Flink窗口
- 窗口:
在上一章中已经了解了 Flink 中事件时间和水位线的概念,那它们有什么具体应用呢?当然是做基于时间的处理计算了。其中最常见的场景,就是窗口聚合计算。 之前我们已经了解了 Flink 中基本的聚合操作。在流处理中往往面对的是连续不断、无休无止的无界流,不可能等到所有所有数据都到齐了才开始处理。所以聚合计算其实 只能针对当前已有的数据——之后再有数据到来,就需要继续累加、再次输出结果。这样似乎 很“实时”,但现实中大量数据一般会同时到来,需要并行处理,这样频繁地更新结果就会给 系统带来很大负担了。 更加高效的做法是,把无界流进行切分,每一段数据分别进行聚合,结果只输出一次。这 就相当于将无界流的聚合转化为了有界数据集的聚合,这就是所谓的“窗口”(Window )聚合 操作。窗口聚合其实是对实时性和处理效率的一个权衡。在实际应用中,我们往往更关心一段 时间内数据的统计结果,比如在过去的一 分钟内有多少用户点击了网页。在这种情况下,我们 就可以定义一个窗口,收集最近一分钟内的所有用户点击数据,然后进行聚合统计,最终输出 一个结果就可以了。 在 Flink 中,提供了非常丰富的窗口操作,下面我们就来详细介绍。
-
窗口的概念:
Flink 是一种流式计算引擎,主要是来处理无界数据流。想 要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这 就是所谓的“窗口”(Window)。 在 Flink 中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的 “框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输 出结果。例如,我们定义一个时间窗口,每 10 秒统计一次数据,那么就相当于把窗口放在那 里,从 0 秒开始收集数据;到 10 秒时,处理当前窗口内所有数据,输出一个结果,然后清空 窗口继续收集数据;到 20 秒时,再对窗口内所有数据进行计算处理,输出结果;依次类推, 如图所示。
这里注意为了明确数据划分到哪一个窗口,用数学符号表示就是一个左闭右开的区间,例如 0~10 秒的窗口可以表示为[0, 10),这里单 位为秒。对于处理时间下的窗口而言,这样理解似乎没什么问题。因为窗口的关闭是基于系统时间的,当前窗口关闭就只能去下一个窗口正如上图中,0~10 秒的窗口关闭后,可能还有时间戳为 9 的数据会来,它就只能进入 10~20 秒的窗口了。这样会造成窗口处理结果的不准确。所以我们需要设置一个延迟时间来等所有数据到齐。比如上面的例子中,我们可以设置延迟时间为 2 秒,这样 0~10 秒的窗口会在时间戳为 12 的数据到来之后,才真正关闭计算输出结果,这 样就可以正常包含迟到的 9 秒数据了如图所示。
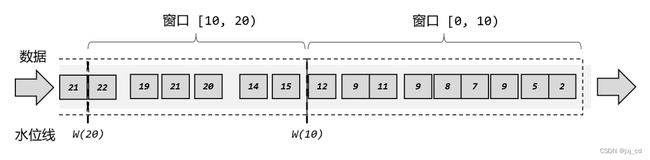 但是这样一来, 0~10 秒的窗口不光包含了迟到的 9 秒数据,连 11 秒和 12 秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。 所以相比之下,我们应该把窗口理解成一个“桶” 。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket) ;每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理如图所示。
但是这样一来, 0~10 秒的窗口不光包含了迟到的 9 秒数据,连 11 秒和 12 秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。 所以相比之下,我们应该把窗口理解成一个“桶” 。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket) ;每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理如图所示。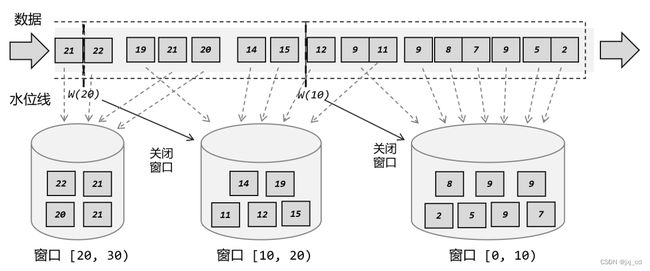 我们可以梳理一下事件时间语义下,之前例子中窗口的处理过程:( 1 )第一个数据时间戳为 2 ,判断之后创建第一个窗口 [0, 10 ),并将 2 秒数据保存进去;(2)后续数据依次到来,时间戳均在 [0, 10 )范围内,所以全部保存进第一个窗口;(3) 11 秒数据到来,判断它不属于 [0, 10 )窗口,所以创建第二个窗口 [10, 20 ),并将 11秒的数据保存进去。