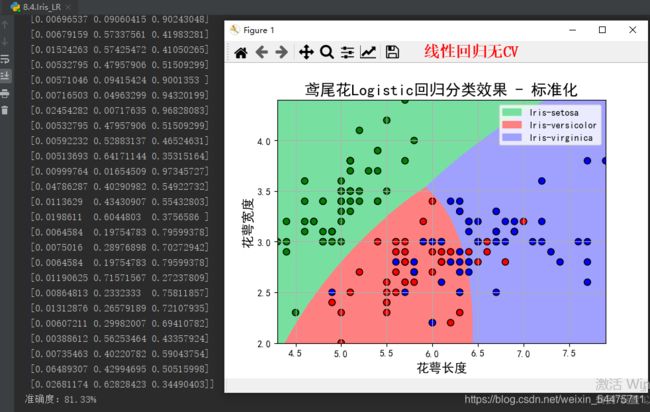
机器学习强化(回归)
一、鸢尾花(线性回归)
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt
import matplotlib as mpl
import matplotlib.patches as mpatches
if __name__ == "__main__":
path = 'iris.data' # 数据文件路径
# # # 手写读取数据
# f = file(path)
# x = []
# y = []
# for d in f:
# d = d.strip()
# if d:
# d = d.split(',')
# y.append(d[-1])
# x.append(map(float, d[:-1]))
# print '原始数据X:\n', x
# print '原始数据Y:\n', y
# x = np.array(x)
# print 'Numpy格式X:\n', x
# y = np.array(y)
# print 'Numpy格式Y - 1:\n', y
# y[y == 'Iris-setosa'] = 0
# y[y == 'Iris-versicolor'] = 1
# y[y == 'Iris-virginica'] = 2
# print 'Numpy格式Y - 2:\n', y
# y = y.astype(dtype=np.int)
# print 'Numpy格式Y - 3:\n', y
# print '\n\n============================================\n\n'
# # 使用sklearn的数据预处理
# df = pd.read_csv(path, header=None)
# x = df.values[:, :-1]
# y = df.values[:, -1]
# print x.shape
# print y.shape
# print 'x = \n', x
# print 'y = \n', y
# le = preprocessing.LabelEncoder()
# le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
# print le.classes_
# y = le.transform(y)
# print 'Last Version, y = \n', y
# def iris_type(s):
# it = {'Iris-setosa': 0,
# 'Iris-versicolor': 1,
# 'Iris-virginica': 2}
# return it[s]
#
# # 路径,浮点型数据,逗号分隔,第4列使用函数iris_type单独处理
# data = np.loadtxt(path, dtype=float, delimiter=',',
# converters={4: iris_type})
data = pd.read_csv(path, header=None)
data[4] = pd.Categorical(data[4]).codes
# iris_types = data[4].unique()
# print iris_types
# for i, type in enumerate(iris_types):
# data.set_value(data[4] == type, 4, i)
x, y = np.split(data.values, (4,), axis=1)
# print 'x = \n', x
# print 'y = \n', y
# 仅使用前两列特征
x = x[:, :2]
#模型:标准化---构造多项式特征(让模型学习到更多)---逻辑回归(CV交叉验证)
lr = Pipeline([('sc', StandardScaler()),
('poly', PolynomialFeatures(degree=2)),
('clf', LogisticRegression()) ])
#机器学习模型(管道)
# model = Pipeline([
# #特征选择,degree:选择线性函数次数
# ('poly', PolynomialFeatures(degree=2, include_bias=True)),
# #逻辑回归--分类
# ('lr', LogisticRegressionCV(Cs=np.logspace(-3, 4, 8), cv=5, fit_intercept=False))
fit_intercept=False))
lr.fit(x, y.ravel())
y_hat = lr.predict(x)
y_hat_prob = lr.predict_proba(x)
np.set_printoptions(suppress=True)
print ('y_hat = \n', y_hat)
print ('y_hat_prob = \n', y_hat_prob)
print (u'准确度:%.2f%%' % (100*np.mean(y_hat == y.ravel())))
# 画图
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
