sparkStreaming入门
1、Spark Streaming 简介
Spark Streaming 是核心 Spark API 的扩展,可实现可扩展、高吞吐量、可容错的实时数据流处理。数据可以从诸如 Kafka,Flume,Kinesis 或 TCP 套接字等众多来源获取,并且可以使用由高级函数(如 map,reduce,join 和 window)开发的复杂算法进行流数据处理。最后,处理后的数据可以被推送到文件系统,数据库和实时仪表板。而且,还可以在数据流上应用 Spark 提供的机器学习和图处理算法。

2、Spark Streaming 的特点

3、Spark Streaming 的内部结构
在内部,它的工作原理如下。Spark Streaming 接收实时输入数据流,并将数据切分成批,然后由 Spark 引擎对其进行处理,最后生成“批”形式的结果流。

Spark Streaming 将连续的数据流抽象为 discretizedstream 或 DStream。在内部,DStream 由一个 RDD 序列表示。
二、Spark Streaming 进阶
1、StreamingContext 对象详解
初始化 StreamingContext
方式一:从 SparkConf 对象中创建
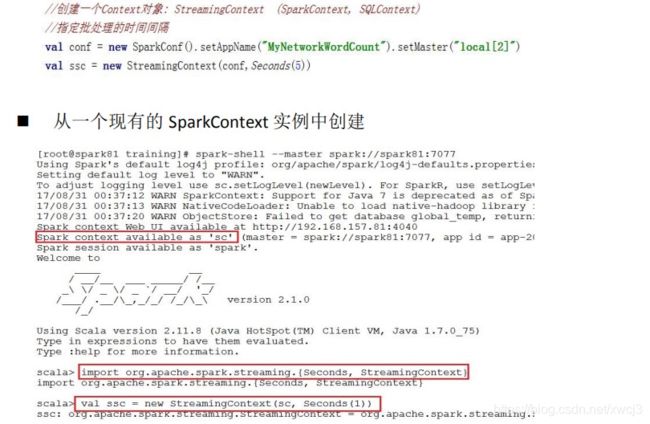
程序中的几点说明:
appName 参数是应用程序在集群 UI 上显示的名称。
master 是 Spark,Mesos 或 YARN 集群的 URL,或者一个特殊的“local []”字符串来让程序以本地模式运行。
当在集群上运行程序时,不需要在程序中硬编码 master 参数,而是使用spark-submit 提交应用程序并将 master 的 URL 以脚本参数的形式传入。但是,
对于本地测试和单元测试,您可以通过“local[]”来运行 Spark Streaming 程序(请确保本地系统中的 cpu 核心数够用)。
StreamingContext 会内在的创建一个 SparkContext 的实例(所有 Spark 功能的起始点),你可以通过 ssc.sparkContext 访问到这个实例。
批处理的时间窗口长度必须根据应用程序的延迟要求和可用的集群资源进行设置。
请务必记住以下几点:
一旦一个 StreamingContextt 开始运作,就不能设置或添加新的流计算。
一旦一个上下文被停止,它将无法重新启动。
同一时刻,一个 JVM 中只能有一个 StreamingContext 处于活动状态。
StreamingContext 上 的 stop() 方 法 也 会 停 止 SparkContext 。 要 仅 停 止StreamingContext(保持 SparkContext 活跃),请将 stop() 方法的可选参数stopSparkContext 设置为 false。
只要前一个 StreamingContext 在下一个 StreamingContext 被创建之前停止(不停止SparkContext),SparkContext就可以被重用来创建多个StreamingContext。
三、DStream 中的转换操作(transformation)
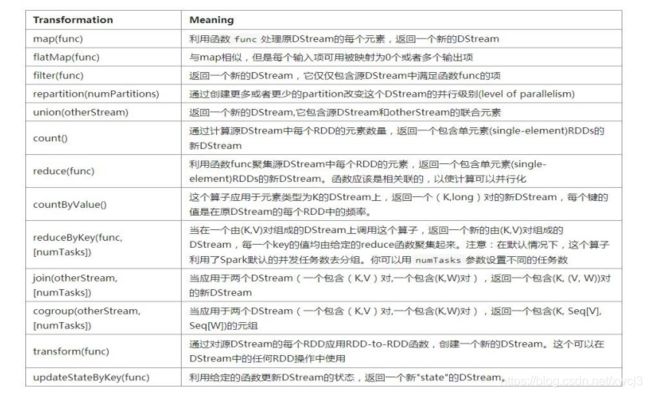
transform(func)
通过 RDD-to-RDD 函数作用于源码 DStream 中的各个 RDD,可以是任意的 RDD 操作,从而返回一个新的 RDD
举例:在 NetworkWordCount 中,也可以使用 transform 来生成元组对
package cm.ccj.pxj
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCountTramform {
def main(args: Array[String]): Unit = {
val pxj = new SparkConf().setAppName("pxj").setMaster("local[4]")
val ssc = new StreamingContext(pxj, Seconds(3))
val datas: ReceiverInputDStream[String] = ssc.socketTextStream("pxj", 8899)
datas.flatMap(_.split(",")).transform(x=>x.map(x=>(x,1))).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
updateStateByKey(func)
操作允许不断用新信息更新它的同时保持任意状态。
定义状态-状态可以是任何的数据类型
定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态
重写 WordCount 程序,累计每个单词出现的频率(注意:累计)
输出结果:
注意:如果在 IDEA 中,不想输出 log4j 的日志信息,可以将 log4j.properties
文件(放在 src 的目录下)的第一行改为:
log4j.rootCategory=ERROR, console
log4j.properties
package cm.ccj.pxj
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object PUpdateStateByKeyDemo {
def main(args: Array[String]): Unit = {
val pxj = new SparkConf().setMaster("local[4]").setAppName("pxj")
val ssc = new StreamingContext(pxj, Seconds(8))
// 设置检查点
ssc.checkpoint("data/bb")
val lines = ssc.socketTextStream("pxj", 8899)
var addfun=(currValues:Seq[Int],prevValueState:Option[Int])=>{
val currentCount = currValues.sum
val prevValueStateCount = prevValueState.getOrElse(0)
Some(currentCount+prevValueStateCount)
}
lines.flatMap(_.split(",")).map((_,1)).updateStateByKey(addfun).print()
ssc.start()
ssc.awaitTermination()
}
}
4、窗口操作
Spark Streaming 还提供了窗口计算功能,允许您在数据的滑动窗口上应用转换操作。下图说明了滑动窗口的工作方式:
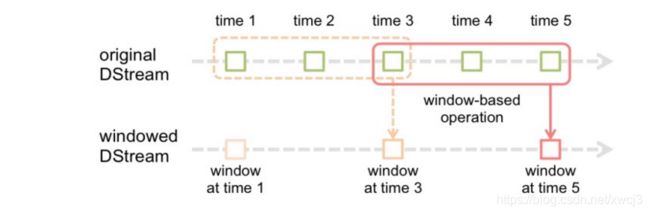
如图所示,每当窗口滑过 originalDStream 时,落在窗口内的源 RDD 被组合并被执行操作以产生 windowed DStream 的 RDD。在上面的例子中,操作应用于最近 3 个时间单位的数据,并以 2 个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
窗口长度(windowlength) - 窗口的时间长度(上图的示例中为:3)。
滑动间隔(slidinginterval) - 两次相邻的窗口操作的间隔(即每次滑动的时间长度)(上图示例中为:2)。这两个参数必须是源 DStream 的批间隔的倍数(上图示例中为:1)。
我们以一个例子来说明窗口操作。 假设您希望对之前的单词计数的示例进行扩展,每 10 秒钟对过去 30 秒的数据进行 wordcount。为此,我们必须在最近 30 秒的 pairs DStream 数 据 中 对 (word, 1) 键 值 对 应 用 reduceByKey 操 作 。 这 是 通 过 使 用reduceByKeyAndWindow 操作完成的。

