ECCV 2020 Best Paper: RAFT 光流检测代码详解
1. 引言
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow 是 2D 光流检测领域内里具有里程碑意义的一个工作。本文模型无论是性能效果,还是参数量、运行效率,相比之前 state-of-the-art 方法都有了很大的提升。github上放出的代码也写得非常清晰,为了方便更多小伙伴了解这篇工作,下面结合原文中画的模型图对主要代码进行解释。
2. 整体框架介绍

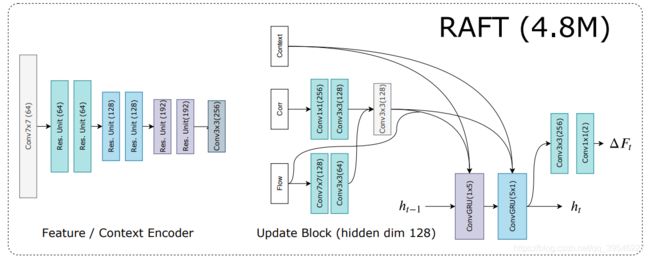
输入为连续的两帧图像,Feature Encoder(权值共享)提取两张图像的特征,并构建多尺度 4D Correlation Volumes 相关性查找表;Context Encoder 单独提取第一帧图的特征,并沿 channel 维度将其 split 成两部分,一部分作为 GRU 的初始隐状态,在后续迭代过程中会不断更新,另一部分用于和任意迭代过程中的光流图以及相关性图结合,作为 GRU(不懂的话请先了解一下 GRU 的大致原理)的一般输入;设置初始光流图为全 0,通过一系列的 GRU 更新光流,最后使用一个特殊的上采样操作得到原始分辨率的光流图(在前面提取特征过程中会将图像下采样 8 倍)。
3. 代码讲解
3.1. RAFT 核心代码
下面是 RAFT 的核心代码(以 4.8M 参数量版本模型为例,删减了不重要的部分),直接来看 forward() 函数,走一遍流程。后续章节将具体讲解其中一些此处未展示的重要代码。
class RAFT(nn.Module):
def __init__(self, args):
super(RAFT, self).__init__()
self.args = args
self.hidden_dim = hdim = 128
self.context_dim = cdim = 128
args.corr_levels = 4
args.corr_radius = 4
self.args.dropout = 0
self.args.alternate_corr = False
# feature network, context network, and update block
self.fnet = BasicEncoder(output_dim=256, norm_fn='instance', dropout=args.dropout)
self.cnet = BasicEncoder(output_dim=hdim+cdim, norm_fn='batch', dropout=args.dropout)
self.update_block = BasicUpdateBlock(self.args, hidden_dim=hdim)
def initialize_flow(self, img):
...
def upsample_flow(self, flow, mask):
...
def forward(self, image1, image2, iters=12, flow_init=None, upsample=True, test_mode=False):
""" Estimate optical flow between pair of frames """
# step 1:预处理
image1 = 2 * (image1 / 255.0) - 1.0 # 图像归一化
image2 = 2 * (image2 / 255.0) - 1.0 # 图像归一化
image1 = image1.contiguous()
image2 = image2.contiguous()
hdim = self.hidden_dim
cdim = self.context_dim
# step 2:Feature Encoder 提取两图特征(权值共享)
with autocast(enabled=self.args.mixed_precision):
fmap1, fmap2 = self.fnet([image1, image2])
fmap1 = fmap1.float()
fmap2 = fmap2.float()
# step 3:初始化 Correlation Volumes 相关性查找表
corr_fn = CorrBlock(fmap1, fmap2, radius=self.args.corr_radius)
# step 4:Context Encoder 提取第一帧图特征
with autocast(enabled=self.args.mixed_precision):
cnet = self.cnet(image1)
net, inp = torch.split(cnet, [hdim, cdim], dim=1) # net 为 GRU 的隐状态,inp 后续与其他特征结合作为 GRU 的一般输入
net = torch.tanh(net)
inp = torch.relu(inp)
# step 5:更新光流
# 初始化光流的坐标信息,coords0 为初始时刻的坐标,coords1 为当前迭代的坐标,此处两坐标数值相等
coords0, coords1 = self.initialize_flow(image1)
flow_predictions = []
for itr in range(iters):
coords1 = coords1.detach()
corr = corr_fn(coords1) # 从相关性查找表中获取当前坐标的对应特征
flow = coords1 - coords0 # 计算当前迭代的光流
with autocast(enabled=self.args.mixed_precision):
net, up_mask, delta_flow = self.update_block(net, inp, corr, flow) # GRU 获取更新的隐状态,用于上采样的 mask,以及光流残差
# F(t+1) = F(t) + \Delta(t)
coords1 = coords1 + delta_flow # 更新光流
# step 6:上采样光流(此处为了训练网络,对每次迭代的光流都进行了上采样,实际 inference 时,只需要保留最后一次迭代后的上采样)
flow_up = self.upsample_flow(coords1 - coords0, up_mask)
flow_predictions.append(flow_up)
if test_mode:
return coords1 - coords0, flow_up # inference 时仅使用上采样的光流 flow_up
return flow_predictions
总结流程:
step 1:预处理
step 2:Feature Encoder 提取两图特征(网络很简单,不做具体讲解)
step 3:初始化 Correlation Volumes 相关性查找表(讲解见 Sec. 3.2.)
