【MapReduce】Mapreduce基础知识整理 (三) shuffle机制、MapJoin、ReduceJoin、倒排序索引
目录
- 1. Mapreduce的Shuffle机制
-
- 1.1概述
- 1.2 shuffle分析
-
- 1.2.1 主要工作流程
- 1.2.2 环形缓冲区
- 1.2.3 详细工作流程
- 2. Map Join 和 Reduce Join
-
- 2.1 表关联
- 2.2 Reduce Join
- 2.3 Map Join
- 2.4 利用hadoop 进行倒排索引
【MapReduce】Mapreduce基础知识整理(一)
1. Mapreduce的Shuffle机制
1.1概述
一个mapreduce过程:
map——>shuffle(排序、分组、分区、combiner)——>reduce
- MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle
- Shuffle: 数据混洗 ——(核心机制:数据分区,排序,局部聚合,缓存,拉取,再合并 排序)
- 具体来说:就是将 MapTask 输出的处理结果数据,按照 Partitioner 组件制定的规则分发 给 ReduceTask,并在分发的过程中,对数据按 key 进行了分区和排序
shuffle过程三大组件及一优化组件的使用案例请点击
1.2 shuffle分析
1.2.1 主要工作流程
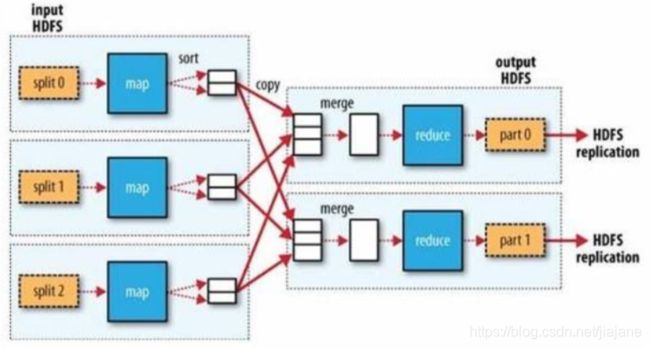

Shuffle 是 MapReduce 处理流程中的一个核心过程,它的每一个处理步骤是分散在各个 maptask 和 reducetask 节点上完成的,整体来看,分为核心 3 个操作:
1、分区 partition(如果 reduceTask 只有一个或者没有,那么 partition 将不起作用。设置没 设置都相当于没有)
2、Sort 根据 key 排序(MapReduce 编程中的 sort 是一定会做的,并且只能按照 key 排序, 当然如果没有 reducer 阶段,那么就不会对 key 排序)
3、Combiner 进行局部 value 的合并(Combiner 是可选的组件,作用只是为了提高任务的执 行效率)
说细流程:
- mapTask 收集我们的 map()方法输出的 kv 对,放到内存缓冲区 kvbuffer(环形缓冲区:内 存中的一种首尾相连的数据结构,kvbuffer 包含数据区和索引区)中
- 从内存缓冲区中的数据区的数据不断溢出本地磁盘文件 file.out,可能会溢出多次,则会 有多个文件,相应的内存缓冲区中的索引区数据溢出为磁盘索引文件 file.out.index
- 多个溢出文件会被合并成大的溢出文件
- 在溢出过程中,及合并的过程中,都要调用 partitoner 进行分区和针对 key 进行排序
- 在数据量大的时候,可以对 mapTask 结果启用压缩,将 mapreduce.map.output.compress 设为 true,并使用 mapreduce.map.output.compress.codec 设置使用的压缩算法,可以提高数 据传输到 reducer 端的效率
- reduceTask 根据自己的分区号,去各个 mapTask 机器上取相应的结果分区数据
- reduceTask 会取到同一个分区的来自不同 mapTask 的结果文件,reduceTask 会将这些文 件再进行合并(归并排序)
- 合并成大文件后,shuffle 的过程也就结束了,后面进入 reduceTask 的逻辑运算过程(从 文件中取出一个一个的键值对 group,调用用户自定义的 reduce()方法)
Shuffle 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大,磁 盘 io 的次数越少,执行速度就越快 缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb 默认 100M 缓冲区的溢写比也可以通过参数调整,参数:mapreduce.map.sort.spill.percent 默认 0.8
1.2.2 环形缓冲区
先看一下源码:
org.apache.hadoop.mapred.MapTask#MapOutputBuffer
public static class MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable {
private int partitions;
private JobConf job;
private TaskReporter reporter;
private Class<K> keyClass;
private Class<V> valClass;
private RawComparator<K> comparator;
private SerializationFactory serializationFactory;
private Serializer<K> keySerializer;
private Serializer<V> valSerializer;
private CombinerRunner<K,V> combinerRunner;
private CombineOutputCollector<K, V> combineCollector;
// Compression for map-outputs
private CompressionCodec codec;
// k/v accounting
private IntBuffer kvmeta; // metadata overlay on backing store
int kvstart; // marks origin of spill metadata
int kvend; // marks end of spill metadata
int kvindex; // marks end of fully serialized records
int equator; // marks origin of meta/serialization
int bufstart; // marks beginning of spill
int bufend; // marks beginning of collectable
int bufmark; // marks end of record
int bufindex; // marks end of collected
int bufvoid; // marks the point where we should stop
// reading at the end of the buffer
byte[] kvbuffer; // main output buffer
private final byte[] b0 = new byte[0];
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3; // length of value
private static final int NMETA = 4; // num meta ints
private static final int METASIZE = NMETA * 4; // size in bytes
// spill accounting
private int maxRec;
private int softLimit;
boolean spillInProgress;;
int bufferRemaining;
volatile Throwable sortSpillException = null;
int numSpills = 0;
private int minSpillsForCombine;
private IndexedSorter sorter;
final ReentrantLock spillLock = new ReentrantLock();
final Condition spillDone = spillLock.newCondition();
final Condition spillReady = spillLock.newCondition();
final BlockingBuffer bb = new BlockingBuffer();
volatile boolean spillThreadRunning = false;
final SpillThread spillThread = new SpillThread();
private FileSystem rfs;
// Counters
private Counters.Counter mapOutputByteCounter;
private Counters.Counter mapOutputRecordCounter;
private Counters.Counter fileOutputByteCounter;
final ArrayList<SpillRecord> indexCacheList =
new ArrayList<SpillRecord>();
private int totalIndexCacheMemory;
private int indexCacheMemoryLimit;
private static final int INDEX_CACHE_MEMORY_LIMIT_DEFAULT = 1024 * 1024;
private MapTask mapTask;
private MapOutputFile mapOutputFile;
private Progress sortPhase;
private Counters.Counter spilledRecordsCounter;
public MapOutputBuffer() {
}
@SuppressWarnings("unchecked")
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
int maxMemUsage = sortmb << 20;
maxMemUsage -= maxMemUsage % METASIZE;
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// output counters
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
// combiner
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
spillInProgress = false;
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}
/**
* Serialize the key, value to intermediate storage.
