> from bookstore.models import Author
>>> a1 = Author(name = '王老师', age = '28', email = '[email protected]')
>>> a1.save()
>>> a1 = Author(name = '吕老师', age = '31', email = '[email protected]')
>>> a1.save()
>>> a1 = Author(name = '祁老师', age = '30', email = '[email protected]')
>>> a1.save()
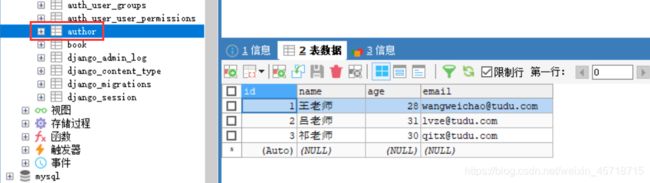
运行结果:
小结

ORM-查询1

all

代码测试:
>>> from bookstore.models import Book
>>> a1 = Book.objects.all()
>>> a1
<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <B
ook: Book object (4)>, <Book: Book object (5)>]>
输出其中的一列进行查看:
>>> for book in a1:
... print(book.title)
...
Python
Django
JQuery
Linux
HTML5
>>>
这样不太好看,怎么优化呢?
代码测试
为我们的Book类添加一个新的方式:
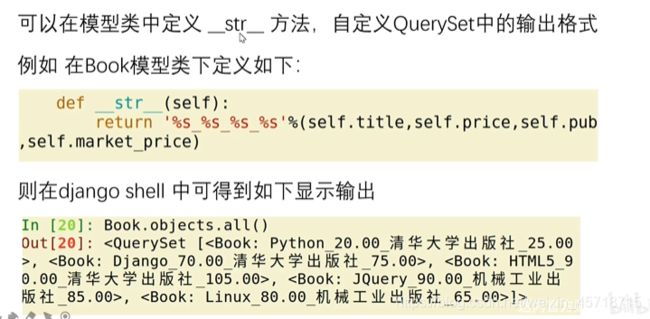
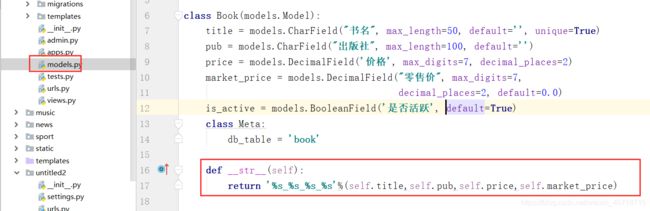
def __str__(self):
return '%s_%s_%s_%s'%(self.title,self.pub,self.price,self.market_price)
然后重启我们的shell,一定要重启。
>>> exit
Use exit() or Ctrl-Z plus Return to exit
>>> ^Z
now exiting InteractiveConsole...
然后再重新进入shell:
(venv) D:\Django\untitled2>python manage.py shell
Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
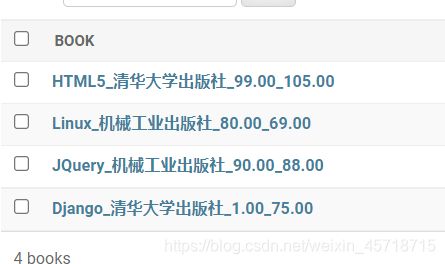
>>> from bookstore.models import Book
>>> a1 = Book.objects.all()
>>> a1
<QuerySet [<Book: Python_清华大学出版社_20.00_25.00>, <Book: Django_清华大学出版社_70.00_75.00>, <Book: JQuery_机械工业出版社_90.00_85.00>, <Book:
Linux_机械工业出版社_80.00_65.00>, <Book: HTML5_清华大学出版社_90.00_105.00>]>
>>>
values

代码测试
>>> a2 = Book.objects.values('title','pub')
>>> a2
<QuerySet [{'title': 'Python', 'pub': '清华大学出版社'}, {'title': 'Django', 'pub': '清
华大学出版社'}, {'title': 'JQuery', 'pub': '机械工业出版社'}, {'title': 'Linux', 'pub':
'机械工业出版社'}, {'title': 'HTML5', 'pub': '清华大学出版社'}]>
>>>
当我们只想取结果中的一列的时候:
>>> for book in a2:
... print(book['title'])
...
Python
Django
JQuery
Linux
HTML5
>>>
values_list

代码测试
>>> a3 = Book.objects.values_list('title','pub')
>>> a3
<QuerySet [('Python', '清华大学出版社'), ('Django', '清华大学出版社'), ('JQuery', '机械
工业出版社'), ('Linux', '机械工业出版社'), ('HTML5', '清华大学出版社')]>
>>> for book in a3:
... print(book[0])
...
Python
Django
JQuery
Linux
HTML5
>>>
注意返回值是元组
order_by

代码测试
>>> a4 = Book.objects.order_by('-price')
>>> a4
<QuerySet [<Book: JQuery_机械工业出版社_90.00_85.00>, <Book: HTML5_清华大学出版社_90.00_
105.00>, <Book: Linux_机械工业出版社_80.00_65.00>, <Book: Django_清华大学出版社_70.00_75
.00>, <Book: Python_清华大学出版社_20.00_25.00>]>
不仅如此,还能联合排序:
>>> a5 = Book.objects.values('title').order_by('-price')
>>> a5
<QuerySet [{'title': 'JQuery'}, {'title': 'HTML5'}, {'title': 'Linux'}, {'title': 'Djang
o'}, {'title': 'Python'}]>
当我们想查看查询的sql语句时:
>>> print(a5.query)
SELECT `book`.`title` FROM `book` ORDER BY `book`.`price` DESC
练习
完成代码
首先需要去创建bookstore应用的路由:
在项目中为该应用添加路由转发:
# http://127.0.0.1:8000/bookstore/all_book
path('bookstore/', include('bookstore.urls')), # 转给bookstore应用
在bookstore中再创建视图函数:
from django.shortcuts import render
from .models import Book
# Create your views here.
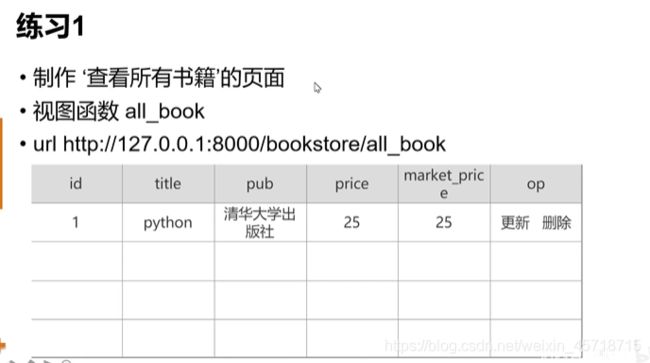
def all_book(request):
all_book = Book.objects.all()
return render(request, 'bookstore/all_book.html', locals())
在应用中创建如下的路径文件:
all_book.html代码如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>书籍title>
head>
<body>
<table border="1">
<tr>
<th>idth>
<th>titleth>
<th>pubth>
<th>priceth>
<th>market_priceth>
<th>opth>
tr>
{% for book in all_book %}
<tr>
<td>{{ book.id}}td>
<td>{{ book.title}}td>
<td>{{ book.pub }}td>
<td>{{ book.price }}td>
<td>{{ book.market_price }}td>
<td>
<a href="">更新a>
<a href="">删除a>
td>
tr>
{% endfor %}
table>
body>
html>
浏览器访问地址:
http://127.0.0.1:8000/bookstore/all_book
运行结果如下:

朴实无华的页面出来了。
小结

ORM-查询操作2
条件查询
filter


测试代码:
>>> b1 = Book.objects.filter(pub='中信出版社')
>>> b1
<QuerySet []>
>>> b1 = Book.objects.filter(pub='清华大学出版社')
>>> b1
<QuerySet [<Book: Python_清华大学出版社_20.00_25.00>, <Book: Django_清华大学出版社_70.00
_75.00>, <Book: HTML5_清华大学出版社_90.00_105.00>]>
>>> print(b1.query)
SELECT `book`.`id`, `book`.`title`, `book`.`pub`, `book`.`price`, `book`.`market_price`
FROM `book` WHERE `book`.`pub` = 清华大学出版社
>>>
>>> b1 = Book.objects.filter(pub='清华大学出版社',title='Python2')
>>> b1
<QuerySet []>
>>> print(b1.query)
SELECT `book`.`id`, `book`.`title`, `book`.`pub`, `book`.`price`, `book`.`market_price`
FROM `book` WHERE (`book`.`pub` = 清华大学出版社 AND `book`.`title` = Python2)
>>>
exclude

get

代码测试:
>>> b2 = Book.objects.get(pub='清华大学出版社')
Traceback (most recent call last):
File "" , line 1, in <module>
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\site-packages\django\db
\models\manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\site-packages\django\db
\models\query.py", line 412, in get
(self.model._meta.object_name, num)
bookstore.models.Book.MultipleObjectsReturned: get() returned more than one Book -- it re
turned 3!
>>>
由于我们数据库中查询出的数据不止一条,所以发生了查询错误。
>>> b2 = Book.objects.get(pub='中信出版社')
Traceback (most recent call last):
File "" , line 1, in <module>
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\site-packages\django\db
\models\manager.py", line 82, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "C:\Users\10938\AppData\Local\Programs\Python\Python36\lib\site-packages\django\db
\models\query.py", line 408, in get
self.model._meta.object_name
bookstore.models.Book.DoesNotExist: Book matching query does not exist.
>>>
此时我们查询的数据不存在,所以会报错
>>> b2 = Book.objects.get(id=1)
>>> b2
<Book: Python_清华大学出版社_20.00_25.00>
此时根据主键查,查出一条数据所以不会出错。
在代码中查询时需要使用try包围
查询谓词
__exact

__contains、__startswith、__endswith

__gt、__gte、__lt、__lte

__in、__range


体验
>>> b3 = Book.objects.filter(id__gt=3)
>>> b3
<QuerySet [<Book: Linux_机械工业出版社_80.00_65.00>, <Book: HTML5_清华大学出版社_90.00_10
5.00>]>
>>> print(b3.query)
SELECT `book`.`id`, `book`.`title`, `book`.`pub`, `book`.`price`, `book`.`market_price` F
ROM `book` WHERE `book`.`id` > 3
>>>
小结
用get查询的时候必须要使用try包围;查询谓词的构成:类属性__谓词(查询id>3的:id__gt=3)
ORM-更新操作
修改单个数据

代码测试:
>>> b2 = Book.objects.get(id=1)
>>> b2.price = 22
>>> b2.save()
>>> b2 = Book.objects.get(id=1)
>>> b2
<Book: Python_清华大学出版社_22.00_25.00>
>>>
修改批量数据

代码测试
>>> b2 = Book.objects.filter(pub='清华大学出版社')
>>> b2.update(price=1)
3
>>> b2 = Book.objects.filter(pub='清华大学出版社')
>>> b2
<QuerySet [<Book: Python_清华大学出版社_1.00_25.00>, <Book: Django_清华大学出版社_1.00_75
.00>, <Book: HTML5_清华大学出版社_1.00_105.00>]>
>>>
练习

练习代码如下:
在应用的路由中创建一个更新用的路由地址:
# http://127.0.0.1:8000/bookstore/update/{{ book.id }}
path('update/' ,views.book_update)
创建一个修改页面:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>书籍信息更新title>
head>
<body>
<table>
<form action="/bookstore/update/{{ update_book.id }}" method="post">
<tr>
<td>
书名:
td>
<td>
<input type="text" name="title" value="{{ update_book.title }}" disabled="disabled">
td>
tr>
<tr>
<td>
出版社:
td>
<td>
<input type="text" name="pub" value="{{ update_book.pub }}" disabled="disabled">
td>
tr>
<tr>
<td>
进价:
td>
<td>
<input type="number" name="price" value="{{ update_book.price }}">
td>
tr>
<tr>
<td>
零售价:
td>
<td>
<input type="number" name="market_price" value="{{ update_book.market_price }}">
td>
tr>
<tr>
<td colspan="2" align="center">
<input type="submit" value="更新" style="width:180px;height:30px" />
td>
tr>
form>
table>
body>
html>
编写更新的视图函数:
def book_update(request, id):
try:
update_book = Book.objects.get(id=id)
except Exception as e:
print('--update book error is %s' % (e))
HttpResponse("--This book is not existed")
if request.method == 'GET':
return render(request, 'bookstore/book_update.html', locals())
elif request.method == 'POST':
update_book.price = request.POST.get('price')
update_book.market_price = request.POST.get('market_price')
update_book.save()
return HttpResponseRedirect('/bookstore/all_book')
浏览器访问地址:
http://127.0.0.1:8000/bookstore/all_book
运行结果如下:
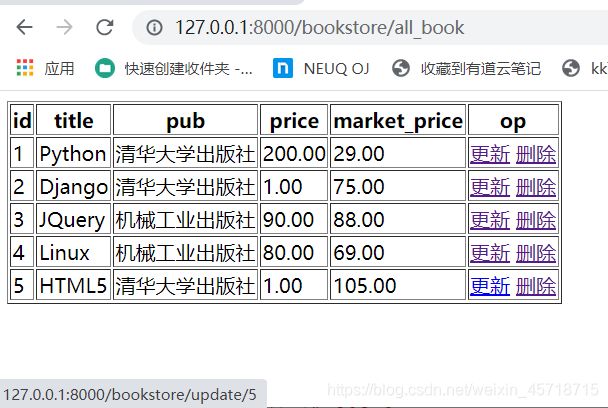
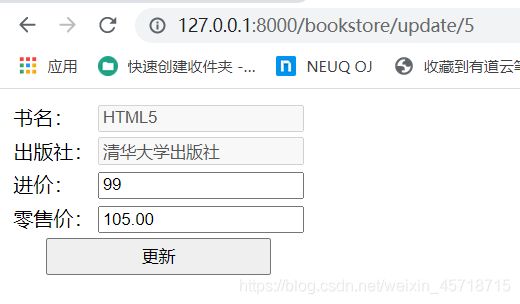
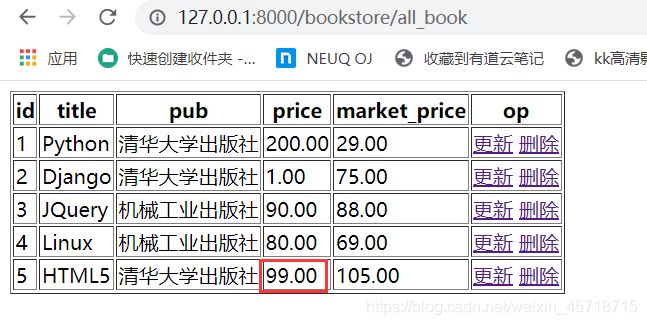
操作完成。
小结
使用get进行查询时一定要用try包围,熟练使用查询和更新操作。
ORM-删除操作
单个数据删除

