使用pytorch实现高斯混合模型分类器
本文是一个利用Pytorch构建高斯混合模型分类器的尝试。我们将从头开始构建高斯混合模型(GMM)。这样可以对高斯混合模型有一个最基本的理解,本文不会涉及数学,因为我们在以前的文章中进行过很详细的介绍。
本文将使用这些库
import torch
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
我们将在二维上创建3个不同的高斯分布(a, B, mix),其中mix应该是由a和B组成的分布。
首先,A和B的分布…
n_samples = 1000
A_means = torch.tensor( [-0.5, -0.5])
A_stdevs = torch.tensor( [0.25, 0.25])
B_means = torch.tensor( [0.5, 0.5])
B_stdevs = torch.tensor( [0.25, 0.25])
A_dist = torch.distributions.Normal( A_means, A_stdevs)
A_samp = A_dist.sample( [n_samples])
B_dist = torch.distributions.Normal( B_means, B_stdevs)
B_samp = B_dist.sample( [n_samples])
plt.figure( figsize=(6,6))
for name, sample in zip( ['A', 'B'], [A_samp, B_samp]):
plt.scatter( sample[:,0], sample[:, 1], alpha=0.2, label=name)
plt.legend()
plt.title( "Distinct Gaussian Samples")
plt.show()
plt.close()
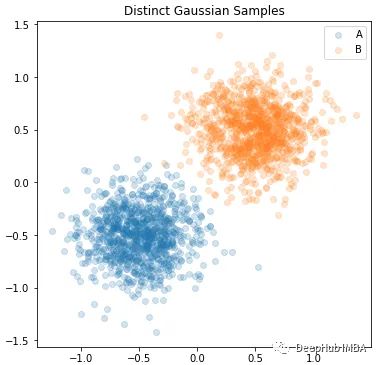
为了创建一个单一的混合高斯分布,我们首先垂直堆叠a和B的均值和标准差,生成新的张量,每个张量的形状=[2,2]。
AB_means = torch.vstack( [ A_means, B_means])
AB_stdevs = torch.vstack( [ A_stdevs, B_stdevs])
pytorch混合分布的工作方式是通过在原始的Normal分布上使用3个额外的分布Independent、Categorical和MixtureSameFamily来实现的。从本质上讲,它创建了一个混合,基于给定Categorical分布的概率权重。因为我们的新均值和标准集有一个额外的轴,这个轴被用作独立的轴,需要决定从中得出哪个均值/标准集的值。
AB_means = torch.vstack( [ A_means, B_means])
AB_stdevs = torch.vstack( [ A_stdevs, B_stdevs])
AB_dist = torch.distributions.Independent( torch.distributions.Normal( AB_means, AB_stdevs), 1)
mix_weight = torch.distributions.Categorical( torch.tensor( [1.0, 1.0]))
mix_dist = torch.distributions.MixtureSameFamily( mix_weight, AB_dist)
在这里用[1.0,1.0]表示Categorical分布应该从每个独立的轴上均匀取样。为了验证它是否有效,我们将绘制每个分布的值…
A_samp = A_dist.sample( (500,))
B_samp = B_dist.sample( (500,))
mix_samp = mix_dist.sample( (500,))
plt.figure( figsize=(6,6))
for name, sample in zip( ['A', 'B', 'mix'], [A_samp, B_samp, mix_samp]):
plt.scatter( sample[:,0], sample[:, 1], alpha=0.3, label=name)
plt.legend()
plt.title( "Original Samples with the new Mixed Distribution")
plt.show()
plt.close()
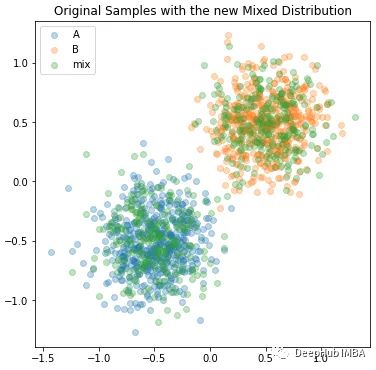
可以看到,的新mix_samp分布实际上与我们原来的两个单独的A和B分布样本重叠。
模型
下面就可以开始构建我们的分类器了
首先需要创建一个底层的GaussianMixModel,它的means、stdev和分类权重实际上可以通过torch backprop和autograd系统进行训练。
class GaussianMixModel( torch.nn.Module):
def __init__(self, n_features, n_components=2):
super().__init__()
self.init_scale = np.sqrt( 6 / n_features) # What is the best scale to use?