# # 无意义,只是为了凑另外两个维度
# x3 = np.ones(x1.size) * np.average(x[:, 2])
# x4 = np.ones(x1.size) * np.average(x[:, 3])
# x_test = np.stack((x1.flat, x2.flat, x3, x4), axis=1) # 测试点
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[:, 0], x[:, 1], c=np.squeeze(y), edgecolors='k', s=50, cmap=cm_dark) # 样本的显示
plt.xlabel(u'花萼长度', fontsize=14)
plt.ylabel(u'花萼宽度', fontsize=14)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
patchs = [mpatches.Patch(color='#77E0A0', label='Iris-setosa'),
mpatches.Patch(color='#FF8080', label='Iris-versicolor'),
mpatches.Patch(color='#A0A0FF', label='Iris-virginica')]
plt.legend(handles=patchs, fancybox=True, framealpha=0.8)
plt.title(u'鸢尾花Logistic回归分类效果 - 标准化', fontsize=17)
plt.show()
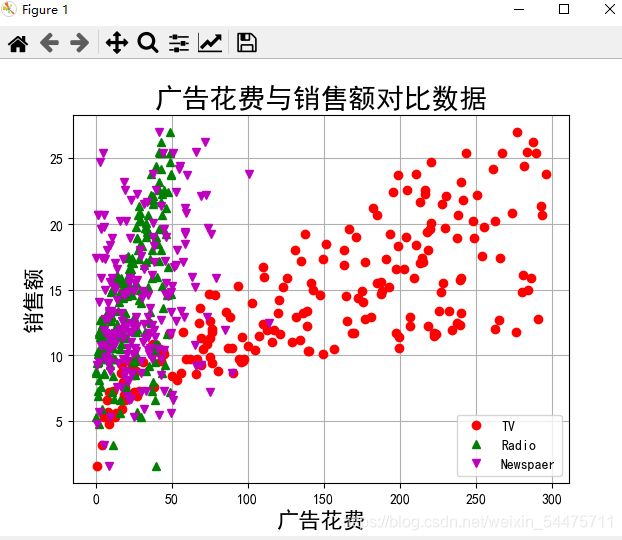
二、广告花费与销售额(无CV)
import csv
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from pprint import pprint
if __name__ == "__main__":
path = 'Advertising.csv'
# # 手写读取数据
# f = file(path)
# x = []
# y = []
# for i, d in enumerate(f):
# if i == 0:
# continue
# d = d.strip()
# if not d:
# continue
# d = map(float, d.split(','))
# x.append(d[1:-1])
# y.append(d[-1])
# pprint(x)
# pprint(y)
# x = np.array(x)
# y = np.array(y)
# Python自带库
# f = file(path, 'r')
# print f
# d = csv.reader(f)
# for line in d:
# print line
# f.close()
# # numpy读入
# p = np.loadtxt(path, delimiter=',', skiprows=1)
# print p
# print '\n\n===============\n\n'
# pandas读入
data = pd.read_csv(path) # TV、Radio、Newspaper、Sales
# x = data[['TV', 'Radio', 'Newspaper']]
x = data[['TV', 'Radio']]
y = data['Sales']
print (x)
print (y)
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
# 绘制1
plt.figure(facecolor='w')
plt.plot(data['TV'], y, 'ro', label='TV')
plt.plot(data['Radio'], y, 'g^', label='Radio')
plt.plot(data['Newspaper'], y, 'mv', label='Newspaer')
plt.legend(loc='lower right')
plt.xlabel(u'广告花费', fontsize=16)
plt.ylabel(u'销售额', fontsize=16)
plt.title(u'广告花费与销售额对比数据', fontsize=20)
plt.grid()
plt.show()
# 绘制2
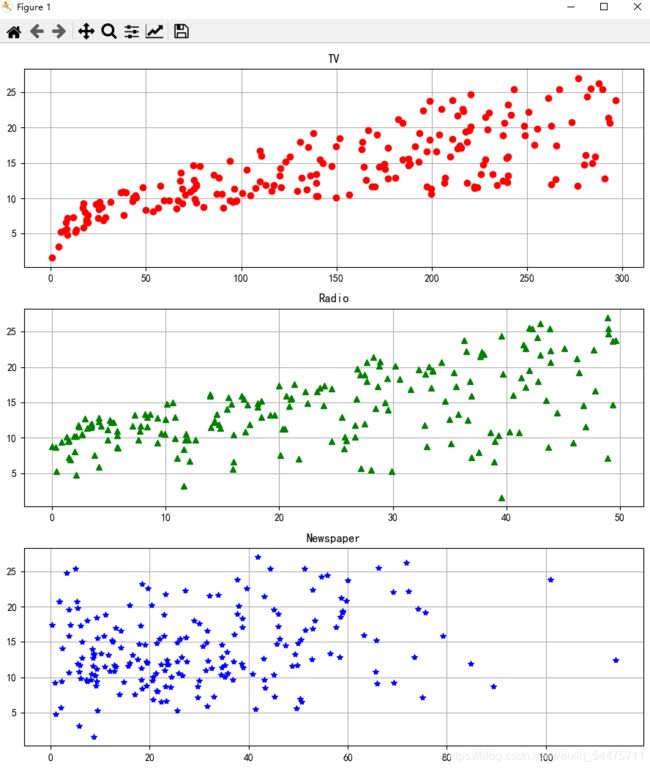
plt.figure(facecolor='w', figsize=(9, 10))
plt.subplot(311)
plt.plot(data['TV'], y, 'ro')
plt.title('TV')
plt.grid()
plt.subplot(312)
plt.plot(data['Radio'], y, 'g^')
plt.title('Radio')
plt.grid()
plt.subplot(313)
plt.plot(data['Newspaper'], y, 'b*')
plt.title('Newspaper')
plt.grid()
plt.tight_layout()
plt.show()
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=1)
print (type(x_test))
print (x_train.shape, y_train.shape)
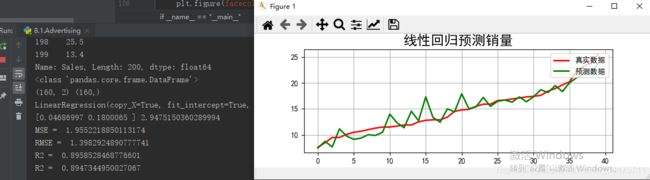
linreg = LinearRegression()