由于水位线设置延迟时间为 2 秒,所以现在的时钟是 9 秒,第一个窗口也没有到关闭时间;(4)之后又有 9 秒数据到来,同样进入 [0, 10 )窗口中;(5) 12 秒数据到来,判断属于 [10, 20 )窗口,保存进去。这时产生的水位线推进到了 10秒,所以 [0, 10 )窗口应该关闭了。第一个窗口收集到了所有的 7 个数据,进行处理计算后输出结果,并将窗口关闭销毁;(6)同样的,之后的数据依次进入第二个窗口,遇到 20 秒的数据时会创建第三个窗口 [20,30)并将数据保存进去;遇到 22 秒数据时,水位线达到了 20 秒,第二个窗口触发计算,输出结果并关闭。这里需要注意的是, Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
我们可以梳理一下事件时间语义下,之前例子中窗口的处理过程:( 1 )第一个数据时间戳为 2 ,判断之后创建第一个窗口 [0, 10 ),并将 2 秒数据保存进去;(2)后续数据依次到来,时间戳均在 [0, 10 )范围内,所以全部保存进第一个窗口;(3) 11 秒数据到来,判断它不属于 [0, 10 )窗口,所以创建第二个窗口 [10, 20 ),并将 11秒的数据保存进去。由于水位线设置延迟时间为 2 秒,所以现在的时钟是 9 秒,第一个窗口也没有到关闭时间;(4)之后又有 9 秒数据到来,同样进入 [0, 10 )窗口中;(5) 12 秒数据到来,判断属于 [10, 20 )窗口,保存进去。这时产生的水位线推进到了 10秒,所以 [0, 10 )窗口应该关闭了。第一个窗口收集到了所有的 7 个数据,进行处理计算后输出结果,并将窗口关闭销毁;(6)同样的,之后的数据依次进入第二个窗口,遇到 20 秒的数据时会创建第三个窗口 [20,30)并将数据保存进去;遇到 22 秒数据时,水位线达到了 20 秒,第二个窗口触发计算,输出结果并关闭。这里需要注意的是, Flink 中窗口并不是静态准备好的,而是动态创建——当有落在这个窗口区间范围的数据达到时,才创建对应的窗口。另外,这里我们认为到达窗口结束时间时,窗口就触发计算并关闭,事实上“触发计算”和“窗口关闭”两个行为也可以分开,这部分内容我们会在后面详述。
- 窗口的分类:
在 Flink 中,窗口的应用非常灵活,我们可以使用各种不同类型的窗口来实现需求。接下来我们就从不同的角度,对Flink中内置的窗口做一个分类说明。
- 按照驱动类型分类:
窗口本身是截取有界数据的一种方式。换句话说,就是以什么方式来开始和结束数据的截取,我们把它叫作窗口的“驱动类 型”。 我们最容易想到的就是按照时间段去截取数据,这种窗口就叫作“时间窗口”(Time Window)。之前所举的例子也都是时间窗口。除了由时间驱动之外, 窗口其实也可以由数据驱动,也就是说按照固定的数量,来截取一段数据集,这种窗口叫作“计数窗口”(Count Window),如图所示。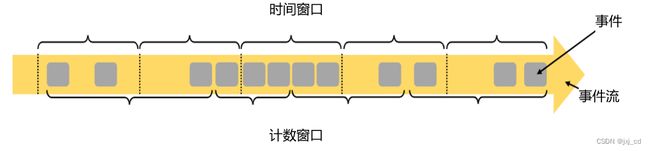
1)时间窗口(Time Window):
时间窗口以时间点来定义窗口的开始时间 和结束时间,截取出的就是某一时间段的数据。到结束时间时, 窗口不再收集数据, 触发计算输出结果, 并将窗口关闭销毁。
用结束时间减去开始时间,得到这段时间的长度, 就是窗口的大小(window size)。这里的时间可以是不同的语义,既可以是处理时间窗口也可以是事件时间窗口。
Flink 中有一个专门的类来表示时间窗口, 名称就叫作 TimeWindow。这个类只有两个私 有属性:start 和 end ,表示窗口的开始和结束的时间戳,单位为毫秒。另外,TimeWindow 还提供了一个 maxTimestamp()方法,用来获取窗口中能够包含数据的最大时间戳
2)计数窗口(Count Window):
计数窗口基于元素的个数来截取数据,到达固定的个数时就触发计算并关闭窗口。每个窗口截取数据的个数,就是窗口的大小。
计数窗口相比时间窗口就更加简单,只需指定窗口大小,就可以把数据分配到对应的窗口中了。在 Flink 内部也并没有对应的类来表示计数窗口,底层是通过“全局窗口”(Global Window)来实现的。 - 按照窗口分配数据的规则分类:
时间窗口和计数窗口,只是对窗口的一个大致划分;在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配方式,就可以有不同的功能。根据分配数据的规则,窗口的具体实现可以分为 4 类:滚动窗口( Tumbling Window )、滑动窗口( Sliding Window )、会话窗口( Session Window ),以及全局窗口( Global Window )。下面我们来做具体介绍。1)滚动窗口(Tumbling Windows):滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动, 那就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚 动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只 会属于一个窗口。 滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有一个,就是窗口 的大小(window size )。比如我们可以定义一个长度为 1 小时的滚动时间窗口,那么每个小时 就会进行一次统计;或者定义一个长度为 10 的滚动计数窗口,就会每 10 个数进行一次统计。
 如上图 所示,小圆点表示流中的数据,我们对数据按照 userId 做了分区。当固定了窗4)全局窗口(Global Windows):
如上图 所示,小圆点表示流中的数据,我们对数据按照 userId 做了分区。当固定了窗4)全局窗口(Global Windows):口大小之后,所有分区的窗口划分都是一致的;窗口没有重叠,每个数据只属于一个窗口。 滚动窗口应用非常广泛,它可以对每个时间段做聚合统计,很多 BI 分析指标都可以用它 来实现。
2)滑动窗口(Sliding Windows):
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的, 而是可以“错开”一定的位置。滑动窗口的参数有两个:除去窗口大小(window size)之外,还有一个“滑动步长”(window slide),它其实就代表了窗口计算的频率。滑动的距离代表了下个窗口开始的时间间隔,而窗口大小是固定的,所 以也就是两个窗口结束时间的间隔;窗口在结束时间触发计算输出结果,那么滑动步长就代表了计算频率。例如,我们定义一个长度为 1 小时、滑动步长为 5 分钟的滑动窗口,那么就会统 计1 小时内的数据,每 5 分钟统计一次。同样,滑动窗口可以基于时间定义,也可以基于数据个数定义。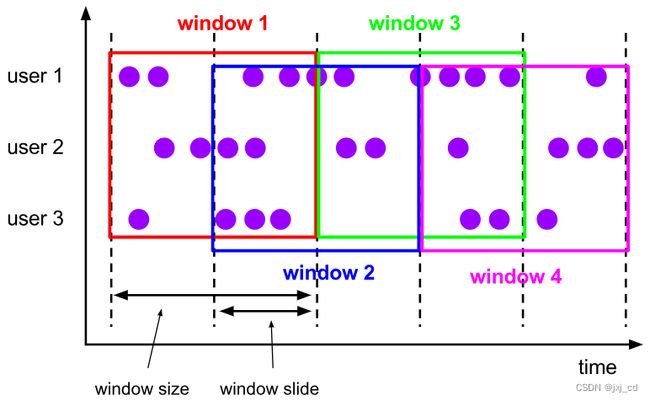 可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值( size/slide )来决 定。如图上所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到 2 个窗口里。比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点 , 9 点 ) 和 [8 点半 , 9 点半 ) 两个窗口;而对于 8 点 10 分的数据,则同时属于 [8点, 9 点 ) 和 [7 点半 , 8 点半 ) 两个窗口。 所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看 作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide )。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不 属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小, 并尽量设置为整数倍的关系。