一些常见的窗口操作如下表所示。所有这些操作都用到了上述两个参数 -
windowLength 和 slideInterval。
window(windowLength, slideInterval)
基于源 DStream 产生的窗口化的批数据计算一个新的 DStream
countByWindow(windowLength, slideInterval)
返回流中元素的一个滑动窗口数
reduceByWindow(func, windowLength, slideInterval)
返回一个单元素流。利用函数 func 聚集滑动时间间隔的流的元素创建这个单元素流。函数必须是相关联的以使计算能够正确的并行计算。 reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的 DStream 上,返回一个由(K,V)对组成的新的DStream。每一个 key 的值均由给定的 reduce 函数聚集起来。注意:在默认情况下,这个算子利用了 Spark 默认的并发任务数去分组。你可以用 numTasks
参数设置不同的任务数
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
上述 reduceByKeyAndWindow() 的更高效的版本,其中使用前一窗口的 reduce计算结果递增地计算每个窗口的 reduce 值。这是通过对进入滑动窗口的新数据进行 reduce 操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数 invFunc)。 像 reduceByKeyAndWindow一样,通过可选参数可以配置 reduce 任务的数量。 请注意,使用此操作必
须启用检查点。
countByValueAndWindow(windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的 DStream 上,返回一个由(K,V)对组成的新的DStream。每个 key 的值都是它们在滑动窗口中出现的频率。
输入 DStreams 和接收器
输入 DStreams 表示从数据源获取输入数据流的 DStreams。NetworkWordCount例子中,lines 表示输入 DStream,它代表从 netcat 服务器获取的数据流。每一个输入流 DStream 和一个 Receiver 对象相关联,这个 Receiver 从源中获取数据,并将数据存入内存中用于处理。输入 DStreams 表示从数据源获取的原始数据流。Spark Streaming 拥有两类数据源:
基本源(Basic sources):这些源在 StreamingContext API 中直接可用。例如文件系统、套接字连接、Akka 的 actor 等
高级源(Advanced sources):这些源包括 Kafka,Flume,Kinesis,Twitter 等等。下面通过具体的案例,详细说明:
文件流:通过监控文件系统的变化,若有新文件添加,则将它读入并作为数据流需要注意的是:
1这些文件具有相同的格式
2这些文件通过原子移动或重命名文件的方式在 dataDirectory 创建
3如果在文件中追加内容,这些追加的新数据也不会被读取。
package cm.ccj.pxj
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FileStreaming {
def main(args: Array[String]): Unit = {
val pxj = new SparkConf().setAppName("pxj").setMaster("local[2]")
val ssc = new StreamingContext(pxj, Seconds(8))
val lines = ssc.textFileStream("data")
lines.print()
ssc.start()
ssc.awaitTermination()
}
}
作者:pxj(潘陈)
日期:2020-02-06 凌晨2:13:45