model = linreg.fit(x_train, y_train)
print (model)
print (linreg.coef_, linreg.intercept_)
order = y_test.argsort(axis=0)
y_test = y_test.values[order]
x_test = x_test.values[order, :]
y_hat = linreg.predict(x_test)
mse = np.average((y_hat - np.array(y_test)) ** 2) # Mean Squared Error
rmse = np.sqrt(mse) # Root Mean Squared Error
print ('MSE = ', mse,)
print ('RMSE = ', rmse)
print ('R2 = ', linreg.score(x_train, y_train))
print ('R2 = ', linreg.score(x_test, y_test))
plt.figure(facecolor='w')
t = np.arange(len(x_test))
plt.plot(t, y_test, 'r-', linewidth=2, label=u'真实数据')
plt.plot(t, y_hat, 'g-', linewidth=2, label=u'预测数据')
plt.legend(loc='upper right')
plt.title(u'线性回归预测销量', fontsize=18)
plt.grid(b=True)
plt.show()
三、广告花费与销售额(有CV)
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Lasso, Ridge
from sklearn.model_selection import GridSearchCV
if __name__ == "__main__":
# pandas读入
data = pd.read_csv('Advertising.csv') # TV、Radio、Newspaper、Sales
x = data[['TV', 'Radio', 'Newspaper']]
# x = data[['TV', 'Radio']]
y = data['Sales']
print (x)
print (y)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
# model = Lasso()
model = Ridge()
alpha_can = np.logspace(-3, 2, 10)
np.set_printoptions(suppress=True)
print ('alpha_can = ', alpha_can)
lasso_model = GridSearchCV(model, param_grid={'alpha': alpha_can}, cv=5)
lasso_model.fit(x_train, y_train)
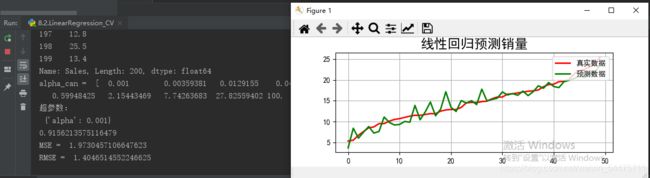
print ('超参数:\n', lasso_model.best_params_)
order = y_test.argsort(axis=0)
y_test = y_test.values[order]
x_test = x_test.values[order, :]
y_hat = lasso_model.predict(x_test)
print (lasso_model.score(x_test, y_test))
mse = np.average((y_hat - np.array(y_test)) ** 2) # Mean Squared Error
rmse = np.sqrt(mse) # Root Mean Squared Error
print ('MSE = ',mse)
print('RMSE = ',rmse)
t = np.arange(len(x_test))
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(facecolor='w')
plt.plot(t, y_test, 'r-', linewidth=2, label=u'真实数据')
plt.plot(t, y_hat, 'g-', linewidth=2, label=u'预测数据')
plt.title(u'线性回归预测销量', fontsize=18)
plt.legend(loc='upper right')
plt.grid()
plt.show()
四、预估波士顿房价
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNetCV
import sklearn.datasets
from pprint import pprint
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
import warnings
#import exceptions
def not_empty(s):
return s != ''
if __name__ == "__main__":
warnings.filterwarnings(action='ignore')
np.set_printoptions(suppress=True)