可以看到,当滑动步长小于窗口大小时,滑动窗口就会出现重叠,这时数据也可能会被同时分配到多个窗口中。而具体的个数,就由窗口大小和滑动步长的比值( size/slide )来决 定。如图上所示,滑动步长刚好是窗口大小的一半,那么每个数据都会被分配到 2 个窗口里。比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点 , 9 点 ) 和 [8 点半 , 9 点半 ) 两个窗口;而对于 8 点 10 分的数据,则同时属于 [8点, 9 点 ) 和 [7 点半 , 8 点半 ) 两个窗口。 所以,滑动窗口其实是固定大小窗口的更广义的一种形式;换句话说,滚动窗口也可以看 作是一种特殊的滑动窗口——窗口大小等于滑动步长(size = slide )。当然,我们也可以定义滑动步长大于窗口大小,这样的话就会出现窗口不重叠、但会有间隔的情况;这时有些数据不 属于任何一个窗口,就会出现遗漏统计。所以一般情况下,我们会让滑动步长小于窗口大小, 并尽量设置为整数倍的关系。
3)会话窗口(Session Windows):会话窗口顾名思义,是基于“会话”( session)来来对数据进行分组的。是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来那么就一直保持会话;如果一段时间没收到数据,那就认为会话超时失效,窗口自动关闭。与滑动窗口和滚动窗口不同,会话窗口只能基于时间来定义,而没有“会话计数窗口”的概念。这很好理解,“会话”终止的标志就是“隔一段时间没有数据来”,如果不依赖时间而改成个数,就成了“隔几个数据没有数据来”,这完全是自相矛盾的说法。 而同样是基于这个判断标准,这“一段时间”到底是多少就很重要了,必须明确指定。考虑到事件时间语义下的乱序流,这里又会有一些麻烦。相邻两个数据的时间间隔 gap大于指定的 size ,我们认为它们属于两个会话窗口,前一个窗口就关闭;可在数据乱序的情况 下,可能会有迟到数据,它的时间戳刚好是在之前的两个数据之间的。这样一来,之前我们判 断的间隔中就不是“一直没有数据”,而缩小后的间隔有可能会比 size 还要小——这代表三个 数据本来应该属于同一个会话窗口。所以 Flink 底层,对会话窗口的处理会比较特殊:每来一个新的数据,都会创建一个新的会话窗口;然后判断已有窗口之间的距离,如果小于给定的 size ,就对它们进行合并( merge )操作。在 Window 算子中,对会话窗口会有单独的处理逻辑。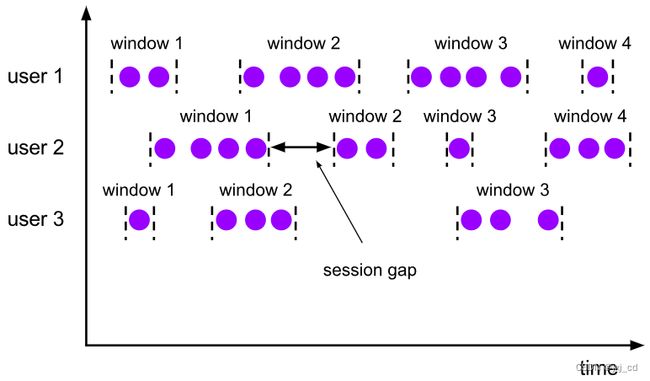
可以看到,与前两种窗口不同,会话窗口的长度不固定,起始和结束时间也是不确定 的,各个分区之间窗口没有任何关联。如图上图所示,会话窗口之间一定是不会重叠的,而 且会留有至少为 size 的间隔(session gap)。 在一些类似保持会话的场景下,往往可以使用会话窗口来进行数据的处理统计。
还有一类比较通用的窗口,就是“全局窗口”。这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以 这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger )。
 可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口( Count Window ),底层就是用全局窗口实现的。
可以看到,全局窗口没有结束的时间点,所以一般在希望做更加灵活的窗口处理时自定义使用。Flink 中的计数窗口( Count Window ),底层就是用全局窗口实现的。
-
窗口 API 概览:
已经了解了 Flink 中窗口的概念和分类,接下来我们就要看看在代码中怎样使用。1) 按键分区( Keyed )和非按键分区( Non-Keyed)在定义窗口操作之前,首先需要确定,到底是基于按键分区( Keyed )的数据流 KeyedStream 来开窗,还是直接在没有按键分区的 DataStream 上开窗。也就是说,在调窗口算子之前, 是否有 keyBy 操作。- 按键分区窗口(Keyed Windows):
经过按键分区 keyBy 操作后,数据流会按照 key 被分为多条逻辑流(logical streams),就是 KeyedStream。基于 KeyedStream 进行窗口操作时, 窗口计算会在多个并行子任务上同时执行。相同 key 的数据会被发送到同一个并行子任务,而窗口操作会基于每个 key 进行单独的处理。所以可以认为,每个 key 上都定义了一组窗口,各自独立地进行统计计算。在代码实现上,我们需要先对 DataStream 调用.keyBy()进行按键分区,然后再调用.window()定义窗口。stream.keyBy(...) .window(...) - 非按键分区(Non-Keyed Windows):
