独家 | 关于数据湖架构、战略和分析的8大错误认知(附链接)

翻译:张玲
校对:丁楠雅
本文约9200字,建议阅读20分钟。
本文打破有关数据湖的8个错误认知,错误认知包括3方面,还提出了5个小技巧,以构建一个灵活的、可交付业务价值的数据湖。

本文的目的是构建数据湖,并提供适应企业数据策略的背景信息。咨询公司和提供商提出的意见相互矛盾,因此,这些信息历来一直不透明,令人困惑。
不幸的是,这些令人困惑和颇具误导性的建议导致人们不断就技术平台的背景信息发问,而不是就一个战略或者业务成果来发问。这种技术驱动的决策过程试图使主观的讨论变得更加客观,例如,他们会追问什么是亚马逊数据湖?或者什么是最好的数据湖软件。也许有一个供应商急于求成,正在医疗领域里推广符合流行语的、兼容HIPPA的数据湖。所以,对于那些想要厘清数据湖如何赋能数据洞察的人来说,这些关于数据湖的讨论令人更加困惑。
亚马逊数据湖
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&isMul=1&isNew=1&lang=zh_CN&token=1763595143&token=1763595143&lang=zh_CN#data-lakes
兼容HIPPA的数据湖
https://aws.amazon.com/lake-formation/
打破这些与数据湖策略、架构和实现建议相关的错误认知,将有助于你理解数据湖失败的原因及其实现面临的各种挑战,还有助于阐明供应商和咨询公司提供的建议可能与数据湖最佳实践背道而驰的原因。
让我们开始一一打破这些错误认知吧!
错误认知1:数据湖与数据仓库,必须二选一
人们普遍建议在数据湖和数据仓库之间二选一,但这是错误的。
审视现实-数据仓库和数据湖之间的区别
这种必须在数据湖和数据仓库之间二选一的认知错误地限制了讨论的框架。当人们通过询问数据仓库是否过时来开启讨论时,似乎在告知是时候抛弃你的企业级数据仓库。这些问题的出发点都有误,而且正在引你误入歧途。
通常,一家公司需要就某一特定的设计模式进行某种形式的技术投资时,就会引发这些问题的讨论。例如,他们声称某些操作可以或必须发生在数据仓库中,然后将这些操作定义为是采用数据湖架构的限制和风险。
那供应商推广的数据湖架构限制示例是什么?
供应商会说数据湖无法像数据仓库那样便于按需扩展计算资源,从而它是受限的。这是真的,但具有误导性。就这就像抱怨汤姆布拉迪肯定是一名可怕的运动员,因为他从未在职业橄榄球生涯中打过本垒打。既然汤姆布拉迪是一名橄榄球运动员,你会期望他成为一名在芬威棒球场(好吧,也叫Pesky'pole)投球飞过左外野全垒打墙的全垒打投球手吗?不。
Pesky'pole
https://www.youtube.com/watch?v=ZdiCbHh5U7w
那么,为什么供应商和咨询公司会在这里应用数据仓库计算概念?
事实上,声称数据湖没有计算资源是一种FUD行销手法(灌输数据湖的负面观念,在你的头脑里注入疑惑和恐惧,使你误以为除了数据仓库以外,别无选择)。数据湖无法按需扩展计算资源,是因为没有需要扩展的计算资源。
FUD行销手法
https://en.wikipedia.org/wiki/Fear,_uncertainty_and_doubt
Redshift Spectrum https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#aws-redshift-spectrum
根据设计,数据湖中的查询数据服务可以很好地抽象出这个引擎模型,而且无论你在Google云上是否有亚马逊数据湖(AWS数据湖)、Oracle数据湖、Azure数据湖或BigQuery数据湖,模型都是类似的。 可以通过Athena这类的查询引擎或者像Redshift、 BigQuery、Snowflake等“仓库”来查询数据湖数据内容,这些服务提供计算资源,而不是提供一个数据湖。
