数据科学中常用的应用统计知识
随着大数据算法技术发展,数据算法越来越倾向机器学习和深度学习相关的算法技术,概率论和应用统计 等传统的技术貌似用的并不是很多了,但实则不然,在数据科学工作,还是会经常需要应用统计概率相关知识解决一些数据问题,例如 A/B试验的显著性计算,因果推断等等,故在此,笔者结合自己应用经验,对数据科学工作中常用到的应用统计知识做一个简单的归纳和总结。
文章目录
-
- 随机抽样和样本偏差
-
- 术语定义
- 误差和偏差
- 有偏估计和 无偏估计
- 抽样分布
-
- 术语定义
- 中心极限定理
- 自助法(bootstrap)
-
- 术语定义
- 自助法用于均值估计
- 特点
- 置信区间
-
- 术语定义
- 特点
- 统计显著性
-
- 标准误差
- 显著性检验思路
-
- 显著性检验用来干啥
- 术语定义
- 零假设
- 备用假设
- 重抽样
- 置换校验:数据科学的最后防线
- 统计显著性和 p p p值
-
- p p p值
- α \alpha α 值
- 数据科学与 p p p值
- 各种显著性检验方法
-
- 显著性检验与随机假设关系
- 显著性校验流程
- Z Z Z 检验
- t t t 检验
- 卡方检验
- 参考
随机抽样和样本偏差
术语定义
- 元素:数据中最小单位
- 样本:大型数据集中一个子集
- 总体:一个大型数据集
- N N N(或者 n n n):一般用 N N N 表示总体规模, n n n 表示样本规模
- 随机抽样:从总体中抽取元素到子集中
- 分层抽样:对总体分层,并在每层中做随机抽样
- 样本偏差:样本对总体作出了错误的估计
- 样本均值: x ˉ \bar{x} xˉ
- 总体均值: μ \mu μ
误差和偏差
-
偏差(Bias):偏差是指预测值或估计值的期望与真实值之间的差异。这种差异通常是系统性的,即它不是随机出现的,而是由于模型的过度简化或者某种系统性的误解导致的。例如,如果你在测量一个物体的长度时,你的尺子始终比真实的尺子短1厘米,那么你的测量结果就会有一个系统性的偏差。
-
随机误差(Random Error):随机误差是指预测值或估计值与其期望之间的差异。这种差异是随机的,即它没有固定的模式,而是由于随机因素(如测量误差或样本的随机性)导致的。在上述的测量例子中,如果你的尺子没有偏差,但由于你每次测量时的角度、力度等因素的不同,导致你的测量结果在真实长度的前后波动,那么这种波动就是随机误差。
-
误差(Error):误差是一个更广泛的概念,它包括了偏差和随机误差两部分。也就是说,误差是指预测值或估计值与真实值之间的总体差异。在统计模型中,我们通常假设误差项是由偏差和随机误差两部分组成的。
总的来说,偏差、随机误差和误差都是描述预测或估计的准确性的重要概念。在进行数据分析和建模时,我们通常希望降低偏差和随机误差,以提高预测或估计的准确性。
有偏估计和 无偏估计
先看定义:
-
无偏估计(Unbiased Estimation):如果一个估计量的期望值等于被估计参数的真实值,那么这个估计量就被称为无偏估计。换句话说,无偏估计在多次重复实验中的平均值会接近真实的参数值。例如,样本均值就是总体均值的无偏估计。
-
有偏估计(Biased Estimation):如果一个估计量的期望值不等于被估计参数的真实值,那么这个估计量就被称为有偏估计。也就是说,有偏估计在多次重复实验中的平均值会偏离真实的参数值。例如,样本方差(除以n而不是n-1)就是总体方差的有偏估计。
所以由上面可知,无论是有偏估计还是无偏估计,都会和真实值有误差,但是不同在于有偏产生的是系统性偏差,而无偏产生的是随机误差。
以射击场景举例,下图虽有误差,但是误差是随机的,分布比较均衡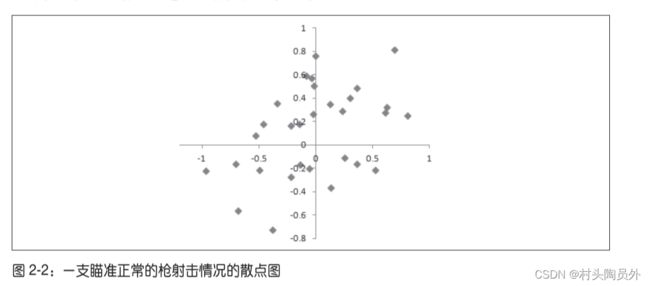
下图则不仅存在随机误差,还存在偏差,主要分布在右上角趋势