如果没有进行 keyBy ,那么原始的 DataStream 就不会分成多条逻辑流。这时窗口逻辑只 能在一个任务(task )上执行,就相当于并行度变成了 1 。所以在实际应用中一般不推荐使用这种方式。 在代码中,直接基于 DataStream 调用 .windowAll() 定义窗口。
stream.windowAll(...)
2)代码中窗口 API 的调用:
接下来我们就可以真正在代码中实现一个窗口操作了。简单来说,窗口 操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)。stream.keyBy() .window( ) .aggregate( ) 其中 .window() 方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的 .aggregate() 方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式, 窗口函数的调用方法也不只.aggregate() 一种。另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy ,后面调用 .window() 时直接换成.windowAll() 就可以了
- 按键分区窗口(Keyed Windows):
- 窗口分配器(Window Assigners):
定义窗口分配器( Window Assigners )是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。 窗口分配数据的规则,其实就对 应着不同的窗口类型。 窗口分配器最通用的定义方式,就是调用.window() 方法。这个方法需要传入一个 WindowAssigner 作为参数,返回 WindowedStream 。如果是非按键分区窗口,那么直接调用 .windowAll() 方法,同样传入一个 WindowAssigner ,返回的是 AllWindowedStream 。窗口按照驱动类型可以分成时间窗口和计数窗口,而按照具体的分配规则,又有滚动窗口、滑动窗口、会话窗口、全局窗口四种。除去需要自定义的全局窗口外,其他常用的类型 Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
- 时间窗口:
1、滚动时间窗口:
窗口分配器由类 TumblingProcessingTimeWindows 提供,需要调用它的静态方法.of()。
这里.of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小, 我们这里创建 了一个长度为 5 秒的滚动窗口。stream.keyBy(...) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .aggregate (...)
2、滑动处理时间窗口:
窗口分配器由类 SlidingProcessingTimeWindows 提供,同样需要调用它的静态方法.of()。stream.keyBy(...) .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) .aggregate (...)这里.of()方法需要传入两个 Time 类型的参数:size 和 slide ,前者表示滑动窗口的大小, 后者表示滑动窗口的滑动步长。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。
3、处理时间会话窗口
窗口分配器由类 ProcessingTimeSessionWindows 提供,需要调用它的静态方法.withGap() 或者.withDynamicGap()。
这里.withGap()方法需要传入一个 Time 类型的参数 size,表示会话的超时时间,也就是最 小间隔 session gap。我们这里创建了静态会话超时时间为 10 秒的会话窗口。stream.keyBy(...) .window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))) .aggregate (...).
