Linux_Shell编程
目录
一、Shell编程之变量
用户自定义变量
环境变量
预定义变量
位置参数变量
二、Shell编程之运算符
declare
expr或let
$((运算式))或$[运算式]
变量测试
三、Shell编程之环境变量配置文件
环境变量配置文件简介
常用的环境变量配置文件
用户登录时文件调用顺序
umask命令
欢迎信息
四、Shell编程之正则表达式
通配符
正则表达式与通配符
基础正则表达式
字符截取命令
字符处理命令
五、Shell编程之条件判断于流程控制
条件判断式
单分支if语句
双分支if语句
多分支if语句
case语句
for循环
while循环和until循环
本文为慕课网Tony老师视频笔记,Tony老师的课通俗易懂,幽默风趣,Linux入门或巩固基础的话,推荐看一下!https://www.imooc.com/u/279399/courses?sort=publish
一、Shell编程之变量
Shell与其他语言对比:
1、php和java等语言主要实现功能
2、Shell是简化管理操作
变量概念:
里面存储的内容或者值是可以改变的量,变量方便在程序中对值进行传递替换和调用
变量命名规则:
1、变量名可以有字母下划线数字组成,但不能以数字打头
2、变量名长度不能超过255个字符
3、变量名在有效范围内必须是唯一的
4、在Bash中变量的默认类型是字符串型
变量的分类:
1、用户自定义变量:变量是自定义的
2、环境变量:这种变量中主要保存的是和系统操作环境相关的数据,
变量可以自定义,但是对系统生效的环境变量名和变量作用是固定的
3、预定义变量:是Bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的
4、位置参数变量(是预定义变量的一种):这种变量主要是用来向脚本中传递参数和数据的,
变量名不能自定义,变量作用是固定的
用户自定义变量
1、Shell中定义变量的时候等号两边不能加空格,否则系统会认为这条语句是一条命令空格后面的是参数
2、如果变量值中有空格需要用双引号或单引号括起来,
双引号括起来的字符串中一些特殊符号是起作用的而单引号括起来的则是一个单纯的符号
3、如果需要调用变量需要在变量名之前加$,定义变量的话不用加$
4、变量的叠加(类似于java中两个字符串相加):x=123 x="$x"456 或 x=${x}456 echo $x 123456
5、set命令:查询系统下所有已经生效的变量,set -u 默认当变量不存在时输出变量为空白,使用该命令之后会明确提示变量不 存在
unset+变量名 删除变量,注意变量名之前不加$
6、自定义变量是局部变量只在当前bash有效
环境变量
1、环境变量是全局变量
2、对系统生效的环境变量名和变量作用是固定的
3、定义环境变量:export 变量名=变量值
4、env命令:查看环境变量,删除也是使用unset,不过删除的时候要到定义该变量的bash中删除
5、常用环境变量
PATH:系统搜索命令的路径
PS1:命令提示符(root@locahost)设置
HOSTNAME:主机名
SHELL:当前的shell
TERM:终端环境
HISTSIZE:历史命令条数
SSH_CLIENT:当前操作环境使用ssh连接的话,这里记录客户端ip
SSH_TTY:ssh连接终端时pts/1
USER:当前登录的用户
6、增加环境变量:PATH="$PATH":/root/bin.sh
7、locale命令:查询当前系统语系,LANG:定义系统主语系的变量,LC_ALL:定义整体语系的变量
8、/etc/sysconfig/i18n 保存着默认语系(下次开机所加载的语系)
预定义变量
1、$? 最后一次执行的命令的返回状态,如果这个变量的值为0,证明上一个命令正确执行,如果值为非0证明上一个命令执行不 正确
2、$$ 当前进程的进程号(PID)
3、$! 后台运行的最后一个进程的进程号(PID)
位置参数变量
1、$n n为数字,$0代表命令本身,$1-$9代表第一到第九个参数,十以上的参数需要用大括号包含,如${10}
2、$* 这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体
3、$@ 这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待
4、$# 这个变量代表命令行中所有参数的个数
二、Shell编程之运算符
进行数值运算的方式如下:
declare
declare:声明变量类型
declare[+/-][选项][变量名]
-:给变量设定类型属性
+:取消变量的类型属性
-a:将变量声明为数组型
-i:将变量声明为整型
-x:将变量声明为环境变量(export其实就是调用这条命令)