数学上的解释推荐看:简述无偏估计和有偏估计
抽样分布
术语定义
- 样本统计量:对抽取自大规模总体中的样本做计算,所得到的一些度量值,比如均值,方差等统计量
- 数据分布:单个元素在数据集上的频数分布
- 抽样分布:在多次抽样得到多个样本,每个样本上得到统计量,由此得到样本统计量的分布(频数分布)
区分单个数据点的分布(即数据分布)和样本统计量的分布(即抽样分布) 非常重要。
中心极限定理
一组独立且同分布的随机变量(每个随机变量的期望和方差都存在),即使这些随机变量本身不是正态分布,当这些随机变量数量 n n n 很大时,其均值统计量的抽样分布趋近于正态分布。
- 随机变量 独立同分布
- 不要求总体分布呈正态分布
- 样本规模越大,均值分布越窄
一定要注意,这里指的是 在 这些随机变量上,得到的 均值 这个统计量的 抽样分布 趋向于正态分布。由此这些 随机变量的求和这个统计量 的抽样分布,也是 趋向于 正态分布。
通常,样本统计量(如均值等)的分布要比数据本身的分布更加规则,分布的形状更趋向 于正态分布的钟形曲线。统计所基于的样本规模越大,上面的观点就愈发成立。此外,样本的规模越大,样本统计量的分布就越窄
自助法(bootstrap)
要估计统计量或模型参数的抽样分布,一个简单而有效的方法是,从样本本身中有放回地抽取更多的样本,并对每次重抽样重新计算统计量或模型。这一过程被称为自助法。自助法无须假设数据或抽样统计量符合正态分布
术语定义
- 自助样本(bootstrap sample):从观测数据集中做有放回的抽取而得到的样本
- 重抽样:在观测数据中重复抽取样本的过程,其中包括自助过程和置换(混洗)过程,即又放回的抽样过程
自助法用于均值估计
使用自助法对规模为 n n n的样本做均值重抽样的算法实现如下:
- 抽取一个样本值,记录后放回总体
- 重复 n n n 次
- 记录 n n n 个重抽样的均值
- 重复步骤 1 ~ 3 1 ~ 3 1~3 多次,例如 r r r 次
- 使用 r r r 个结果:
- 计算它们的标准偏差(估计抽样均值的标准误差)
- 生成直方图或箱线图
- 找出置信区间
我们称 r r r为自助法的迭代次数, r r r的值可任意指定。迭代的次数越多,对标准误差或置信区间的估计就越准确。上述过程的结果给出了样本统计量或估计模型参数的一个自助集,可以从该自助集查看统计量或参数的变异性。
虽然Bootstrap法不需要假设数据或抽样统计量符合特定的分布,但它仍然有一些假设和限制。例如,Bootstrap法假设原始数据是一个对总体的良好代表,也就是说,原始数据中的观察结果是独立同分布的。如果这个假设不成立,那么Bootstrap法可能会给出误导性的结果。
特点
- 自助法(即对数据集做有放回的抽样)是一种评估样本统计量变异性的强大工具
- 自助法可以类似的方式应用于各种场景中,无须深入探究抽样分布的数学近似
- 自助法可以在不使用数学近似的情况下,估计统计量的抽样分布
- 用于预测模型时,聚合多个自助样本的预测(即 Bagging 方法),要优于使用单个模型的预测
置信区间
要了解一个样本估计量中潜在的误差情况,除了使用频数表、直方图、箱线图 和标准误差等方法外,还有一种方法是置信区间。
术语定义
- 置信水平:以百分比表示的置信区间。该区间是从同一总体中以同一方式构建的(多次抽样得到的样本中得到抽样分布),可以包含我们感兴趣的统计量
- 区间端点:置信区间的两端
其实就是 由抽样分布得到某一范围,用该范围来估计统计量。故抽样原理是置信区间的实现基础,这种范围覆盖形式更具确定性。
特点
- 置信区间是一种以区间范围表示估计量的常用方法
- 数据越多,样本估计量的变异性越小
- 所能容忍的置信水平越低,置信区间就越狭小
- 自助法是一种构建置信区间的有效方法
统计显著性
上面讲到 中心极限定理时,提到样本规模越大,均值分布越窄
标准误差