* When this method returns, kvindex must refer to sufficient unused
* storage to store one METADATA.
*/
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; must make contiguous
bb.shiftBufferedKey();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
// It's possible for records to have zero length, i.e. the serializer
// will perform no writes. To ensure that the boundary conditions are
// checked and that the kvindex invariant is maintained, perform a
// zero-length write into the buffer. The logic monitoring this could be
// moved into collect, but this is cleaner and inexpensive. For now, it
// is acceptable.
bb.write(b0, 0, 0);
// the record must be marked after the preceding write, as the metadata
// for this record are not yet written
int valend = bb.markRecord();
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(
distanceTo(keystart, valend, bufvoid));
// write accounting info
kvmeta.put(kvindex + PARTITION, partition);
kvmeta.put(kvindex + KEYSTART, keystart);
kvmeta.put(kvindex + VALSTART, valstart);
kvmeta.put(kvindex + VALLEN, distanceTo(valstart, valend));
// advance kvindex
kvindex = (kvindex - NMETA + kvmeta.capacity()) % kvmeta.capacity();
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}
private TaskAttemptID getTaskID() {
return mapTask.getTaskID();
}
/**
* Set the point from which meta and serialization data expand. The meta
* indices are aligned with the buffer, so metadata never spans the ends of
* the circular buffer.
*/
private void setEquator(int pos) {
equator = pos;
// set index prior to first entry, aligned at meta boundary
final int aligned = pos - (pos % METASIZE);
// Cast one of the operands to long to avoid integer overflow
kvindex = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(EQUATOR) " + pos + " kvi " + kvindex +
"(" + (kvindex * 4) + ")");
}
/**
* The spill is complete, so set the buffer and meta indices to be equal to
* the new equator to free space for continuing collection. Note that when
* kvindex == kvend == kvstart, the buffer is empty.
*/
private void resetSpill() {
final int e = equator;
bufstart = bufend = e;
final int aligned = e - (e % METASIZE);
// set start/end to point to first meta record
// Cast one of the operands to long to avoid integer overflow
kvstart = kvend = (int)
(((long)aligned - METASIZE + kvbuffer.length) % kvbuffer.length) / 4;
LOG.info("(RESET) equator " + e + " kv " + kvstart + "(" +
(kvstart * 4) + ")" + " kvi " + kvindex + "(" + (kvindex * 4) + ")");
}
/**
* Compute the distance in bytes between two indices in the serialization
* buffer.
* @see #distanceTo(int,int,int)
*/
final int distanceTo(final int i, final int j) {
return distanceTo(i, j, kvbuffer.length);
}
/**
* Compute the distance between two indices in the circular buffer given the
* max distance.
*/
int distanceTo(final int i, final int j, final int mod) {
return i <= j
? j - i
: mod - i + j;
}
/**
* For the given meta position, return the offset into the int-sized
* kvmeta buffer.
*/
int offsetFor(int metapos) {
return metapos * NMETA;
}
/**
* Compare logical range, st i, j MOD offset capacity.
* Compare by partition, then by key.
* @see IndexedSortable#compare
*/
public int compare(final int mi, final int mj) {
final int kvi = offsetFor(mi % maxRec);
final int kvj = offsetFor(mj % maxRec);
final int kvip = kvmeta.get(kvi + PARTITION);
final int kvjp = kvmeta.get(kvj + PARTITION);
// sort by partition
if (kvip != kvjp) {
return kvip - kvjp;
}
// sort by key
return comparator.compare(kvbuffer,
kvmeta.get(kvi + KEYSTART),
kvmeta.get(kvi + VALSTART) - kvmeta.get(kvi + KEYSTART),
kvbuffer,
kvmeta.get(kvj + KEYSTART),
kvmeta.get(kvj + VALSTART) - kvmeta.get(kvj + KEYSTART));
}
final byte META_BUFFER_TMP[] = new byte[METASIZE];
/**
* Swap metadata for items i, j
* @see IndexedSortable#swap
*/
public void swap(final int mi, final int mj) {
int iOff = (mi % maxRec) * METASIZE;
int jOff = (mj % maxRec) * METASIZE;
System.arraycopy(kvbuffer, iOff, META_BUFFER_TMP, 0, METASIZE);
System.arraycopy(kvbuffer, jOff, kvbuffer, iOff, METASIZE);
System.arraycopy(META_BUFFER_TMP, 0, kvbuffer, jOff, METASIZE);
}
/**
* Inner class managing the spill of serialized records to disk.
*/
protected class BlockingBuffer extends DataOutputStream {
public BlockingBuffer() {
super(new Buffer());
}
/**
* Mark end of record. Note that this is required if the buffer is to
* cut the spill in the proper place.
*/
public int markRecord() {
bufmark = bufindex;
return bufindex;
}
/**
* Set position from last mark to end of writable buffer, then rewrite
* the data between last mark and kvindex.
* This handles a special case where the key wraps around the buffer.
* If the key is to be passed to a RawComparator, then it must be
* contiguous in the buffer. This recopies the data in the buffer back
* into itself, but starting at the beginning of the buffer. Note that
* this method should only be called immediately after detecting
* this condition. To call it at any other time is undefined and would
* likely result in data loss or corruption.