file_data = pd.read_csv('housing.data', header=None)
# a = np.array([float(s) for s in str if s != ''])
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, filter(not_empty, d[0].split(' '))))
data[i] = d
x, y = np.split(data, (13, ), axis=1)
# data = sklearn.datasets.load_boston()
# x = np.array(data.data)
# y = np.array(data.target)
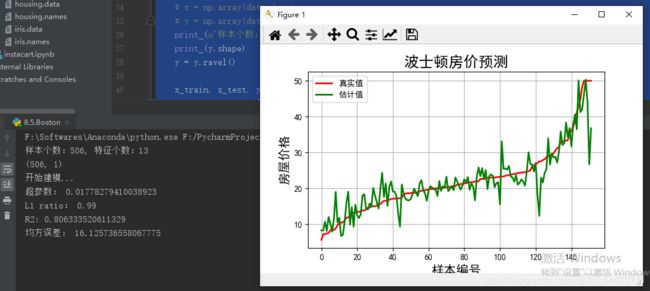
print (u'样本个数:%d, 特征个数:%d' % x.shape)
print (y.shape)
y = y.ravel()
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=0)
model = Pipeline([
('ss', StandardScaler()),
('poly', PolynomialFeatures(degree=3, include_bias=True)),
('linear', ElasticNetCV(l1_ratio=[0.1, 0.3, 0.5, 0.7, 0.99, 1], alphas=np.logspace(-3, 2, 5),
fit_intercept=False, max_iter=1e3, cv=3))
])
print (u'开始建模...')
model.fit(x_train, y_train)
linear = model.get_params('linear')['linear']
print (u'超参数:', linear.alpha_)
print (u'L1 ratio:', linear.l1_ratio_)
# print u'系数:', linear.coef_.ravel()
order = y_test.argsort(axis=0)
y_test = y_test[order]
x_test = x_test[order, :]
y_pred = model.predict(x_test)
r2 = model.score(x_test, y_test)
mse = mean_squared_error(y_test, y_pred)
print ('R2:', r2)
print (u'均方误差:', mse)
t = np.arange(len(y_pred))
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(facecolor='w')
plt.plot(t, y_test, 'r-', lw=2, label=u'真实值')
plt.plot(t, y_pred, 'g-', lw=2, label=u'估计值')
plt.legend(loc='best')
plt.title(u'波士顿房价预测', fontsize=18)
plt.xlabel(u'样本编号', fontsize=15)
plt.ylabel(u'房屋价格', fontsize=15)
plt.grid()
plt.show()
五、时间序列分析ARIMA(预测乘客人数)
import pandas as pd
import numpy as np
from statsmodels.tsa.arima_model import ARIMA
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import warnings
from statsmodels.tools.sm_exceptions import HessianInversionWarning
def extend(a, b):
return 1.05*a-0.05*b, 1.05*b-0.05*a
def date_parser(date):
return pd.datetime.strptime(date, '%Y-%m')
if __name__ == '__main__':
warnings.filterwarnings(action='ignore', category=HessianInversionWarning)
pd.set_option('display.width', 100)
np.set_printoptions(linewidth=100, suppress=True)
data = pd.read_csv('AirPassengers.csv', header=0, parse_dates=['Month'], date_parser=date_parser, index_col=['Month'])
data.rename(columns={'#Passengers': 'Passengers'}, inplace=True)
print (data.dtypes)
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
x = data['Passengers'].astype(np.float)
x = np.log(x)
print (x.head(10))
show = 'prime' # 'diff', 'ma', 'prime'