self.n_features = n_features
self.n_components = n_components
weights = torch.ones( n_components)
means = torch.randn( n_components, n_features) * self.init_scale
stdevs = torch.rand( n_components, n_features) * self.init_scale
#
# Our trainable Parameters
self.blend_weight = torch.nn.Parameter(weights)
self.means = torch.nn.Parameter(means)
self.stdevs = torch.nn.Parameter(stdevs)
def forward(self, x):
blend_weight = torch.distributions.Categorical( torch.nn.functional.relu( self.blend_weight))
comp = torch.distributions.Independent(torch.distributions.Normal( self.means, torch.abs( self.stdevs)), 1)
gmm = torch.distributions.MixtureSameFamily( blend_weight, comp)
return -gmm.log_prob(x)
def extra_repr(self) -> str:
info = f" n_features={self.n_features}, n_components={self.n_components}, [init_scale={self.init_scale}]"
return info
@property
def device(self):
return next(self.parameters()).device
该模型将返回落在模型的混合高斯分布域中的每个样本的负对数似然。
为了训练它,我们需要从混合高斯分布中提供样本。为了验证它是有效的,将提供一个普遍分布的一批样本,看看它是否可以,哪些样本可能与我们的训练集中的样本相似。
train_means = torch.randn( (4,2))
train_stdevs = (torch.rand( (4,2)) + 1.0) * 0.25
train_weights = torch.rand( 4)
ind_dists = torch.distributions.Independent( torch.distributions.Normal( train_means, train_stdevs), 1)
mix_weight = torch.distributions.Categorical( train_weights)
train_dist = torch.distributions.MixtureSameFamily( mix_weight, ind_dists)
train_samp = train_dist.sample( [2000])
valid_samp = torch.rand( (4000, 2)) * 8 - 4.0
plt.figure( figsize=(6,6))
for name, sample in zip( ['train', 'valid'], [train_samp, valid_samp]):
plt.scatter( sample[:,0], sample[:, 1], alpha=0.2, label=name)
plt.legend()
plt.title( "Training and Validation Samples")
plt.show()
plt.close()
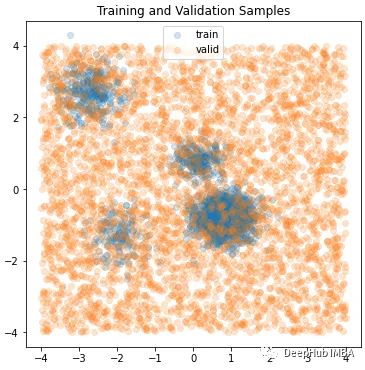
模型只需要一个超参数n_components:
gmm = GaussianMixModel( n_features=2, n_components=4)
gmm.to( 'cuda')
训练的循环也非常简单:
max_iter = 20000
features = train_samp.to( 'cuda')
optim = torch.optim.Adam( gmm.parameters(), lr=5e-4)
metrics = {'loss':[]}
for i in range( max_iter):
optim.zero_grad()
loss = gmm( features)
loss.mean().backward()
optim.step()
metrics[ 'loss'].append( loss.mean().item())
print( f"{i} ) \t {metrics[ 'loss'][-1]:0.5f}", end=f"{' '*20}\r")
if metrics[ 'loss'][-1] < 0.1:
print( "---- Close enough")
break
if len( metrics[ 'loss']) > 300 and np.std( metrics[ 'loss'][-300:]) < 0.0005:
print( "---- Giving up")
break
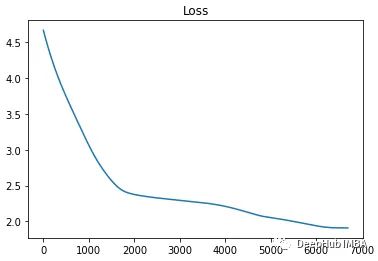
print( f"Min Loss: {np.min( metrics[ 'loss']):0.5f}")
在这个例子中,循环在在1.91043的损失时停止了不到7000次迭代。
如果我们现在通过模型运行valid_samp样本,可以将返回值转换为相对概率,并重新绘制由预测着色的验证数据。
with torch.no_grad():
logits = gmm( valid_samp.to( 'cuda'))
probs = torch.exp( -logits)
plt.figure( figsize=(6,6))
for name, sample in zip( ['pred'], [valid_samp]):
plt.scatter( sample[:,0], sample[:, 1], alpha=1.0, c=probs.cpu().numpy(), label=name)
plt.legend()
plt.title( "Testing Trained model on Validation")
plt.show()
plt.close()
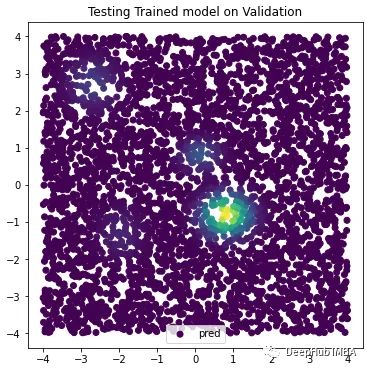
我们的模型已经学会了识别与训练分布区域对应的样本。但是我们还可以进行改进
分类
通过上面的介绍应该已经对如何创建高斯混合模型以及如何训练它有了大致的了解,下一步将使用这些信息来构建一个复合(GMMClassifier)模型,该模型可以学习识别混合高斯分布的不同类别。
这里创建了一个重叠高斯分布的训练集,5个不同的类,其中每个类本身是一个混合高斯分布。
这个GMMClassifier将包含5个不同的GaussianMixModel实例。每个实例都会尝试从训练数据中学习一个单独的类。每个预测将组合成一组分类逻辑,GMMClassifier将使用这些逻辑进行预测。
首先需要对原始的GaussianMixModel做一个小的修改,并将输出从return -gmm.log_prob(x)更改为return gmm.log_prob(x)。因为我们没有在训练循环中直接尝试减少这个值,所以它被用作我们分类分配的logits。
新的模型就变成了……
class GaussianMixModel( torch.nn.Module):
def __init__(self, n_features, n_components=2):
super().__init__()
self.init_scale = np.sqrt( 6 / n_features) # What is the best scale to use?