我们从 Lending Club Loan Data拉取数据,用里面的"annual_inc"列数据做实验。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("loan.csv")
sample_data = df['annual_inc'].sample(1000, random_state=2023)
plt.hist(sample_data, 30, alpha = 0.5, label='data') # 原始数据点分布
# 从5*1000个数据元素中,每次随机抽取5个元素(样本规模),组成一个小组,总共得到1000 个小组,每个小组里求平均
sample_data5 = df['annual_inc'].sample(1000*5, random_state=2023)
index = np.array([[j for i in range(5)] for j in range(1000)]).flatten()
tmp_df = pd.DataFrame(columns=['data_5', 'index'])
tmp_df['data_5'] = sample_data5
tmp_df['index'] = index
sample_data5_res = tmp_df.groupby('index')['data_5'].mean().reset_index() # 得到平均值分布(样本规模为5)
# 从20*1000个数据元素中,每次随机抽取20个元素(样本规模),组成一个小组,总共得到1000 个小组,每个小组里求平均
sample_data20 = df['annual_inc'].sample(1000*20, random_state=2023)
index = np.array([[j for i in range(20)] for j in range(1000)]).flatten()
tmp_df = pd.DataFrame(columns=['data_20', 'index'])
tmp_df['data_20'] = sample_data20
tmp_df['index'] = index
sample_data20_res = tmp_df.groupby('index')['data_20'].mean().reset_index()# 得到平均值分布(样本规模为20)
plt.hist(sample_data_res['data_5'], 30, alpha = 0.5, label='data_5')
plt.hist(sample_data_res['data_20'], 30, alpha = 0.5, label='data_20')
plt.legend(loc='upper left')
plt.show()
我们先来看看 原始数据点分布:
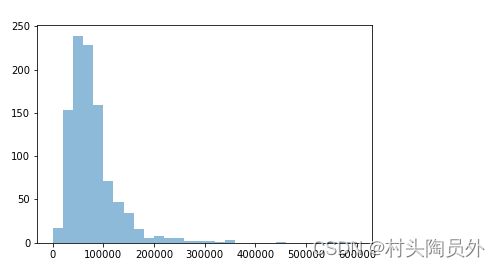
再来看看,样本规模为5 VS 样本规模为20的均值分布:
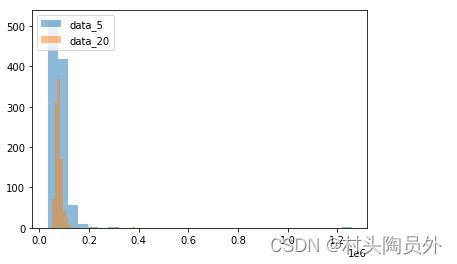
显然,单值的原始数据点分布比较宽泛一点,样本规模为20的均值分布明显比样本规模为5的均值分布要窄很多,符合上面中心极限定理的说法。
随着样本规模越来越大,均值分布也越来越窄,故其越来越接近总体的真正均值。
由此引入标准误差定义:标准误差是一种单变量度量,它总结了单个统计量抽样分布的变异性,可用于度量一个统计量(如样本均值)的精度或稳定性
标准误差 计算公式: s n \frac{s}{\sqrt{n}} ns
其中 s s s 表示标准偏差(统计量标准差), n n n 表示样本规模。
实验上,就是以相同规模,多次自助法抽样,得到 统计量的分布。
上面讲到,样本规模与真实值的关系,样本规模越大越接近真实值,故不难理解在计算 标准误差 时为何除以 n \sqrt{n} n,样本规模越大,标准误差越小。