这里.withDynamicGap()方法需要传入一个 SessionWindowTimeGapExtractor 作为参数,用 来定义 session gap 的动态提取逻辑。在这里, 我们提取了数据元素的第一个字段, 用它的长 度乘以 1000 作为会话超时的间隔。.window(ProcessingTimeSessionWindows.withDynamicGap( new SessionWindowTimeGapExtractor
4、滚动事件时间窗口:
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口一致。
5、滑动事件时间窗口:stream.keyBy(...) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .aggregate (...)
窗口分配器由类 SlidingEventTimeWindows 提供, 用法与滑动处理事件窗口一致。
6、事件时间会话窗口stream.keyBy(...) .window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) .aggregate (...)
窗口分配器由类 EventTimeSessionWindows 提供, 用法与处理事件会话窗口一致。stream.keyBy(...) .window(EventTimeSessionWindows.withGap(Time.seconds(10))) .aggregate (...) - 计数窗口:
计数窗口概念非常简单, 本身底层是基于全局窗口(Global Window) 实现的。Flink 为我 们提供了非常方便的接口:直接调用.countWindow()方法。根据分配规则的不同, 又可以分为 滚动计数窗口和滑动计数窗口两类。
1、滚动计数窗口:stream.keyBy(...) .countWindow(10)定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发计算执行并关闭窗口。
2、滑动计数窗口:
与滚动计数窗口类似,不过需要在.countWindow()调用时传入两个参数: size 和 slide,前者表示窗口大小,后者表示滑动步长。
定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每 隔 3个数据就统计输出一次结果。stream.keyBy(...) .countWindow(10,3)
3、全局窗口:
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接调 用.window(),分配器由 GlobalWindows 类提供。
注意使用全局窗口, 必须自行定义触发器才能实现窗口计算, 否则起不到任何作用。stream.keyBy(...) .window(GlobalWindows.create());
- 时间窗口:
- 窗口函数(Window Functions):
定义了窗口分配器, 我们只是知道了数据属于哪个窗口, 可以将数据收集起来了;至于收集起来干什么 必须再接上一个定义窗口如何进行计算的操作, 这就是所谓的“窗口函数”(window functions)。
经窗口分配器处理之后,数据可以分配到对应的窗口中, 而数据流经过转换得到的数据类 型是 WindowedStream。这个类型并不是 DataStream,所以并不能直接进行其他转换,而必须 进一步调用窗口函数,对收集到的数据进行处理计算之后,才能最终再次得到 DataStream,如 图 所示。
窗口函数定义了要对窗口中收集的数据做的计算操作,根据处理的方式可以分为两类:增量聚合函数和全窗口函数。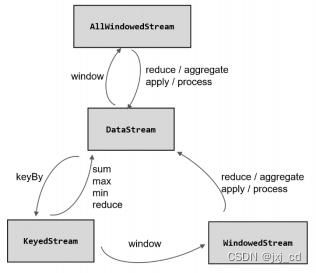
1、增量聚合函数(incremental aggregation functions)窗口将数据收集起来,最基本的处理操作当然就是进行聚合。窗口对无限流的切分,可以 看作得到了一个有界数据集。如果我们等到所有数据都收集齐,在窗口到了结束时间要输出结 果的一瞬间再去进行聚合,显然就不够高效了——这相当于真的在用批处理的思路来做实时流 处理。
为了提高实时性,可以每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是 在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候, 只需要拿出之前聚合的状态直接输出,这就大大提高了程序运行的效率和实时性。
典型的增量聚合函数有两个: ReduceFunction 和 AggregateFunction。
1)归约函数(ReduceFunction):