批量删除

代码测试
>>> b1 = Book.objects.get(id = 1)
>>> b1.delete()
(1, {'bookstore.Book': 1})
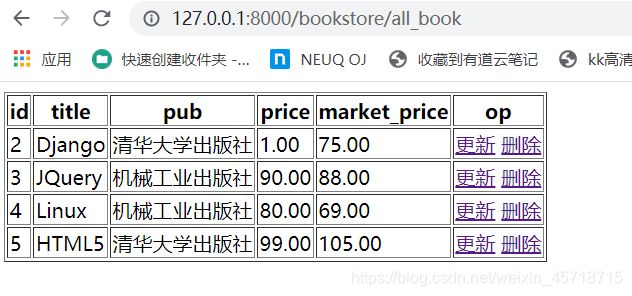
伪删除

练习

完成代码
在应用的路由器中添加跳转地址:
# http://127.0.0.1:8000/bookstore/delete?book_id=xx
path('delete',views.delete_book),
在视图中修改视图函数:
from django.shortcuts import render,HttpResponse,HttpResponseRedirect
from .models import Book
# Create your views here.
def all_book(request):
# all_book = Book.objects.all()
all_book = Book.objects.filter(is_active=True)
return render(request, 'bookstore/all_book.html', locals())
def book_update(request, id):
try:
update_book = Book.objects.get(id=id, is_active=True)
except Exception as e:
print('--update book error is %s' % (e))
HttpResponse("--This book is not existed")
if request.method == 'GET':
return render(request, 'bookstore/book_update.html', locals())
elif request.method == 'POST':
update_book.price = request.POST.get('price')
update_book.market_price = request.POST.get('market_price')
update_book.save()
return HttpResponseRedirect('/bookstore/all_book')
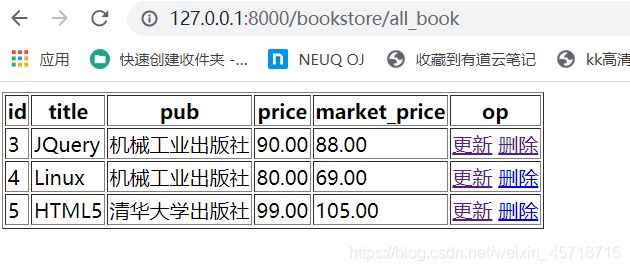
def delete_book(request):
#通过获取查询字符串 book_id 拿到要删除的book的id
book_id = request.GET.get('book_id')
if not book_id:
return HttpResponse('----请求异常')
try:
book = Book.objects.get(id = book_id,is_active=True)
except Exception as e:
print('---delete book get error %s ---'% (e))
return HttpResponse('---The book is error---')
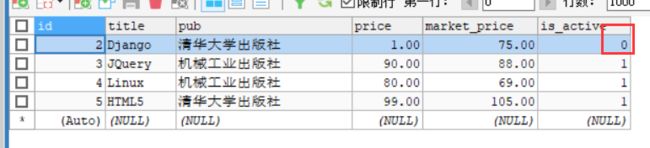
#将其is_active 改成False
book.is_active = False
book.save()
#302跳转至all_book
return HttpResponseRedirect('/bookstore/all_book')
pass
为页面添加跳转地址:
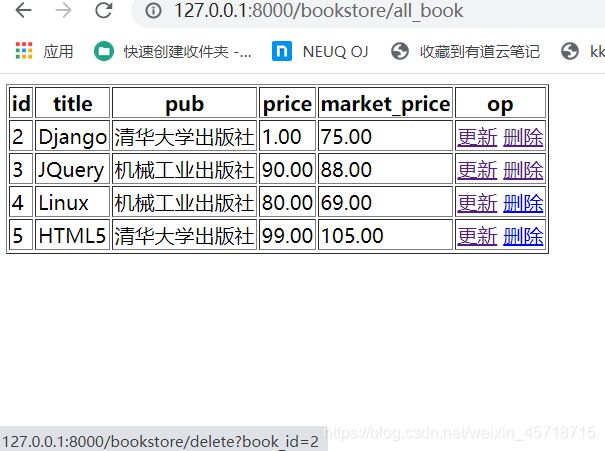
<a href="/bookstore/delete?book_id={{ book.id }}">删除a>
路由器访问地址:
http://127.0.0.1:8000/bookstore/all_book
运行结果如下:
小结
开发中使用伪删除比使用真正的删除会好很多。
F对象和Q对象
F对象
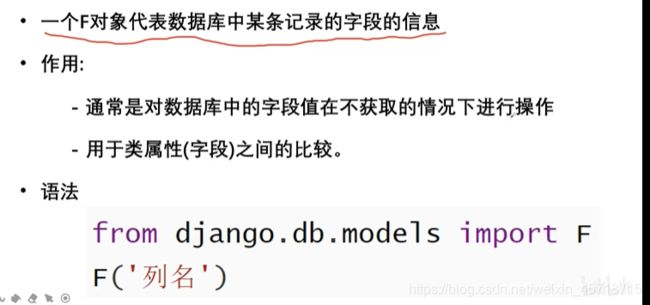


指令测试:
>>> from django.db.models import F
>>> Book.objects.filter(market_price__gt=F('price'))
<QuerySet [<Book: Django_清华大学出版社_1.00_75.00>, <Book: HTML5_清华大学出版社_99.00_10
5.00>]>
Q对象



指令测试:
>>> from django.db.models import Q
>>> Book.objects.filter(Q(market_price__gt=20)|Q(pub='清华大学出版社'))
<QuerySet [<Book: Django_清华大学出版社_1.00_75.00>, <Book: JQuery_机械工业出版社_90.00_8
8.00>, <Book: Linux_机械工业出版社_80.00_69.00>, <Book: HTML5_清华大学出版社_99.00_105.00
>]>
>>>
小结

聚合查询和原生数据库操作
聚合查询

整表聚合

指令测试:
>>> from django.db.models import Count
>>> Book.objects.aggregate(res=Count('id'))
{'res': 4}
>>>
分组聚合



代码测试:
>>> bs = Book.objects.values('pub')
>>> bs.annotate(res=Count('id'))
<QuerySet [{'pub': '清华大学出版社', 'res': 2}, {'pub': '机械工业出版社', 'res': 2}]>
>>>
该可以继续查询:
>>> bs.annotate(res=Count('id')).filter(res__gt=2)
<QuerySet []>
原生数据库操作
查询



危险性测试:
>>> s1 = Book.objects.raw('select * from book where id = %s'%('1 or 1=1'))
>>> s1
<RawQuerySet: select * from book where id = 1 or 1=1>
>>> for i in s1:
... print(i)
...
Django_清华大学出版社_1.00_75.00
JQuery_机械工业出版社_90.00_88.00
Linux_机械工业出版社_80.00_69.00
HTML5_清华大学出版社_99.00_105.00
>>>
这样用户可以非法的查询到我们数据库中的所有信息。
>>> s2 = Book.objects.raw('slect * from book where id = %s',['1 or 1=1'])
>>> for k in s2:
... print(k.title)
我运行会报错,视频能查出来,不知道为啥。
cursor
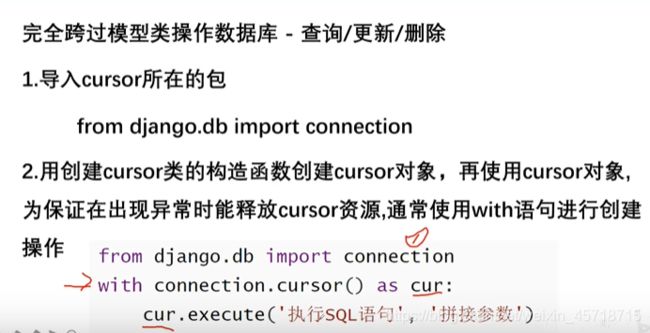