* @see #markRecord()
*/
protected void shiftBufferedKey() throws IOException {
// spillLock unnecessary; both kvend and kvindex are current
int headbytelen = bufvoid - bufmark;
bufvoid = bufmark;
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
final int avail =
Math.min(distanceTo(0, kvbidx), distanceTo(0, kvbend));
if (bufindex + headbytelen < avail) {
System.arraycopy(kvbuffer, 0, kvbuffer, headbytelen, bufindex);
System.arraycopy(kvbuffer, bufvoid, kvbuffer, 0, headbytelen);
bufindex += headbytelen;
bufferRemaining -= kvbuffer.length - bufvoid;
} else {
byte[] keytmp = new byte[bufindex];
System.arraycopy(kvbuffer, 0, keytmp, 0, bufindex);
bufindex = 0;
out.write(kvbuffer, bufmark, headbytelen);
out.write(keytmp);
}
}
}
public class Buffer extends OutputStream {
private final byte[] scratch = new byte[1];
@Override
public void write(int v)
throws IOException {
scratch[0] = (byte)v;
write(scratch, 0, 1);
}
/**
* Attempt to write a sequence of bytes to the collection buffer.
* This method will block if the spill thread is running and it
* cannot write.
* @throws MapBufferTooSmallException if record is too large to
* deserialize into the collection buffer.
*/
@Override
public void write(byte b[], int off, int len)
throws IOException {
// must always verify the invariant that at least METASIZE bytes are
// available beyond kvindex, even when len == 0
bufferRemaining -= len;
if (bufferRemaining <= 0) {
// writing these bytes could exhaust available buffer space or fill
// the buffer to soft limit. check if spill or blocking are necessary
boolean blockwrite = false;
spillLock.lock();
try {
do {
checkSpillException();
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// ser distance to key index
final int distkvi = distanceTo(bufindex, kvbidx);
// ser distance to spill end index
final int distkve = distanceTo(bufindex, kvbend);
// if kvindex is closer than kvend, then a spill is neither in
// progress nor complete and reset since the lock was held. The
// write should block only if there is insufficient space to
// complete the current write, write the metadata for this record,
// and write the metadata for the next record. If kvend is closer,
// then the write should block if there is too little space for
// either the metadata or the current write. Note that collect
// ensures its metadata requirement with a zero-length write
blockwrite = distkvi <= distkve
? distkvi <= len + 2 * METASIZE
: distkve <= len || distanceTo(bufend, kvbidx) < 2 * METASIZE;
if (!spillInProgress) {
if (blockwrite) {
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
// need to use meta exclusively; zero-len rec & 100% spill
// pcnt would fail
resetSpill(); // resetSpill doesn't move bufindex, kvindex
bufferRemaining = Math.min(
distkvi - 2 * METASIZE,
softLimit - distanceTo(kvbidx, bufindex)) - len;
continue;
}
// we have records we can spill; only spill if blocked
if (kvindex != kvend) {
startSpill();
// Blocked on this write, waiting for the spill just
// initiated to finish. Instead of repositioning the marker
// and copying the partial record, we set the record start
// to be the new equator
setEquator(bufmark);
} else {
// We have no buffered records, and this record is too large
// to write into kvbuffer. We must spill it directly from
// collect
final int size = distanceTo(bufstart, bufindex) + len;
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
bufvoid = kvbuffer.length;
throw new MapBufferTooSmallException(size + " bytes");
}
}
}
if (blockwrite) {
// wait for spill
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException(
"Buffer interrupted while waiting for the writer", e);
}
}
} while (blockwrite);
} finally {
spillLock.unlock();
}
}
// here, we know that we have sufficient space to write
if (bufindex + len > bufvoid) {
final int gaplen = bufvoid - bufindex;
System.arraycopy(b, off, kvbuffer, bufindex, gaplen);
len -= gaplen;
off += gaplen;
bufindex = 0;
}
System.arraycopy(b, off, kvbuffer, bufindex, len);
bufindex += len;
}
}
public void flush() throws IOException, ClassNotFoundException,
InterruptedException {
LOG.info("Starting flush of map output");
if (kvbuffer == null) {
LOG.info("kvbuffer is null. Skipping flush.");
return;
}
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
assert !spillLock.isHeldByCurrentThread();
// shut down spill thread and wait for it to exit. Since the preceding
// ensures that it is finished with its work (and sortAndSpill did not
// throw), we elect to use an interrupt instead of setting a flag.
// Spilling simultaneously from this thread while the spill thread
// finishes its work might be both a useful way to extend this and also
// sufficient motivation for the latter approach.
try {
spillThread.interrupt();
spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
// release sort buffer before the merge
kvbuffer = null;
mergeParts();
Path outputPath = mapOutputFile.getOutputFile();
fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen());
}
public void close() { }
protected class SpillThread extends Thread {
@Override
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
private void checkSpillException() throws IOException {
final Throwable lspillException = sortSpillException;
if (lspillException != null) {
if (lspillException instanceof Error) {
final String logMsg = "Task " + getTaskID() + " failed : " +
StringUtils.stringifyException(lspillException);
mapTask.reportFatalError(getTaskID(), lspillException, logMsg);
}
throw new IOException("Spill failed", lspillException);
}
}
private void startSpill() {
assert !spillInProgress;
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
spillInProgress = true;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
spillReady.signal();
}
private void sortAndSpill() throws IOException, ClassNotFoundException,
InterruptedException {
//approximate the length of the output file to be the length of the
//buffer + header lengths for the partitions
final long size = distanceTo(bufstart, bufend, bufvoid) +
partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
final int mstart = kvend / NMETA;
final int mend = 1 + // kvend is a valid record
(kvstart >= kvend
? kvstart
: kvmeta.capacity() + kvstart) / NMETA;
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
int spindex = mstart;
final IndexRecord rec = new IndexRecord();
final InMemValBytes value = new InMemValBytes();
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
writer = new Writer<K, V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null) {
// spill directly
DataInputBuffer key = new DataInputBuffer();
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec) + PARTITION) == i) {
final int kvoff = offsetFor(spindex % maxRec);
int keystart = kvmeta.get(kvoff + KEYSTART);
int valstart = kvmeta.get(kvoff + VALSTART);
key.reset(kvbuffer, keystart, valstart - keystart);
getVBytesForOffset(kvoff, value);
writer.append(key, value);
++spindex;
}
} else {
int spstart = spindex;
while (spindex < mend &&
kvmeta.get(offsetFor(spindex % maxRec)
+ PARTITION) == i) {
++spindex;
}
// Note: we would like to avoid the combiner if we've fewer
// than some threshold of records for a partition
if (spstart != spindex) {
combineCollector.setWriter(writer);
RawKeyValueIterator kvIter =
new MRResultIterator(spstart, spindex);
combinerRunner.combine(kvIter, combineCollector);
}
}
// close the writer
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} finally {
if (null != writer) writer.close();
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
LOG.info("Finished spill " + numSpills);
++numSpills;
} finally {
if (out != null) out.close();
}
}
/**
* Handles the degenerate case where serialization fails to fit in
* the in-memory buffer, so we must spill the record from collect
* directly to a spill file. Consider this "losing".
