GaussDB学习笔记
系统表
pg_users
pg_database
pg_tables
pg_tablespace
pg_statistic
在PG_TABLES系统表中查看public Schema中包含的前缀为search_table的表
gaussdb=#
SELECT distinct(tablename) FROM pg_tables WHERE SCHEMANAME = 'public' AND TABLENAME LIKE 'search_table%';
查看和停止正在运行的查询语句
通过视图PG_STAT_ACTIVITY可以查看正在运行的查询语句。方法如下:
设置参数track_activities为on。
SET track_activities = on;
当此参数为on时,数据库系统才会收集当前活动查询的运行信息。
查看正在运行的查询语句。以查看正在运行的查询语句所连接的数据库名、执行查询的用户、查询状态及查询对应的PID为例:
SELECT datname, usename, state,pid FROM pg_stat_activity;
如果state字段显示为idle,则表明此连接处于空闲,等待用户输入命令。
如果仅需要查看非空闲的查询语句,则使用如下命令查看:
SELECT datname, usename, state, pid FROM pg_stat_activity WHERE state != 'idle';
若需要取消运行时间过长的查询,通过PG_TERMINATE_BACKEND函数,根据线程ID(即2中查询结果的pid字段)结束会话。
SELECT PG_TERMINATE_BACKEND(12800);
查看最耗时SQL
SELECT current_timestamp - query_start AS runtime, datname, usename, query FROM pg_stat_activity where state != 'idle' ORDER BY 1 desc;
使用gsql的\d+命令查询表的属性
gaussdb=# \d+ customer_t1;
执行如下命令将搜索路径设置为myschema、public,首先搜索myschema。
gaussdb=#
SET SEARCH_PATH TO myschema, public;
撤销PUBLIC在public模式下创建对象的权限,下面语句中第一个“public”是模式,第二个“PUBLIC”指的是所有角色。
gaussdb=#
REVOKE CREATE ON SCHEMA public FROM PUBLIC;
执行如下命令查询系统和用户定义的所有索引。
gaussdb=#
SELECT RELNAME FROM PG_CLASS WHERE RELKIND='i';
更新统计信息
ANALYZE tablename; --更新单个表的统计信息
ANALYZE; --更新全库的统计信息
表的选择
1.行存储
默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常更新的场景
gaussdb=# CREATE TABLE customer_t1
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
);
--删除表
gaussdb=# DROP TABLE customer_t1;
2列存储
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。
gaussdb=# CREATE TABLE customer_t2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
--删除表
gaussdb=# DROP TABLE customer_t2;
3行存表和列存表的选择
更新频繁程度
数据如果频繁更新,选择行存表。
插入频繁程度
频繁的少量插入,选择行存表。一次插入大批量数据,选择列存表。
表的列数
表的列数很多,选择列存表。
查询的列数
如果每次查询时,只涉及了表的少数(<50%总列数)几个列,选择列存表。
压缩率
列存表比行存表压缩率高。但高压缩率会消耗更多的CPU资源。
表设计
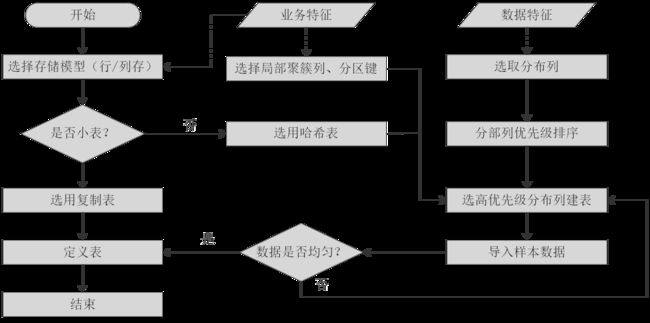
在分布式框架下,数据分布在各个DN上。一个或者几个DN的数据存在一块物理存储设备上,好的表定义至少需要达到以下几个目标:
表数据均匀分布在各个DN上,以防止单个DN对应的存储设备空间不足造成集群有效容量下降。选择合适分布列,避免数据分布倾斜可以实现该点。
1.表Scan压力均匀分散在各个DN上,以避免单DN的Scan压力过大,形成Scan的单节点瓶颈。
2.分布列不选择基表上等值filter中的列可以实现该点。
3.减少扫描数据数据量。通过分区的剪枝机制可以实现该点。
4.尽量极少随机IO。通过聚簇/局部聚簇可以实现该点。
5.尽量避免数据shuffle,减小网络压力。通过选择join-condition或者group by列为分布列可以更好的实现这点。
1.选择存储模型
表的存储模型选择是表定义的第一步。客户业务属性是表的存储模型的决定性因素,依据下面表格选择适合当前业务的存储模型。
| 存储模型 | 适用场景 |
|---|---|
| 行存 | 点查询(返回记录少,基于索引的简单查询)。增删改比较多的场景 |
| 列存 | 统计分析类查询 (group , join多的场景) |
2.选择分布方式
复制表(Replication)方式将表中的全量数据在集群的每一个DN实例上保留一份。主要适用于记录集较小的表。这种存储方式的优点是每个DN上都有该表的全量数据,在join操作中可以避免数据重分布操作,从而减小网络开销,同时减少了plan segment(每个plan segment都会起对应的线程);缺点是每个DN都保留了表的完整数据,造成数据的冗余。一般情况下只有较小的维度表才会定义为Replication表。
哈希(Hash)表将表中某一个或几个字段进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置。对于Hash分布表,在读/写数据时可以利用各个节点的IO资源,大大提升表的读/写速度。一般情况下大表定义为Hash表。