小结

不推荐使用原生SQL语句。
admin后台管理-1
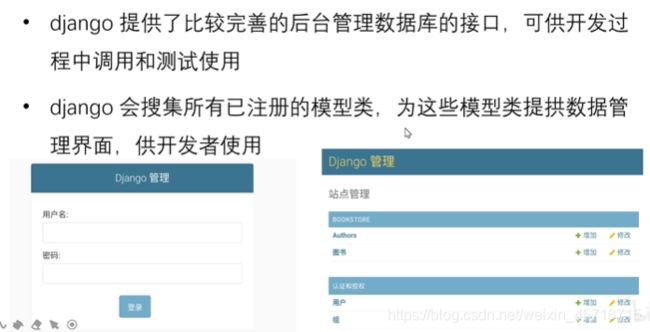
创建账号

(venv) D:\Django\untitled2>python manage.py createsuperuser
用户名 (leave blank to use '10938'): 用户名
电子邮件地址: 邮箱
Password:
Password (again):
Superuser created successfully.
访问地址:
http://127.0.0.1:8000/admin/
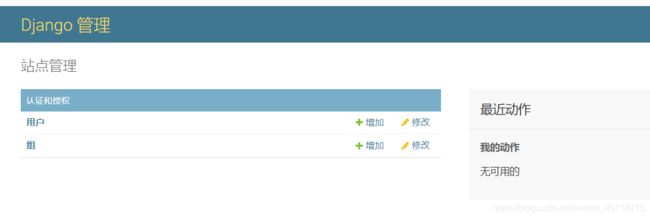
小结

admin后台管理-2
注册自定义模型类

代码测试:
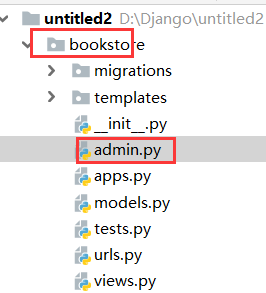
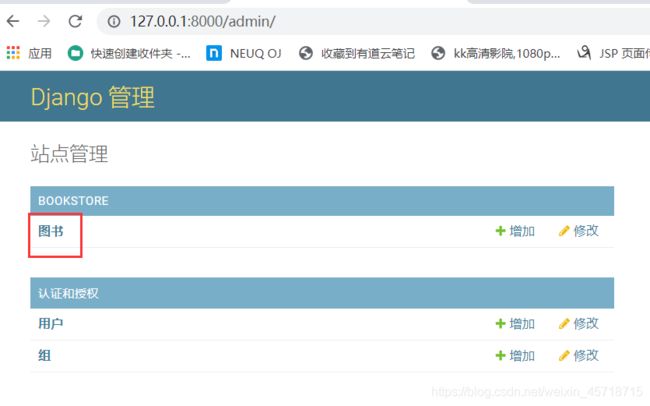
from django.contrib import admin
from .models import Book
# Register your models here.
admin.site.register(Book)
访问网址:
http://127.0.0.1:8000/admin/
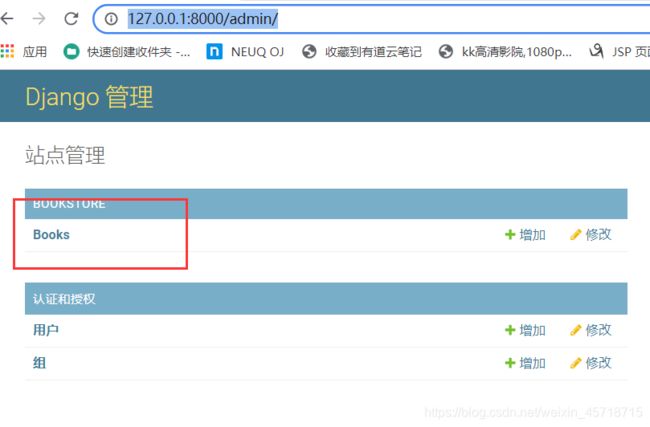
这里的显示格式和我们之前设置的相关:
模型管理类



修改代码如下:
修改admin.py
from django.contrib import admin
from .models import Book
# Register your models here.
class BookManager(admin.ModelAdmin):
list_display = ['id','title','pub','price']
admin.site.register(Book,BookManager)
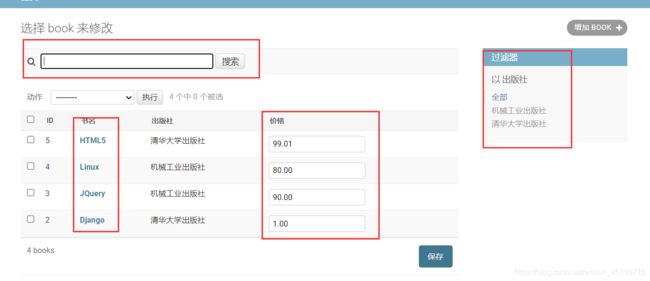
刷新网页:
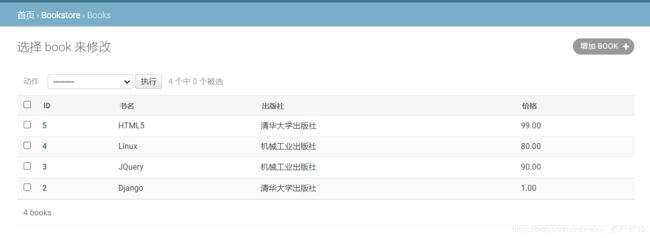
为什么系统会知道我们每一列的中文呢?
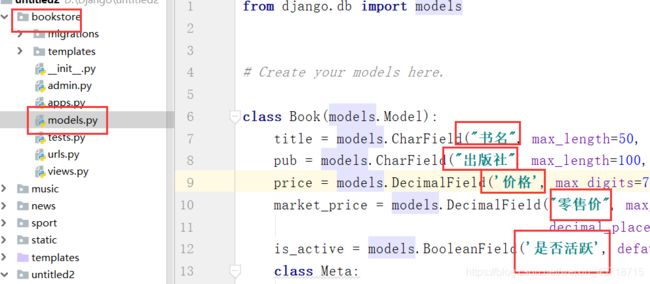
常用的模型类:
class BookManager(admin.ModelAdmin):
# 列表页显示那些字段的列
list_display = ['id','title','pub','price']
# 控制list_display中的字段 那些可以连接到修改页
list_display_links = ['title']
# 添加过滤器
list_filter = ['pub']
# 添加搜索框 [进行模糊查询,可以继续添加参数]
search_fields = ['title']
# 添加可在列表页编辑的字段 与 list_display_links 互斥
list_editable = ['price']

再谈Meta类

代码测试:
class Meta:
db_table = 'book'
verbose_name = '图书'
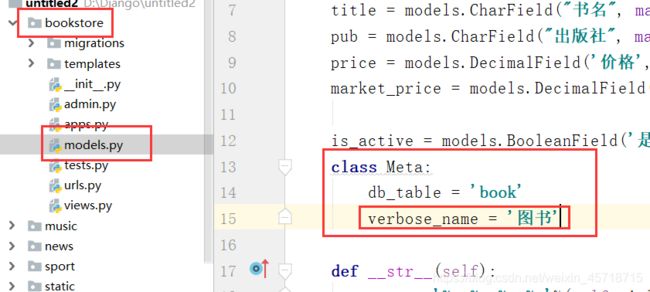
运行结果如下:

多了个s,原因是因为单词的复数形式。
修改代码如下:
class Meta:
db_table = 'book'
verbose_name = '图书'
verbose_name_plural = verbose_name
让单复数显示相同。运行结果如下:
练习

小结

关系映射-1

一对一




创建数据

代码测试:
创建oto应用:
python manago.py startapp oto
from django.db import models
# Create your models here.
class Author(models.Model):
name = models.CharField('姓名',max_length=11)
class Wife(models.Model):
name = models.CharField('姓名',max_length=11)
author = models.OneToOneField(Author,on_delete=models.CASCADE)
python manage.py makemigrations
python manage.py migrate
添加数据:
(venv) D:\Django\untitled2>python manage.py shell
>>> from oto.models import *
>>> a1 = Author.objects.create(name='wang')
>>> w1 = Wife.objects.create(name='wangfuren',author=a1)
>>> a2 = Author.objects.create(name='guo')
>>> w2 = Wife.objects.create(name='guofuren',author_id=2)
最后的 author_id=2 可以改成 author_id=a2.id
数据库截图:


查询数据
正向查询

反向查询


关系映射-2
一对多

创建

代码测试:
创建otm应用:
python manage.py startapp otm
应用注册:

from django.db import models
# Create your models here.
class Publisher(models.Model):
# 出版社
name = models.CharField('出版社名称',max_length=50)
class Book(models.Model):
# 书名
title = models.CharField('书名',max_length=11)
publisher = models.ForeignKey(Publisher,on_delete=models.CASCADE)
创建迁移文件:
python manage.py makemigrations
创建表:
python manage.py migrate
查看数据库:

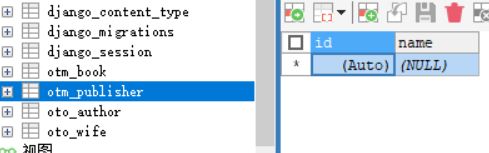
创建数据

代码测试:
(venv) D:\Django\untitled2>python manage.py shell
>>> from otm.models import *
>>> p1 = Publisher.objects.create(name = '中信出版社')
>>> b1 = Book.objects.create(title = 'Python1',publisher=p1)
>>> b2 = Book.objects.create(title = 'Python2',publisher_id=1)
>>>
数据库信息查看:

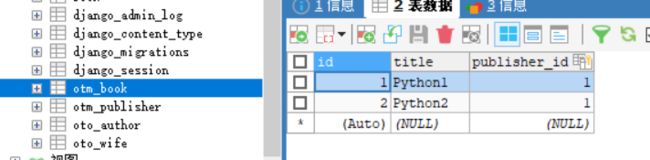
插入成功。
查询数据
正向查询

反向查询

代码测试:
正向查询测试:
>>> b1.publisher
<Publisher: Publisher object (1)>
>>> b1.publisher.name
'中信出版社'
反向查询测试:
>>> p1
<Publisher: Publisher object (1)>
>>> p1.book_set
<django.db.models.fields.related_descriptors.create_reverse_many_to_one_manager.<locals>.
RelatedManager object at 0x000001E417C3A278>
>>> p1.book_set.all()
<QuerySet [<Book: Book object (1)>, <Book: Book object (2)>]>
>>>
多对多映射

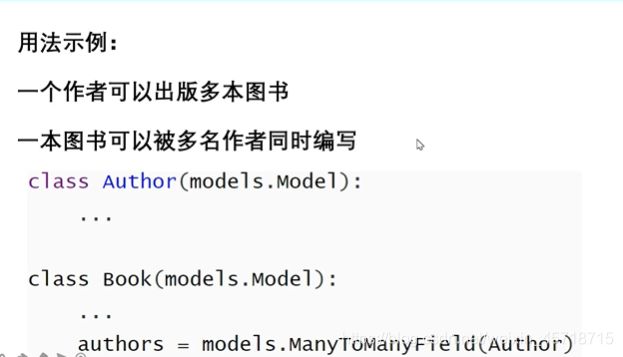
代码测试:
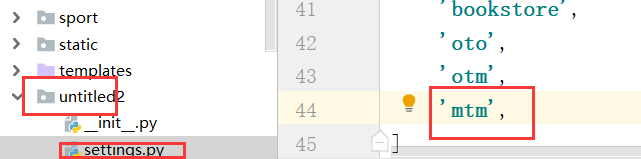
创建应用mtm:
(venv) D:\Django\untitled2>python manage.py makemigrations
应用注册:
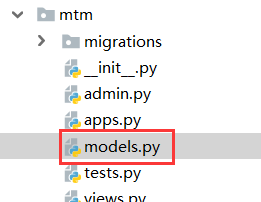
from django.db import models
# Create your models here.
class Author(models.Model):
name = models.CharField('姓名',max_length=11)
class Book(models.Model):
title = models.CharField('书名',max_length=11)
author = models.ManyToManyField(Author)
生成注册文件:
(venv) D:\Django\untitled2>python manage.py makemigrations
创建数据表:
(venv) D:\Django\untitled2>python manage.py migrate
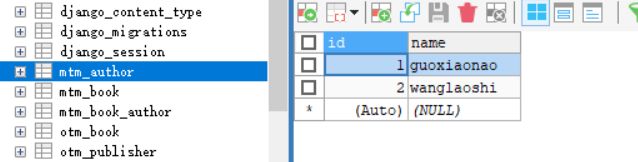
数据库查看结果:

比之前多了一张中间表。
创建数据

代码测试:
>>> from mtm.models import *
>>> a1 = Author.objects.create(name='guoxiaonao')
>>> b1 = a1.book_set.create(title='python1')
>>> a2 = Author.objects.create(name='wanglaoshi')
>>> a2.book_set.add(b1)
>>>
数据库查看:
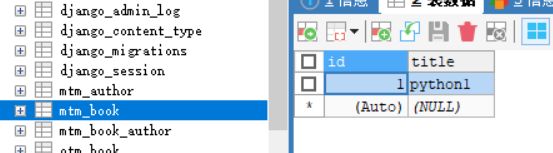
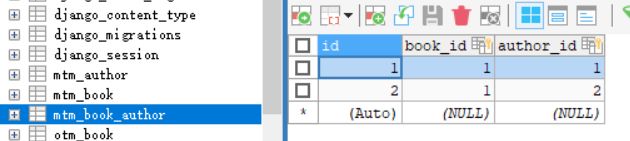
查询数据
正向查询

