MySQL的日志系统redo log、binlog、undo log的详细介绍
详细介绍了Mysql的日志系统中的三种日志:重做日志(redo log)、归档日志(binlog)、回滚日志(undo log )以及一条更新sql的执行流程。
我们的sql可以分为两种,一种是查询,一种是更新(插入,更新,删除),此前学习了一条查询sql语句的执行流程,而如果是更新语句,则除了上面的流程之外(更新还会导致相关表的查询缓存全部失效),还会涉及到三个重要的日志模块(基于InnoDB引擎),分别是重做日志(redo log)、归档日志(binlog)、回滚日志(undo log )。
除了上面三种日志之外,常见MySQL日志还有:
- 慢查询日志(slow log):记录所有执行时间超过long_query_time的所有查询或不使用索引的查询。
- 中继日志(relay log):MySQL主从复制时从服务器使用的日志。
文章目录
- 1 redo log重做日志
-
- 1.1 redo log文件格式
- 2 binlog归档日志
-
- 2.1 binlog 文件格式
- 3 undo log回滚日志
- 4 日志参数
1 redo log重做日志
redo log日志模块又名重做日志、事务日志,它是InnoDB引擎自带的一个日志模块。redo log通常又被称为物理日志,记录的是数据页的物理修改,比如哪个数据页的那个偏移量位置做了什么修改,而不是某一行或某几行修改成怎样,每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成。它可以用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置,因为修改会覆盖之前的)。redo log保证了事务的持久性。
在MySQL中,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程IO成本、随机查找成本(因为操作的数据散落在磁盘各处)都很高。为了解决这个问题,MySQL使用了WAL技术(Write Ahead Logging),也称为日志先行技术,它的关键点就是先写日志,再写磁盘。写日志虽然也是写磁盘,但是它是顺序写,相比随机写开销更小,能提升语句执行的性能。WAL技术保证了数据一致性和持久性,并且提升语句执行性能。
当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到Buffer Poll内存中,并更新redo log日志系统内存,这个时候更新就算完成了。同时,InnoDB引擎会在适当的时候,将这个操作记录由后台线程异步更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做的。
1.1 redo log文件格式
InnoDB的redo log是固定大小的,并且大小可以配置,比如可以配置为一组4个文件,每个文件的大小是1GB,那么总共就可以记录4GB的操作。它采用的是环形数组形式,只能从头开始写,写到末尾就将一部分redo log跟新到磁盘中,随后又回到开头循环写。
如下面这个图所示:
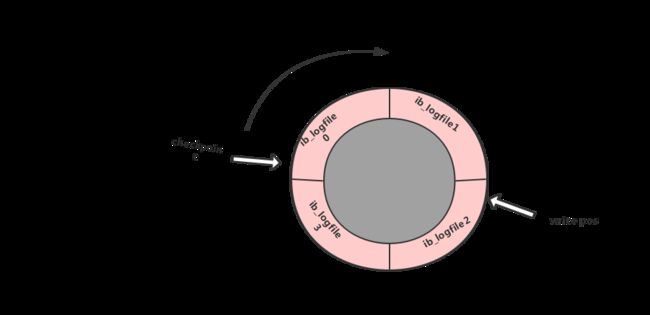
上图中,write pos是当前redo log日志刷盘记录的指针,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。checkpoint可以看做是脏页刷盘检查点,也是往后推移并且循环的,写checkpoint之前要把buffer pool脏数据记录更新到数据文件中完成数据落盘才可以,即checkpoint之前的数据更改一定是成功持久化到数据文件中了的。
在redo log满了到擦除旧记录腾出新空间这段期间,是不能再接收新的更新请求,所以有可能会导致MySQL卡顿。
在writepos和checkpoint之间的还空着的部分(在上图中就是ib_logfile_2和ib_logfile_3),可以用来记录新的操作,如果write pos追上了checkpoint,表示redo log满了,这个时候不能够在执行新的更新,得停下来先擦除一些记录,把checkpoint推进一下。擦除记录前要把记录更新到数据文件。
由于redo log的加入,保证了MySQL数据一致性和持久性的同时(即使数据刷盘之前MySQL奔溃了,重启后仍然能通过redo log里的更改记录进行重放,重新刷盘,保证之前提交的记录不会丢失,这个能力称为crash-safe),还提升了sql语句的执行性能(写redo log是顺序写,相比于更新数据文件的随机写,日志的写入开销更小,能显著提升语句的执行性能,提高并发量)。
实际上,数据库的crash-safe保证的是:
- 如果客户端收到事务成功的消息,事务就一定持久化了;
- 如果客户端收到事务失败(比如主键冲突、回滚等)的消息,事务就一定失败了;
- 如果客户端收到“执行异常”的消息或者什么也没收到,应用需要重连后通过查询当前状态来继续后续的逻辑。此时数据库只需要保证内部(数据和日志之间,主库和备库之间)一致就可以了,即事务一致性。
2 binlog归档日志
binlog日志模块位于Mysql架构中的Server层中,因此这是MySQL自带的日志模块,和具体的存储引擎无关,binlog一个二进制格式的日志文件,所有的存储引擎都可以识别并使用,也称为逻辑日志。
在之前MySQL中并没有InnoDB引擎,MySQL自带的引擎是MyISAM,但是MyISAM没有crash-safe的能力,因为binlog日志只能用于归档。而InnoDB是另一个公司以插件形式引入MySQL的,既然只依赖binlog没有crash-safe能力,所以InnoDB使用另外一套日志系统----也就是redo log来实现crash-safe能力。
