使用VGG框架实现从二分类到多分类
一.数据集的准备
与之前的不同,这一次我们不使用开源数据集,而是自己来制作数据集。重点需要解决的问题是对数据进行预处理,如每一个图片的大小均不同,需要进行resize,还需要对每一张图片打标签等操作。
数据集文件
首先新建一个数据集文件夹,要进行猫狗分类,所依在train文件夹下新建2个文件夹,分别为cat和dog,里面分别放入若干张cat和dog的图片。然后编写一个脚本,对数据集生成一个数据集文件cls_train.txt,用于描述数据集里的类别和路径。
# prepare.py
import os
from os import getcwd
classes = ['cat', 'dog']
sets = ['train']
if __name__ == '__main__':
wd = getcwd() # 该方法返回当前工作目录的路径
for i in sets: # 遍历训练集
list_file = open('cls_' + i + '.txt', 'w')
datasets_path = i
types_name = os.listdir(datasets_path) #获取train路径下每一张图片的路径,即为cat dog
for type_name in types_name: # 遍历每一张图片
if type_name not in classes:
continue
cls_id = classes.index(type_name) # 返回当前图片在classes中的索引,即为类别0-1
photos_path = os.path.join(datasets_path, type_name)
photos_name = os.listdir(photos_path)
for photo_name in photos_name:
_, postfix = os.path.splitext(photo_name) # 分离文件名和拓展名
if postfix not in ['.jpg', '.png', '.jpeg']:
continue
list_file.write(str(cls_id) + ';' + '%s/%s' % (wd, os.path.join(photos_path, photo_name)))
list_file.write('\n')
list_file.close()
执行后会生成一个txt文件,里面的内容如下
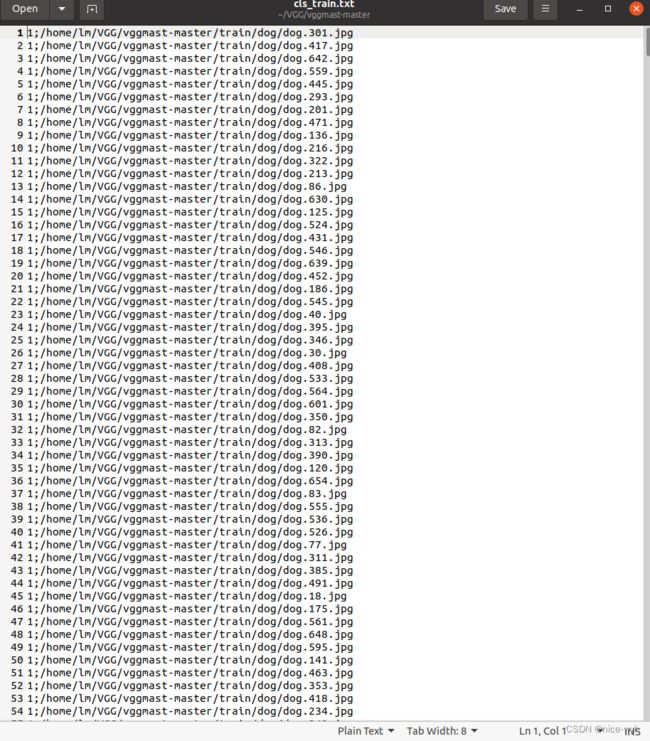
预处理
这里新建一个data.py文件,内容为调用网上找的代码
import cv2
import numpy as np
import torch.utils.data as data
from PIL import Image
def preprocess_input(x):
x /= 127.5 # 将输入数据的范围缩放到[-1, 1]
x -= 1.0
return x
def cvtColor(image):
if len(np.shape(image)) == 3 and np.shape(image)[-2] == 3:
return image
else:
image = image.convert('RGB')
return image
class DataGenerator(data.Dataset):
def __init__(self, annotation_lines, input_shape, random = True):
self.annotations_lines = annotation_lines
self.input_shape = input_shape
self.random = random
def __len__(self):
return len(self.annotations_lines)
def __getitem__(self, index):
annotation_path = self.annotations_lines[index].split(';')[1].split()[0]
image = Image.open(annotation_path)
image = self.get_random_data(image, self.input_shape, random=self.random)
image = np.transpose(preprocess_input(np.array(image).astype(np.float32)), [2, 0, 1])
y = int(self.annotations_lines[index].split(';')[0])
return image, y
def rand(self, a = 0, b = 1):
return np.random.rand()*(b - a) + a
def get_random_data(self, image, input_shape, jitter = .3, hue = .1, sat = 1.5, val = 1.5, random = True):
image = cvtColor(image)
iw, ih = image.size
h, w = input_shape
if not random:
scale = min(w/iw, h/ih)
nw = int(iw * scale)
nh = int(ih * scale)
dx = (w - nw) // 2
dy = (h - nh) // 2
image = image.resize((nw, nh), Image.BICUBIC)
new_image = Image.new('RGB', (w, h), (128, 128, 128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image, np.float32)
return image_data
new_ar = w/h * self.rand(1 - jitter, 1 + jitter) / self.rand(1 - jitter, 1 + jitter)
scale = self.rand(.75, 1.25)
if new_ar <1:
nh = int(scale * h)
nw = int(nh * new_ar)
else:
nw = int(scale * w)
nh = int(nw / new_ar)