标准误差 不仅仅 针对均值 这个统计量
其实也很容易理解 标准误差:统计量分布离散度越低,样本规模越大,显然统计量分布就越集中,自然 误差就越小
理解 标准误差 的数学意义 对理解后面内容至关重要。
显著性检验思路
显著性检验用来干啥
判断样本数据是否具有统计学上的显著差异。它帮助我们确定一个观察到的差异是否是由于真实的效应,而不是由于随机因素引起的。避免数据研究人员受到随机性的愚弄。
术语定义
- 零假设:完全归咎于偶然/随机性的假设
- 备用假设:与零假设相反,即实验者希望证明的假设
零假设
假设检验使用的逻辑是:“鉴于人们倾向于对异常的随机行为做出反应,并将其解释为有意义的真实行为,我们要在A/B实验中证明,组间差异要比偶然性可能导致的差异更极端。” 这里包含了一个基线假设,即各个处理是等同的,并且组间差异完全是由偶然性所导致的。我们称该基线假设为零假设。事实上,我们希望能证明零假设是错误的,并证明A组和B组结果之间的差异要比偶然性可能导致的差异更大。
备用假设
假设检验本身不仅包括零假设,还包括一个相抵消的备择假设。下面通过一些例子来说明
- 零假设是“A组和B组的均值间没有差异”,备择假设是“A不同于B”(可能更大,也 可能更小)
- 零假设是“A≤B”,备择假设是“B > A”
- 零假设是“B不会比A大 x % x\% x%”,备择假设是“B比A大 x % x\% x%”
总而言之,零假设和备择假设必须涵盖了所有的可能性。假设检验的结构取决于零假设的性质。
重抽样
在统计学中,重抽样是指从观测数据中反复地抽取数据值,目标是评估一个统计量中的随机变异性。重抽样还可用于评估并提高一些机器学习模型的准确性。例如,对于使用多个自助数据集构建的决策树模型,可以通过Bagging过程计算其平均值
- 自助法(Bootstrap):上面已经提到,自助法可以用来评估一个估计量的可靠性。
- 置换校验:将多组(例如A/B实验中两组)样本组合在一起,并将观测值随机的重新分配给 重抽样。
置换校验的目的:就是将多组样本打乱组合在一起,目的就是验证零假设,如果是效果是随机产生的,那么再重新抽样,各组之间的差异和置换之前的各组差异相差不大。
置换过程如下:
- 将各个组得出的结果组合为一个数据集。
- 对组合得到的数据做随机混洗,然后从中随机抽取(有放回)一个规模与A组相同的重抽样样本。
- 在余下的数据中,随机抽取(无放回)一个规模与B组相同的重抽样样本。
- 如果还有C组、D组甚至更多的组,执行同样的操作。
- 无论对原始样本计算的是哪一种统计量或估计量(例如,组比例差异),现在对重抽样 进行重新计算,并记录结果。这构成了一次置换迭代。
- 重复上述步骤 R R R次,生成检验统计量的置换分布
现在我们回头查看所观测到的组间差异,并与置换差异进行对比。如果观测到的差异位于置换差异内,那么置换检验的结果并不能证实任何事情,因为观测到的差异落在偶然可能产生之差异的范围内。但是,如果观测到的差异大部分落在置换分布之外,那么我们就可以得出与偶然性无关这一结论。如果使用专业术语描述,我们称差异是统计显著的。
简而言之:就是可以通过置换校验,得到 随机效果,与 实验效果 比较得到差异,再判断这个差异是否是 显著的,由此得到 实验效果是否是真实的。
置换校验:数据科学的最后防线
在探索随机变异性中,置换检验是一种十分有用的启发式过程。它很容易编码,也很容易理解和解释。针对统计学中那些基于公式的形式主义和“假决定论”,置换检验提供了切实可行的绕行方法。
不同于依赖于统计学公式的方法,重抽样的一个优点在于给出了一种更加近乎万能的推断方法。它所适用的数据可以是数值,也可以是二元的;样本规模可以相同,也可以不同;并且无须假设数据符合正态分布。
统计显著性和 p p p值