反向查询

小结

多练习。
cookies和session-1
会话
系统奔溃写的东西全没了
从打开浏览器访问一个网站,到关闭浏览器结束此次访问,称之为一次会话。
HTTP本身是无状态的,导致会话状态难以保持。
Cookies
保存在客户端浏览器上的存储空间
特点:
- cookies在浏览器是以键值对的形式进行存储的,键和值都是以ASCII码的形式存储的
- 存储的数据带有生命周期
- cookies的数据是按照域隔离的,不同的域之间无法访问
- cookies的内部数据会在每次访问此网站时都会携带到服务器,如果cookies过大会影响访问速度。
存储
HttpResponse.set_cookie(key,value=’’,max_age=None,expires=None)
-key:cookie的名字
-value:cookie的值
-max_age:存活相对时间,秒
-expires:具体过期时间
当不指定max_age和expires时,关闭浏览器时此数据失效。
删除&获取
获取:request.COOKIES
删除:request.delete_cookie(key)
session
会话保持-登录流程
用户登录->账号密码传至后端,服务器数据库验证,正确则发放cookie->后续浏览器将自动把当前域下的cookie都发送至服务器。但浏览器存储不是十分安全,因此引入了session。
session技术实际将数据存在了服务器里,对于不同的浏览器有不同的存储空间,生成空间后,会将一个sessionID返还给浏览器,浏览器会将sessionID存储在Cookies,之后每次返还给服务器。
session是在服务器上开辟一段空间用于保留浏览器和服务器交互时的重要数据。
session初始配置:
- 1.INSTALLED_APPS:django.contrib.sessions
- 2.MIDDLEWARE:
‘django.contrib.sessions.middleware.SessionMiddleware’
session的使用:
session对象是一个类似于字典的SessionStore类型的对象。
- 保存session的值到服务器:
request.session[‘KEY’] = VALUE - 获取session的值
value = request.session[‘KEY’]
value = request.session.get(‘KEY’,默认值) - 删除session
del request.session[‘KEY’]
干预session时间:settings.py里的SESSION_COOKIE_AGE指定cookies中的保存时间,默认两周
SESSION_EXPIRE_AT_BROWSER_CLOSE = True,关闭浏览器自动清除session,默认False
SESSION的数据在Django中保存在数据库中,因此需要保证已经执行过了migrate
Django session的问题:
- 1.django session的表是单表设计,且该表数据量不会自动清理,哪怕是已经过期。
- 2.可以每晚执行python manage.py clearsessions,会自动删除已经过期的session数据。
缓存


优化思想


数据库缓存


服务器内存


代码如下:
strings文件配置:
# 数据库缓存配置 需要手动执行 创建表的命令
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
'TIMEOUT': 300, # 缓存保存时间 单位秒 ,默认值为300
'OPTIONS': {
'MAX_ENTRIES': 300, # 缓存最大数据条数
'CULL_FREQUENCY': 2, # 缓存条数达到最大值时 删除1/x的缓存数据
}
}
}
执行以下命令创建缓存表:
python manage.py createcachetable
查看数据库中的表
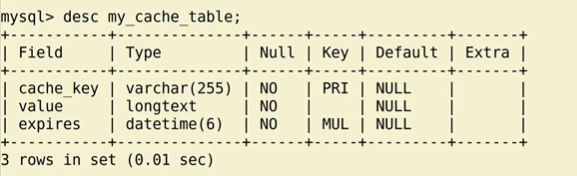
难点在cache_key怎么创建。
整理缓存策略
样式一

样式二

代码测试:
创建views.py文件:

创建视图函数:
import time
from django.http import HttpResponse
from django.views.decorators.cache import cache_page
'''
验证原理:
第一次访问的时候肯定是没有缓存的,也就是会直接打印出当前的时间,
当有缓存时,打印出来的会是之前的时间
'''
@cache_page(15)
def test_cache(request):
t = time.time()
return HttpResponse('t is %s' % t)
添加路由地址:
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('test_cache',views.test_cache)
]
浏览器访问地址:
http://127.0.0.1:8000/test_cache
运行结果如下:
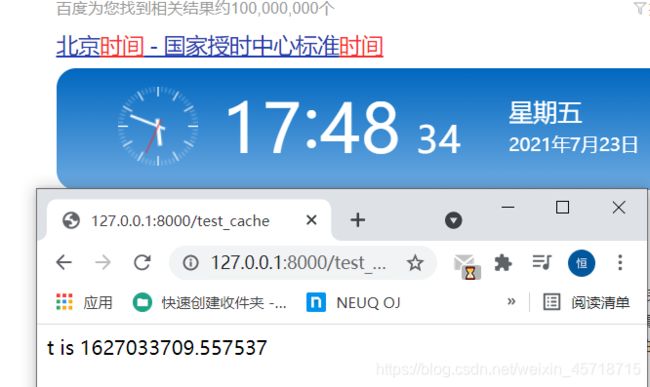
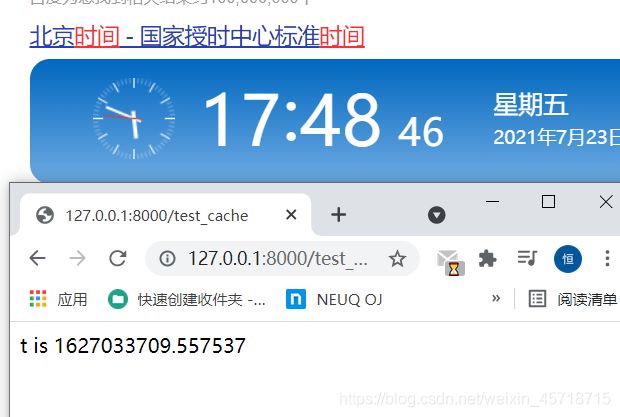
可以很明显的看出来,时间在走,但是我们打印的时间却是之前的时间,当时间超过我们设置的时间的时候:
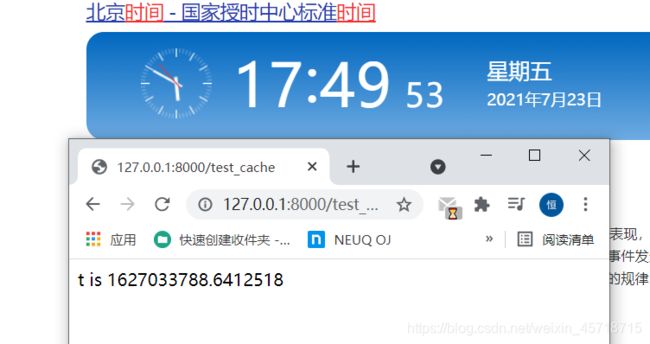
实现原理就是第一次访问的时候肯定是没有缓存的,也就是会直接打印出当前的时间,
当有缓存时,打印出来的会是之前的时间。
小结
局部缓存策略

缓存api的使用方法:



代码测试:
>>> from django.core.cache import cache
>>> cache.set('uuuname','guoxiaonao',20)
>>> cache.get('uuuname')
'guoxiaonao'
>>>