之所以将binlog称为归档日志,是因为binlog不会像redo log一样擦掉之前的记录循环写,而是一直记录(超过有效期才会被清理),如果超过单个日志文件的最大值(默认1G,可以通过变量 max_binlog_size 设置),则会新起一个文件继续记录。但由于日志可能是基于事务来记录的(如InnoDB表类型),而事务是绝对不可能也不应该跨文件记录的,如果正好binlog日志文件达到了最大值但事务还没有提交则不会切换新的文件记录,而是继续增大日志,所以 max_binlog_size 指定的值和实际的binlog日志大小不一定相等。
并且,binlog记录的内容和redo log也不一样,redo log是物理日志,记录的是“某个数据页上做了什么修改”,binlog是逻辑日志,日志中包含了所有引起或可能引起数据库改变(如delete语句但没有匹配行)的事件信息(sql语句),比如“给 ID=2 这一行的 c 字段加 1 ”,但绝不会包括select和show这样的查询sql语句,sql语句以"事件"的形式保存,每一个记录的sql包含了时间、事件开始和结束位置等信息。
正是由于binlog有归档的作用,所以binlog主要用作:
主从同步,从库的数据同步依赖的就是binlog。MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。这种同步可以推广的更远,即可以通过监听binlog日志,将一个普通库中操作,同步到另一个库的相同的表中,这两个表可以结构一致,但是没有主从关系,大公司应该都有监听binlog日志的组件。- binlog文件是追加写入的,不会覆盖,数据库可以
基于某个时间点的精确还原,即数据恢复。首先将某个时间点的数据库全备份数据导入,然后找到对应的binlog文件,然后指定二进制日志的起始/终止时间点或者指定起始/终止pos节点,执行恢复即可。
2.1 binlog 文件格式
binlog 日志有三种格式,通过show variables like 'binlog_format'可以查看使用的哪一种。
三种格式的对比如下:
| format | 定义 | 优点 | 缺点 |
|---|---|---|---|
| statement | 记录的是修改SQL语句原文。MySQL5.7之前的默认格式。 | 日志文件小,节约IO,提高性能。写完之后的最后会有 COMMIT和XID标记。 | 准确性差,对一些系统函数不能准确复制或不能复制,如now()、uuid()等 |
| row(推荐) | 记录的是每行的实际数据的变更。MySQL5.7及其之后的默认格式。 | 准确性强,能准确复制数据的变更,利于数据恢复和主从同步。写完之后的最后会有一个 XID event标记。 | 以每行记录的修改来记录,一个sql更新多行就会记录多条。导致日志文件大,产生较大的网络IO和磁盘IO |
| mixed | statement和row模式的混合。根据sql语句由系统决定在基于段和基于行的日志格式中进行选择。 | 准确性强,文件大小适中 | 有可能发生主从不一致问题 |
3 undo log回滚日志
undo log同样是InnoDB引擎的另一个日志模块,undo log顾名思义,主要就是提供了回滚的作用。undo log保证了事务的原子性,但它还有另一个主要作用,就是多个版本控制(MVCC,全称Multi-Version Concurrency Control)。
undo log和redo log记录物理日志不一样,它是逻辑日志。在数据更新的流程中,会记录一条与当前sql操作相反的逻辑日志到undo log中,可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。undo log记录中存储的是老版本数据,当一个旧的事务需要读取数据时,为了能读取到老版本的数据,需要逆着undo链找到满足其可见性的记录,这就是MVCC的一致性视图简单原理(后面会详细讲解MVCC)。
如果因为某些原因导致事务异常失败了,可以借助undo log中的逻辑记录读取到相应的内容进行回滚,保证事务的原子性,所以undo log也必不可少。
为了保证事务并发操作时,在写各自的undo log时不产生冲突,undo log是采用回滚段(segment)的方式来记录的,每个undo操作在记录的时候占用一个undo log segment,每个回滚段中有1024个undo log segment。
应用到多版本行版本控制(MVCC)的时候(读已提交和可重复读的隔离级别),有时候也是通过undo log来实现的:当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据是什么,从而提供该行版本信息,让用户实现非锁定的一致性读取,可以有效减少加锁操作,提升性能。
4 日志参数
https://www.cnblogs.com/wushenghfut/p/11832141.html
https://blog.csdn.net/u010520724/article/details/108274959
https://zhuanlan.zhihu.com/p/147040331
undolog文件名为undo_001、undo_002。
redolog文件名为ib_logfile0、ib_logfile1。
binlog文件名为binlog.000009、binlog.000010。
查看binlog:
show binary logs
查看当前mysqlbinlog位置:
which mysqlbinlog
查看binlog:
/usr/bin/mysqlbinlog --no-defaults --database=db --start-datetime='2019-04-11 00:00:00' --stop-datetime='2019-04-11 15:00:00' binlog.000009 | more
参考资料:
- 《 MySQL 技术内幕: InnoDB 存储引擎》
- 《高性能 MySQL》
- 《MySQL实战45讲 | 极客时间 | 丁奇》
- 《详细分析MySQL的日志(一)》
如有需要交流,或者文章有误,请直接留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!