*/
private void spillSingleRecord(final K key, final V value,
int partition) throws IOException {
long size = kvbuffer.length + partitions * APPROX_HEADER_LENGTH;
FSDataOutputStream out = null;
try {
// create spill file
final SpillRecord spillRec = new SpillRecord(partitions);
final Path filename =
mapOutputFile.getSpillFileForWrite(numSpills, size);
out = rfs.create(filename);
// we don't run the combiner for a single record
IndexRecord rec = new IndexRecord();
for (int i = 0; i < partitions; ++i) {
IFile.Writer<K, V> writer = null;
try {
long segmentStart = out.getPos();
// Create a new codec, don't care!
FSDataOutputStream partitionOut = CryptoUtils.wrapIfNecessary(job, out);
writer = new IFile.Writer<K,V>(job, partitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (i == partition) {
final long recordStart = out.getPos();
writer.append(key, value);
// Note that our map byte count will not be accurate with
// compression
mapOutputByteCounter.increment(out.getPos() - recordStart);
}
writer.close();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, i);
writer = null;
} catch (IOException e) {
if (null != writer) writer.close();
throw e;
}
}
if (totalIndexCacheMemory >= indexCacheMemoryLimit) {
// create spill index file
Path indexFilename =
mapOutputFile.getSpillIndexFileForWrite(numSpills, partitions
* MAP_OUTPUT_INDEX_RECORD_LENGTH);
spillRec.writeToFile(indexFilename, job);
} else {
indexCacheList.add(spillRec);
totalIndexCacheMemory +=
spillRec.size() * MAP_OUTPUT_INDEX_RECORD_LENGTH;
}
++numSpills;
} finally {
if (out != null) out.close();
}
}
/**
* Given an offset, populate vbytes with the associated set of
* deserialized value bytes. Should only be called during a spill.
*/
private void getVBytesForOffset(int kvoff, InMemValBytes vbytes) {
// get the keystart for the next serialized value to be the end
// of this value. If this is the last value in the buffer, use bufend
final int vallen = kvmeta.get(kvoff + VALLEN);
assert vallen >= 0;
vbytes.reset(kvbuffer, kvmeta.get(kvoff + VALSTART), vallen);
}
/**
* Inner class wrapping valuebytes, used for appendRaw.
*/
protected class InMemValBytes extends DataInputBuffer {
private byte[] buffer;
private int start;
private int length;
public void reset(byte[] buffer, int start, int length) {
this.buffer = buffer;
this.start = start;
this.length = length;
if (start + length > bufvoid) {
this.buffer = new byte[this.length];
final int taillen = bufvoid - start;
System.arraycopy(buffer, start, this.buffer, 0, taillen);
System.arraycopy(buffer, 0, this.buffer, taillen, length-taillen);
this.start = 0;
}
super.reset(this.buffer, this.start, this.length);
}
}
protected class MRResultIterator implements RawKeyValueIterator {
private final DataInputBuffer keybuf = new DataInputBuffer();
private final InMemValBytes vbytes = new InMemValBytes();
private final int end;
private int current;
public MRResultIterator(int start, int end) {
this.end = end;
current = start - 1;
}
public boolean next() throws IOException {
return ++current < end;
}
public DataInputBuffer getKey() throws IOException {
final int kvoff = offsetFor(current % maxRec);
keybuf.reset(kvbuffer, kvmeta.get(kvoff + KEYSTART),
kvmeta.get(kvoff + VALSTART) - kvmeta.get(kvoff + KEYSTART));
return keybuf;
}
public DataInputBuffer getValue() throws IOException {
getVBytesForOffset(offsetFor(current % maxRec), vbytes);
return vbytes;
}
public Progress getProgress() {
return null;
}
public void close() { }
}
private void mergeParts() throws IOException, InterruptedException,
ClassNotFoundException {
// get the approximate size of the final output/index files
long finalOutFileSize = 0;
long finalIndexFileSize = 0;
final Path[] filename = new Path[numSpills];
final TaskAttemptID mapId = getTaskID();
for(int i = 0; i < numSpills; i++) {
filename[i] = mapOutputFile.getSpillFile(i);
finalOutFileSize += rfs.getFileStatus(filename[i]).getLen();
}
if (numSpills == 1) { //the spill is the final output
sameVolRename(filename[0],
mapOutputFile.getOutputFileForWriteInVolume(filename[0]));
if (indexCacheList.size() == 0) {
sameVolRename(mapOutputFile.getSpillIndexFile(0),
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]));
} else {
indexCacheList.get(0).writeToFile(
mapOutputFile.getOutputIndexFileForWriteInVolume(filename[0]), job);
}
sortPhase.complete();
return;
}
// read in paged indices
for (int i = indexCacheList.size(); i < numSpills; ++i) {
