互联网Java工程师面试题·Java 总结篇·第十一弹
目录
90、简述一下你了解的设计模式。
91、用 Java 写一个单例类。
92、什么是 UML?
93、UML 中有哪些常用的图?
94、用 Java 写一个冒泡排序。
95、用 Java 写一个折半查找。
90、简述一下你了解的设计模式。
所谓设计模式,就是一套被反复使用的代码设计经验的总结(情境中一个问题经过证实的一个解决方案)。使用设计模式是为了可重用代码、让代码更容易被他人理解、保证代码可靠性。设计模式使人们可以更加简单方便的复用成功的设计和体系结构。将已证实的技术表述成设计模式也会使新系统开发者更加容易理解其设计思路。
在 GoF 的《Design Patterns: Elements of Reusable Object-Oriented Software》中给出了三类(创建型[对类的实例化过程的抽象化]、结构型[描述如何将类或对象结合在一起形成更大的结构]、行为型[对在不同的对象之间划分责任和算法的抽象化])共 23 种设计模式,包括:Abstract Factory(抽象工厂模式),Builder(建造者模式),Factory Method(工厂方法模式),Prototype(原始模型模式),Singleton(单例模式);Facade(门面模式),Adapter(适配器模式),Bridge(桥梁模式),Composite(合成模式),Decorator(装饰模式),Flyweight(享元模式),Proxy(代理模式);Command(命令模式),Interpreter(解释器模式),Visitor(访问者模式),Iterator(迭代子模式),Mediator(调停者模式),Memento(备忘录模式),Observer(观察者模式),State(状态模式 ),Strategy(策略模式 ),Template Method(模板方法模式),Chain Of Responsibility(责任链模式)。
面试被问到关于设计模式的知识时,可以拣最常用的作答,例如:
工厂模式:工厂类可以根据条件生成不同的子类实例,这些子类有一个公共的抽象父类并且实现了相同的方法,但是这些方法针对不同的数据进行了不同的操作(多态方法)。当得到子类的实例后,开发人员可以调用基类中的方法而不必考虑到底返回的是哪一个子类的实例。
代理模式:给一个对象提供一个代理对象,并由代理对象控制原对象的引用。实际开发中,按照使用目的的不同,代理可以分为:远程代理、虚拟代理、保护代理、Cache 代理、防火墙代理、同步化代理、智能引用代理。
适配器模式:把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起使用的类能够一起工作。
模板方法模式:提供一个抽象类,将部分逻辑以具体方法或构造器的形式实现,然后声明一些抽象方法来迫使子类实现剩余的逻辑。不同的子类可以以不同的方式实现这些抽象方法(多态实现),从而实现不同的业务逻辑。
除此之外,还可以讲讲上面提到的门面模式、桥梁模式、单例模式、装潢模式(Collections 工具类和 I/O 系统中都使用装潢模式)等,反正基本原则就是拣自己最熟悉的、用得最多的作答,以免言多必失。
91、用 Java 写一个单例类。
饿汉式单例:
public class Singleton {
private Singleton(){}
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
}懒汉式单例:
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static synchronized Singleton getInstance(){
if (instance == null) instance = new Singleton();
return instance;
}
}
注意:实现一个单例有两点注意事项,①将构造器私有,不允许外界通过构造器创建对象;②通过公开的静态方法向外界返回类的唯一实例。这里有一个问题可以思考:Spring 的 IoC 容器可以为普通的类创建单例,它是怎么做到的呢?
92、什么是 UML?
UML 是统一建模语言(Unified Modeling Language)的缩写,它发表于 1997年,综合了当时已经存在的面向对象的建模语言、方法和过程,是一个支持模型化和软件系统开发的图形化语言,为软件开发的所有阶段提供模型化和可视化支持。使用 UML 可以帮助沟通与交流,辅助应用设计和文档的生成,还能够阐释系统的结构和行为。
93、UML 中有哪些常用的图?