浏览器缓存策略
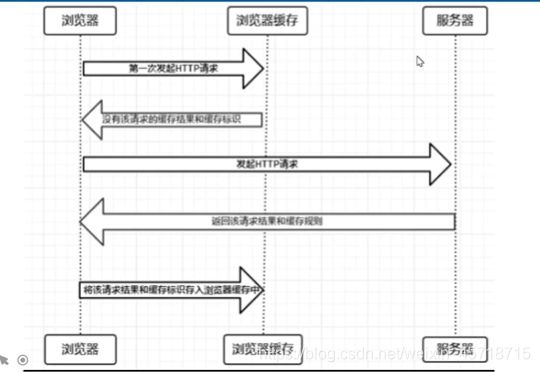
强缓存

协商缓存



小结

中间件-1

编写中间件



注册中间件

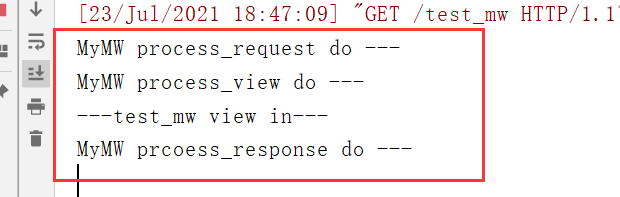
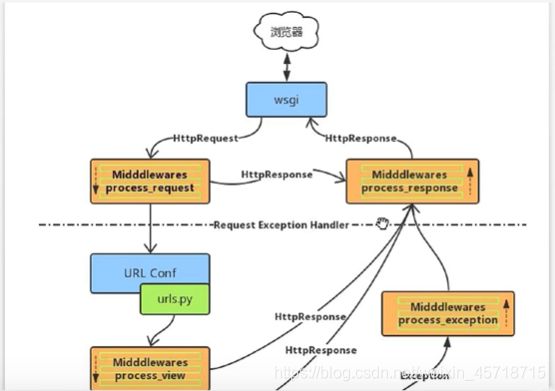
在进入视图函数之前是从上到下,从视图函数出来是从下到上调用
代码测试:
创建一个新的文件夹:
新建文件mymiddleware.py文件
from django.utils.deprecation import MiddlewareMixin
class MyMW(MiddlewareMixin):
def process_request(self,request):
print('MyMW process_request do ---')
def process_view(self,request,callback,callback_args,callback_kwargs):
print('MyMW process_view do ---')
def process_response(self,request,response):
print('MyMW prcoess_response do ---')
return response
在settings.py文件中进行注册:
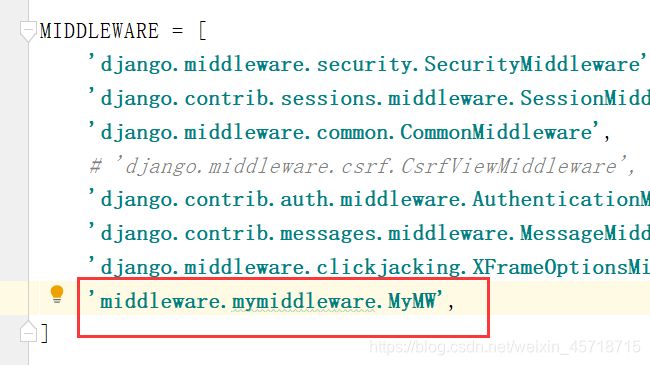
middleware.mymiddleware.MyMW
新建视图函数:
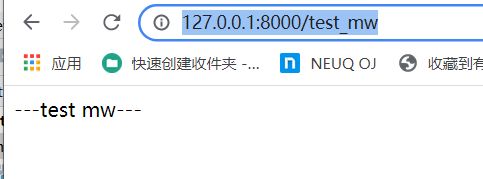
def test_mw(request):
print('---test_mw view in---')
return HttpResponse('---test mw---')
在主路由中添加访问地址:
path('test_mw',views.test_mw),
浏览器访问地址
http://127.0.0.1:8000/test_mw
运行结果如下:
练习1

小结

中间件-2
练习答案:
新建中间件类:
class VisitLimie(MiddlewareMixin):
visit_times = {}
def process_request(self,request):
ip_address = request.META['REMOTE_ADDR']
path_url = request.path_info
if not re.match('^/test',path_url):
return
times = self.visit_times.get(ip_address, 0)
print('ip',ip_address,'已访问',times)
self.visit_times[ip_address] = times +1
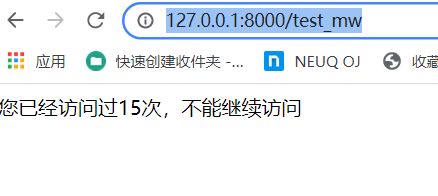
if times < 5:
return
return HttpResponse('您已经访问过'+str(times)+'次,不能继续访问')
在settings.py中注册中间件:
'middleware.mymiddleware.VisitLimie'
访问以下地址:
http://127.0.0.1:8000/test_mw
访问超过5次之后:
ps:测试完记得将注册的这个拦截test的注销掉,否则后面都没法运行了
中间件执行总流程

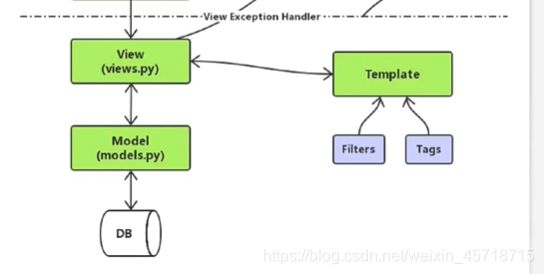
CSRF攻击

Django防范

配置步骤

代码测试:
新建页面模板:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<form action="/test_csrf" method="post">
<input type="text" name="username">
<input type="submit" value="提交">
form>
body>
html>
创建视图函数:
def test_csrf(request):
if request.method == 'GET':
return render(request,'test_csrf.html')
elif request.method == 'POST':
return HttpResponse('---test post is ok---')
配置路由地址:
path('test_csrf',views.test_csrf),
访问地址:
http://127.0.0.1:8000/test_csrf
运行结果:
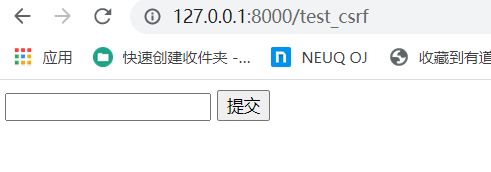
此时我们点提交时:
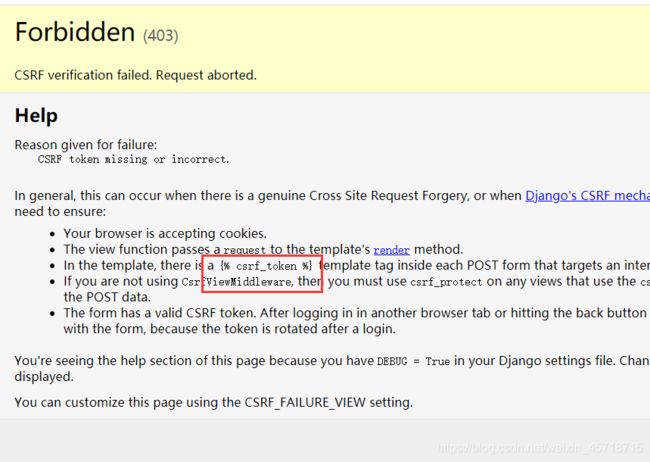
原因就是我们form的POST提交没有暗号
修改代码如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Titletitle>
head>
<body>
<form action="/test_csrf" method="post">
{% csrf_token %}
<input type="text" name="username">
<input type="submit" value="提交">
form>
body>
html>
再次点击提交:
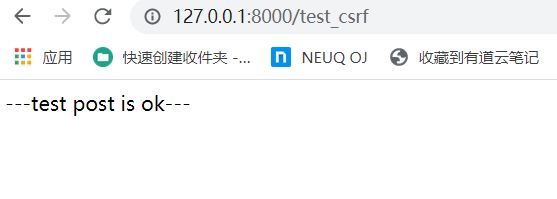
post提交成功
特殊说明
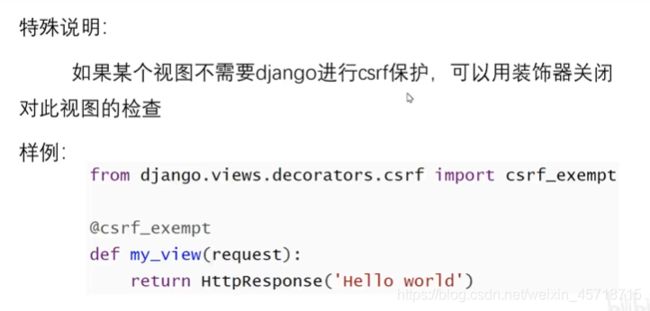
小结