image = image.resize((nw, nh), Image.BICUBIC)
#将图像多余部分加上灰条
dx = int(self.rand(0, w - nw))
dy = int(self.rand(0, h - nh))
new_image = Image.new('RGB', (w, h), (128, 128, 128))
new_image.paste(image, (dx, dy))
image = new_image
#翻转图像
flip = self.rand()<.5
if flip : image= image.transpose(Image.FLIP_LEFT_RIGHT)
rotate = self.rand()<.5
if rotate:
angle = np.random.randint(-15, 15)
a, b = w/2, h/2
M = cv2.getRotationMatrix2D((a, b), angle ,1)
image = cv2.warpAffine(np.array(image), M, (w, h), borderValue=[128, 128, 128])
# 色域扭曲
hue = self.rand(-hue, hue)
sat = self.rand(1, sat) if self.rand() < .5 else 1/self.rand(1, sat)
val = self.rand(1, val) if self.rand() < .5 else 1/self.rand(1, val)
x = cv2.cvtColor(np.array(image, np.float32) / 255, cv2.COLOR_RGB2HSV)
x[...,1] *= sat
x[...,2] *= val
x[x[:,:,0] > 360, 0] = 360
x[:,:,1:][x[:,:,1:] > 1] = 1
x[x < 0] = 0
image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB) * 255
return image_data二.构建VGG网络
构建网络
新建一个net.py,用于创建VGG网络,这里参考pytorch官网给出的源码pytorch官网vgg代码。
我们将其中的代码复制过来(不是全部),如下,对他进行修改。复制部分如下
from functools import partial
from typing import Any, cast, Dict, List, Optional, Union
import torch
import torch.nn as nn
from ..transforms._presets import ImageClassification
from ..utils import _log_api_usage_once
from ._api import register_model, Weights, WeightsEnum
from ._meta import _IMAGENET_CATEGORIES
from ._utils import _ovewrite_named_param, handle_legacy_interface
__all__ = [
"VGG",
"VGG11_Weights",
"VGG11_BN_Weights",
"VGG13_Weights",
"VGG13_BN_Weights",
"VGG16_Weights",
"VGG16_BN_Weights",
"VGG19_Weights",
"VGG19_BN_Weights",
"vgg11",
"vgg11_bn",
"vgg13",
"vgg13_bn",
"vgg16",
"vgg16_bn",
"vgg19",
"vgg19_bn",
]
class VGG(nn.Module):
def __init__(
self, features: nn.Module, num_classes: int = 1000, init_weights: bool = True, dropout: float = 0.5
) -> None:
super().__init__()
_log_api_usage_once(self)
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
layers: List[nn.Module] = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs: Dict[str, List[Union[str, int]]] = {
"A": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"B": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
"E": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512, "M", 512, 512, 512, 512, "M"],
}
def _vgg(cfg: str, batch_norm: bool, weights: Optional[WeightsEnum], progress: bool, **kwargs: Any) -> VGG:
if weights is not None:
kwargs["init_weights"] = False
if weights.meta["categories"] is not None:
_ovewrite_named_param(kwargs, "num_classes", len(weights.meta["categories"]))
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if weights is not None:
model.load_state_dict(weights.get_state_dict(progress=progress, check_hash=True))
return model相关处理是,需要删掉多余部分,然后根据自己需求修改部分代码,修改后的代码如下
import torch
import torch.nn as nn
from torch.hub import load_state_dict_from_url
# 权重下载地址
model_urls = {