Redshift
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#aws-redshift
BigQuery
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#bigquery
所以,对于大多数企业来说,数据湖和数据仓库如何共存才是正确的讨论内容,而不是讨论如何二选一。 当有人向你提出只能二选一时,他们可能是利益相关方,也就是说他们的产品或者商业伙伴也提供相关的功能。
错误认知2:数据仓库就是一个数据湖
审视现实-定义有效的数据湖
的确,有一些供应商和咨询公司主张将数仓作为数据湖模型。
不同的供应商和咨询公司会建议使用模式(或其他物理或逻辑结构)来表示数据从“原始”到数仓中其他状态的生命周期,业务所需的任何成熟度数据都可以在仓库范围内完成。
传统上,数仓旨在反映企业已经完成的事务,也反映企业完成一系列的一致事务,例如一个已经完成的事务可能提供有关收入、订单、“最佳客户”和其他领域的重要事务。
但是,在数仓“导入所有数据”模型中,数仓包含所有的数据内容,其中会包括暂时的和易失的原始数据。
将所有的原始数据重新打包到数仓中的操作更像是操作型数据库(Operational Data Store,ODS)或者数据集市的操作,而不像是数仓的操作。 你能将所有的数据都扔进数仓吗? 不能。 不能仅仅因为你可以在技术上做一些事情,就可以使它成为正确的体系结构。
操作型数据库
https://en.wikipedia.org/wiki/Operational_data_store
数据处理
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#data-wrangler-data-munging
技术债务
https://en.wikipedia.org/wiki/Technical_debt
正确的做法是,数据湖可以最小化技术债务,同时还可以加速企业团队对数据的消耗。 考虑到数仓、查询引起和数据分析市场的变化在加快,你战略的核心应该是最小化风险和技术债务。
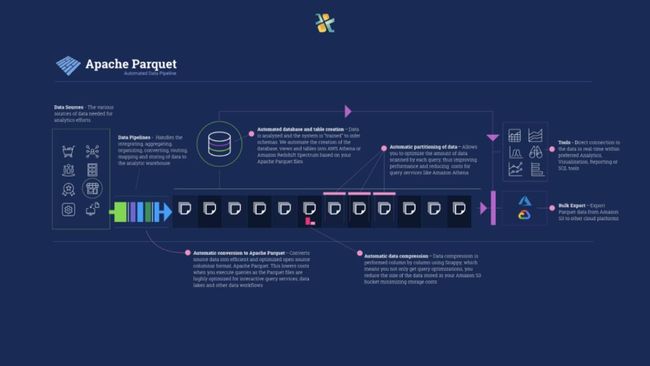
数据湖架构
错误认知3:数据湖只能用Hadoop来实现
审视现实-Hadoop不是一个数据湖
虽然Hadoop技术可以用于数据湖的构建和运行,但它们并不能反映出所支持的数据湖的基本战略和架构。
认识到数据湖最先反映的是战略和架构,而不是技术,这一点很重要。Pentaho联合创始人兼首席技术官詹姆斯·狄克逊(也就是创造“数据湖”这个词的人)说:
这种情况和传统的商业智能分析程序构建方式类似,根据终端用户给出的数据问题清单,从数据流中筛选出与问题相关的字段属性,并批量记载到数据集市中。在你提出新问题之前,这个方法是可行的。数据湖可以完全解决这个问题,你可以将所有数据存储在数据湖中,填充数据集市和数据仓库以满足传统的数据需求,针对新问题,则可以启用数据湖中的原始数据以供即席查询和生成报告。
Hadoop和其它技术一样,可以支持战略和架构的实现。如果现在你有一个数据湖,会有很多非Hadoop的选择,即使这些选择使用了Hadoop相关技术。例如,你的数据湖需要同时支持Snowflake这样的数仓解决方案和在AWS Athena、Presto,、Redshift Spectrum和BigQuery这样的就地查询方式。
AWS Athena
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#aws-athena
Redshift Spectrum
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#redshift
错误认知4:数据湖仅用于“存储”数据
审视现实-数据湖不仅仅是一个存放数据的地方