-r:将变量声明为只读变量(设置了只读之后不能取消不能删除,慎用)
-p:显示指定变量的被声明的类型
expr或let
dd=$(expr $aa + $bb)
dd的值是aa和bb的和。注意+号左右两边必须有空格
$((运算式))或$[运算式]
dd=$(($aa+$bb))
dd=$[$aa+$bb]
变量测试
比如x=${y-新增},作用是用x值推测y的值,在脚本优化时使用,变量测试表见百度
三、Shell编程之环境变量配置文件
环境变量配置文件简介
环境变量配置文件中主要是定义对系统环境生效的系统默认环境变量,如PATH等
source命令
命令和source命令作用相同
修改配置文件之后必须注销重新登录才生效,使用source命令可以不重新登录
常用的环境变量配置文件
对所有用户起作用:
/etc/profile(历史命令条数在这设置)
/etc/profile.d/*.sh
/etc/bashrc(命令别名在这设置)
对当前用户起作用:
~/.bash_profile
~/.bashrc
用户登录时文件调用顺序
/etc/profile -- ~/.bash_profile -- ~/.bashrc -- /etc/bashrc -- 命令提示符
| | (root用户切换用户时不需要输入密码走这条路,比起完整的线路少加载了/etc/profile, | | ~/.bash_profile,~/.bashrc)
/etc/profile.d/*.sh-----------------------
|
/etc/profile.d/lang.sh -- /etc/sysconfig/i18h(默认语系)
~/.bash_logout:注销时执行的环境变量文件
umask命令
umask:查看系统默认权限
注意:
1、文件最高权限为666(文件不能一建立就可以执行,需要后续赋予执行权限)
2、目录最高权限为777
3、权限不能使用数字进行换算,而必须使用字母
4、umask定义的权限,是系统默认权限中准备丢弃的权限
欢迎信息
本地终端欢迎信息/etc/issue:
支持转移字符比如:/l 显示登录的终端号,/m 显示硬件体系结构
远程终端欢迎信息:/etc/issue.net
转义符在/etc/issue.net文件中不能使用
是否显示此欢迎信息,由ssh的配置文件/etc/ssh/ssd_config决定
加入"Banner /etc/issue.net"行才能显示(需要重启SSH服务)
登录后欢迎信息:/etc/motd
不管是本地终端登录还是远程登录,都可以显示此欢迎信息
四、Shell编程之正则表达式
正则表达式:主要用于字符串的分割、匹配、查找和替换(主要是模糊匹配)
通配符
*:匹配任意内容
?:匹配任意一个内容
[]:匹配中括号中的一个字符
正则表达式与通配符
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配。grep、awk、sed等命令可以支持正则表达式
通配符用来匹配符合条件的文件名,通配符是完全匹配。ls、find、cp这些命令不支持正则表达式,所以只能用shell自带的通配符来进行匹配了
基础正则表达式
*:前一个字符匹配0次或任意多次
.:匹配除了换行符外任意一个字符
^:匹配行首。例如:^hello会匹配以hello开头的行
$:匹配行尾。例如hello$会匹配以hello结尾的行
[]:匹配中括号中指定的任意一个字符,只匹配一个字符。
例如:[aoeiu]匹配任意一个元音字母,[0-9]匹配任意一位数字,[a-z][0-9]匹配小写字母和一位数字构成的两位字符
[^]:匹配除中括号中的字符以外的任意一个字符。
例如:[^0-9]匹配任意一位非数字字符,[^a-z]表示任意一位非小写字母
\:转义符。用于将特殊符号的含义取消
\{n\}:表示其前面的字符恰好出现n次。例如:[0-9]\{4\}匹配4位数字,[1][3-8][0-9]\{9\}匹配手机号码
\{n,\}:表示其前面的字符出现不小于n次。例如:[0-9]\{2,\}表示2位及2位以上的数字
\{n,m\}:表示其前面的字符至少出现n次,最多出现m次。例如:[a-z]\{6,8\}匹配6-8位的小写字母
字符截取命令
cut[选项]文件名:字段提取命令
-f 列号:提取第几列
-d 分隔符:按照指定分隔符分割列
printf '输出类型输出格式' 输出内容
输出类型:
%ns:输出字符串。n是数字指代输出几个字符
%ni:输出整数。n是数字指代输出几个数字
%m.nf:输出浮点数。m和n是数字,指代输出的整数位数和小数位数,如%8.2f
代表输出8位数,其中2位是小数,6位是整数
输出格式:
/a:输出警告声音
/b:输出退格键,也就是BackSpace键
/f:清除屏幕
/n:换行
/r:回车,也就是Enter键