self.n_features = n_features
self.n_components = n_components
weights = torch.ones( n_components)
means = torch.randn( n_components, n_features) * self.init_scale
stdevs = torch.rand( n_components, n_features) * self.init_scale
#
# Our trainable Parameters
self.blend_weight = torch.nn.Parameter(weights)
self.means = torch.nn.Parameter(means)
self.stdevs = torch.nn.Parameter(stdevs)
def forward(self, x):
blend_weight = torch.distributions.Categorical( torch.nn.functional.relu( self.blend_weight))
comp = torch.distributions.Independent(torch.distributions.Normal( self.means, torch.abs( self.stdevs)), 1)
gmm = torch.distributions.MixtureSameFamily( blend_weight, comp)
return gmm.log_prob(x)
def extra_repr(self) -> str:
info = f" n_features={self.n_features}, n_components={self.n_components}, [init_scale={self.init_scale}]"
return info
@property
def device(self):
return next(self.parameters()).device
我们的GMMClassifier的代码如下:
class GMMClassifier( torch.nn.Module):
def __init__(self, n_features, n_classes, n_components=2):
super().__init__()
self.n_classes = n_classes
self.n_features = n_features
self.n_components = n_components if isinstance( n_components, list) else [n_components] * self.n_classes
self.class_models = torch.nn.ModuleList( [ GaussianMixModel( n_features=self.n_features, n_components=self.n_components[i]) for i in range( self.n_classes)])
def forward(self, x, ret_logits=False):
logits = torch.hstack( [ m(x).unsqueeze(1) for m in self.class_models])
if ret_logits:
return logits
return logits.argmax( dim=1)
def extra_repr(self) -> str:
info = f" n_features={self.n_features}, n_components={self.n_components}, [n_classes={self.n_classes}]"
return info
@property
def device(self):
return next(self.parameters()).device
创建模型实例时,将为每个类创建一个GaussianMixModel。由于每个类对于其特定的高斯混合可能具有不同数量的组件,因此我们允许n_components是一个int值列表,该列表将在生成每个底层模型时使用。例如:n_components=[2,4,3,5,6]将向类模型传递正确数量的组件。为了简化将所有底层模型设置为相同的值,也可以简单地提供n_components=5,这将在生成模型时产生[5,5,5,5,5]。
在训练期间,需要访问logits,因此forward()方法中提供了ret_logits参数。训练完成后,可以在不带参数的情况下调用forward(),以便为预测的类返回一个int值(它只接受logits的argmax())。
我们还将创建一组5个独立但重叠的高斯混合分布,每个类有随机数量的高斯分量。
clusters = [0, 1, 2, 3, 4]
features_group = {}
n_samples = 2000
min_clusters = 2
max_clusters = 10
for c in clusters:
features_group[ c] = []
n_clusters = torch.randint( min_clusters, max_clusters+1, (1,1)).item()
print( f"Class: {c} Clusters: {n_clusters}")
for i in range( n_clusters):
mu = torch.randn( (1,2))
scale = torch.rand( (1,2)) * 0.35 + 0.05
distribution = torch.distributions.Normal( mu, scale)
features_group[ c] += distribution.expand( (n_samples//n_clusters, 2)).sample()
features_group[ c] = torch.vstack( features_group[ c])