d = 1
diff = x - x.shift(periods=d)
ma = x.rolling(window=12).mean()
xma = x - ma
p = 2
q = 2
model = ARIMA(endog=x, order=(p, d, q)) # 自回归函数p,差分d,移动平均数q
arima = model.fit(disp=-1) # disp<0:不输出过程
prediction = arima.fittedvalues
print (type(prediction))
y = prediction.cumsum() + x[0]
mse = ((x - y)**2).mean()
rmse = np.sqrt(mse)
plt.figure(facecolor='w')
if show == 'diff':
plt.plot(x, 'r-', lw=2, label=u'原始数据')
plt.plot(diff, 'g-', lw=2, label=u'%d阶差分' % d)
#plt.plot(prediction, 'r-', lw=2, label=u'预测数据')
title = u'乘客人数变化曲线 - 取对数'
elif show == 'ma':
#plt.plot(x, 'r-', lw=2, label=u'原始数据')
#plt.plot(ma, 'g-', lw=2, label=u'滑动平均数据')
plt.plot(xma, 'g-', lw=2, label=u'ln原始数据 - ln滑动平均数据')
plt.plot(prediction, 'r-', lw=2, label=u'预测数据')
title = u'滑动平均值与MA预测值'
else:
plt.plot(x, 'r-', lw=2, label=u'原始数据')
plt.plot(y, 'g-', lw=2, label=u'预测数据')
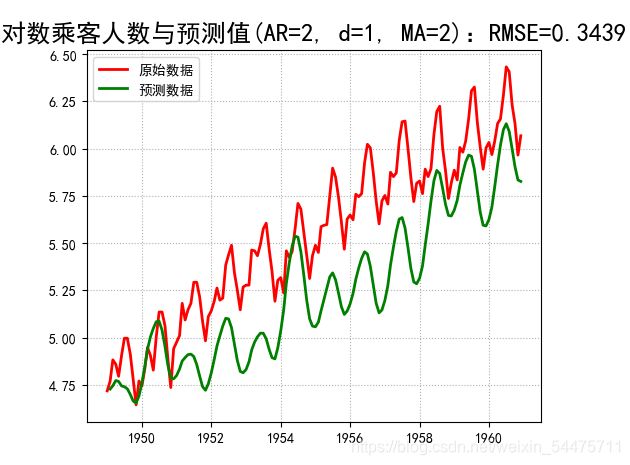
title = u'对数乘客人数与预测值(AR=%d, d=%d, MA=%d):RMSE=%.4f' % (p, d, q, rmse)
plt.legend(loc='upper left')
plt.grid(b=True, ls=':')
plt.title(title, fontsize=18)
plt.tight_layout(2)
plt.savefig('%s.png' % title)
plt.show()
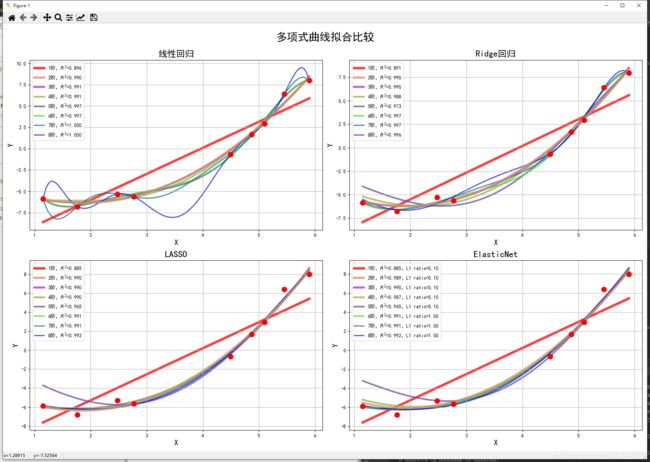
六、多项式曲线拟合比较
import numpy as np
from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, ElasticNetCV
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.exceptions import ConvergenceWarning
import matplotlib as mpl
import warnings
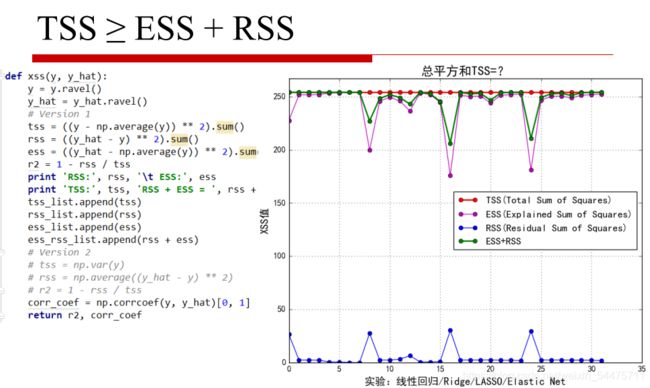
def xss(y, y_hat):
y = y.ravel()
y_hat = y_hat.ravel()
# Version 1
tss = ((y - np.average(y)) ** 2).sum()
rss = ((y_hat - y) ** 2).sum()
ess = ((y_hat - np.average(y)) ** 2).sum()
r2 = 1 - rss / tss
# print 'RSS:', rss, '\t ESS:', ess
# print 'TSS:', tss, 'RSS + ESS = ', rss + ess
tss_list.append(tss)
rss_list.append(rss)
ess_list.append(ess)
ess_rss_list.append(rss + ess)
# Version 2
# tss = np.var(y)
# rss = np.average((y_hat - y) ** 2)
# r2 = 1 - rss / tss
corr_coef = np.corrcoef(y, y_hat)[0, 1]
return r2, corr_coef
if __name__ == "__main__":
warnings.filterwarnings(action='ignore', category=ConvergenceWarning)
np.random.seed(0)
np.set_printoptions(linewidth=1000)
N = 9
x = np.linspace(0, 6, N) + np.random.randn(N)
x = np.sort(x)
y = x**2 - 4*x - 3 + np.random.randn(N)
x.shape = -1, 1
y.shape = -1, 1
models = [Pipeline([
('poly', PolynomialFeatures()),
('linear', LinearRegression(fit_intercept=False))]),
Pipeline([
('poly', PolynomialFeatures()),