当供应商将数据湖定义为存储的同义词时,这可能会变得复杂。例如,微软将产品打包为Azure Data Lake Storage或Azure Data Lake Storage Gen2,数据湖确实提供了存放数据的功能,但这只是其特征之一。
如前所述,应该将数据湖视为是企业更为广泛的数据栈中的战略元素,这包括在下游系统中(如数仓)支持事务数据集成,或者在Tableau或Oracle ETL等工具中支持数据处理。
因此,数据湖不仅仅可以存储数据,还可以兼容数仓、数据分析技术栈中的技术。事实上,大多数数据湖是动态的生态系统,而不是静态的封闭系统。当数仓负载适中时,数据湖是一个活跃数据源,源源不断为其输送数据,反之亦然,负载过重时,数据湖进行对数据进行适当地动态处理,以降低成本和提高效率。
数据湖对数据进行适当地组织,以便将下游价值传递给使用数据的下游系统,包括数仓。例如,数据湖在支持数仓整合事务数据方面发挥了积极的作用。
我们有一位客户使用数据湖对数十个网站和第三方酒店的标签进行质量控制分析,这有助于识别负责这项工作的不同团队可能存在的差异和执行错误。还有一位客户在将数据导入企业级数据仓库前,使用数据湖过滤来自不同部门、第三方和合作伙伴系统中的不准确订单或重复的多渠道订单。
这两个例子都强调了,数据湖在保证下游事务数据的准确性和合规性上发挥了积极的作用。
正如麦肯锡员工所说:“...数据湖不仅保证了技术栈的灵活性,而且还保证了业务能力的灵活性。”数据湖作为一种服务模型,是为了交付业务价值,而不仅仅是存储数据。
交付业务价值 https://www.mckinsey.com/business-functions/digital-mckinsey/our-insights/a-smarter-way-to-jump-into-data-lakes
错误认知5:数据湖仅存储“原始”数据
审视现实--定义有效的数据湖策略和架构
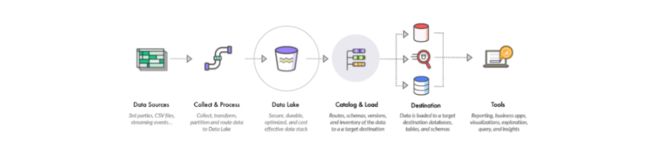
正如之前所说的,这和数仓旨在反映既定事务数据的基本前提相矛盾。 一个更好的历史数据比较不是在数仓和数据湖之间进行,而是在ODS和数据湖之间进行。
从历史数据角度上看,数据湖是一个ODS,而不是一个数仓,因为数据湖从上游获取粗糙和不稳定的原始数据。 一个ODS数据通常时间范围很窄,可能只有90天内的数据,针对某一特定数据领域,时间范围可能更窄。 另一方面,数据湖对于保留的数据没有时间范围限制,从而时间范围更广些。
那么,数据湖仅是为了存储“原始”数据吗?
不。
根据设计,数据湖应该有一定程度的数据输入管理(即管理什么数据要进入数据湖)。 如果你没有管理数据进入模式的意识,那么你其它地方的技术栈可能存在问题,这对于数仓或任何其它数据系统也是一样的,垃圾进,垃圾出。
与我们合作的一位客户将Adobe事件数据发送到AWS,以支持企业Oracle云环境。 为什么要从AWS到Oracle呢? 因为这是Oracle BI环境中最高效的和最具成本效益的数据处理模式,尤其是考虑到使用AWS数据湖和Athena作为按需查询服务的灵活性和经济性。
Adobe事件数据发送到AWS,以支持企业Oracle云环境
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#oracle-data-lake
通过最大限度地保证数据的有效性,提高处理数据的效率,你可以最大限度地降低下游数据处理者所要付出的数据处理成本。
错误认知6:数据湖仅适用于“大”数据
审视现实-数据湖有各种形状和大小
不幸的是,“大数据”角度给人以一种错觉:数据湖仅适用于里海范围那么大的数据,这当然会让数据胡的概念令人生畏。因此,用如此量大的术语来描述数据湖会使那些本可以从中获益的人无法接近。
另一个观点是数据湖和大数据只能二选一。像自然界中的湖泊一样,数据湖有各种不同的形状和大小。每一种数据湖都有一种自然状态,通常反映数据的生态系统,就像自然界中反映鱼、鸟或其它有机体的生态系统一样。
