Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose (译文)
链接
Arxiv:
https://arxiv.org/abs/2002.10137
Video:
https://www.bilibili.com/video/BV15f4y1t7FD/
摘要
现实世界中会说话的面孔通常伴随着自然的头部运动。然而,大多数现有的谈话人脸视频生成方法只考虑具有固定头部姿势的面部动画。在本文中,我们提出了一个深度神经网络模型来解决这个问题,该模型将源人物的音频信号a和目标人物的非常短的视频V作为输入,并输出具有个性化头部姿势(利用V中的视觉信息)、表情和嘴唇同步的合成高质量对话人脸视频(通过考虑A和V)。我们工作中最具挑战性的问题是,自然姿势通常会导致头部平面内和平面外旋转,这使得合成的会说话的人脸视频远离真实感。为了解决这一挑战,我们重建3D人脸动画并将其重新渲染为合成帧。要将这些帧微调为具有平滑背景的真实帧d转换,我们提出了一种新的记忆增强型GAN模块。通过首先训练基于公开数据集的通用映射,并使用目标人的输入短视频微调映射,我们开发了一种只需要少量帧(约300帧)的有效策略学习包括头部姿势在内的个性化说话行为。大量实验和两项用户研究表明,我们的方法可以生成高质量的对话(即,个性化的头部动作、表情和良好的嘴唇同步)会说话的面部视频,与最先进的方法相比,这些视频看起来更具有明显的头部运动效果。
1. 介绍
视觉和听觉是人与人或人与机器相互作用的两个重要的感觉通道。这两种模式中的信息密切相关[1]。近年来,跨模态学习和建模在跨学科研究中引起了越来越多的关注,包括计算机视觉、计算机图形学和多媒体(例如,[2]、[3]、[4]、[5]、[6]、[7])。
在本文中,我们重点研究了将源人物的一段音频信号转换为目标人物的视觉信息的谈话人脸视频生成。这种音频驱动的视觉模型有着广泛的应用,例如带宽有限的视频转换、虚拟锚和角色扮演游戏/移动生成等。最近,许多研究工作已经被提出(例如,[2]、[4]、[8]、[9])。然而,他们中的大多数只考虑固定头部姿势的面部动画。
在现实场景中,自然的头部运动在高质量的交流中起着重要作用[10],而胡人的感知对真实视频中细微的头部运动非常敏感。事实上,人类在交流中很容易通过固定的头部姿势感到不舒服。在本文中,我们提出了一个深度神经网络模型用来根据音频生成个性化的头部姿势的高质量对话人脸视频。
从言语中推断头部姿势(缩写为姿势-从言语中推断)不是一个新想法(例如,[11],[12])。虽然已经观察到语音和头部姿势之间存在一些可测量的相关性[6],[13],但从语音预测头部运动仍然是一个具有挑战性的问题。[12]中提出了一种实用的方法,首先从语音中推断面部活动,然后根据面部特征建模头部姿势。在我们的工作中,通过观察在深度网络中同时学习两个相关任务可能有助于提高这两个任务的性能,我们同时从语音中推断面部表情和头部姿势。
由于自然头部姿势通常会导致头部平面内和平面外旋转,因此合成具有高质量面部动画和平滑背景过渡的真实对话人脸视频非常具有挑战性。为了避免语音问题带来的困难,并专注于解决真实视频合成的挑战,我们设计了系统的输入,以包括源人物的一段音频信号和目标人物的一段简短(仅几秒钟)的对话人脸视频。请注意,随着智能手机的普及,拍摄非常短的视频(如10秒)的成本几乎与拍照(如自拍)的成本相同。因此,我们在输入的短视频中同时使用面部和音频信息来学习目标人的个性化谈话行为(例如,嘴唇和头部动作),这大大简化了我们的系统。
为了在说出源人物的输入音频信号时输出具有个性化头部姿势的目标人物的高质量合成视频,我们的系统重建三维人脸动画并将其重新渲染为视频帧。给定一个信息有限的轻量级渲染引擎,这些渲染帧通常远离真实感。然后,我们提出了一种新的记忆增强GAN模块,该模块可以根据目标人的身份特征,将粗糙的渲染帧细化为平滑过渡的真实帧。据我们所知,我们提出的方法是第一个能够将任意来源的人的音频信号转换成具有个性化头部姿势的任意目标人的人脸对话视频的系统。作为比较,之前的工作[7]只能为特定的人(即奥巴马)生成具有个性化头部姿势的高质量对话人脸视频,因为它需要大量与该特定人相关的训练数据,因此,它不能推广到任意主题。此外,当输入的短对话人脸视频不可用时,我们的方法也可以使用人脸图像作为输入,并实现与先前方法[2]、[4]、[9]相当的嘴唇同步和视频质量。我们的代码是公开的。
本文的贡献主要有三个方面:
- 我们提出了一种新的深度神经网络模型,该模型可以将任意来源的音频信号转换为任意目标人的高质量对话人脸视频,具有个性化的头部姿势和嘴唇同步。
- 与将特定参数化人脸模型的渲染微调为照片真实感视频帧的网络[14]不同,我们的记忆增强型GAN模块可以为各种人脸身份生成照片真实感视频帧(即,对应于不同的目标人物)。
- 通过首先基于公共可用数据集[3]训练通用映射,并使用目标人的输入短视频微调映射,我们开发了一种只需少量帧(约300帧)即可学习包括头部姿势在内的个性化谈话行为的有效策略。
2. 相关工作
2.1 说话人脸生成
根据被驱动信号的不同,现有的人脸视频生成方法可以大致分为两类。一个驱动信号是视频帧[14]、[15]、[16]、[17]、[18]、[19]、[20],另一个是音频帧[2]、[4]、[7]、[8]、[9]、[18]、[21]、[22]、[23]。视频驱动的对话人脸视频生成(又称人脸再现)将表情和头部姿势从驱动帧传输到目标演员的人脸图像。传统的优化方法使用3DMM参数[15]、[24]或图像扭曲[16]传递表达式。基于学习的方法[14]、[19]通过目标演员的视频或使用基于图像或附加标记的GAN模型的一般视听数据进行训练。视频帧驱动方法仅使用一种模态,即视觉信息。
音频驱动方法利用视觉和听觉两种模式,可进一步分为两个子类:针对具体人脸生成对话人脸视频,以及对于任意目标人脸[2]、[4]、[8]、[9]。后一种方法通常以音频片段和任意一张人脸图像作为输入。Chung等人[4]学习了人脸和音频信号的联合嵌入,并使用编码器-解码器CNN模型生成有声人脸视频。Zhou等人[9]提出了一种方法,通过学习联合视听表示,音频和视频都可以作为输入。Chen等人[2]首先将音频传输到面部地标,然后根据地标生成视频帧。Song等人[8]提出了一种有条件的经常性对抗网络,该网络在经常性单位中集成了音频和图像功能。然而,在这些2D方法生成的对话人脸视频中,在对话过程中头部姿势几乎是固定的。这一缺陷是由基于2D的方法固有的缺陷造成的,因为很难仅使用2D信息来自然建模姿势的变化。尽管Song等人[8]提到,他们的方法可以扩展到特殊情况下的个性化姿势,但尚未提供有关此扩展的详细信息。相比之下,我们将三维几何信息引入到该系统中,以同时建模个性化的头部姿势、表情和嘴唇同步。