features = torch.vstack( [features_group[ c] for c in clusters]).numpy()
targets = torch.vstack( [torch.ones( (features_group[ c].size(0), 1)) * c for c in clusters]).view( -1).numpy()
idxs = np.arange( features.shape[0])
valid_idxs = np.random.choice( idxs, 1000)
train_idxs = [i for i in idxs if i not in valid_idxs]
features_valid = torch.tensor( features[ valid_idxs])
targets_valid = torch.tensor( targets[ valid_idxs])
features = torch.tensor( features[ train_idxs])
targets = torch.tensor( targets[ train_idxs])
print( features.shape)
plt.figure( figsize=(8,8))
for c in clusters:
plt.scatter( features_group[c][:,0].numpy(), features_group[c][:,1].numpy(), alpha=0.2, label=c)
plt.title( f"{n_samples} Samples Per Class, Multiple Clusters per Class")
plt.legend()
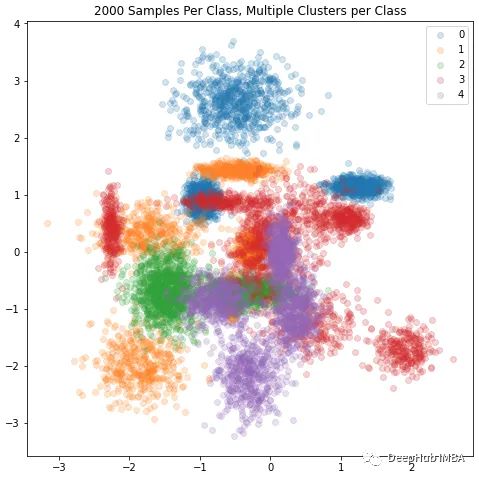
通过运行上面的代码,我们可以知道每个类使用的n_component的数量。在实际中他应该是一个超参数搜索过程,但是这里我们已经知道了,所以我们直接使用它
Class: 0 Clusters: 3
Class: 1 Clusters: 5
Class: 2 Clusters: 2
Class: 3 Clusters: 8
Class: 4 Clusters: 4
然后创建模型:
gmmc = GMMClassifier( n_features=2, n_classes=5, n_components=[3, 5, 2, 8, 4])
gmmc.to( 'cuda')
训练循环也有一些修改,因为这次想要训练由logit预测提供的模型的分类损失。所以需要在监督学习的训练过程中提供目标。
features = features.to( DEVICE)
targets = targets.to( DEVICE)
optim = torch.optim.Adam( gmmc.parameters(), lr=3e-2)
loss_fn = torch.nn.CrossEntropyLoss()
metrics = {'loss':[]}
for i in range(4000):
optim.zero_grad()
logits = gmmc( features, ret_logits=True)
loss = loss_fn( logits, targets.type( torch.long))
loss.backward()
optim.step()
metrics[ 'loss'].append( loss.item())
print( f"{i} ) \t {metrics[ 'loss'][-1]:0.5f}", end=f"{' '*20}\r")
if metrics[ 'loss'][-1] < 0.1:
print( "---- Close enough")
break
print( f"Mean Loss: {np.mean( metrics[ 'loss']):0.5f}")
然后从验证数据中对数据进行分类,验证数据是在创建训练数据时生成的,每个样本基本上都是不同的值,但来自适当的类。
preds = gmmc( features_valid.to( 'cuda'))
查看preds值,可以看到它们是预测类的整数。
print( preds[0:10])
____
tensor([2, 4, 2, 4, 2, 3, 4, 0, 2, 2], device='cuda:1')
最后通过将这些值与targets_valid进行比较,可以确定模型的准确性。
accuracy = (targets_valid == preds).sum() / targets_valid.size(0) * 100.0
print( f"Accuracy: {accuracy:0.2f}%")
____
Accuracy: 81.50%
还可以查看每个类别预测的准确性……
class_acc = {}
for c in range(5):
target_idxs = (targets_valid == c)
class_acc[c] = (targets_valid[ target_idxs] == preds[ target_idxs]).sum() / targets_valid[ target_idxs].size(0) * 100.0
print( f"Class: {c} \t{class_acc[c]:0.2f}%")
----
Class: 0 98.54%
Class: 1 69.06%
Class: 2 86.12%
Class: 3 70.05%
Class: 4 84.09%
可以看到,它在预测重叠较少的类方面做得更好,这是有道理的。并且平均81.5%的准确率也相当不错,因为所有这些不同的类别都是重叠的。我相信还有很多可以改进的地方。如果你有建议,或者可以指出我所犯的错误,请留言。
https://avoid.overfit.cn/post/9edc2bc2d5ea48108cff1a51786ab60d
作者:Todd Shifflett