Path indexFileName = mapOutputFile.getSpillIndexFile(i);
indexCacheList.add(new SpillRecord(indexFileName, job));
}
//make correction in the length to include the sequence file header
//lengths for each partition
finalOutFileSize += partitions * APPROX_HEADER_LENGTH;
finalIndexFileSize = partitions * MAP_OUTPUT_INDEX_RECORD_LENGTH;
Path finalOutputFile =
mapOutputFile.getOutputFileForWrite(finalOutFileSize);
Path finalIndexFile =
mapOutputFile.getOutputIndexFileForWrite(finalIndexFileSize);
//The output stream for the final single output file
FSDataOutputStream finalOut = rfs.create(finalOutputFile, true, 4096);
if (numSpills == 0) {
//create dummy files
IndexRecord rec = new IndexRecord();
SpillRecord sr = new SpillRecord(partitions);
try {
for (int i = 0; i < partitions; i++) {
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec, null);
writer.close();
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
sr.putIndex(rec, i);
}
sr.writeToFile(finalIndexFile, job);
} finally {
finalOut.close();
}
sortPhase.complete();
return;
}
{
sortPhase.addPhases(partitions); // Divide sort phase into sub-phases
IndexRecord rec = new IndexRecord();
final SpillRecord spillRec = new SpillRecord(partitions);
for (int parts = 0; parts < partitions; parts++) {
//create the segments to be merged
List<Segment<K,V>> segmentList =
new ArrayList<Segment<K, V>>(numSpills);
for(int i = 0; i < numSpills; i++) {
IndexRecord indexRecord = indexCacheList.get(i).getIndex(parts);
Segment<K,V> s =
new Segment<K,V>(job, rfs, filename[i], indexRecord.startOffset,
indexRecord.partLength, codec, true);
segmentList.add(i, s);
if (LOG.isDebugEnabled()) {
LOG.debug("MapId=" + mapId + " Reducer=" + parts +
"Spill =" + i + "(" + indexRecord.startOffset + "," +
indexRecord.rawLength + ", " + indexRecord.partLength + ")");
}
}
int mergeFactor = job.getInt(JobContext.IO_SORT_FACTOR, 100);
// sort the segments only if there are intermediate merges
boolean sortSegments = segmentList.size() > mergeFactor;
//merge
@SuppressWarnings("unchecked")
RawKeyValueIterator kvIter = Merger.merge(job, rfs,
keyClass, valClass, codec,
segmentList, mergeFactor,
new Path(mapId.toString()),
job.getOutputKeyComparator(), reporter, sortSegments,
null, spilledRecordsCounter, sortPhase.phase(),
TaskType.MAP);
//write merged output to disk
long segmentStart = finalOut.getPos();
FSDataOutputStream finalPartitionOut = CryptoUtils.wrapIfNecessary(job, finalOut);
Writer<K, V> writer =
new Writer<K, V>(job, finalPartitionOut, keyClass, valClass, codec,
spilledRecordsCounter);
if (combinerRunner == null || numSpills < minSpillsForCombine) {
Merger.writeFile(kvIter, writer, reporter, job);
} else {
combineCollector.setWriter(writer);
combinerRunner.combine(kvIter, combineCollector);
}
//close
writer.close();
sortPhase.startNextPhase();
// record offsets
rec.startOffset = segmentStart;
rec.rawLength = writer.getRawLength() + CryptoUtils.cryptoPadding(job);
rec.partLength = writer.getCompressedLength() + CryptoUtils.cryptoPadding(job);
spillRec.putIndex(rec, parts);
}
spillRec.writeToFile(finalIndexFile, job);
finalOut.close();
for(int i = 0; i < numSpills; i++) {
rfs.delete(filename[i],true);
}
}
}
/**
* Rename srcPath to dstPath on the same volume. This is the same
* as RawLocalFileSystem's rename method, except that it will not
* fall back to a copy, and it will create the target directory
* if it doesn't exist.
*/
private void sameVolRename(Path srcPath,
Path dstPath) throws IOException {
RawLocalFileSystem rfs = (RawLocalFileSystem)this.rfs;
File src = rfs.pathToFile(srcPath);
File dst = rfs.pathToFile(dstPath);
if (!dst.getParentFile().exists()) {
if (!dst.getParentFile().mkdirs()) {
throw new IOException("Unable to rename " + src + " to "
+ dst + ": couldn't create parent directory");
}
}
if (!src.renameTo(dst)) {
throw new IOException("Unable to rename " + src + " to " + dst);
}
}
} // MapOutputBuffer
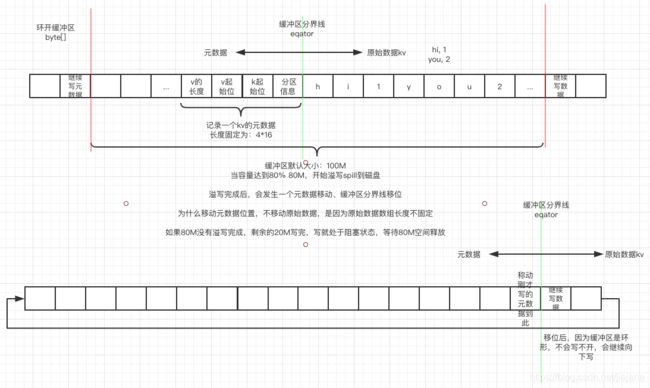
图片是帮助理解画的,有不正确的欢迎指正
相关配置:
<property>
<name>mapreduce.task.io.sort.mbname>
<value>100value>
<description>The total amount of buffer memory to use while sorting
files, in megabytes. By default, gives each merge stream 1MB, which
should minimize seeks.description>
property>
<property>
<name>mapreduce.map.sort.spill.percentname>
<value>0.80value>
<description>The soft limit in the serialization buffer. Once reached, a