('linear', RidgeCV(alphas=np.logspace(-3, 2, 50), fit_intercept=False))]),
Pipeline([
('poly', PolynomialFeatures()),
('linear', LassoCV(alphas=np.logspace(-3, 2, 50), fit_intercept=False))]),
Pipeline([
('poly', PolynomialFeatures()),
('linear', ElasticNetCV(alphas=np.logspace(-3, 2, 50), l1_ratio=[.1, .5, .7, .9, .95, .99, 1],
fit_intercept=False))])
]
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
np.set_printoptions(suppress=True)
plt.figure(figsize=(18, 12), facecolor='w')
d_pool = np.arange(1, N, 1) # 阶
m = d_pool.size
clrs = [] # 颜色
for c in np.linspace(16711680, 255, m):
print(c)
q = int(c)
clrs.append('#%06x' % q)
line_width = np.linspace(5, 2, m)
titles = u'线性回归', u'Ridge回归', u'LASSO', u'ElasticNet'
tss_list = []
rss_list = []
ess_list = []
ess_rss_list = []
for t in range(4):
model = models[t]
plt.subplot(2, 2, t+1)
plt.plot(x, y, 'ro', ms=10, zorder=N)
for i, d in enumerate(d_pool):
model.set_params(poly__degree=d)
model.fit(x, y.ravel())
lin = model.get_params('linear')['linear']
output = u'%s:%d阶,系数为:' % (titles[t], d)
if hasattr(lin, 'alpha_'):
idx = output.find(u'系数')
output = output[:idx] + (u'alpha=%.6f,' % lin.alpha_) + output[idx:]
if hasattr(lin, 'l1_ratio_'): # 根据交叉验证结果,从输入l1_ratio(list)中选择的最优l1_ratio_(float)
idx = output.find(u'系数')
output = output[:idx] + (u'l1_ratio=%.6f,' % lin.l1_ratio_) + output[idx:]
print (output, lin.coef_.ravel())
x_hat = np.linspace(x.min(), x.max(), num=100)
x_hat.shape = -1, 1
y_hat = model.predict(x_hat)
s = model.score(x, y)
r2, corr_coef = xss(y, model.predict(x))
# print 'R2和相关系数:', r2, corr_coef
# print 'R2:', s, '\n'
z = N - 1 if (d == 2) else 0
label = u'%d阶,$R^2$=%.3f' % (d, s)
if hasattr(lin, 'l1_ratio_'):
label += u',L1 ratio=%.2f' % lin.l1_ratio_
plt.plot(x_hat, y_hat, color=clrs[i], lw=line_width[i], alpha=0.75, label=label, zorder=z)
plt.legend(loc='upper left')
plt.grid(True)
plt.title(titles[t], fontsize=18)
plt.xlabel('X', fontsize=16)
plt.ylabel('Y', fontsize=16)
plt.tight_layout(1, rect=(0, 0, 1, 0.95))
plt.suptitle(u'多项式曲线拟合比较', fontsize=22)
plt.show()
y_max = max(max(tss_list), max(ess_rss_list)) * 1.05
plt.figure(figsize=(9, 7), facecolor='w')
t = np.arange(len(tss_list))
plt.plot(t, tss_list, 'ro-', lw=2, label=u'TSS(Total Sum of Squares)')
plt.plot(t, ess_list, 'mo-', lw=1, label=u'ESS(Explained Sum of Squares)')
plt.plot(t, rss_list, 'bo-', lw=1, label=u'RSS(Residual Sum of Squares)')
plt.plot(t, ess_rss_list, 'go-', lw=2, label=u'ESS+RSS')