分页

Paginator

Paginator属性


Paginator异常

page


代码测试:
创建新的视图函数:
def test_page(request):
#/test_page/4
#/test_page?page=1
page_num = request.GET.get('page',1)
all_data = ['a','b','c','d','e']
paginator = Paginator(all_data,2)
c_page = paginator.page(int(page_num))
return render(request,'test_page.html',locals())
这里此采用的是第二种访问地址。
第一种访问方式需要在路由器中设置page后面的参数,也就是
path(‘page/int:pg’,views.test_page)
def test_page(request)方法中直接使用pg就行
创建访问地址:
path('test_page',views.test_page),
创建test_page.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页title>
head>
<body>
{% for p in c_page %}
<p>
{{ p }}
p>
{% endfor %}
{% if c_page.has_previous %}
<a href="/test_page?page={{ c_page.previous_page_number }}">上一页a>
{% else %}
上一页
{% endif %}
{% for p_num in paginator.page_range %}
{% if p_num == c_page.number %}
{{ p_num }}
{% else %}
<a href="/test_page?page={{ p_num }}">{{ p_num }}a>
{% endif %}
{% endfor %}
{% if c_page.has_next %}
<a href="/test_page?page={{ c_page.next_page_number }}">下一页a>
{% else %}
下一页
{% endif %}
body>
html>
浏览器访问地址:
http://127.0.0.1:8000/test_page
运行结果如下:
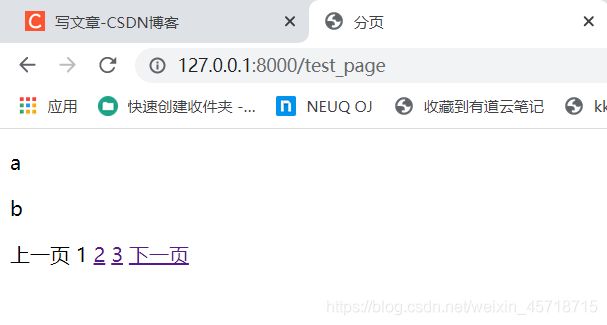
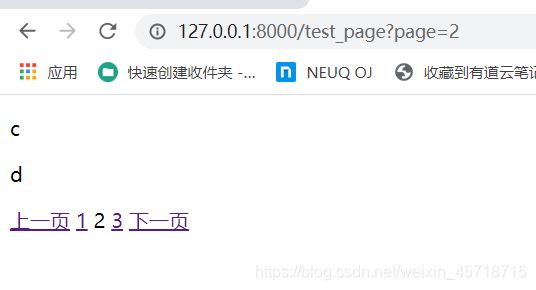
小结

Django生成CSV文件
csv文件定义

python中生成CSV文件

代码测试:
import csv
with open('test_csv.csv','w',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['a','b','c'])
writer.writerow(['e','f','g'])
运行结果:
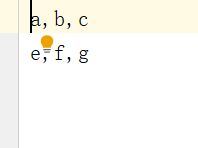
CSV文件下载

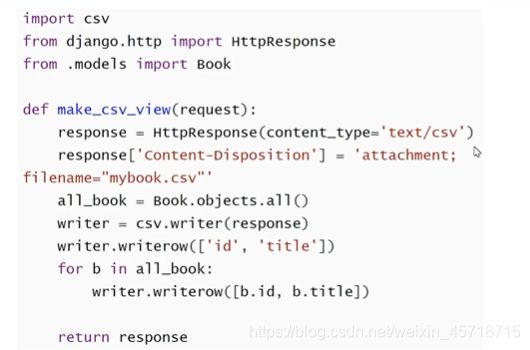
代码测试:
创建视图函数
def test_csv(request):
response = HttpResponse(content_type='text/csv')
response['Content-Disposition'] = 'attachment;filename="test.csv"'
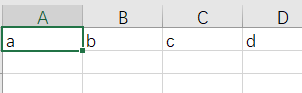
all_data = ['a','b','c','d']
writer = csv.writer(response)
writer.writerow(all_data)
return response
添加路由地址:
path('test_csv',views.test_csv),
浏览器访问地址:
http://127.0.0.1:8000/test_csv
运行结果:
练习
修改之前的页面,让网页可以直接生成当前页面的数据的csv文件。
修改代码如下:
创建视图:
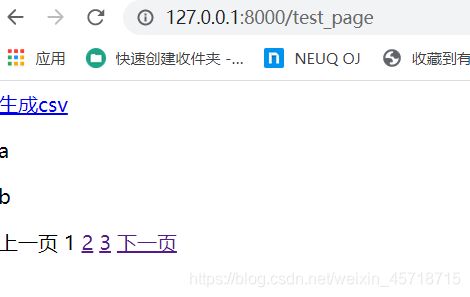
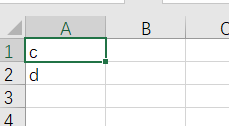
def make_page_csv(request):
# /test_page/4
# /test_page?page=1
page_num = request.GET.get('page', 1)
all_data = ['a', 'b', 'c', 'd', 'e']
paginator = Paginator(all_data, 2)
c_page = paginator.page(int(page_num))
response = HttpResponse(content_type='text/csv')
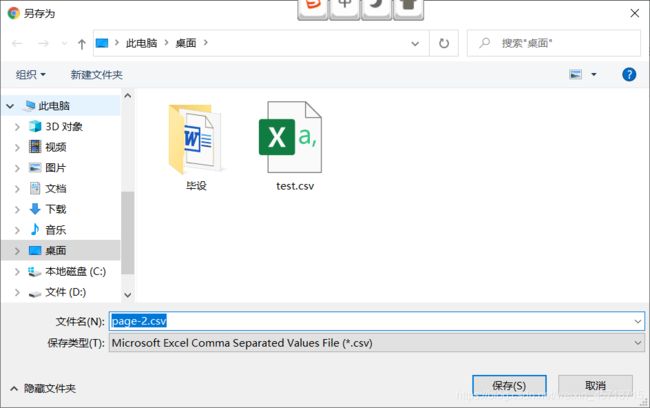
response['Content-Disposition'] = 'attachment;filename="page-%s.csv"'%(page_num)
writer = csv.writer(response)
for b in c_page:
writer.writerow([b])
return response
创建路由地址:
path('make_page_csv',views.make_page_csv),
修改html文件:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页title>
head>
<body>
<a href="/make_page_csv?page={{ c_page.number }}">生成csva>
{% for p in c_page %}
<p>
{{ p }}
p>
{% endfor %}
{% if c_page.has_previous %}
<a href="/test_page?page={{ c_page.previous_page_number }}">上一页a>
{% else %}
上一页
{% endif %}
{% for p_num in paginator.page_range %}
{% if p_num == c_page.number %}
{{ p_num }}
{% else %}
<a href="/test_page?page={{ p_num }}">{{ p_num }}a>
{% endif %}
{% endfor %}
{% if c_page.has_next %}
<a href="/test_page?page={{ c_page.next_page_number }}">下一页a>
{% else %}
下一页
{% endif %}
body>
html>
访问地址:
http://127.0.0.1:8000/test_page
内建用户系统



基本模型操作-创建用户

代码测试:
>>> from django.contrib.auth.models import User
>>> u = User.objects.create_user(username='ggg',password='123456')