"vgg16":"https://download.pytorch.org/models/vgg16-397923af.pth"
}
class VGG(nn.Module):
def __init__(self, features, num_classes = 1000, init_weights = True, dropout = 0.5):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) #使处于不同大小的图片也能进行分类
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p = dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p = dropout), # 完成4096的全连接
nn.Linear(4096, num_classes), # 对num_classes的分类
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode = "fan_out", nonlinearity = "relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight , 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1) # 对输入层进行平铺,转化为一维数据
x = self.classifier(x)
return x
def make_layers(cfg, batch_norm = False): # 对输入的cfg进行循环
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
"D" : [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"], # 数字代表通道数,M代表最大池化
}
def vgg16(pretrained=True, progress=True, num_classes=2):
model = VGG(make_layers(cfgs["D"]))
if pretrained:
state_dict = load_state_dict_from_url(model_urls['vgg16'], model_dir='./model', progress=progress)#预训练模型地址
model.load_state_dict(state_dict)
if num_classes != 1000:
model.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p = 0.5), # 随机删除一部分不合格
nn.Linear(4096, 4096),
nn.ReLU(True), # 防止过拟合
nn.Dropout(p = 0.5), # 完成4096的全连接
nn.Linear(4096, num_classes), # 对num_classes的分类
)
return model
if __name__ == "__main__":
in_data = torch.ones(1, 3, 224, 224)
net = vgg16(pretrained=False, progress=True, num_classes=2)
out = net(in_data)
print(out)
可以看到,修改后的代码和之前代码相比,删除了多余部分,同时根据示范代码定义了自己的vgg16网络对象,同时设置in_data,对网络进行验证,当单独执行python3 net.py时,网络可以输出预测值,说明网络设置正确。
网络讲解
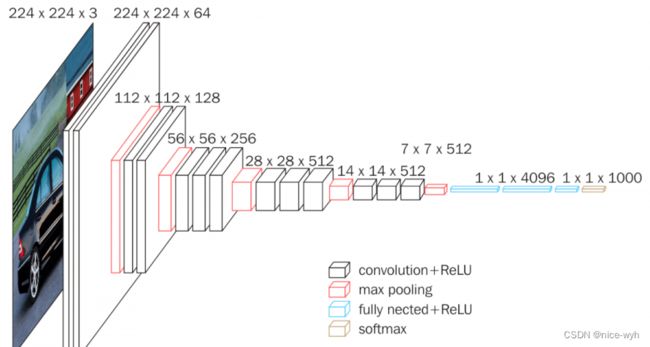
这里随便找一张VGG的网络结构图,当输入一个224*224*3的图片时,代码会进行前向传播forward,就会进行第一步x = self.features(x),就会执行函数make_layers,这里会读取cfg里的参数,所有读到64,执行make_layers里的else部分,因而会进行2d卷积操作加ReLU(即为图中最左面黑色部分,下方也标注出是convolution+ReLU)。以此类推,就完成了整个网络的执行(参照cfg里的参数一步步对应着看)。
注:虽然网络结构图里并没有GAP(全局平均池化),但在代码里加入了此部分。
三.训练网络
加载数据集
新建一个main.py文件用于编写训练代码。
首先完成数据集读取工作,这一部分调用了data.py文件(在第一部分提到的,这个代码是参考的别人代码)的DataGenerator类来生成数据,然后调用pytorch的DataLoader来加载数据集,设置batch_size=4。
import torch
import torch.nn as nn
from net import vgg16
from torch.utils.data import DataLoader#工具取黑盒子,用函数来提取数据集中的数据(小批次)
from data import *
'''数据集'''
annotation_path='cls_train.txt'#读取数据集生成的文件
with open(annotation_path,'r') as f:
lines=f.readlines()
np.random.seed(10101)#函数用于生成指定随机数
np.random.shuffle(lines)#数据打乱
np.random.seed(None)
num_val=int(len(lines)*0.2)#十分之一数据用来测试
num_train=len(lines)-num_val
#输入图像大小
input_shape=[224,224] #导入图像大小
train_data=DataGenerator(lines[:num_train],input_shape,True)
val_data=DataGenerator(lines[num_train:],input_shape,False)
val_len=len(val_data)
print(val_len)#返回测试集长度
# 取黑盒子工具
"""加载数据"""
gen_train=DataLoader(train_data,batch_size=4)#训练集batch_size读取小样本,规定每次取多少样本