step 4:Context Encoder 提取第一帧图特征(网络同 Feature Encoder)
step 5:更新光流(讲解见 Sec. 3.3.,从相关性查找表中获取当前坐标对应特征的步骤放在 Sec. 3.2. 中讲解)
step 6:上采样光流(讲解见 Sec. 3.4.)
3.2. Correlation Volumes 相关性查找表
在 step 3 初始化相关性查找表时,调用 __init__() 函数;在 step 5 查找对应特征时,调用 __call__() 函数。
class CorrBlock:
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
self.num_levels = num_levels
self.radius = radius
self.corr_pyramid = []
# all pairs correlation
corr = CorrBlock.corr(fmap1, fmap2) # 对两图特征使用矩阵乘法得到相关性查找表
batch, h1, w1, dim, h2, w2 = corr.shape
corr = corr.reshape(batch*h1*w1, dim, h2, w2) # (b,h,w,1,h,w) -> (bhw,1,h,w)
self.corr_pyramid.append(corr)
for i in range(self.num_levels-1):
corr = F.avg_pool2d(corr, 2, stride=2) # 使用平均 pooling 的方式获得多尺度查找表
self.corr_pyramid.append(corr)
def __call__(self, coords):
r = self.radius
coords = coords.permute(0, 2, 3, 1) # (b,2,h,w) -> (b,h,w,2) 当前坐标,包含x和y两个方向,由 meshgrid() 函数得到,细节见 Sec. 3.3.
batch, h1, w1, _ = coords.shape
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i] # (bhw,1,h,w) 某一尺度的相关性查找表
dx = torch.linspace(-r, r, 2*r+1) # (2r+1) x方向的相对位置查找范围
dy = torch.linspace(-r, r, 2*r+1) # (2r+1) y方向的相对位置查找范围
delta = torch.stack(torch.meshgrid(dy, dx), axis=-1).to(coords.device) # 查找窗 (2r+1,2r+1,2)
centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**i # (b,h,w,2) -> (bhw,1,1,2) 某一尺度下的坐标
delta_lvl = delta.view(1, 2*r+1, 2*r+1, 2) # (2r+1,2r+1,2) -> (1,2r+1,2r+1,2) 查找窗
coords_lvl = centroid_lvl + delta_lvl # (bhw,1,1,2) + (1,2r+1,2r+1,2) -> (bhw,2r+1,2r+1,2) 可以形象理解为:对于 bhw 这么多待查找的点,每一个点需要搜索 (2r+1)*(2r+1) 邻域范围内的其他点,每个点包含 x 和 y 两个坐标值
corr = bilinear_sampler(corr, coords_lvl) # (bhw,1,2r+1,2r+1) 在查找表上搜索每个点的邻域特征,获得相关性图
corr = corr.view(batch, h1, w1, -1) # (bhw,1,2r+1,2r+1) -> (b,h,w,(2r+1)*(2r+1))
out_pyramid.append(corr)
out = torch.cat(out_pyramid, dim=-1)
return out.permute(0, 3, 1, 2).contiguous().float()
@staticmethod
def corr(fmap1, fmap2):
batch, dim, ht, wd = fmap1.shape
fmap1 = fmap1.view(batch, dim, ht*wd) # 第一帧图特征 (b,c,h,w) -> (b,c,hw)
fmap2 = fmap2.view(batch, dim, ht*wd) # 第二帧图特征 (b,c,h,w) -> (b,c,hw)
corr = torch.matmul(fmap1.transpose(1,2), fmap2) # (b,hw,c) * (b,c,hw) -> (b,hw,hw) 后两维使用矩阵乘法,第一维由广播得到
corr = corr.view(batch, ht, wd, 1, ht, wd) # (b,hw,hw) -> (b,h,w,1,h,w)
return corr / torch.sqrt(torch.tensor(dim).float()) # 这里除的意义不是很明确,应该有一定的数学意义,有了解的小伙伴可以在评论区补充一下(不影响理解)
def bilinear_sampler(img, coords, mode='bilinear', mask=False):
""" Wrapper for grid_sample, uses pixel coordinates """
H, W = img.shape[-2:]
xgrid, ygrid = coords.split([1,1], dim=-1) # (bhw,2r+1,2r+1,1)
xgrid = 2*xgrid/(W-1) - 1 # x方向归一化
ygrid = 2*ygrid/(H-1) - 1 # y方向归一化
grid = torch.cat([xgrid, ygrid], dim=-1) # (bhw,2r+1,2r+1,2)
img = F.grid_sample(img, grid, align_corners=True) # img: (bhw,1,h,w) -> (bhw,1,2r+1,2r+1) 根据搜索范围 grid 在查找表 img 中采样对应特征
return img
3.3. GRU 更新光流
光流初始化。
class RAFT(nn.Module):
def initialize_flow(self, img):
""" Flow is represented as difference between two coordinate grids flow = coords1 - coords0"""
N, C, H, W = img.shape
coords0 = coords_grid(N, H//8, W//8).to(img.device) # (b,2,h,w)
coords1 = coords_grid(N, H//8, W//8).to(img.device) # (b,2,h,w)