thread will begin to spill the contents to disk in the background. Note that
collection will not block if this threshold is exceeded while a spill is
already in progress, so spills may be larger than this threshold when it is
set to less than .5description>
property>
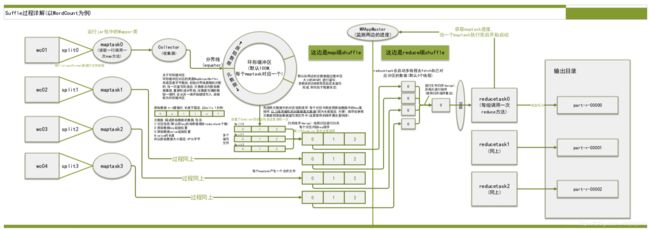
1.2.3 详细工作流程

-
一个文件在hdfs上是以block形式存放,默认blocksize=128M,存3份。文件会进行逻辑切片,一个split运行一个maptask,默认一个逻辑切片的大小就是blocksize的大小(最后一个切片可能小于128M,也可能大于128M,最大1.1*blocksize=140.8M)。有多少个blocksize就运行多少个maptask。所以同时会有很多个maptask并行计算。
-
每个maptask处理完输入的split数据后,会把结果写入到内存的一个环形缓冲区中,写入过程会进行简单排序,默认大小100M,当缓冲区使用阀值默认超过0.8时,后台会启动一个线程将缓冲区数据溢写spill到磁盘(mapred-site.xml:mapreduce.cluster.local.dir),同时mapper可继续向缓冲区写数据。
-
数据溢写到磁盘之前,会根据reducetask的数据量划分等数据的分区,每个分区中的数据会根据map输出的key进行内排序(字典排序、自然数顺序或自定义排序),如果有combiner,它会在溢写到磁盘之前排好序的输出 上运行(combiner 的作用是使 map 输出更紧凑,写到本地磁盘和传给 reducer 的数据更少), 最后在本地生成分好区且排好序的小文件; 如果 map 向环形缓冲区写入数据的速度大于向 本地写入数据的速度,环形缓冲区被写满,向环形缓冲区写入数据的线程会阻塞,直至缓冲区 中的内容全部溢写到磁盘后再次启动,到阀值后会向本地磁盘新建一个溢写文件
-
map 任务完成之前,会把本地磁盘溢写的所有文件不停地合并成得到一个结果文件,如果有combiner,会在合并大文件前再执行一次,合并得到的结果文件会根据小溢写文件的分区而分区,每个分区的数据会再次根据 key 进行排序,得到的结果文件是分好区且排好序的,可以合并成一个文件的溢写文件数量默认为 10(mapred-site.xml:mapreduce.task.io.sort.factor);这个结果文件的分区存在一个映射关系,比如 0~1024 字节内容为 0 号分区内容,1025~4096 字节内容为 1 号分区内容等等。
-
reduce 任务启动,Reducer 个数由 mapred-site.xml 的 mapreduce.job.reduces 配置决定, 或者初始化 job 时调用 Job.setNumReduceTasks(int);Reducer 中的一个线程定期向 MRAppMaster 询问 Mapper 输出结果文件位置,mapper 结束后会向 MRAppMaster 汇报信息; 从而 Reducer 得知 Mapper 状态,得到 map 结果文件目录;
-
当有一个 Mapper 结束时,reduce 任务进入复制阶段,reduce 任务通过 http 协议(hadoop 内置了 netty 容器)把所有 Mapper 结果文件的对应的分区数据复制过来,比如,编号为 0 的 reducer 复制 map 结果文件中 0 号分区数据,1 号 reduce 复制 map 结果文件中 1 号分区的 数据等等,Reducer 可以并行复制 Mapper 的结果,默认线程数为 5(mapred-site.xml:mapreduce.reduce.shuffle.parallelcopies);
所有 Reducer 复制完成 map 结果文件后,由于 Reducer 会失败,NodeManager 并没有在第 一个 map 结果文件复制完成后删除它,直到作业完成后 MRAppMaster 通知 NodeManager 进行删除;
另外:如果 map 结果文件相当小,则会被直接复制到 reduce NodeManager 的内存中(缓冲区 大小由 mapred-site.xml:mapreduce.reduce.shuffle.input.buffer.percent 指定,默认 0.7);一旦 缓冲区达到 reduce 的阈值大小 0.66(mapred-site.xml:mapreduce.reduce.shuffle.merge.percent) 或写入到 reduce NodeManager 内存中文件个数达到 map 输出阈值 1000(mapred-site.xml:mapreduce.reduce.merge.inmem.threshold),reduce 就会把 map 结果文 件合并溢写到本地; -
复制阶段完成后,Reducer 进入 Merge 阶段,循环地合并 map 结果文件,维持其顺序排 序,合并因子默认为 10(mapred-site.xml:mapreduce.task.io.sort.factor),经过不断地 Merge 后 得到一个“最终文件”,可能存储在磁盘也可能存在内存中;
-
“最终文件”输入到 reduce 进行计算,计算结果输入到 HDFS。
2. Map Join 和 Reduce Join
2.1 表关联
有三份数据
用户表 users
| 序号 | 属性 | 类型 | 描述 |
|---|---|---|---|
| 1 | UserID | BigInt | 用户ID |
| 2 | Gender | String | 性别 |
| 3 | Age | Int | 年龄 |
| 4 | Occupation | String | 职业 |
| 5 | Zipcode | String | 邮政编码 |
users.dat 数据样例:
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
电影表 movies
| 序号 | 属性 | 类型 | 描述 |
|---|---|---|---|
| 1 | MovieID | BigInt | 电影ID |
| 2 | Title | String | 电影名字 |
| 3 | Genres | String | 电影类型 |
movies.dat 数据样例:
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
评分表 ratings
| 序号 | 属性 | 类型 | 描述 |
|---|---|---|---|
| 1 | UserID | BigInt | 用户ID |
| 2 | MovieID | BigInt | 电影ID |
| 3 | Rating | Double | 评分 |
| 4 | Timestamped | String | 评分时间戳 |
ratings.dat 数据样例:
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
例如我们用sql实现:
所有用户对电影的评分
select a.MovieID,a.Title,b.UserId,b.Rating from movies a join ratings b where a.MovieID=b.MovieID
2.2 Reduce Join
ReduceJoin.java
/**
* movies.dat
* 数据格式为: 2::Jumanji (1995)::Adventure|Children's|Fantasy
* 对应字段为:MovieID BigInt, Title String, Genres String
* 对应字段中文解释:电影ID,电影名字,电影类型
*
* ratings.dat
* 数据格式为: 1::1193::5::978300760
* 对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
* 对应字段中文解释:用户ID,电影ID,评分,评分时间戳
*
* map端:读取文件的
* key: 两表的关联键
* value: 两个表的其它需要字段
* 打标记 标识数据来源
* movies.dat: "M"+value
* ratings.dat: "R"+value
*
* reduce端:
* 相同关联键的两个表中的数据
* 将两个表的数据进行拼接
*
*/
public class ReduceJoin {
/**
* 要同时读取两个文件,并且要知道是来自哪个表
* 在map()执行之前可以获取当前这一行数据的来源
*
* Mapper中有三个核心函数:
* setup——map——cleanup
* setup:在task开始的时候执行一次
* map:每一行执行一次
* clean:task结束的时候执行一次
*
* 重写setup
* 获取文件名
* 一个maptask对应一个逻辑切片split
* 假如 a.txt 300M
* split0
* split1
* split2
*/
static class MyMapper extends Mapper<LongWritable,Text, Text,Text>{
String fileName;
Text mk = new Text();
Text mv = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
/**
* InputSplit是一个抽象类,要强转成FileSplit
* 获取输入切片
*/
FileSplit split = (FileSplit) context.getInputSplit();
//获取输入切片的文件名
fileName = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] datas = value.toString().split("::");