以下是一些例子:
诺大的“Caspian”:
就像里海是大片水域一样,这种类型的数据湖是一个存放各种半结构化和非结构化数据的大型数仓,这些整合了不同数据集的超大数据集反映了来自企业方方面面的信息。
临时的“Ephemeral”:就像沙漠可以有小的、临时的湖泊一样,临时的数据湖“Ephemeral”也是短暂存在的。它们可以用于项目、试生产、PoC或者一个点解决方案,可以很快打开,也可以很快关闭。
领域性的“Project”:这种类型的数据湖和“Ephemeral”一样往往集中在特定的知识领域中。然后,和临时“Ephemeral”不同的是,这种数据湖可以持续一段时间。这些数据湖可能也很浅,可能专注于一个狭窄的数据领域,如媒体、社交、网络分析、电子邮件或类似的数据源。有一位客户称他们的项目为“Tableau数据湖”。
通过设计,所有数据湖类型都应该采用一种抽象,以最大限度地降低风险,并提供更大的灵活性。此外,它们的结构应该便于数据处理,独立于数据规模的大小。当数据科学家、业务用户或者python代码使用数据湖时,确保它们拥有一个易于处理数据和可自定义数据规模的数据环境。
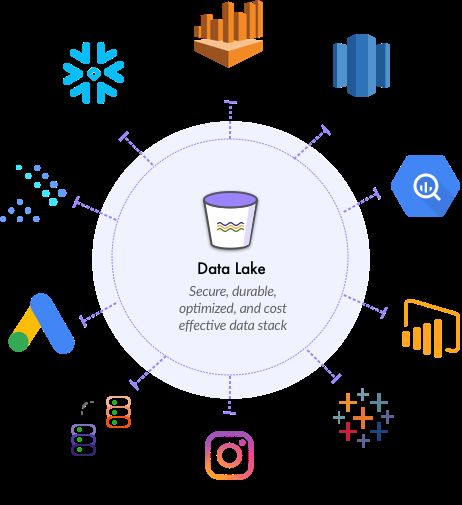
无论你的使用场景是机器学习、数据可视化、生成报告还是为数仓和数据集市输送数据,数据规模的不同,思考方式不同,有可能创造出使用这些数据湖的新方式。
错误认知7:数据湖没有安全保障
审视现实-安全是一种选择,确保你考虑的是它
从某种意义上说,人们会依赖于隐性的安全技术解决方案(即自动的AWS S3 AES对象加密),而不会去构建一个显性的、可以管理安全性的架构和下游使用场景,这可能会导致安全漏洞,但这可以说是很多系统的漏洞,而非仅是数据湖本身的漏洞。因此,认为数据湖本质上不安全的观点是不准确的。
安全可以是而且应该是我们要考虑的重中之重,这里有4个需要考虑的方面:
访问:通常,对针对基础数据定义良好的访问策略。在AWS中,你可以定义针对S3的IAM策略及其相关服务。除此以外,微软还有一个描述类似安全策略方法的Azure数据湖架构。
工具:处理数据的工作和系统也会确保一定的安全性。例如,查询引擎可以有一个表级和列级数据的访问控制机制。此外,数据处理工具(如Tableau或Power BI)也可以对数据湖中的数据设置访问控制。
加密:通常会希望(或强制)在数据传输和静止时对其进行加密。
分区:逻辑分区和物理分区在一定水平上进一步简化了安全策略,例如团队可以将数据从初始数据池ETL至另一个位置,实现匿名化敏感数据,以供下游使用。
人们可以争论这些不同策略的优点,但要是说数据湖本身是不安全的,这是不正确的。
错误认知8:数据湖会变成数据沼泽
审视现实-正确安排人员、流程和技术
在极端情况下,这是真的。如果你把一个数据湖当作是你笔记本电脑上一个通用的“无标题文件夹”来处理文件,那么就可能会变成一个数据沼泽(见错误认知4),所以,这会存在风险。然而,对于任何习惯以这种方式进行文件转储的人来说,他们对成功安排人员、流程和技术都有点不感兴趣。
那么,真正的数据沼泽是什么呢?真正的数据沼泽是设计不当创造出来的,而不是疏于管理促成的。
数据湖更大的威胁不是缺乏治理、管理、生命周期策略和元数据,而是缺乏防止这种情况发生的生态系统,这个生态系统包括工具、角色、职责和系统。数据湖之所以成为沼泽,不仅仅是因为“倾倒文件”,还因为数据湖的相关人员、流程和技术安排过于复杂。如果你认为你的企业级数仓过程缓慢,那么你的数据湖也会如此。
简单、敏捷和灵活是数据湖众多优点中的一部分,当湖中出现重要的业务逻辑和流程时,你将面临这样的风险:创建出来的解决方案缺乏简单性、无法响应变化、设计过于严格,而这就是你需要警惕的数据沼泽。数据沼泽是昂贵的、费时的,从而无法满足任何人的期望。这听起来是不是很熟悉?