2.2 3D人脸重建
三维人脸重建的目的是从二维图像中重建人脸的三维形状和外观。在这一领域提出了大量的方法,读者可以参考调查[25]和其中的参考资料。这些方法大多基于3D变形模型(3DMM)[26],该模型从扫描的3D人脸数据集中学习PCA基础,以表示一般的人脸形状。传统方法通过综合分析法拟合3DMM,该方法通过最小化渲染重建和给定图像之间的差异来优化3DMM参数[26]、[27]、[28]。
基于学习的方法[29]、[30]、[31]、[32]、[33]、[34]、[35]、[36]、[37]、[38]、[39]使用CNN学习从人脸图像到3DMM参数的映射。为了解决缺乏足够训练数据的问题,一些方法使用合成数据[29]、[30]、[33]、[38],而另一些方法使用无监督或弱监督学习[34]、[35]、[36]、[39]。本文采用[39]方法进行三维人脸重建
2.3 对抗及记忆网络
生成性对抗网络(GANs)[40]已成功应用于许多计算机视觉问题。Isola等人[41]提出的Pix2Pix在两个不同域之间的图像到图像转换方面显示出强大的能力。后来它被扩展到视频到视频合成[42],[43]。它还被应用于人脸动画和纹理合成领域。Kim等人[14]使用GAN将渲染的人脸图像转换为逼真的视频帧。虽然这种方法可以取得很好的效果,但它只适用于特定的目标人,并且必须通过与该特定人相关的数千个样本进行训练。Olszewski等人[44]提出了一种生成真实动态纹理的网络。
记忆网络是一种利用外部记忆扩充神经网络的方案。它已应用于问答系统[45],[46],综述[47],图像字幕[48]和图像彩色化[49]。由于该方案能够记住选定的关键信息,因此对于单次或多次学习都是有效的。在本文中,我们使用一个带有记忆网络的GAN来微调渲染帧,使之成为任意人的真实帧。
3. 我们的方法
在本文中,我们要解决的问题是,当给定源人物的语音和目标人物的短视频(约10秒)时,生成高质量的对话人脸视频。除了学习从语音到嘴唇运动和面部表情的转换外,我们的说话人脸生成还考虑了目标人的个性化说话行为(即头部姿势)。

图1。我们的方法的流程图。(第1阶段)我们训练从输入音频到面部表情和常见头部姿势的一般映射。然后,我们重建3D人脸,并微调通用映射,从输入视频中学习个性化的说话行为。因此,我们可以获得具有个性化头部姿势的三维人脸动画。(第2阶段)我们使用从输入视频获得的纹理和照明信息将3D人脸动画渲染为视频帧。然后,我们使用一种新的记忆增强GAN模块将这些合成帧微调为真实帧。
为了实现这一目标,我们的想法是使用以个性化头部姿势为核心的三维人脸动画,以弥合视听驱动的头部姿势学习和真实对话人脸视频生成之间的差距。我们的方法流程图如图1所示,可分为以下两个阶段进行解释。
第一阶段:从视听信息到3D人脸动画。我们使用LRW视频数据集[3]来训练从语音到面部表情和常见头部姿势的一般映射。然后,在给定音频信号和短视频的情况下,我们首先重建3D人脸(第3.1节),并微调通用映射,以从输入视频(第3.2节)中学习个性化的说话行为。为此,我们获得了具有个性化头部姿势的三维人脸动画。
第2阶段:从3D人脸动画到逼真的对话人脸视频生成。我们使用从输入视频获得的纹理和照明信息将三维人脸动画渲染为视频帧。有了这些有限的信息,图形引擎只能提供粗略的渲染效果,对于高质量的视频来说,这种效果通常不够逼真。为了将这些合成的帧细化为真实的帧,我们提出了一种新的记忆增强GAN模块(第3.4节),该模块也由LRW视频数据集进行训练。该GAN模块可以处理各种身份,并生成高质量的帧,其中包含与从输入视频中提取的人脸身份相匹配的真实对话人脸。
请注意,上述两个阶段中的两个映射都涉及两个步骤:一个步骤是从LRW视频数据集中学习的常规映射,第二个步骤是从输入视频中学习/检索个性化对话或渲染信息的轻量级微调步骤。
3.1 3D人脸重建
我们采用最先进的基于深度学习的方法[39]进行三维人脸重建。它使用CNN将3D人脸几何、纹理和照明的参数模型拟合到输入人脸照片I。该方法重建3DMM系数 χ ( I ) = { α , β , δ , γ , p } ∈ R 257 \chi(\mathbf{I})=\{\boldsymbol{\alpha}, \boldsymbol{\beta}, \boldsymbol{\delta}, \boldsymbol{\gamma}, \mathbf{p}\} \in \mathbb{R}^{257} χ(I)={α,β,δ,γ,p}∈R257 ,其中 α ∈ R 80 \boldsymbol{\alpha} \in \mathbb{R}^{80} α∈R80 是人脸识别的系数向量, β ∈ R 64 \boldsymbol{\beta} \in \mathbb{R}^{64} β∈R64 表示表情系数, δ ∈ R 80 \delta \in \mathbb{R}^{80} δ∈R80 代表纹理, γ ∈ R 27 \gamma \in \mathbb{R}^{27} γ∈R27 是照明的系数向量, p ∈ R 6 \mathbf{p} \in \mathbb{R}^{6} p∈R6 是姿势向量,包括旋转和平移。然后面部形状 S S S 和面部纹理 T T T 可以表示为 S = S ‾ + B i d α + B exp β \mathbf{S}=\overline{\mathbf{S}}+\mathbf{B}_{i d} \boldsymbol{\alpha}+\mathbf{B}_{\exp } \boldsymbol{\beta} S=S+Bidα+Bexpβ, T = T ‾ + B tex δ \mathbf{T}=\overline{\mathbf{T}}+\mathbf{B}_{\text {tex }} \boldsymbol{\delta} T=T+Btex δ ,其中̄ S ‾ \overline{\mathbf{S}} S 和 T ‾ \overline{\mathbf{T}} T 是平均形状,纹理, B i d , B exp \mathbf{B}_{i d}, \mathbf{B}_{\exp } Bid,Bexp 和 B tex \mathbf{B}_{\text {tex }} Btex 分别是形状、表情和纹理的PCA基础。Basel Face模型[50]用于 B i d \mathbf{B}_{i d} Bid 和 B tex \mathbf{B}_{\text {tex }} Btex ,FaceWareHouse[51]用于 B exp \mathbf{B}_{\text {exp }} Bexp 。