gen_test=DataLoader(val_data,batch_size=4)#测试集读取小样本构建网络对象
首先还是固定套路,根据自己电脑挂载设备,构建net为vgg16的网络对象,同时设置为使用预训练模型,progress为True,分类类别为2(cat、dog)。
设置学习率、选择优化器为Adam、设置学习率更新方法。
'''构建网络'''
device=torch.device('cuda'if torch.cuda.is_available() else "cpu")#电脑主机的选择
net=vgg16(True, progress=True,num_classes=2)#定于分类的类别
net.to(device)
'''选择优化器和学习率的调整方法'''
lr=0.0001#定义学习率
optim=torch.optim.Adam(net.parameters(),lr=lr)#导入网络和学习率
sculer=torch.optim.lr_scheduler.StepLR(optim,step_size=1)#步长为1的读取开始训练
根据固有套路编写训练代码,设定为20轮,使用交叉熵损失函数,用计算出的loss进行反向传播和参数更新,同时每遍历完一遍数据集都要进行学习率的更新,再进行测试计算在测试集上的损失和精度,最后在循环完20轮之后,保存网络。
'''训练'''
epochs=20#读取数据次数,每次读取顺序方式不同
for epoch in range(epochs):
print(f"---------------第{epoch}轮训练开始-----------------")
total_train=0 #定义总损失
for img, label in gen_train:
with torch.no_grad():
img =img.to(device)
label=label.to(device)
optim.zero_grad()
output=net(img)
train_loss=nn.CrossEntropyLoss()(output,label).to(device)
train_loss.backward()#反向传播
optim.step()#优化器更新
total_train+=train_loss #损失相加
sculer.step()
total_test=0#总损失
total_accuracy=0#总精度
for img,label in gen_test:
with torch.no_grad():
img=img.to(device)
label=label.to(device)
optim.zero_grad()#梯度清零
out=net(img)#投入网络
test_loss=nn.CrossEntropyLoss()(out,label).to(device)
total_test+=test_loss#测试损失,无反向传播
accuracy=((out.argmax(1)==label).sum()).clone().detach().cpu().numpy()#正确预测的总和比测试集的长度,即预测正确的精度
total_accuracy+=accuracy
print("训练集上的损失:{}".format(total_train))
print("测试集上的损失:{}".format(total_test))
print("测试集上的精度:{:.1%}".format(total_accuracy/val_len))#百分数精度,正确预测的总和比测试集的长度
torch.save(net,f"DogandCat{epoch+1}.pth")
print("模型已保存")四.测试网络
新建一个predict.py文件,用于测试网络性能。
首先读取一张待检测图像,并把它resize成网络规定的244*244大小,再转成Tensor输入,之后加载网络和训练好的模型,即可进行预测。
同时这里使用了plt进行绘图显示,用out.argmax(1)获取预测输出最大概率的索引,将它打印在图上显示。
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
from net import vgg16
test_pth=r'/home/lm/VGG/vggmast-master/train/cat/cat.4.jpg'#设置可以检测的图像
test=Image.open(test_pth)
'''处理图片'''
transform=transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])
image=transform(test)
'''加载网络'''
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")#CPU与GPU的选择
net =vgg16()#输入网络
net=torch.load("/home/lm/VGG3/vggmast-master/DogandCat20.pth")#已训练完成的结果权重输入#模型导入
image=torch.reshape(image,(1,3,224,224)).to(device)#四维图形,RGB三个通 (batch_size, channel, width, height)
net.eval()#设置为推测模式
with torch.no_grad():
out=net(image)
out=F.softmax(out,dim=1)#softmax 函数确定范围
out=out.data.cpu().numpy()
print(out)
a=int(out.argmax(1))#输出最大值位置
plt.figure()
list=['Cat','Dog']
# plt.suptitle("Classes:{}:{:.1%}".format(list[a],out[0,a]))#输出最大概率的道路类型
plt.suptitle(f"Classes:{list[a]}:{out[0, a]}")#输出最大概率的道路类型
plt.imshow(test)
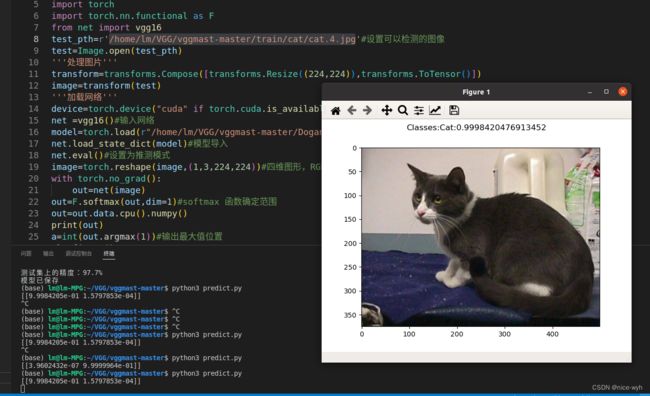
plt.show()最终效果为
五.训练更多类别
现在train数据集下只有cat、dog两类,现进行修改,再增加1类,实现多类别分类。
首先对prepare.py文件的类别进行更改,如下
classes = ['cat', 'dog', 'sheep']
sets = ['train']再重新运行此代码,生成新的数据集文件.