范围(Range)和列表(List)分布是由用户自定义的分布策略,根据分布列的取值落入满足一定范围或者具体值的对应目标DN,这两种分布方式便于用户灵活地进行数据管理,但对用户本身的数据抽象能力有一定的要求。

复制表和哈希表

3.选择分布列
Hash分布表的分布列选取至关重要,需要满足以下原则:
1.列值应比较离散,以便数据能够均匀分布到各个DN。例如,考虑选择表的主键为分布列,如在人员信息表中选择身份证号码为分布列。
2.在满足第一条原则的情况下尽量不要选取存在常量filter的列。例如,表dwcjk相关的部分查询中出现dwcjk的列zqdh存在常量的约束(例如zqdh=’000001’),那么就应当尽量不用zqdh做分布列。
3.在满足前两条原则的情况,考虑选择查询中的连接条件为分布列,以便Join任务能够下推到DN中执行,且减少DN之间的通信数据量。
对于Hash分表策略,如果分布列选择不当,可能导致数据倾斜,查询时出现部分DN的I/O短板,从而影响整体查询性能。因此在采用Hash分表策略之后需对表的数据进行数据倾斜性检查,以确保数据在各个DN上是均匀分布的。可以使用以下SQL检查数据倾斜性
select
xc_node_id, count(1)
from tablename
group by xc_node_id
order by xc_node_id desc;
其中xc_node_id对应DN,一般来说,不同DN的数据量相差5%以上即可视为倾斜,如果相差10%以上就必须要调整分布列。
GaussDB支持多分布列特性,可以更好地满足数据分布的均匀性要求。
4.使用局部聚簇
局部聚簇(Partial Cluster Key)是列存下的一种技术。这种技术可以通过min/max稀疏索引较快的实现基表扫描的filter过滤。Partial Cluster Key可以指定多列,但是一般不建议超过2列
5.使用分区表
分区表是把逻辑上的一张表根据某种方案分成几张物理块进行存储。这张逻辑上的表称之为分区表,物理块称之为分区。分区表是一张逻辑表,不存储数据,数据实际是存储在分区上的。分区表和普通表相比具有以下优点:
- 改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索效率。
- 增强可用性:如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
- 方便维护:如果分区表的某个分区出现故障,需要修复数据,只修复该分区即可。
GaussDB支持的分区表为范围分区表。
范围分区表: 将数据基于范围映射到每一个分区。这个范围是由创建分区表时指定的分区键决定的。分区键经常采用日期,例如将销售数据按照月份进行分区
6.选择数据类型
高效数据类型,主要包括以下三方面:
- 尽量使用执行效率比较高的数据类型
一般来说整型数据运算(包括=、>、<、≧、≦、≠等常规的比较运算,以及group by)的效率比字符串、浮点数要高。比如某客户场景中对列存表进行点查询,filter条件在一个numeric列上,执行时间为10+s;修改numeric为int类型之后,执行时间缩短为1.8s左右。 - 尽量使用短字段的数据类型
长度较短的数据类型不仅可以减小数据文件的大小,提升IO性能;同时也可以减小相关计算时的内存消耗,提升计算性能。比如对于整型数据,如果可以用smallint就尽量不用int,如果可以用int就尽量不用bigint。 - 使用一致的数据类型
表关联列尽量使用相同的数据类型。如果表关联列数据类型不同,数据库必须动态地转化为相同的数据类型进行比较,这种转换会带来一定的性能开销
创建和管理分区表
GaussDB Kernel数据库支持的分区表为范围分区表,列表分区表,哈希分区表。
范围分区表:将数据基于范围映射到每一个分区,这个范围是由创建分区表时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期,例如将销售数据按照月份进行分区。
列表分区表:将数据中包含的键值分别存储在不同的分区中,依次将数据映射到每一个分区,分区中包含的键值由创建分区表时指定。
哈希分区表:将数据根据内部哈希算法依次映射到每一个分区中,包含的分区个数由创建分区表时指定。
分区表和普通表相比具有以下优点:
改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索效率。
增强可用性:如果分区表的某个分区出现故障,表在其他分区的数据仍然可用。
方便维护:如果分区表的某个分区出现故障,需要修复数据,只修复该分区即可。
均衡I/O:可以把不同的分区映射到不同的磁盘以平衡I/O,改善整个系统性能。
普通表若要转成分区表,需要新建分区表,然后把普通表中的数据导入到新建的分区表中。因此在初始设计表时,请根据业务提前规划是否使用分区表
创建和管理索引
索引可以提高数据的访问速度,但同时也增加了插入、更新和删除操作的处理时间。所以是否要为表增加索引,索引建立在哪些字段上,是创建索引前必须要考虑的问题。需要分析应用程序的业务处理、数据使用、经常被用作查询的条件或者被要求排序的字段来确定是否建立索引。
索引建立在数据库表中的某些列上。因此,在创建索引时,应该仔细考虑在哪些列上创建索引。
在经常需要搜索查询的列上创建索引,可以加快搜索的速度。
在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列结构。
在经常使用连接的列上创建索引,可以加快连接的速度。
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
在经常使用WHERE子句的列上创建索引,加快条件的判断速度。
为经常出现在关键字ORDER BY、GROUP BY、DISTINCT后面的字段建立索引。
优化
1.批量更新或删除数据后,会在数据文件中产生大量的删除标记,查询过程中标记删除的数据也是需要扫描的。故多次批量更新/删除后,标记删除的数据量过大会严重影响查询的性能。建议在批量更新/删除业务会反复执行的场景下,定期执行VACUUM FULL以保持查询性能。