使用朗伯曲面假设计算照明度,并用球面谱波 ( S H ) (\mathrm{SH}) (SH) 基函数近似[52]。具有法向量 n i \mathbf{n}_{i} ni 和纹理 t i \mathbf{t}_{i} ti 的顶点 v i v_{i} vi 的辐照度为 C ( n i , t i , γ ) = C\left(\mathbf{n}_{i}, \mathbf{t}_{i}, \gamma\right)= C(ni,ti,γ)= t i ∑ b = 1 B 2 γ b Φ b ( n i ) \mathbf{t}_{i} \sum_{b=1}^{B^{2}} \gamma_{b} \Phi_{b}\left(\mathbf{n}_{i}\right) ti∑b=1B2γbΦb(ni) ,其中 Φ b : R 3 → R \Phi_{b}: \mathbb{R}^{3} \rightarrow \mathbb{R} Φb:R3→R 为SH基函数, γ b \gamma_{b} γb 为SH系数, B = 3 B=3 B=3 为SH带数。姿势由旋转角度和平移表示。透视摄影机模型用于将三维人脸模型投影到图像平面上。
3.2 从音频到表情和姿势的映射
众所周知,音频信号与唇部和下半部面部运动有很强的相关性。然而,只生成下半部分说话人脸显得僵硬且不自然。换句话说,面部的上半部分(包括眼睛和眉毛)运动和头部姿势对于自然的说话脸也是必不可少的。我们使用从输入视频中提取的音频信息和 3D 面部几何信息来建立从输入音频到面部表情和头部姿势的映射。请注意,虽然一个人在说同一个词时可能会有不同的头部姿势,但短时间内的说话风格往往是一致的,我们在附录 A 中提供了音频和姿势之间的相关性分析。
我们提取输入音频的梅尔频率倒谱系数 (MFCC) 特征,并使用 3DMM 系数对面部表情和头部姿势进行建模。为了建立它们之间的映射,我们设计了一个 LSTM 网络,如下所示。给定音频序列 s = { s ( 1 ) , … , s ( T ) } \mathbf{s}=\left\{s^{(1)}, \ldots, s^{(T)}\right\} s={s(1),…,s(T)} 的 MFCC 特征,真实表达系数序列 β = { β ( 1 ) , … , β ( T ) } \boldsymbol{\beta}=\left\{\beta^{(1)}, \ldots, \beta^{(T)}\right\} β={β(1),…,β(T)} , 和一个真实姿势向量序列 p = { p ( 1 ) , … , p ( T ) } \mathbf{p}=\left\{p^{(1)}, \ldots, p^{(T)}\right\} p={p(1),…,p(T)} ,我们生成预测表达系数序列 β ~ = { β ~ ( 1 ) , … , β ~ ( T ) } \widetilde{\boldsymbol{\beta}}=\left\{\widetilde{\beta}^{(1)}, \ldots, \widetilde{\beta}^{(T)}\right\} β ={β (1),…,β (T)} 和姿势向量序列 p ~ = { p ~ ( 1 ) , … , p ~ ( T ) } \widetilde{\mathbf{p}}=\left\{\widetilde{p}^{(1)}, \ldots, \widetilde{p}^{(T)}\right\} p ={p (1),…,p (T)} 。将 LSTM 网络表示为 R R R ,我们的音频到表情和头部姿势映射可以表示为:
[ β ~ ( t ) , p ~ ( t ) , h ( t ) , c ( t ) ] = R ( E ( s ( t ) ) , h ( t − 1 ) , c ( t − 1 ) ) \left[\widetilde{\beta}^{(t)}, \widetilde{p}^{(t)}, h^{(t)}, c^{(t)}\right]=R\left(E\left(s^{(t)}\right), h^{(t-1)}, c^{(t-1)}\right) [β (t),p (t),h(t),c(t)]=R(E(s(t)),h(t−1),c(t−1))
这里 E E E 是一个附加的音频编码器,应用于音频序列的 MFCC 特征 s ( t ) s^{(t)} s(t), 然后 h ( t ) , c ( t ) h^{(t)}, c^{(t)} h(t),c(t) 分别是 t t t 时刻 LSTM 单元的隐藏状态和单元状态。
我们使用包含四个损失项的损失函数来优化网络:表达系数的均方误差 (MSE) 损失、姿势系数的 MSE 损失、姿势的帧间连续性损失和帧间连续性表达损失。
记 (1) 中 β ~ = ϕ 1 ( s ) , p ~ = ϕ 2 ( s ) \widetilde{\boldsymbol{\beta}}=\phi_{1}(\mathbf{s}), \widetilde{\mathbf{p}}=\phi_{2}(\mathbf{s}) β =ϕ1(s),p =ϕ2(s), 损失函数公式为:
L ( R , E ) = E s , β [ ( β − ϕ 1 ( s ) ) 2 ] + λ 1 E s , p [ ( p − ϕ 2 ( s ) ) 2 ] + λ 2 E s [ ∑ t = 0 T − 1 ( ϕ 2 ( s ) ( t + 1 ) − ϕ 2 ( s ) ( t ) ) 2 ] + λ 3 E s [ ∑ t = 0 T − 1 ( ϕ 1 ( s ) ( t + 1 ) − ϕ 1 ( s ) ( t ) ) 2 ] \begin{aligned} \mathcal{L}(R, E) &=\mathbb{E}_{\mathbf{s}, \boldsymbol{\beta}}\left[\left(\boldsymbol{\beta}-\phi_{1}(\mathbf{s})\right)^{2}\right]+\lambda_{1} \mathbb{E}_{\mathbf{s}, \mathbf{p}}\left[\left(\mathbf{p}-\phi_{2}(\mathbf{s})\right)^{2}\right] \\ &+\lambda_{2} \mathbb{E}_{\mathbf{s}}\left[\sum_{t=0}^{T-1}\left(\phi_{2}(\mathbf{s})^{(t+1)}-\phi_{2}(\mathbf{s})^{(t)}\right)^{2}\right] \\ &+\lambda_{3} \mathbb{E}_{\mathbf{s}}\left[\sum_{t=0}^{T-1}\left(\phi_{1}(\mathbf{s})^{(t+1)}-\phi_{1}(\mathbf{s})^{(t)}\right)^{2}\right] \end{aligned} L(R,E)=Es,β[(β−ϕ1(s))2]+λ1Es,p[(p−ϕ2(s))2]+λ2Es[t=0∑T−1(ϕ2(s)(t+1)−ϕ2(s)(t))2]+λ3Es[t=0∑T−1(ϕ1(s)(t+1)−ϕ1(s)(t))2]
其中帧间连续性损失由姿势/表情的梯度的平方 L 2 L_2 L2 范数计算。
3.3 渲染与背景匹配
3.3.1 渲染
通过重建目标人物的 3D 人脸(第 3.1 节)并生成表情和姿势序列(第 3.2 节),我们收集了与音频语音同步的 3DMM 系数的混合序列,其中身份,纹理和光照系数来自目标人物,表情和姿势系数来自音频。给定这个混合的 3DMM 系数序列,我们可以使用 [36] 中的渲染引擎渲染面部图像序列。
如果我们从重建的 3DMM 系数计算反照率,这些反照率是低频且过于平滑,导致渲染的人脸图像在视觉上与输入的人脸图像不相似。另一种方法是根据输入的人脸图像计算详细的反照率。即,我们首先将重建的 3D 形状(面部网格)投影到图像平面上,然后将像素颜色分配给每个网格顶点。这样,通过划分光照来计算反照率。最后,将表情最中性、旋转角度最小的帧的反照率设置为视频的反照率。
我们在我们的方法中使用了上面提到的两种方案。在一般映射中,我们使用详细反照率进行渲染,因为LRW数据集中的视频非常短(大约1秒)。在个性化映射(即通过输入短视频进行调优)中,我们使用低频反照率来容忍头部姿势的变化,输入视频(约10秒)可以提供更多目标人物的训练数据进行微调合成的帧(用低频反照率渲染)变成真实的帧。
3.3.2 背景匹配
到目前为止,渲染的帧只有脸部部分,没有头发和背景区域,这些区域对于逼真的人脸视频也是必不可少的。一个直观的解决方案是通过匹配头部姿势来匹配来自输入视频的背景。然而,对于一个10秒左右的短视频,我们只有不到300帧来选择合适的背景,这是非常少的,在可能的高维姿态空间中可以看作是非常稀疏的点。我们的实验还表明,这种直观的解决方案无法产生好的视频帧。
在我们的方法中,我们建议从合成姿势序列中提取一些关键帧,其中关键帧对应于合成姿势序列中的关键头部运动。我们选择关键帧为短时间内在一个轴上具有最大头部方向的帧,例如,具有最左侧或最右侧头部姿势的帧。然后我们只匹配这些关键帧的背景。我们将这些匹配的背景称为关键背景。对于两个相邻关键帧之间的那些帧,我们使用线性插值来确定它们的背景。每帧中的姿势也被修改以适应背景。最后,通过包含匹配的背景来组装整个渲染帧。
如果只输入信号人脸图像 I I I 而不是短视频,我们通过使用 [30] 中的人脸轮廓方法将 I I I 旋转到预测姿势来获得匹配的背景。
3.4 用于细化帧的记忆增强 GAN
由轻量级图形引擎 [36] 渲染的合成帧通常远非现实。为了将这些框架细化为现实的框架,我们提出了一种记忆增强的 GAN。我们的方法与之前基于 GAN 的人脸再现 (FR) 方法 [14] 之间的区别是:
- FR 仅针对单个指定的人脸身份细化帧,而我们的方法可以处理各种人脸身份。即,给定目标人脸的不同身份特征,我们的方法可以使用相同的 GAN 模型输出不同的帧细化效果。
- FR 使用数千帧来为单个指定的人脸身份训练网络,而我们在一般映射学习中只为每个身份使用几个帧。基于一般映射,我们使用目标人脸的少量帧(来自输入的短视频)对网络进行微调。
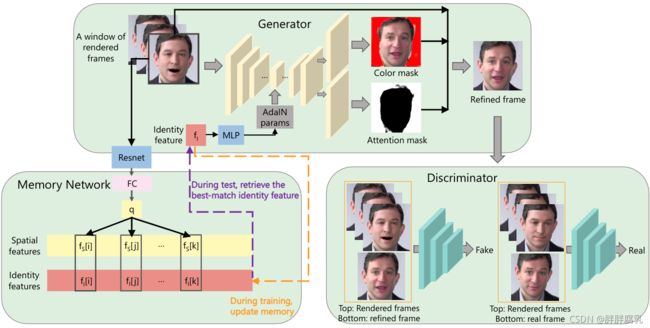
图 2. 我们用于将渲染帧细化为真实帧的记忆增强 GAN。生成器以渲染帧的窗口和身份特征作为输入,并基于注意力机制生成细化的帧。判别器判断一帧是否真实。引入记忆网络以在训练期间记住代表性身份并在测试期间检索最佳匹配身份特征。在训练过程中,记忆网络通过成对的空间特征和真实身份特征进行更新。在测试过程中,记忆网络使用空间特征作为查询来检索最匹配的身份特征。
我们将帧细化过程建模为一个函数 Φ \Phi Φ,该函数使用成对的训练数据 { ( r i , g i ) } \left\{\left(r_{i}, g_{i}\right)\right\} {(ri,gi)}, r i ∈ R r_{i} \in \mathcal{R} ri∈R 和 g i ∈ T g_{i} \in \mathcal{T} gi∈T 从渲染帧(即图形引擎渲染的合成帧)域 R \mathcal{R} R 映射到真实帧域 T \mathcal{T} T。为了处理多重身份细化,我们构建了一个 GAN 网络,它由一个条件生成器 G G G 、一个条件鉴别器 D D D 和一个额外的记忆网络 M M M组成(图 2)。记忆网络存储配对特征,即(空间特征、身份特征),这些特征在训练过程中更新。它的作用是记住包括训练集中罕见实例在内的代表性身份,并在测试期间检索最匹配的身份特征。条件生成器将渲染帧的窗口(即 3 个相邻帧 r t − 2 , r t − 1 , r t ) \left.r_{t-2}, r_{t-1}, r_{t}\right) rt−2,rt−1,rt) 的子集)和身份特征作为输入,并使用 U-Net [53]及AdaIN [54] 合成一个细化的帧。条件鉴别器以渲染帧的窗口和精炼帧或真实帧作为输入,并鉴别帧是真实帧还是合成帧。