if(fileName.equals("movies.dat")){
/**
* movies.dat
* 数据格式为: 2::Jumanji (1995)::Adventure|Children's|Fantasy
* 对应字段为:MovieID BigInt, Title String, Genres String
* 对应字段中文解释:电影ID,电影名字,电影类型
*/
mk.set(datas[0]);
mv.set("M"+datas[1]+"\t"+datas[2]);
}else {
/**
* ratings.dat
* 数据格式为: 1::1193::5::978300760
* 对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
* 对应字段中文解释:用户ID,电影ID,评分,评分时间戳
*/
mk.set(datas[1]);
mv.set("R"+datas[0]+"\t"+datas[2]+"\t"+datas[3]);
}
context.write(mk,mv);
}
}
/**
* Reduce端进行拼接
* 相同关联键的数据(电影ID)
* key=2
* movies
* 2 MJumanji (1995) Adventure|Children's|Fantasy
* ratings
* 2 R1 6 86788
*/
static class MyReducer extends Reducer<Text,Text,Text,Text>{
Text rv = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//创建两个集群,分别从放这个key关联的,movies和ratings数据
List<String> mlist = new ArrayList<String>();
List<String> rlist = new ArrayList<String>();
//按标记区分,将数据存入相应list
for (Text v:values){
String val = v.toString();
if(val.startsWith("M")){
mlist.add(val.substring(1));
}else if(val.startsWith("R")){
rlist.add(val.substring(1));
}
}
//join 拼接
for (String m:mlist){
for (String r:rlist){
String rest = m +"\t|\t" +r;
rv.set(rest);
context.write(key,rv);
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME","hdp01");
Configuration conf = new Configuration();
conf.set("mapperduce.framework.name","local");
conf.set("fs.defaultFS","hdfs://10.211.55.20:9000");
// Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReduceJoin.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//输入多个文件
FileInputFormat.setInputPaths(job, new Path("/tmpin/moviesRating/movies.dat"),new Path("/tmpin/moviesRating/ratings.dat"));
FileOutputFormat.setOutputPath(job, new Path("/tmpout/moviesRating/out1"));
job.waitForCompletion(true);
}
}
运行结果:
[hdp01@hdp01 tmpfiles]$ hdfs dfs -cat /tmpout/moviesRating/out1/part-r-00000
电影ID 电影名字 电影类型 | 用户ID 评分 评分时间戳
1 Toy Story (1995) Animation|Children's|Comedy | 4395 3 965159784
1 Toy Story (1995) Animation|Children's|Comedy | 220 5 976836351
.
.
.
999 2 Days in the Valley (1996) Crime | 3095 1 969644225
999 2 Days in the Valley (1996) Crime | 3031 4 972526918
缺陷:
join的过程reduce端执行的
-
性能低 压力大
reducetask并行度 job.setNumReducetasks()
最大 datanode*0.95
maptask的并行度—split—block
reducetask并行度不能太高 -
容易产生数据倾斜 根本性能缺陷
关联的键本身数据就分配不均匀 容易产生数据倾斜
数据倾斜:当有多个reducetask的时候 某一个reducetask的数据分配的过多
造成多个reducetask中数据分配不均匀,产生数据倾斜计算表象:
map 100% reduce 20%
map 100% reduce 60%
map 100% reduce 90%
map 100% reduce 90%
map 100% reduce 90%
map 100% reduce 90%
…
其它reducetask都完成了,某个reducetask计算的量太大,都在等它完成呢
大数据不怕数据量大 怕数据倾斜 严重影响计算性能
reducetask----yarnchild----一个节点上
解决办法:map join
2.3 Map Join
MapJoin.java
/**
* map端执行join
* 1.先将其中一个表的数据加载到每个运行maptask的节点的缓存中(本地)
* 2.在mapper的setup中读取这个数据
* 存储到容器中 关联 map key-关联建 value:其他
*
* 3.在map()进行关联
*/
public class MapJoin {
static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
Map<String,String> mmap=new HashMap<String,String>();
Text mk=new Text();
Text mv=new Text();
//setup中进行本地缓存文件的读取 本地缓存---本地路径
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//获取本地缓存路径 通过context对象获取
//获取本地缓存文件路径 返回的所有缓存路径的数组
//我们这个数组只有一个元素的
// Path[] files = context.getLocalCacheFiles(); //depreached
URI[] files = context.getCacheFiles();
//获取本次缓存 /home/hadoop/apps/movies.dat
String path = new Path(files[0].getPath()).getName();
//参数是本地缓存路径 创建一个文件读取流
BufferedReader br=new BufferedReader(new FileReader(path));
String line=null;
//1::Toy Story (1995)::Animation|Children's|Comedy
while ((line=br.readLine())!=null){
String[] datas = line.split("::");
//key:关联建 value:其他 Toy Story (1995) Animation|Children's|Comedy
mmap.put(datas[0],datas[1]+"\t"+datas[2]);
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//先获取ratings.dat表的每一行数据 6040::2019::5::956703977
String[] infos = value.toString().split("::");
//进行拼接
//获取这个数据中的关联建
String joinkkey=infos[1];
//从map集合中判断是否存在这个关联建 存在 关联 不存在 不管
if(mmap.containsKey(joinkkey)){
String res=infos[0]+"\t"+infos[2]+"\t"+infos[3]+"\t|\t"+mmap.get(joinkkey);
mk.set(joinkkey);
mv.set(res);
context.write(mk,mv);
}
}
}
static class MyReducer extends Reducer<Text, Text, Text, Text> {
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
// System.setProperty("HADOOP_USER_NAME","hdp01");
// Configuration conf = new Configuration();
// conf.set("mapperduce.framework.name","local");
// conf.set("fs.defaultFS","hdfs://10.211.55.20:9000");
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(MapJoin.class);