最基本的聚合方式就是归约,就是将窗口中收集到的数据两两进行归约。当我们进行流处 理时, 就是要保存一个状态; 每来一个新的数据, 就和之前的聚合状态做归约, 这样就实现了增量式的聚合。
窗口函数中也提供了 ReduceFunction:只要基于 WindowedStream 调用.reduce()方法, 然 后传入 ReduceFunction 作为参数,就可以指定以归约两个元素的方式去对窗口中数据进行聚 合了。这里的 ReduceFunction 其实与简单聚合时用到的 ReduceFunction 是同一个函数类接口, 所以使用方式也是完全一样的。
2)聚合函数(AggregateFunction):
ReduceFunction 可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。这就迫使我们必须在聚合前, 先将数据转换(map) 成预期结果类型; 而在有些情况下, 还需要对状态进行进一步处理才能得到输出结果,这时它们的类型可能不同, 使用ReduceFunction 就会非常麻烦。Flink 的 Window API 中的 aggregate 就提供了这样的操作。直接基于 WindowedStream 调 用 .aggregate() 方法 ,就可以定义更加灵活的窗口 聚合操作 。这个方法 需要传入 一个 AggregateFunction 的实现类作为参数。AggregateFunction 在源码中的定义如下:
public interface AggregateFunctionAggregateFunction 可以看作是 ReduceFunction 的通用版本,这里有三种类型:输入类型( IN )、累加器类型( ACC )和输出类型( OUT )。输入类型 IN 就是输入流中元素的数据类型; 累加器类型 ACC 则是我们进行聚合的中间状态类型;而输出类型当然就是最终计算结果的类 型了。2、 全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗 口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。很明显,这就是典型的批处理思路了——先攒数据,等一批都到齐了再正式启动处理流程。 这样做毫无疑问是低效的。
那为什么还需要有全窗口函数呢?因为有些场景下,我们要做的计算必须基于全部的 数据才有效,这时做增量聚合就没什么意义了;另外, 输出的结果有可能要包含上下文中的一 些信息(比如窗口的起始时间),这是增量聚合函数做不到的。所以,我们还需要有更丰富的 窗口计算方式, 这就可以用全窗口函数来实现。
全窗口函数也有两种:WindowFunction 和 ProcessWindowFunction。
1)窗口函数(WindowFunction):
WindowFunction 字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可 以基于 WindowedStream 调用.apply()方法, 传入一个 WindowFunction 的实现类。public interface WindowFunctionvar3, Collector var4) throws Exception; } 当窗口到达结束时间需要触发计算时,就会调用这里的 apply 方法。我们可以从 input 集 合中取出窗口收集的数据,结合 key 和 window 信息,通过收集器(Collector)输出结果。WindowFunction 能提供的上下文信息较少, 也没有更高级的功能。 事实上,它的作用可以被 ProcessWindowFunction 全覆盖,所以之后可能会逐渐弃用。一般在 实际应用, 直接使用 ProcessWindowFunction 就可以了。
2)处理窗口函数(ProcessWindowFunction):
ProcessWindowFunction 是 Window API 中最底层的通用窗口函数接口。之所以说它“最底 层”,是因为除了可以拿到窗口中的所有数据之外, ProcessWindowFunction 还可以获取到一个“上下文对象”(Context)。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当 前的时间和状态信息。这里的时间就包括了处理时间(processing time)和事件时间水位线(event time watermark)。这就使得 ProcessWindowFunction 更加灵活、功能更加丰富。public abstract class ProcessWindowFunctionvar3, Collector var4) throws Exception; public void clear(ProcessWindowFunction - 触发器:
触发器主要是用来控制窗口什么时候触发计算。所谓的“触发计算”,本质上就是执行窗口函数,基于 WindowedStream 调用 .trigger() 方法,就可以传入一个自定义的窗口触发器( Trigger )。
stream.keyBy(...) .window(...) .trigger(new MyTrigger())Trigger 是窗口算子的内部属性,每个窗口分配器( WindowAssigner )都会对应一个默认的触发器;对于 Flink 内置的窗口类型,触发器都已经做了实现。例如,所有事件时间窗口,默认的触发器都是 EventTimeTrigger ;类似还有 ProcessingTimeTrigger 和 CountTrigger。
-
移除器(Evictor):
移除器主要用来定义移除某些数据的逻辑。基于 WindowedStream 调用.evictor()方法, 就 可以传入一个自定义的移除器(Evictor)。Evictor 是一个接口, 不同的窗口类型都有各自预实现的移除器。stream.keyBy(...) .window(...) .evictor(new MyEvictor())默认情况下,预实现的移除器都是在执行窗口函数(window fucntions) 之前移除数据的。
-
允许延迟(Allowed Lateness):
在事件时间语义下, 窗口中可能会出现数据迟到的情况。这是因为在乱序流中,水位线 (watermark) 并不一定能保证时间戳更早的所有数据不会再来。当水位线已经到达窗口结束时间时, 窗口会触发计算并输出结果, 这时一般窗口也就销毁了; 如果窗口关闭之后, 又有属于本窗口的数据,默认情况下就会被丢弃。
在多数情况下,直接丢弃数据会导致统计结果不准确,为了解决迟到数据的问题, Flink 提供了一个特殊的接口, 可以为窗口算子设置一个 “允许的最大延迟”(Allowed Lateness)。也就是说,我们可以设定允许延迟一段时间,在这段时间内,窗口不会销毁, 继续到来的数据依然可以进入窗口中并触发计算。直到水位线推进到 了 窗口结束时间 + 延迟时间, 才真正将窗口的内容清空,正式关闭窗口。
基于 WindowedStream 调用.allowedLateness()方法, 传入一个 Time 类型的延迟时间, 就可 以表示允许这段时间内的延迟数据。stream.keyBy(...) .window(TumblingEventTimeWindows.of(Time.hours(1))) .allowedLateness(Time.minutes(1))比如上面的代码中, 定义了 1 小时的滚动窗口,并设置了允许 1 分钟的延迟数据。在不考虑水位线延迟的情况下, 对于 8 点~9 点的窗口, 本来应该是水位线到达 9 点 整就触发计算并关闭窗口;现在允许延迟 1 分钟,那么 9 点整就只是触发一次计算并输出结果, 并不会关窗。后续到达的数据, 只要属于 8 点~9 点窗口, 依然可以在之前统计的基础上继续 叠加,并且再次输出一个更新后的结果。直到水位线到达了 9 点零 1 分,这时就真正清空状态、关闭窗口, 之后再来的迟到数据就会被丢弃了。
-
侧输出流
即使可以设置窗口的延迟时间, 终归还是有限的,后续的数据还是会被丢弃。如果不想丢弃任何一个数据, 又该怎么做呢? Flink 还提供了另外一种方式处理迟到数据。可以将未收入窗口的迟到数据,放入“侧 输出流”(side output)进行另外的处理。所谓的侧输出流,相当于是数据流的一个“分支”, 这个流中单独放置那些本该被丢弃的数据。 - 窗口的生命周期:
1、 窗口的创建
窗口的类型和基本信息由窗口分配器(window assigners) 指定, 但窗口不会预先创建好, 而是由数据驱动创建。当第一个应该属于这个窗口的数据元素到达时, 就会创建对应的窗口。2、窗口计算的触发
除了窗口分配器,每个窗口还会有自己的窗口函数(window functions)和触发器(trigger)。 窗口函数可以分为增量聚合函数和全窗口函数,主要定义了窗口中计算的逻辑;而触发器则是 指定调用窗口函数的条件。3. 窗口的销毁
一般情况下,当时间达到了结束点,就会直接触发计算输出结果、进而清除状态销毁窗口。 这时窗口的销毁可以认为和触发计算是同一时刻。这里需要注意,Flink 中只对时间窗口 (TimeWindow) 有销毁机制; 由于计数窗口(CountWindow) 是基于全局窗口(GlobalWindw) 实现的,而全局窗口不会清除状态, 所以就不会被销毁。在特殊的场景下,窗口的销毁和触发计算会有所不同。事件时间语义下, 如果设置了允许 延迟,那么在水位线到达窗口结束时间时,仍然不会销毁窗口;窗口真正被完全删除的时间点, 是窗口的结束时间加上用户指定的允许延迟时间。