基于注意力的生成器 G G G 。我们使用基于注意力的生成器来细化渲染帧。给定一个渲染帧的窗口 ( r t − 2 , r t − 1 , r t ) \left.r_{t-2}, r_{t-1}, r_{t}\right) rt−2,rt−1,rt)) 和一个身份特征 f t f_t ft(从 ArcFace [55] 中提取),生成器合成一个颜色掩码 C t C_t Ct 和一个注意掩码 A t A_t At,并输出一个细化的帧 o t o_t ot (这是渲染帧和颜色蒙版的加权平均值)。
o t = A t ⋅ r t + ( 1 − A t ) ⋅ C t o_{t}=A_{t} \cdot r_{t}+\left(1-A_{t}\right) \cdot C_{t} ot=At⋅rt+(1−At)⋅Ct
注意掩码指定生成的颜色掩码中的每个像素对最终细化的贡献程度。我们的生成器架构基于 U-Net 结构 2,并有两个修改。 (1) 为了生成两个输出(即颜色和注意力掩码),我们将最后一个卷积块修改为两个并行的卷积块,其中每个生成一个掩码。 (2) 为了将渲染帧的窗口和身份特征作为输入,我们采用 AdaIN [54] 将身份特征合并到我们的网络中,其中 AdaIN 参数是从输入身份特征生成的。实验结果表明,我们的网络可以为各种身份生成精细的目标人相关纹理。
记忆网络 M。我们使用记忆网络来记住代表性身份,包括训练集中的罕见实例,以便在测试期间我们可以从中检索相似的身份特征。我们通过修改它以输出连续帧来适应我们系统中 [49] 中的网络。特别是,我们的记忆网络存储成对的空间特征和身份特征。空间特征是通过以下方式提取的:(1) 将输入渲染帧馈送到在 ImageNet [57] 上预训练的 ResNet18 [56],(2) 提取“pool5”特征,以及 (3) 将“pool5”特征传递给可学习的全连接层和归一化。成对的身份特征是通过将相应的真实帧输入 ArcFace [55] 来提取的。
在训练期间,我们使用从训练集中提取的成对特征更新记忆网络。这种更新包括(1)阈值三元组损失 [49] 使相似身份的空间特征更接近,不同身份的空间特征更远,以及(2)记忆项更新过程,其中更新现有特征对或旧对被新对替换4。在测试过程中,我们以空间特征为查询检索身份特征,在内存中寻找其最近的空间特征并返回相应的身份特征。注意到直接将此特征输入生成器可能会导致抖动效果,我们通过插值来平滑多个相邻帧中检索到的特征,并将平滑后的特征用作生成器的输入。
判别器 D. 条件判别器以渲染帧的窗口和检查帧(精制帧或真实帧)作为输入,并判别检查帧是否真实。我们采用 Patch-GAN [41] 架构作为我们的鉴别器。
损失函数。我们的 GAN 模型 5 的损失函数具有三个项:GAN 损失、L1 损失和注意力损失 [17],以防止注意力掩码 A 饱和,这也加强了注意力掩码的平滑度。将输入渲染帧表示为 r,将身份特征表示为 f,将真实帧表示为 g,损失函数表示为:
L ( G , D ) = ( E r , g [ log D ( r , g ) ] + E r [ log ( 1 − D ( r , G ( r , f ) ) ) ] ) + λ 1 E r , g [ ∥ g − G ( r , f ) ∥ 1 ] + λ 2 E r [ ∥ A ∥ 2 ] + λ 3 E r [ ∑ i , j H , W ( A i + 1 , j − A i , j ) 2 + ( A i , j + 1 − A i , j ) 2 ] \begin{aligned} \mathcal{L}(G, D) &=\left(\mathbb{E}_{r, g}[\log D(r, g)]+\mathbb{E}_{r}[\log (1-D(r, G(r, f)))]\right) \\ &+\lambda_{1} \mathbb{E}_{r, g}\left[\|g-G(r, f)\|_{1}\right]+\lambda_{2} \mathbb{E}_{r}\left[\|A\|_{2}\right] \\ &+\lambda_{3} \mathbb{E}_{r}\left[\sum_{i, j}^{H, W}\left(A_{i+1, j}-A_{i, j}\right)^{2}+\left(A_{i, j+1}-A_{i, j}\right)^{2}\right] \end{aligned} L(G,D)=(Er,g[logD(r,g)]+Er[log(1−D(r,G(r,f)))])+λ1Er,g[∥g−G(r,f)∥1]+λ2Er[∥A∥2]+λ3Er[i,j∑H,W(Ai+1,j−Ai,j)2+(Ai,j+1−Ai,j)2]
我们训练 GAN 模型来优化损失函数:
G ∗ = argmin G max D L ( G , D ) G^{*}=\underset{G}{\operatorname{argmin}} \max _{D} \mathcal{L}(G, D) G∗=GargminDmaxL(G,D)
4. 实验
我们在 PyTorch 中实现了我们的方法。所有实验均在配备 Titan Xp GPU 的 PC 上进行。该代码是公开的6。本节中的动态结果可以在随附的演示视频中找到。
4.1 实验设置
在我们的模型中,两个组件(LSTM 的音频到表情和姿势,以及记忆增强的 GAN)涉及两个训练步骤:(1) 由 LRW 视频数据集训练的一般映射 [3] 和 (2) 微调一般映射学习个性化的谈话行为。在微调阶段,我们从 Youtube 收集了 15 个真实世界的单人说话人脸视频。在每个视频中,我们使用其前 12 秒(约 300 帧)作为训练数据。鉴于训练有素的通用映射,我们观察到 300 帧 8 足以完成微调任务。在第 4.3 节中,我们对来自原始 Youtube 视频的音频和来自 VoxCeleb 和 TCD 数据集的音频评估了我们的个性化微调效果(两个示例见图 3)。下面我们将通用映射和微调个性化映射分别表示为 Ours-G 和 Ours-P。网络首先在 Ours-G 中训练(使用通用数据集),然后在 Ours-P 中微调(针对特定人)。

图 4. 我们的方法适用于不同种族和年龄的人。