统计学家引入了统计显著性的概念,用于衡量一个实验(也可以是对已有数据的研究)所生成的结果和随机生成的结果的差异,如果差异超过了随机变异的范围,则我们称它是统计显著的。
p p p值
如果零假设是真的,那么观察到当前或更极端结果的概率。换句话说,p值是指在零假设成立的情况下(随机情况下),得到当前观察结果或更极端结果的概率
p值的定义是:如果p值很小(通常小于0.05或0.01),那么我们就有足够的证据来拒绝零假设,因为在零假设成立的情况下,观察到当前结果的概率非常小。这种情况下,我们说结果是统计显著的。
注意:p值并不是零假设为真的概率,也不是研究假设为假的概率。它只是在零假设为真的情况下,观察到当前或更极端结果的概率。
α \alpha α 值
α \alpha α值是一个预先设定的阈值,用于确定统计显著性。 α \alpha α 值也被称为显著性水平(significance level)。
在假设检验中,我们首先设定一个零假设(null hypothesis),然后计算一个统计量和对应的 p p p 值。接下来,我们将计算出的 p p p 值与预先设定的 α \alpha α值进行比较。如果 p p p 值小于或等于 α \alpha α值,那么我们认为结果是统计显著的,有足够的证据拒绝零假设。如果 p p p值大于 α \alpha α值,那么我们没有足够的证据拒绝零假设。
注意: α \alpha α 值的选择是主观的,研究者可以根据实际情况和研究目的来设定一个合适的 α \alpha α值
数据科学与 p p p值
首先需要说明的是 p p p值对我们做科学决策,有时候并不可靠,结合 α \alpha α值来说,该判断比较主观,但是 p p p值可以当做一种辅助决策的信息,例如 p p p值可以作为一种特征输入到机器学习模型中,或者可以根据 p p p值判断该特征是否应该在模型中。
各种显著性检验方法
显著性检验与随机假设关系
上面我们讲到,显著性检验针对的让研究人员免受随机性的愚弄,但是下面的各种显著性检验方法,你会发现并没有直接针对随机性的假设来检验显著性,这是为什么呢?
显著性检验的目的是帮助我们判断观察到的数据或结果是否可能仅仅是由随机因素引起的。这并不意味着我们在假设检验中直接对"随机性"进行检验,而是我们通过检验特定的统计假设(如两组数据的均值是否相等)来间接地评估随机因素的影响。
在假设检验中,我们设定一个零假设,这通常是我们想要证伪的假设,例如"两组数据的均值相等"。如果这个假设是真的,那么任何我们在数据中观察到的差异都可以被认为是由随机因素引起的。然后我们计算一个统计量和对应的 p p p 值,这个 p p p 值表示在零假设为真的情况下,观察到当前或更极端结果的概率。
如果 p p p值很小(比如小于我们设定的显著性水平 α \alpha α),那么我们就有足够的证据拒绝零假设,因为在零假设为真的情况下,观察到当前结果的概率非常小。这意味着我们观察到的结果不太可能仅仅是由随机因素引起的,因此我们认为这个结果是统计显著的。
所以,虽然我们在假设检验中并不直接对"随机性"进行检验,但我们通过检验特定的统计假设来间接地评估随机因素的影响。
显著性校验流程
-
提出假设:首先,我们需要明确研究中的零假设( H 0 H0 H0)和备择假设( H 1 H1 H1)。零假设通常表示没有差异或效应,而备择假设则表示存在差异或效应。
-
选择显著性水平:显著性水平(通常表示为 α \alpha α)是我们在假设检验中所接受的最大错误概率。常见的显著性水平选择为 0.05 0.05 0.05或 0.01 0.01 0.01,表示我们愿意接受 5 % 5\% 5%或 1 % 1\% 1%的错误概率。
-
选择适当的统计检验方法:根据研究设计和数据类型,选择适当的统计检验方法。常见的统计检验方法包括t检验、方差分析(ANOVA)、卡方检验等。
-
计算统计量:根据所选的统计检验方法,计算相应的统计量。例如,在t检验中,我们计算t值;在方差分析中,我们计算F值。