job.setMapperClass(MyMapper.class);
//设置最终输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//1.将需要进行join的一个表 加载到maptask的本地缓存中
//将指定的文件的加载到本地缓存中 在哪一个节点执行maptask 本地就是指哪一个节点
job.addCacheFile(new URI("/tmpin/moviesRating/movies.dat"));
//设定reducetask的个数为0才不会执行reducetask,否则默认会走
job.setNumReduceTasks(0);
//map()需要读取的文件的路径 只需要一个表,另一个表在缓存中
FileInputFormat.addInputPath(job, new Path("/tmpin/moviesRating/ratings.dat"));
FileOutputFormat.setOutputPath(job, new Path("/tmpout/moviesRating/out2"));
job.waitForCompletion(true);
}
}
打jar包上传服务器运行:
[hdp01@hdp01 tmpfiles]$ hadoop jar follow-1.0-SNAPSHOT.jar com.study.follow.join.MapJoin
运行结果:
[hdp01@hdp01 tmpfiles]$ hdfs dfs -cat /tmpout/moviesRating/out2/part-m-00000
电影ID 用户ID 评分 评分时间戳 | 电影名字 电影类型
1193 1 5 978300760 | One Flew Over the Cuckoo's Nest (1975) Drama
661 1 3 978302109 | James and the Giant Peach (1996) Animation|Children's|Musical
914 1 3 978301968 | My Fair Lady (1964) Musical|Romance
3408 1 4 978300275 | Erin Brockovich (2000) Drama
mapjoin优势:
不会产生数据倾斜
并行度高 maptask–逻辑切片–block
执行效率高
缺陷:
其中一个表放在本地缓存中的,最终以流的形式读取jvm的内存中
本地缓存的表不能太大的 如果太大 jvm的内存不足
只能适用
大小表 小表放在缓存中
小小表 任意一个表放在缓存中
大大表
将其中的一个表进行瘦身或切分 转换为小表
大*小 hive
2.4 利用hadoop 进行倒排索引
倒排索引原理
倒排序索引也常被称为反向索引、置入档案或反向档案,是一种索引方法
应用全文搜索—搜索引擎
正向索引:
多个文件中每一个文件中包含的关键词,以及关键词所在的位置 、次数等做的索引
1.txt hello,1,0 hello,1,17
2.txt hello,3,5
3.txt spark
4.txt hbase
文件中包含了哪些关键词 这些关键词的位置、次数
通过文件名找关键字好找,比如hello出现在哪些文件中?
需要获取每一个文件的正向索引,循环遍历文件, 看其中是否包含这个关键字
正常的搜索引擎中:输入的关键字 ,找包含这个关键字的文件
反向索引:
以关键词做索引 这个关键词在哪些文件中出现过
hello 1.txt,3,1,4,6 2.txt,1,3
spark 3.txt,2,1,5 4.txt,1,2
搜索引擎:
输入华为 ,返回了很对网页(包含华为这个关键字的)
华为 www.huawei.com,0 www.baidubaike.com,2
这种的索引方式,就叫做倒排索引
便于指定关键字的全文搜索
示例:
有两份数据:
1.txt
A friend in need is a friend indeed
Good is good but better carries it
2.txt
A good name is better than riches
Time is a bird for ever on the wing
Adversity is a good disciple
题目:用mapreduce创建倒排序索引,统计每一个关键词在每一个文档中的第几行出现了多少次。
格式如下:
good 1.txt:2,2;2.txt:1,1;2.txt:3,1
good 在1.txt中第2行出现2次
good 在2.txt中第1行出现1次
good 在2.txt中第3行出现1次
下面代码中是用便移量表示的:
good 1.txt:36,2; 2.txt:70,1; 2.txt:0,1;
good 在1.txt中在便移量36开始的行出现2次
good 在2.txt中在便移量70开始的行出现1次
good 在2.txt中在便移量0开始的行出现1次
InvertedIndex.java
/**
* map:
* key: 关键字
* value: 文档名 位置 次数
*
* reduce:
* 相同关键字所在的文件信息都到reduce端,进行拼接
*/
public class InvertedIndex {
static class InvertedIndexMapper extends Mapper<LongWritable, Text,Text,Text> {
String fileName;
Text mk = new Text();
Text mv = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//一个逻辑切片,执行一个maptask,获取当前切片的文件名称
FileSplit inputSplit = (FileSplit) context.getInputSplit();
fileName = inputSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] keyWords = value.toString().split(" ");
//统计次数 map
Map<String,Integer> keyCount = new HashMap<String, Integer>();
for (String word:keyWords) {
//转小写,不然大写,和小写代表两个词
word = word.toLowerCase();
if(keyCount.containsKey(word)){
keyCount.put(word,keyCount.get(word)+1);
}else {
keyCount.put(word,1);
}
}
for (String k:keyCount.keySet()) {
mk.set(k);
//位置信息就用key,LongWitable 便移量
mv.set(fileName+":"+key.get()+","+keyCount.get(k)+";\t");
context.write(mk,mv);
}
}
}
static class InvertedIndexReducer extends Reducer<Text,Text,Text,Text>{
Text rv=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text val:values) {
sb.append(val.toString());
}
rv.set(sb.substring(0,sb.length()-1));
context.write(key,rv);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
System.setProperty("HADOOP_USER_NAME","hdp01");
Configuration conf = new Configuration();
conf.set("mapperduce.framework.name","local");
conf.set("fs.defaultFS","hdfs://10.211.55.20:9000");
Job job= Job.getInstance(conf);
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("/tmpin/invetedIndex"));
FileOutputFormat.setOutputPath(job, new Path("/tmpout/invertedIndex/out1"));
//提交job
//可以打印日志的 参数代表是否打印运行的进程
job.waitForCompletion(true);
}
}
输出结果:
[hdp01@hdp01 tmpfiles]$ hdfs dfs -cat /tmpout/invertedIndex/out1/part-r-00000
a 1.txt:0,2; 2.txt:0,1; 2.txt:70,1; 2.txt:34,1;
adversity 2.txt:70,1;
better 2.txt:0,1; 1.txt:36,1;
bird 2.txt:34,1;
but 1.txt:36,1;
carries 1.txt:36,1;
disciple 2.txt:70,1;
ever 2.txt:34,1;
for 2.txt:34,1;
friend 1.txt:0,2;
good 1.txt:36,2; 2.txt:70,1; 2.txt:0,1;
in 1.txt:0,1;
indeed 1.txt:0,1;
is 1.txt:36,1; 1.txt:0,1; 2.txt:70,1; 2.txt:34,1; 2.txt:0,1;
it 1.txt:36,1;
name 2.txt:0,1;
need 1.txt:0,1;
on 2.txt:34,1;
riches 2.txt:0,1;
than 2.txt:0,1;
the 2.txt:34,1;
time 2.txt:34,1;
wing 2.txt:34,1;