在我们的实验中,方程(2)中的参数为 λ 1 = 0.2 \lambda_{1}=0.2 λ1=0.2, λ 2 = 0.01 \lambda_{2}=0.01 λ2=0.01 和 λ 3 = 0.0001 \lambda_{3}=0.0001 λ3=0.0001.。等式(4)中的参数是 λ 1 = 100 , λ 2 = 2 , λ 3 = 1 e − 5. \lambda_{1}=100, \lambda_{2}=2, \lambda_{3}=1 e-5 . λ1=100,λ2=2,λ3=1e−5. 。我们的方法适用于不同种族和年龄的人。一些示例如图 4 所示。
5. 结论
在本文中,我们提出了一个深度神经网络模型,该模型可以生成一个目标人的高质量谈话人脸视频,该人说出源人的音频。由于自然说话的头部姿势经常导致平面内和平面外的头部旋转,为了克服直接从输入视频到输出视频渲染逼真帧的困难,我们重建 3D 面部并使用 3D 面部动画来弥合视听驱动的头部姿势学习和逼真的人脸视频生成之间的差距。 3D 面部动画结合了个性化的头部姿势,并使用图形引擎重新渲染为视频帧。最后,使用记忆增强的 GAN 模块将渲染的帧微调为逼真的帧。实验结果和用户研究表明,我们的方法可以生成具有个性化头部姿势的高质量谈话头部视频,并且在最先进的音频驱动谈话人脸生成方法中没有考虑到这种独特的特征。
6. 附录 A 音频和头部姿势之间的相关性
我们提出的深度网络模型学习从音频特征到面部表情和头部姿势的映射。我们根据观察到一个人在短时间内的说话风格通常是一致的,从音频中推断出头部姿势。在我们的模型中,我们有两个训练步骤:(1)LRW 训练的一般映射,以及(2)使用目标人物的短视频作为训练数据的微调步骤。目标人的头部姿态估计主要在微调阶段学习,因为LRW包含不同人的数据,他们的头部动作不同;所以我们设计从目标人物的短视频中学习头部运动行为。
为了验证我们可以从音频特征推断头部姿势的观察结果,我们对这些短视频中的音频和姿势进行了相关性分析。我们使用 MFCC 特征表示音频,并使用三个欧拉角(即俯仰、偏航、滚动)表示姿势。对于一个MFCC特征s,我们在同一个短视频中找到其局部邻域内的所有MFCC特征,并计算相邻MFCC对之间的距离和对应位姿之间的距离。我们使用半径= 0.5∗|s| 的球形邻域计算这两个距离之间的相关性。 15条短视频的平均相关系数为0.45,相关系数最大和最小分别为0.58和0.24。这些结果表明音频和姿势之间存在正相关。
7. 参考文献
[1] J. R. Nazzaro and J. N. Nazzaro, “Auditory versus visual learningof temporal patterns,” Journal of Experimental Psychology, vol. 84,no. 3, pp. 477–8, 1970.
[2] L. Chen, R. K. Maddox, Z. Duan, and C. Xu, “Hierarchical cross-modal talking face generation with dynamic pixel-wise loss,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR),2019, pp. 7832–7841.
[3] J. S. Chung and A. Zisserman, “Lip reading in the wild,” in 13thAsian Conference on Computer Vision (ACCV 2016), 2016, pp. 87–103.
[4] J. S. Chung, A. Jamaludin, and A. Zisserman, “You said that?” inBritish Machine Vision Conference (BMVC 2017), 2017.
[5] A. Davis, M. Rubinstein, N. Wadhwa, G. J. Mysore, F. Durand, andW. T. Freeman, “The visual microphone: passive recovery of soundfrom video,” ACM Trans. Graph., vol. 33, no. 4, pp. 79:1–79:10, 2014.
[6] T. Oh, T. Dekel, C. Kim, I. Mosseri, W. T. Freeman, M. Rubinstein,and W. Matusik, “Speech2face: Learning the face behind a voice,”in IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2019, pp. 7539–7548.
[7] S. Suwajanakorn, S. M. Seitz, and I. Kemelmacher-Shlizerman,“Synthesizing obama: learning lip sync from audio,” ACM Trans.Graph., vol. 36, no. 4, pp. 95:1–95:13, 2017.
[8] Y. Song, J. Zhu, D. Li, A. Wang, and H. Qi, “Talking face generationby conditional recurrent adversarial network,” in Proceedings of theTwenty-Eighth International Joint Conference on Artificial Intelligence(IJCAI 2019), 2019, pp. 919–925.
[9] H. Zhou, Y. Liu, Z. Liu, P. Luo, and X. Wang, “Talking face gener-ation by adversarially disentangled audio-visual representation,”in The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI2019), 2019, pp. 9299–9306.