/t:水平输出退格键,也就是Tab键
/v:垂直输出退格键,也就是Tab键
printf '%s' $(cat student.txt)
不调整输出格式
printf '%s\t%s\t%s\t%s\n' $(cat student.txt)
调整格式输出
在awk命令的输出中支持print和printf命令(和C语言中正好相反)
print:print会在每个输出之后自动加入一个换行符(Linux默认没有print命令)
printf:printf是标准的格式输出命令,并不会自动加入换行符,如果需要换行,需要手工加入换行符
awk '条件1{动作1}条件2{动作2}...' 文件名:字段提取命令(默认用空格或者制表符作为分隔符)
条件(Pattern)
一般使用关系表达式作为条件
x>10判断变量 x是否大于10
x>=10大于等于
x<=10小于等于
动作(Action)
格式化输出
流程控制语句
无条件:
awk '{printf $2 "\t" $4 "\n"}' student.txt
截取student文件的第二列和第四列并以\t为分隔符,\n为换行符
注意,这里printf命令后面需要用单引号括起来,但是awk命令已经用了单引号,所以printf命令的转义字符用双引号括起来
df -h | awk '{print $1 "\t" $3}'
截取磁盘分区信息的第一行和第三行并以\t为分隔符
df -h | grep "dev/sda5" | awk '{print $5}'
截取根分区的磁盘使用百分比
有条件:
awk 'BEGIN{printf "This is a transcript \n"}{printf $2 "\t" $4 "\n"}' student.txt
截取student文件中的第二列和第四列,在输出的时候先输出This is...,同理也有END
cat /etc/passwd | grep "/bin/bash" | awk 'BEGIN{FS=":"}{printf $1 "\t" $3 "\n"}'
指定分隔符为冒号
cat student.txt | grep -v Name | awk '$4>=70{printf $2 "\n"}'
读取student文件中除了包含Name行的数据,如果成绩大于等于70打印学生名字
sed命令:主要用于对数据进行选取、替换、删除、新增
sed[选项] '[动作]' 文件名
选项:
-n:一般sed命令把所有的数据都输出到屏幕,如果加入此选项则只会把经过sed命令处理的行输出到屏幕
-e:允许对输入数据应用多条sed命令编辑
-i:用sed的修改结果直接修改读取数据文件,而不是由屏幕输出
动作:
a:追加,在当前行后添加一行或多行
c:行替换,用c后面的字符串替换原数据行
i:插入,在当前行前插入一行或多行。
d:删除,删除指定行
p:打印,输出指定行
s:字串替换,用一个字符串替换另一个字符串。格式为“行范围s/旧字串/新字串/g”(和vim中的替换格式类似)
字符处理命令
排序命令sort
sort[选项]文件名
选项:
-f:忽略大小写
-n:以数值型进行排序,默认使用字符串型排序
-r:反向排序
-t:指定分隔符,默认分隔符是制表符
-k n[,m]:按照指定的字段范围排序。从n字段开始,m字段结束(默认到行尾)
统计命令wc
wc[选项名]文件名
选项:
-l:只统计行数
-w:只统计单词数
-m:只统计字符数
五、Shell编程之条件判断于流程控制
条件判断式
两种判断格式:
test -e /root/install.log
[-e /root/install.log]
[-d /root] && echo "yes" || echo "no"
第一个判断命令如果正确执行,则打印"yes",否则打印"no"
文件类型判断表

文件权限判断表

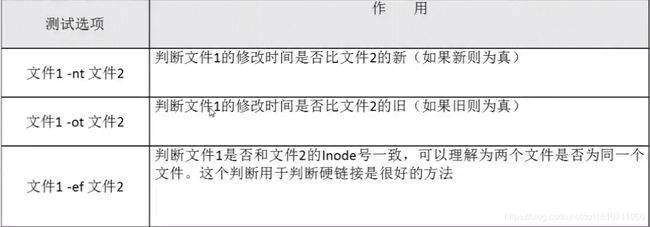
两个文件之间比较
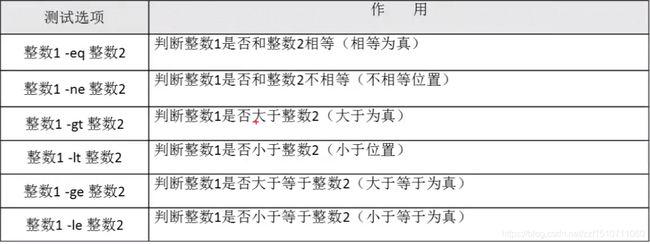
两个整数之间比较
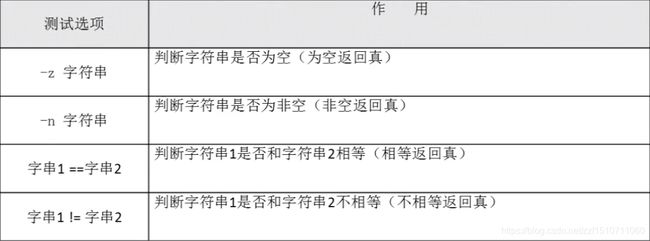
字符串的判断
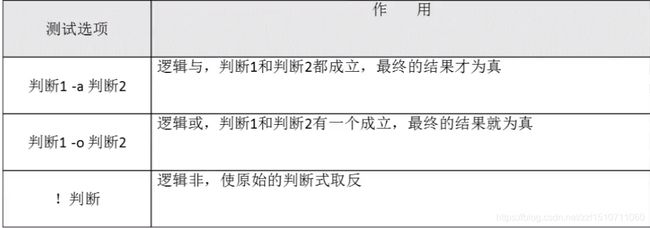
多重条件判断
单分支if语句
if [[ condition ]]; then
#statements
fiif语句使用fi结尾,和一般语言使用大括号不同
[ 条件判断式 ]就是使用test命令判断,所以中括号和条件判断式之间必须有空格
then后面跟符合条件之后执行的程序,可以放在[]之后,用";"分割。也可以换行写入,就不需要";"了
判断登录的用户是否为root:
test=$(env | grep "USER" | cut -d "=" -f2)