plt.ylim((0, y_max))
plt.legend(loc='center right')
plt.xlabel(u'实验:线性回归/Ridge/LASSO/Elastic Net', fontsize=15)
plt.ylabel(u'XSS值', fontsize=15)
plt.title(u'总平方和TSS=?', fontsize=18)
plt.grid(True)
plt.show()

在这里插入图片描述
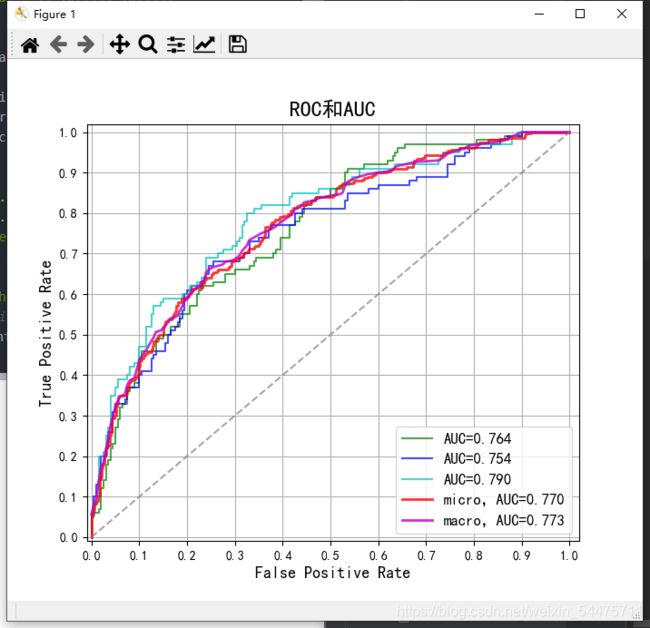
七、ROC和AUC(自编数据)
import numbers
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression, LogisticRegressionCV
from sklearn.svm import SVC
from sklearn.preprocessing import label_binarize
from numpy import interp
from sklearn import metrics
from itertools import cycle
if __name__ == '__main__':
np.random.seed(0)
pd.set_option('display.width', 300)
np.set_printoptions(suppress=True)
n = 300
x = np.random.randn(n, 50)
y = np.array([0]*100+[1]*100+[2]*100)
n_class = 3
alpha = np.logspace(-3, 3, 7)
clf = LogisticRegression(penalty='l2', C=1)
clf.fit(x, y)
y_score = clf.decision_function(x)
y = label_binarize(y, classes=np.arange(n_class))
colors = cycle('gbc')
fpr = dict()
tpr = dict()
auc = np.empty(n_class+2)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(7, 6), facecolor='w')
for i, color in zip(np.arange(n_class), colors):
fpr[i], tpr[i], thresholds = metrics.roc_curve(y[:, i], y_score[:, i])
auc[i] = metrics.auc(fpr[i], tpr[i])
plt.plot(fpr[i], tpr[i], c=color, lw=1.5, alpha=0.7, label=u'AUC=%.3f' % auc[i])
# micro
fpr['micro'], tpr['micro'], thresholds = metrics.roc_curve(y.ravel(), y_score.ravel())
auc[n_class] = metrics.auc(fpr['micro'], tpr['micro'])
plt.plot(fpr['micro'], tpr['micro'], c='r', lw=2, ls='-', alpha=0.8, label=u'micro,AUC=%.3f' % auc[n_class])
# macro
fpr['macro'] = np.unique(np.concatenate([fpr[i] for i in np.arange(n_class)]))
tpr_ = np.zeros_like(fpr['macro'])
for i in np.arange(n_class):
tpr_ += interp(fpr['macro'], fpr[i], tpr[i])
tpr_ /= n_class
tpr['macro'] = tpr_
auc[n_class+1] = metrics.auc(fpr['macro'], tpr['macro'])
print ('Macro AUC:', metrics.roc_auc_score(y, y_score, average='macro'))
plt.plot(fpr['macro'], tpr['macro'], c='m', lw=2, alpha=0.8, label=u'macro,AUC=%.3f' % auc[n_class+1])
plt.plot((0, 1), (0, 1), c='#808080', lw=1.5, ls='--', alpha=0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True)
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
# plt.legend(loc='lower right', fancybox=True, framealpha=0.8, edgecolor='#303030', fontsize=12)
plt.title(u'ROC和AUC', fontsize=17)
plt.show()
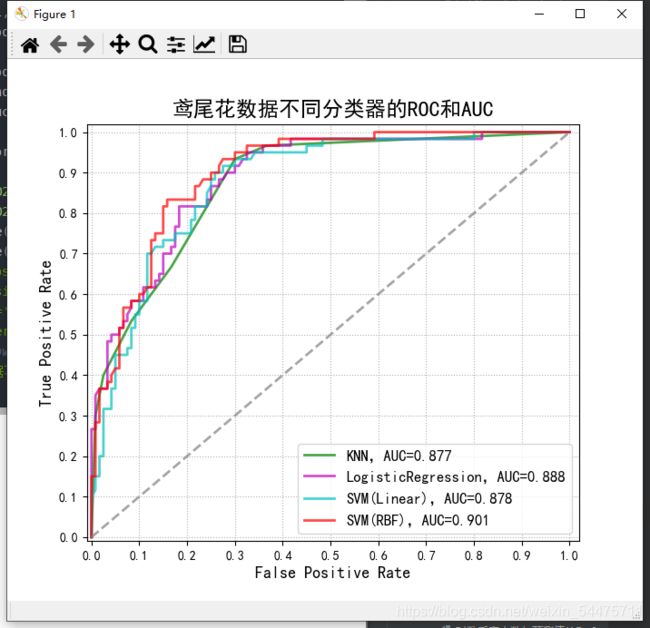
八、ROC和AUC(鸢尾花数据)
import numbers