# optical flow computed as difference: flow = coords1 - coords0
return coords0, coords1
def coords_grid(batch, ht, wd):
coords = torch.meshgrid(torch.arange(ht), torch.arange(wd)) # (h,w),(h,w)
coords = torch.stack(coords[::-1], dim=0).float() # (2,h,w)
return coords[None].repeat(batch, 1, 1, 1) # (b,2,h,w)
GRU 更新光流,BasicMotionEncoder 和 FlowHead 的网络结构相对简单,不展开解释。
class BasicUpdateBlock(nn.Module):
def __init__(self, args, hidden_dim=128, input_dim=128):
super(BasicUpdateBlock, self).__init__()
self.args = args
self.encoder = BasicMotionEncoder(args)
self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)
self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
self.mask = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64*9, 1, padding=0))
def forward(self, net, inp, corr, flow, upsample=True):
motion_features = self.encoder(flow, corr) # 结合光流和相关性图提取特征
inp = torch.cat([inp, motion_features], dim=1) # 连接 Context Encoder 提取的特征和上面提取的特征
net = self.gru(net, inp) # GRU 迭代,更新隐状态 net
delta_flow = self.flow_head(net) # 由隐状态得到光流残差
# scale mask to balence gradients
mask = .25 * self.mask(net) # 由隐状态得到上采样 mask
return net, mask, delta_flow
class SepConvGRU(nn.Module):
def __init__(self, hidden_dim=128, input_dim=192+128):
super(SepConvGRU, self).__init__()
self.convz1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convr1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convq1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convz2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convr2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convq2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
def forward(self, h, x):
# 将 3x3 卷积替换成 1x5 和 5x1 的两次卷积,在不提高参数量的情况下增大感受野,下面使用的数学计算见 GRU 公式
# horizontal
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz1(hx))
r = torch.sigmoid(self.convr1(hx))
q = torch.tanh(self.convq1(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
# vertical
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz2(hx))
r = torch.sigmoid(self.convr2(hx))
q = torch.tanh(self.convq2(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
return h

3.4. 上采样光流
8 倍上采样的过程可以简单描述为:每个像素点都要扩展成 8*8 个像素点,具体方式是每个扩展的像素点由原像素点及周围的 8 邻域像素点(总共 9 个像素点)加权得到,而权重则是由网络生成的,因此权重矩阵的参数量为 b*c*h*w*9*8*8(x,y 坐标使用相同的权重,不用再乘 2)。实验证明这种上采样对于光流任务非常有效,在物体边缘能够获得如丝般顺滑的效果。感兴趣的小伙伴也可以在其他需要上采样的任务中进行尝试,或许会有意想不到的效果。
class RAFT(nn.Module):
def upsample_flow(self, flow, mask):
""" Upsample flow field [H/8, W/8, 2] -> [H, W, 2] using convex combination """
N, _, H, W = flow.shape
mask = mask.view(N, 1, 9, 8, 8, H, W) # (b,9*8*8,h,w) -> (b,1,9,8,8,h,w)
mask = torch.softmax(mask, dim=2) # 权重归一化
up_flow = F.unfold(8 * flow, [3,3], padding=1) # (b,2,h,w) -> (b,2*3*3,h*w)
# 提取每个像素点以及周围的 8 邻域像素点特征(总共 9 个像素点)重新排列到 channel 维度上
# 这里 8*flow 的原因是上采样后图像的尺度变大了,为了匹配尺度增大的像素坐标,光流也要按同样的倍率(8 倍)上采样
up_flow = up_flow.view(N, 2, 9, 1, 1, H, W) # (b,2*3*3,h*w) -> (b,2,9,1,1,h,w)
up_flow = torch.sum(mask * up_flow, dim=2) # (b,1,9,8,8,h,w) * (b,2,9,1,1,h,w) -> (b,2,9,8,8,h,w) ->(sum) (b,2,8,8,h,w)
up_flow = up_flow.permute(0, 1, 4, 2, 5, 3) # (b,2,8,8,h,w) -> (b,2,h,8,w,8)
return up_flow.reshape(N, 2, 8*H, 8*W) # (b,2,h,8,w,8) -> (b,2,8h,8w)