if [ "$test"==root ]; then
echo "Current user is root"
fi判断分区使用率:
test=$(df -h | grep sda5 | awk '{print $5}' | cut -d "%" -f 1)
if [ "$test"-ge"90" ]; then
echo "/ is full"
fi双分支if语句
if [[ condition ]]; then
#statements
else
#statements
fi判断apache是否启动(注意:该脚本名中不能出现httpd)
这里grep -v grep是因为执行grep的时候也会产生一个包含httpd字符的进程需要把它也过滤
同理,如果脚本名中包含httpd关键字,那么执行该脚本的时候test永远不会为空,因为脚本本身也是个进程
test=$(ps aux | grep httpd | grep -v grep)
#截取httpd进程,并把结果赋予变量test
if [[ -n "$test" ]]; then
#如果test的值不为空
echo "$(data) httpd is ok!" >> /tmp/autostart-acc.log
#否则启动apache服务
else
/etc/rc.d/init.d/httpd start &> /dev/null
echo "$(data)restart httpd!!" >> /tmp/autostart-acc.log
fi多分支if语句
if [[ condition ]]; then
#statements
elif [[ condition ]]; then
#statements
elif [[ condition ]]; then
#statements
else
#statements
fi判断num是否为纯数字
原理是把num中的数字都替换成空,如果最后结果test为空,证明num中是纯数字
test=$(echo $num | sed 's/[0-9]//g')判断用户输入的是什么文件
#接收键盘的输入,并赋予变量file
read -p "Please input a filename: " file
#判断变量是否为空
if [[ -z "$file" ]]; then
echo "Error,please input a filename"
exit 1
elif [[ ! -e "$file" ]]; then
#判断file值是否存在
echo "Your input is not a file!"
exit 2
elif [[ -f "$file" ]]; then
#判断file的值是否为普通文件
echo "$file is a regulare file!"
elif [[ -d "$file" ]]; then
#判断file的值是否为目录文件
echo "$file is a directory!"
else
echo "$file is an other file!"
ficase语句
case $变量名 in
"值1" )
#如果变量的值等于值1,则执行程序1
;;
"值2" )
#如果变量的值等于值2,则执行程序2
;;
...
*)
#如果变量的值都不是以上的值,则执行此程序
esacfor循环
for (( i = 0; i < 10; i++ )); do
#statements
done
for 变量 in 值1 值2 值3...; do
#statements
done批量添加指定数量的用户
read -p "Please input user name:" -t 30 name
read -p "Please input the number of users:" -t 30 num
read -p "Please input the password of users:" -t 30 pass
if [[ !-z "$name" -a !-z "$num" -a !-z"$pass" ]]; then
y=$(echo $num | sed 's/[0-9]//g')
if [[ -z $y ]]; then
for (( i = 1; i <= num; i=i+1 )); do
/usr/sbin/useradd $name$i $>/dev/null
echo $pass | /usr/bin/passwd --stdin $name$i $>/dev/null
done
fi
fiwhile循环和until循环
while [[ condition ]]; do
#statements
done
#跟while循环相反,当条件判断不成立就进行循环,成立就终止循环
until [[ condition ]]; do
#statements
done