然后在net.py对网络定义的代码进行更改,如下,把num_classes修改为3
def vgg16(pretrained=True, progress=True, num_classes=3):在main.py对网络代码进行更改,把num_classes修改为3,如下
net=vgg16(True, progress=True,num_classes=3)#定于分类的类别最后在predict.py修改list=['Cat','Dog','Sheep']即可。
重复上述步骤开始训练并对预测结果进行测试
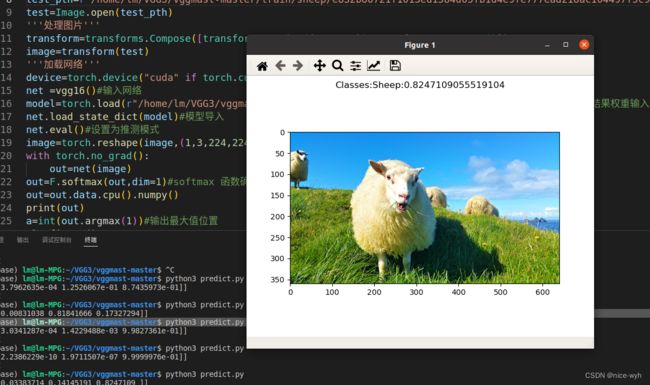
可以看到模型可以正确预测出图片种类。
六.模型文件转换
因为我们保存时保存的是.pth文件,但是对于嵌入式设备的实际部署,大多数用的是.onnx文件,因此需要进行转换。
新建一个onnx.py文件,编写如下代码并运行,即可完成onnx文件生成。
import torch
import torchvision
from net import vgg16
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = vgg16()
model=torch.load("/home/lm/VGG3/vggmast-master/DogandCat20.pth")
model.eval()
example = torch.ones(1, 3, 244, 244)
example = example.to(device)
torch.onnx.export(model, example, "cat.onnx", verbose=True, opset_version=11)
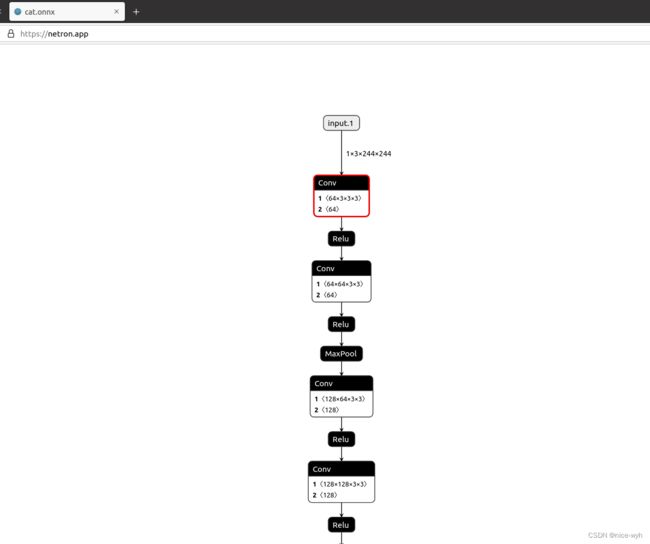
七.模型网络可视化
当生成pth或onnx文件后,如果想对模型网络进行可视化,可以使用Netron工具,它支持多种格式文件可视化。
参考链接:netron
只需要把文件拖入即可
八.总结
通过观察预测结果可以看出,模型预测效果并不是很好,所以可以通过增加epoch来调整,同时也可以使用其他网络(后续也会尝试其他网络结构),同时整体代码和之前的代码框架有些许区别,之后我也会进行完善,还有一些py文件,如data.py本人也不是很清楚其中的逻辑,因为大多都是开源的,之后我也会继续对本文进行更新讲解。
九.源码地址
链接: https://pan.baidu.com/s/1mFE__1hG3S24d_dL4p1QHg 提取码: yngp 复制这段内容后打开百度网盘手机App,操作更方便哦