对于那些正在计划或者已经部署了数据湖的人来说,要小心数据湖的定位和特性蔓延。经常会看到供应商将其在传统数仓和其它ETL产品中发现的特性和功能定义为数据湖的功能,尽管从技术上讲,可以在数据湖中进行复杂的数据处理。
但是,你可能在数据湖外已经有了执行这些处理操作的工作流、工具、人员和技术,并不是所有的数据处理都符合你的上下游流程,请仔细考虑数据湖嵌套处理数据导致复杂性激增的风险。
请警惕,当前或计划中的数据湖逐渐看起来更像是传统的ETL工具和数仓的合体,如果你已经经历过一个过于复杂的构建企业级数仓工作,会很容易发现这一点。
数据驱动企业的数据湖架构及策略
结果,数据湖的技术术语、最佳实践和致力于构建更好平台的投资都在改进。业务实践的经济性、架构方式和优化方法都在不断变化,这允许团队以适应应用场景的方法将这些数据湖解决方案整合进企业的数据栈中。
不幸的是,这些批评逐渐变成广为流传的“数据湖不成功”、“数据湖等同于数据沼泽”、“数据湖与Hadoop等特定技术过于紧密联系”等这类信息。最后,还会出现“什么是数据湖”定义过于模糊和不固定的抱怨。
批评是任何技术发展的必要组成部分。
然而,技术发展的关键是以退为进,这样做,是因为这些批评并非仅针对数据湖。事实上,这些评论可以针对任何一项技术,特别是数据项目。例如,术语“数据仓库”和数据湖定义一样模糊而不断变化(见错误认知2),在谷歌上搜索“失败的数据仓库”,也会发现一些关于项目失败的故事。这些是否意味着我们应该放弃“数据仓库”这个短语或者停止追求这些项目?
不。
通常情况下,蔑视数据湖的咨询公司或企业都将自己提供的产品和服务视为灵丹妙药,致力于实现自己的愿景和最佳实践。如果一个咨询公司或供应商不相信一个模型,为什么要他们参与一个他们不相信的解决方案呢?将数据湖工作委托给这类咨询公司或供应商,很有可能是数据湖失败的一个原因。
在深入了解如何构建数据湖或如何和企业定制数据湖之前,我们有一些技巧可以帮助你进行规划。
如何构建数据湖
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&appmsgid=100013110&isMul=1&token=698435870&lang=zh_CN#amazon-data-lake
开始:从小处做起,要灵活
因此,停止购买闪亮的Hortonworks数据湖解决方案,组建软件开发工程师、客户经理、解决方案架构和支持技术工程师来构建企业数据湖吧!
从小处做起,要灵活。下面是一些关于如何运转数据湖实现的小技巧:
焦点:
寻找可以部署“Ephemeral”和“Project”解决方案的机会,确保你可以降低风险,克服技术和组织挑战,从而使你的团队能够建立对数据湖的信心。
激情:
确保你有一个内部的“福音传道者”或“大力倡导者”,这个人对公司内部的解决方案和应用充满激情。
如果缺少这样充满激情的人或团队,你会发现构建数据湖的热情就很快殆尽,正如健身房新年促销4周会员卡一样。
简单:
坚持简单和敏捷的理念,根据这一点,做出人、流程和技术的选择。
缺乏复杂性不应该被视为缺陷,而应该视作是精心设计的副产品。
缩小:
缩小数据范围,可以很好地定义数据湖,以便了解从ERP、CRM、Point-of-Sales、Marketing or Advertising data从导出地数据,这个阶段的数据处理经历有助于你了解数据的基本结构、获取、治理、质量和测试的工作流。
实验:将你的解决方案和现代BI分析工具(如Tableau、Power BI、Amazon Quicksight或Looker)结合起来,这可以让非技术用户有机会通过访问数据湖来测试和探索数据,同时也有助于你利用不同的用户群来评估性能瓶颈,发现改进机会,及时补充与现有EDW系统或其它数据系统的连接和其它候补数据源。除此之外,还允许你发现对团队有意义的数据湖工具以及适合投入资源的数据湖自动化部分。
将你的解决方案和现代BI分析工具(如Tableau、Power BI、Amazon Quicksight或Looker)结合起来
https://blog.openbridge.com/building-a-serverless-business-intelligence-stack-with-apache-parquet-tableau-and-amazon-athena-e1a2363c2e6d
AWS Lake Formation
https://aws.amazon.com/lake-formation/
使用无代码、全自动和零管理的Amazon Redshift Spectrum或Amazon Athena Services来启动你的工作。
Amazon Redshift Spectrum
https://www.openbridge.com/warehouse/amazon-redshift-spectrum
Amazon Athena Services
https://www.openbridge.com/warehouse/amazon-athena
致电
https://calendly.com/openbridge/project-discussio
编辑:王菁
校对:林亦霖
译者简介

张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无境,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织