-
确定临界值:根据显著性水平和自由度,查找相应的临界值。这些临界值用于判断统计量是否达到了显著性水平。
-
进行假设检验:将计算得到的统计量与临界值进行比较。如果统计量超过了临界值,我们拒绝零假设,认为差异是显著的。否则,我们无法拒绝零假设,认为差异不显著。
-
得出结论:根据假设检验的结果,得出关于研究问题的结论。如果拒绝了零假设,我们可以认为存在差异或效应;如果无法拒绝零假设,我们则无法得出差异或效应的结论。
Z Z Z 检验
z z z检验是一种常用的统计方法,用于比较一个样本均值与总体均值之间的差异是否显著。
适用条件:
- 样本规模大于30
- 样本来自于一个整体呈正态分布的总体
- 样本的观测值是独立的。这意味着样本中的每个观测值与其他观测值之间没有相关性
- 一个已知均值
统计量 Z Z Z计算公式:
Z = X ˉ − μ s n Z=\frac{\bar{X}-\mu}{\frac{s}{\sqrt{n}}} Z=nsXˉ−μ
- X ˉ \bar{X} Xˉ :样本均值
- μ \mu μ:已知均值
- s s s:样本标准差或总体标准差(这里就是为什么要求样本规模足够大,样本规模足够大,样本标准差才会和总体标准差越接近)
- n n n: 样本规模
注意:这里的 μ \mu μ 既可以是总体均值,亦或是对照组等均值,视具体问题和假设而定
其实这个计算公式也比较好理解:均值差异(分子)在标准误差(分母)上的倍数。
因为上面已经要求总体分布符合正态分布,统计量 z z z的抽样分布符合标准正态分布,因此允许我们通过标准正态分布的表格来确定 p p p 值。
计算得到的 Z Z Z值进行查表,可知均值之间的差异显著与否。
计算举例推荐看:z检验
t t t 检验
用于小样本(样本容量小于30)的两个样本均值差异程度的检验方法。它是用 T T T分布理论来推断差异发生的概率,从而判定两个样本均值的差异是否显著。
适用条件:
- 小样本,样本容量小于30
- 总体是正态分布,方差 σ \sigma σ 未知
统计量 t t t的计算公式:
Z = X ˉ − μ s n Z=\frac{\bar{X}-\mu}{\frac{s}{\sqrt{n}}} Z=nsXˉ−μ
自由度: n − 1 n-1 n−1
- X ˉ \bar{X} Xˉ :样本均值
- μ \mu μ:已知均值
- s s s:样本标准差
- n n n: 样本规模
因为此时是小样本,样本标准差和总体标准差相差较大,无法得到统计量 t t t 符合标准正态分布,此时科学家经过试验发现, t t t的抽样分布更适合 t t t分布,因此通过 t t t分布来查表获得 p p p值。
计算得到统计量 t t t值后,再查表可知显著性
计算举例推荐看t检验
卡方检验
卡方检验主要用于比较观察频数(实际结果)和期望频数(零假设结果)之间的差异,或者比较两个分类变量之间的独立性。
计算方法:
R p = O b s e r v e d − E x p e c t e d E x p e c t e d R_p=\frac{Observed-Expected}{\sqrt{Expected}} Rp=ExpectedObserved−Expected
卡方统计量 = ∑ i r ∑ j c R p 2 卡方统计量=\sum_{i}^{r}\sum_{j}^{c} {R_p}^2 卡方统计量=i∑rj∑cRp2
其中 r , c r,c r,c 分别表示行数和列数。
自由度= ( r − 1 ) ∗ ( c − 1 ) (r-1)*(c-1) (r−1)∗(c−1)
查表可得 p p p 值,在指定阈值下,可以得到是否拒绝零假设。
计算举例推荐看 卡方检验
除了上面几个常用的,还有 k-s检验、F值检验、方差分析等等
参考
- 书籍《面向数据科学的应用统计》
- GPT4