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression, LogisticRegressionCV
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from numpy import interp
from sklearn import metrics
from itertools import cycle
def iris_type(s):
# python3读取数据时候,需要一个编码因此在string面前加一个b
it = {b'Iris-setosa': 0, b'Iris-versicolor': 1, b'Iris-virginica': 2}
return it[s]
iris_feature = 'sepal length', 'sepal width', 'petal lenght', 'petal width'
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
print('%s Accuracy:%.3f' % (tip, np.mean(acc)))
if __name__ == '__main__':
np.random.seed(0)
pd.set_option('display.width', 300)
np.set_printoptions(suppress=True)
# data = pd.read_csv('iris.data', header=None)
# iris_types = data[4].unique()
# for i, iris_type in enumerate(iris_types):
# data.set_value(data[4] == iris_type, 4, i)
data = np.loadtxt('iris.data', dtype=float, delimiter=',', converters={4: iris_type})
x, y = np.split(data, (4,), axis=1)
x = data[:, :2]
n, features = x.shape
y = data[:, -1].astype(np.int)
c_number = np.unique(y).size
x, x_test, y, y_test = train_test_split(x, y, train_size=0.6, random_state=0)
y_one_hot = label_binarize(y_test, classes=np.arange(c_number))
alpha = np.logspace(-2, 2, 20)
models = [
['KNN', KNeighborsClassifier(n_neighbors=7)],
['LogisticRegression', LogisticRegressionCV(Cs=alpha, penalty='l2', cv=3)],
['SVM(Linear)', GridSearchCV(SVC(kernel='linear', decision_function_shape='ovr'), param_grid={'C': alpha})],
['SVM(RBF)', GridSearchCV(SVC(kernel='rbf', decision_function_shape='ovr'), param_grid={'C': alpha, 'gamma': alpha})]]
colors = cycle('gmcr')
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(7, 6), facecolor='w')
for (name, model), color in zip(models, colors):
model.fit(x, y)
if hasattr(model, 'C_'):
print(model.C_)
if hasattr(model, 'best_params_'):
print(model.best_params_)
if hasattr(model, 'predict_proba'):
y_score = model.predict_proba(x_test)
else:
y_score = model.decision_function(x_test)
fpr, tpr, thresholds = metrics.roc_curve(y_one_hot.ravel(), y_score.ravel())
auc = metrics.auc(fpr, tpr)
print(auc)
plt.plot(fpr, tpr, c=color, lw=2, alpha=0.7, label=u'%s,AUC=%.3f' % (name, auc))
plt.plot((0, 1), (0, 1), c='#808080', lw=2, ls='--', alpha=0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
# plt.legend(loc='lower right', fancybox=True, framealpha=0.8, edgecolor='#303030', fontsize=12)
plt.title(u'鸢尾花数据不同分类器的ROC和AUC', fontsize=17)
plt.show()