[10] D. Glowinski, N. Dael, A. Camurri, G. Volpe, M. Mortillaro,and K. R. Scherer, “Toward a minimal representation of affectivegestures,” IEEE Trans. Affective Computing, vol. 2, no. 2, pp. 106–118, 2011.
[11] D. Greenwood, S. D. Laycock, and I. Matthews, “Predicting headpose from speech with a conditional variational autoencoder,” in18th Annual Conference of the International Speech CommunicationAssociation (INTERSPEECH), 2017, pp. 3991–3995.
[12] D. Greenwood, I. Matthews, and S. D. Laycock, “Joint learningof facial expression and head pose from speech,” in 19th AnnualConference of the International Speech Communication Association(INTERSPEECH), 2018, pp. 2484–2488.
[13] C. Busso, Z. Deng, M. Grimm, U. Neumann, and S. Narayanan,“Rigid head motion in expressive speech animation: Analysis andsynthesis,” IEEE Trans. Audio, Speech & Language Processing, vol. 15,no. 3, pp. 1075–1086, 2007.
[14] H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nießner, P. P ́erez,C. Richardt, M. Zollh ̈ofer, and C. Theobalt, “Deep video portraits,”ACM Trans. Graph., vol. 37, no. 4, pp. 163:1–163:14, 2018.
[15] J. Thies, M. Zollh ̈ofer, M. Stamminger, C. Theobalt, andM. Nießner, “Face2face: Real-time face capture and reenactmentof RGB videos,” in IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2016, pp. 2387–2395.
[16] H. Averbuch-Elor, D. Cohen-Or, J. Kopf, and M. F. Cohen, “Bring-ing portraits to life,” ACM Trans. Graph., vol. 36, no. 6, pp. 196:1–196:13, 2017.
[17] A. Pumarola, A. Agudo, A. M. Mart ́ınez, A. Sanfeliu, andF. Moreno-Noguer, “GANimation: Anatomically-aware facial ani-mation from a single image,” in 15th European Conference (ECCV),2018, pp. 835–851.
[18] O. Wiles, A. S. Koepke, and A. Zisserman, “X2face: A network forcontrolling face generation using images, audio, and pose codes,”in 15th European Conference (ECCV), 2018, pp. 690–706.
[19] E. Zakharov, A. Shysheya, E. Burkov, and V. S. Lempitsky, “Few-shot adversarial learning of realistic neural talking head models,”CoRR, vol. abs/1905.08233, 2019.
[20] Y. Zhang, S. Zhang, Y. He, C. Li, C. C. Loy, and Z. Liu, “One-shotface reenactment,” CoRR, vol. abs/1908.03251, 2019.
[21] B. Fan, L. Wang, F. K. Soong, and L. Xie, “Photo-real talking headwith deep bidirectional LSTM,” in IEEE International Conferenceon Acoustics, Speech and Signal Processing (ICASSP 2015), 2015, pp.4884–4888.
[22] K. Vougioukas, S. Petridis, and M. Pantic, “Realistic speech-drivenfacial animation with GANs,” International Journal of ComputerVision, DOI:10.1007/s11263-019-01251-8, 2019. [Online]. Available:https://doi.org/10.1007/s11263-019-01251-8
[23] J. Thies, M. Elgharib, A. Tewari, C. Theobalt, and M. Nießner,“Neural voice puppetry: Audio-driven facial reenactment,” CoRR,vol. abs/1912.05566, 2019.
[24] J. Thies, M. Zollh ̈ofer, M. Stamminger, C. Theobalt, andM. Nießner, “Facevr: Real-time gaze-aware facial reenactment invirtual reality,” ACM Trans. Graph., vol. 37, no. 2, pp. 25:1–25:15,2018.
[25] M. Zollh ̈ofer, J. Thies, P. Garrido, D. Bradley, T. Beeler, P. P ́erez,M. Stamminger, M. Nießner, and C. Theobalt, “State of the arton monocular 3D face reconstruction, tracking, and applications,”Computer Graphics Forum, vol. 37, no. 2, pp. 523–550, 2018.
[26] V. Blanz and T. Vetter, “A morphable model for the synthesis of3D faces,” in Proceedings of the 26th Annual Conference on ComputerGraphics and Interactive Techniques (SIGGRAPH 1999), 1999, pp.187–194.
[27] P. Garrido, M. Zollh ̈ofer, D. Casas, L. Valgaerts, K. Varanasi,P. P ́erez, and C. Theobalt, “Reconstruction of personalized 3D facerigs from monocular video,” ACM Trans. Graph., vol. 35, no. 3, pp.28:1–28:15, 2016.
[28] L. Jiang, J. Zhang, B. Deng, H. Li, and L. Liu, “3D face reconstruc-tion with geometry details from a single image,” IEEE Trans. ImageProcessing, vol. 27, no. 10, pp. 4756–4770, 2018.
[29] E. Richardson, M. Sela, and R. Kimmel, “3D face reconstruction bylearning from synthetic data,” in Fourth International Conference on3D Vision (3DV 2016), 2016, pp. 460–469.
[30] X. Zhu, Z. Lei, X. Liu, H. Shi, and S. Z. Li, “Face alignment acrosslarge poses: A 3D solution,” in IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2016, pp. 146–155.
[31] E. Richardson, M. Sela, R. Or-El, and R. Kimmel, “Learning de-tailed face reconstruction from a single image,” in IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5553–5562.
[32] A. S. Jackson, A. Bulat, V. Argyriou, and G. Tzimiropoulos,“Large pose 3D face reconstruction from a single image via directvolumetric CNN regression,” in IEEE International Conference onComputer Vision (ICCV), 2017, pp. 1031–1039.
[33] M. Sela, E. Richardson, and R. Kimmel, “Unrestricted facial ge-ometry reconstruction using image-to-image translation,” in IEEEInternational Conference on Computer Vision (ICCV), 2017, pp. 1585–1594.
[34] A. Tewari, M. Zollh ̈ofer, H. Kim, P. Garrido, F. Bernard, P. P ́erez,and C. Theobalt, “Mofa: Model-based deep convolutional faceautoencoder for unsupervised monocular reconstruction,” in IEEEInternational Conference on Computer Vision (ICCV), 2017, pp. 3735–3744.