UML 定义了多种图形化的符号来描述软件系统部分或全部的静态结构和动态结构,包括:用例图(use case diagram)、类图(class diagram)、时序图(sequence diagram)、协作图(collaboration diagram)、状态图(statechart diagram)、活动图(activity diagram)、构件图(component diagram)、部署图(deployment diagram)等。在这些图形化符号中,有三种图最为重要,分别是:用例图(用来捕获需求,描述系统的功能,通过该图可以迅速的了解系统的功能模块及其关系)、类图(描述类以及类与类之间的关系,通过该图可以快速了解系统)、时序图(描述执行特定任务时对象之间的交互关系以及执行顺序,通过该图可以了解对象能接收的消息也就是说对象能够向外界提供的服务)。
用例图:
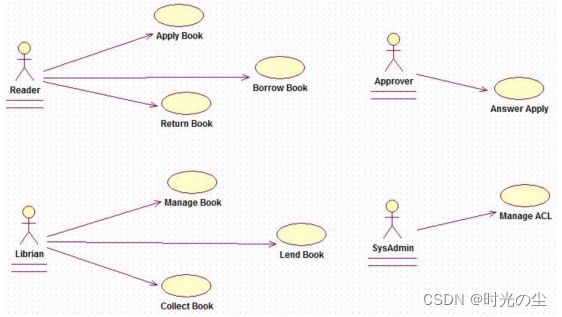
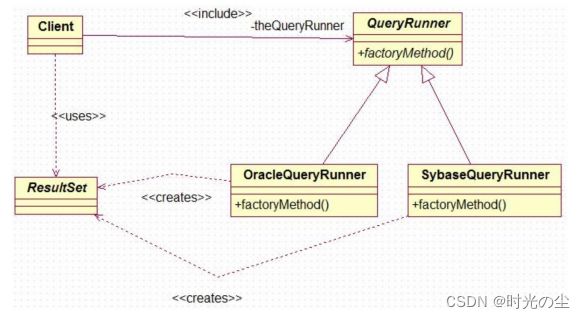
类图:
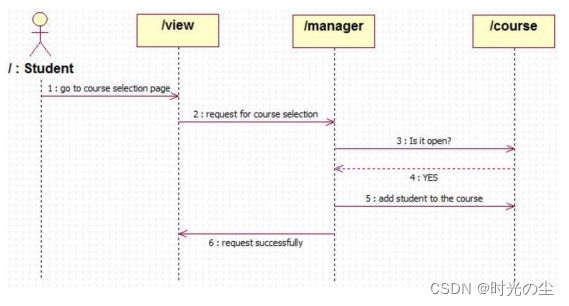
时序图:
94、用 Java 写一个冒泡排序。
冒泡排序几乎是个程序员都写得出来,但是面试的时候如何写一个逼格高的冒泡排序却不是每个人都能做到,下面提供一个参考代码:
import java.util.Comparator;
public interface Sorter {
/**
* 排序
* @param list 待排序的数组
*/
public > void sort(T[] list);
/**
* 排序
* @param list 待排序的数组
* @param comp 比较两个对象的比较器
*/
public void sort(T[] list, Comparator comp);
}
import java.util.Comparator;
/**
* 冒泡排序
*
*/
public class BubbleSorter implements Sorter {
@Override
public > void sort(T[] list) {
boolean swapped = true;
for (int i = 1, len = list.length; i < len && swapped; ++i) {
swapped = false;
for (int j = 0; j < len - i; ++j) {
if (list[j].compareTo(list[j + 1]) > 0) {
T temp = list[j];
list[j] = list[j + 1];
list[j + 1] = temp;
swapped = true;
}
}
}
}
@Override
public void sort(T[] list, Comparator comp) {
boolean swapped = true;
for (int i = 1, len = list.length; i < len && swapped; ++i) {
swapped = false;
for (int j = 0; j < len - i; ++j) {
if (comp.compare(list[j], list[j + 1]) > 0) {
T temp = list[j];
list[j] = list[j + 1];
list[j + 1] = temp;
swapped = true;
}
}
}
}
} 95、用 Java 写一个折半查找。
折半查找,也称二分查找、二分搜索,是一种在有序数组中查找某一特定元素的搜索算法。搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组已经为空,则表示找不到指定的元素。这种搜索算法每一次比较都使搜索范围缩小一半,其时间复杂度是 O(logN)。
import java.util.Comparator;
public class MyUtil {
public static > int binarySearch(T[] x, Tkey) {
return binarySearch(x, 0, x.length- 1, key);
}
// 使用循环实现的二分查找
public static int binarySearch(T[] x, T key, Comparator comp)
{
int low = 0;
int high = x.length - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int cmp = comp.compare(x[mid], key);
if (cmp < 0) {
low= mid + 1;
}
else if (cmp > 0) {
high= mid - 1;
}
else {
return mid;
}
}
return -1;
}
// 使用递归实现的二分查找
private static> int binarySearch(T[] x, int low, int high, T key) {
if(low <= high) {
int mid = low + ((high -low) >> 1);
if(key.compareTo(x[mid])== 0) {
return mid;
}
else if(key.compareTo(x[mid])< 0) {
return binarySearch(x,low, mid - 1, key);
}
else {
return binarySearch(x,mid + 1, high, key);
}
}
return -1;
}
} 说明:上面的代码中给出了折半查找的两个版本,一个用递归实现,一个用循环实现。需要注意的是计算中间位置时不应该使用(high+ low) / 2 的方式,因为加法运算可能导致整数越界,这里应该使用以下三种方式之一:low + (high - low)/ 2 或 low + (high – low) >> 1 或(low + high) >>> 1(>>>是逻辑右移,是不带符号位的右移)
要想了解更多:
千题千解·Java面试宝典_时光の尘的博客-CSDN博客