[35] L. Tran and X. Liu, “Nonlinear 3D face morphable model,” in IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2018,pp. 7346–7355.
[36] K. Genova, F. Cole, A. Maschinot, A. Sarna, D. Vlasic, and W. T.Freeman, “Unsupervised training for 3D morphable model regres-sion,” in IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018, pp. 8377–8386.
[37] B. Gecer, S. Ploumpis, I. Kotsia, and S. Zafeiriou, “GANFIT:generative adversarial network fitting for high fidelity 3D facereconstruction,” in IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2019, pp. 1155–1164.
[38] Y. Guo, J. Zhang, J. Cai, B. Jiang, and J. Zheng, “CNN-basedreal-time dense face reconstruction with inverse-rendered photo-realistic face images,” IEEE Trans. Pattern Anal. Mach. Intell.,vol. 41, no. 6, pp. 1294–1307, 2019.
[39] Y. Deng, J. Yang, S. Xu, D. Chen, Y. Jia, and X. Tong, “Accurate3D face reconstruction with weakly-supervised learning: Fromsingle image to image set,” in IEEE Computer Vision and PatternRecognition (CVPR) Workshops, 2019.
[40] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adver-sarial nets,” in Advances in Neural Information Processing Systems(NeurIPS), 2014, pp. 2672–2680.
[41] P. Isola, J. Zhu, T. Zhou, and A. A. Efros, “Image-to-image trans-lation with conditional adversarial networks,” in IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5967–5976.
[42] T. Wang, M. Liu, J. Zhu, N. Yakovenko, A. Tao, J. Kautz, andB. Catanzaro, “Video-to-video synthesis,” in Advances in NeuralInformation Processing Systems (NeurIPS), 2018, pp. 1152–1164.
[43] T.-C. Wang, M.-Y. Liu, A. Tao, G. Liu, J. Kautz, and B. Catanzaro,“Few-shot video-to-video synthesis,” in Advances in Neural Infor-mation Processing Systems (NeurIPS), 2019.
[44] K. Olszewski, Z. Li, C. Yang, Y. Zhou, R. Yu, Z. Huang, S. Xiang,S. Saito, P. Kohli, and H. Li, “Realistic dynamic facial textures froma single image using GANs,” in IEEE International Conference onComputer Vision (ICCV), 2017, pp. 5439–5448.
[45] S. Sukhbaatar, A. Szlam, J. Weston, and R. Fergus, “End-to-endmemory networks,” in Advances in Neural Information ProcessingSystems (NeurIPS), 2015, pp. 2440–2448.
[46] A. Kumar, O. Irsoy, P. Ondruska, M. Iyyer, J. Bradbury, I. Gulrajani,V. Zhong, R. Paulus, and R. Socher, “Ask me anything: Dynamicmemory networks for natural language processing,” in Proceedingsof the 33nd International Conference on Machine Learning (ICML2016), 2016, pp. 1378–1387.
[47] B. Kim, H. Kim, and G. Kim, “Abstractive summarization of redditposts with multi-level memory networks,” in Proceedings of the2019 Conference of the North American Chapter of the Association forComputational Linguistics: Human Language Technologies (NAACL-HLT 2019), 2019, pp. 2519–2531.
[48] C. C. Park, B. Kim, and G. Kim, “Attend to you: Personalizedimage captioning with context sequence memory networks,” in2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2017, pp. 6432–6440.
[49] S. Yoo, H. Bahng, S. Chung, J. Lee, J. Chang, and J. Choo, “Coloringwith limited data: Few-shot colorization via memory augmentednetworks,” in IEEE Conference on Computer Vision and PatternRecognition (CVPR), 2019, pp. 11 283–11 292.
[50] P. Paysan, R. Knothe, B. Amberg, S. Romdhani, and T. Vetter, “A3D face model for pose and illumination invariant face recogni-tion,” in Sixth IEEE International Conference on Advanced Video andSignal Based Surveillance (AVSS 2009), 2009, pp. 296–301.
[51] C. Cao, Y. Weng, S. Zhou, Y. Tong, and K. Zhou, “Facewarehouse:A 3D facial expression database for visual computing,” IEEE Trans.Vis. Comput. Graph., vol. 20, no. 3, pp. 413–425, 2014.
[52] R. Ramamoorthi and P. Hanrahan, “An efficient representation forirradiance environment maps,” in Proceedings of the 28th AnnualConference on Computer Graphics and Interactive Techniques (SIG-GRAPH 2001), 2001, pp. 497–500.
[53] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutionalnetworks for biomedical image segmentation,” in Medical ImageComputing and Computer-Assisted Intervention (MICCAI 2015), 2015,pp. 234–241.
[54] X. Huang and S. J. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in IEEE InternationalConference on Computer Vision (ICCV), 2017, pp. 1510–1519.
[55] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additiveangular margin loss for deep face recognition,” in IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2019, pp. 4690–4699.
[56] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learningfor image recognition,” in IEEE Conference on Computer Vision andPattern Recognition (CVPR), 2016, pp. 770–778.
[57] J. Deng, W. Dong, R. Socher, L. Li, K. Li, and F. Li, “Imagenet: Alarge-scale hierarchical image database,” in IEEE Computer SocietyConference on Computer Vision and Pattern Recognition (CVPR), 2009,pp. 248–255.
[58] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: A large-scale speaker identification dataset,” in 18th Annual Confer-ence of the International Speech Communication Association (INTER-SPEECH), 2017, pp. 2616–2620.
[59] N. Harte and E. Gillen, “TCD-TIMIT: an audio-visual corpus ofcontinuous speech,” IEEE Trans. Multimedia, vol. 17, no. 5, pp. 603–615, 2015.
[60] L. Chen, Z. Li, R. K. Maddox, Z. Duan, and C. Xu, “Lip movementsgeneration at a glance,” in 15th European Conference (ECCV), 2018,pp. 538–553.
[61] R. E. Kaliouby and P. Robinson, “Generalization of a vision-basedcomputational model of mind-reading,” in Affective Computingand Intelligent Interaction, First International Conference (ACII 2005),2005, pp. 582–589.
[62] C. Villani, Topics in optimal transportation. American Mathematical Society, 2003, no. 58.