
content
前端课程复习题
html
1、什么是HTML5
HTML的全称是(Hyper Text Markup Language )即超文本标记语言,它是互联网上应用最广泛的标记语言。
2、列举vscode常用快捷键,越多越好
//常用快捷键:
1、代码格式化:Shift+Alt+F
2、 移动某一行:Alt+ ↑ / ↓
3、复制某一行:Shift+Alt + ↓ / ↑
4、快速保存:Ctrl+s
5、快速查找:Ctrl+F
6、快速替换:Ctrl+H
7、ctrl+上下箭头上下滚动页面
8、Ctrl+Shift+K 删除某一行
9、ctrl + Enter 跳转下一行开头
10、shift + ctrl + enter 跳转上一行开头
11、Ctrl+Shift+ 跳转到相应的匹配括号
12、Alt+Shift+A 多行注释
13、Ctrl+Shift+F 全局搜索3、列举常用的HTML标签,越多越好
//常见HTMl标签:
h1-h6、p、span、强调标签 em、strong、换行 br、hr、del、center、div
//常用布局标签:
header、main 主体、footer、nav、aside 和主题相关的、article文章之类、section独立的块区、div
//常用的图片标签:img:src alt width height4、简述无序列表的应用场景
在网页中按照行展示关联性的内容,如:新闻列表、排行榜、账单等
5、列举表单属性,并简述每种属性的效果
一、表单的标签
1、form 表示HTML表单
2、input 表示用来收集用户输入数据的控件,通过设置type属性的不同属性值获取不同功能的控件
3、label 可以通过for属性绑定表单中其它控件,解释其他控件用途
4、select、option、optgroup 表单下拉框组合
5、textarea 表示可以输入多行文本的控件
6、datalist 定义一组提供给用户的建议值
7、fieldset、legend 对表单中的控件分组
8、output 表示计算结果
9、button 按钮,可以通过设置type值获取重置、提交、普通按钮这三种功能的按钮,这些功能的控件都可以通过input获取
二、标签用法及标签属性
通常情况下,标签都需要配合标签属性才能达到目的,有些属性是所有标签都有的,有些属性是只有部分标签有的,有些属性是某个标签独有的。
下面尽量列出每个标签所有的属性,以及一个常用的搭配
form标签
1)action 表示表单提交的页面
2)method 表示表单的请求方式,有POST和GET两种,默认GET
3)enctype 表示浏览器对发送给服务器的数据所采用的编码格式。 有三种:application/x-www-form-urlencoded(默认编码,不能将文件上传到服务器)、multipart/form-data(用于上传文件到服务器)、text/plain(未规范的编码,不建议使用,不同浏览器理解不同)
4)name 设置表单名称
5)target 设置提交时的目标位置,_blank、_parent、_selt、_top
6)autocomplete 设置浏览器记住用户输入的数据, 实现自动完成表单。 默认为 on 自动完成,如果不想自动完成则设置 off。
7)novalidate 设置是否执行客户端数据有效性检查,input标签是表单标签中使用频率最高的标签,通过设置type属性的值获取不同功能的控件
labe标签:通过for属性绑定表单中其它控件,当点击label时相当于点击了和label绑定的控件,标签中文本用于解释控件用途
6、简述块元素和内联元素的特性及区别
1、块级元素:块级元素独占一行,默认宽度为100%
2、行内元素:行内元素在同一行显示,默认宽度由内容撑开
3、块级元素可以设置宽高,行内元素设置宽高不生效
4、行内元素width 和 height 属性将不起作用.
5、块级元素可以设置margin和padding的四周,行内元素只能设置margin和padding的左右 6、块级元素默认display为block,行内元素默认display为inline
7、布局时,块级元素可以包含块级元素和行内元素,行内元素一般不要包含块级元素
7、创建页面,在页面上完成视频和音频的播放
添加音频使用标签,这个标签被所有浏览器支持,是html5推荐的音频导入标签,但是遗憾的是在html4标准中是不被支持的或者说是非法的。
音视频导入
其中controls属性就是用来显示播放控制界面的,就是这个:(偷懒的话可以写成"controls"就ok,不必加"="以及后面的内容了。)
如果以后您使用自己编写的控制界面,就可以不添加这个属性。
删掉这个属性后就是这样:这样为自定义的播放控制界面留出了位置。
标签夹着标签中可以添加多个
type属性是告诉浏览器音乐文件的类型。
不同格式的文件的生成需要我们自己去做,这就涉及到如何给一个音频文件进行格式转化的问题。这个问题我们明天再说,今天先学习为页面添加音频和视频。
下面我们来看一下视频的导入方法,示例代码如下:
我们可以通过设置height和width属性来控制视频的面积。实例代码如下:
视频画面变小了,和视频并排的是我们之前添加的音频文件,由此可知,这两个元素都是内联元素。
css
1、css基础选择器有哪些,分别完成选择器的编写
全局选择器 *
元素选择器 div,a 标记名{属性1:属性组1;属性2:属性组2;属性3:属性组3;}
类选择器 . .类名{属性1:属性值1;属性2:属性值2;属性3:属性3;}
ID选择器 # #id名{属性1:属性值1;属性2:属性值2;属性3:属性值3;}
2、编写css引入到html文件的四种方式
1.行内式 是在标记的style属性中设定CSS样式。这种方式没有体现出CSS的优势,不推荐使用。
2.嵌入式 是将CSS样式集中写在网页的
标签对的标签对中。缺点是对于一个包含很多网页的网站,在每个网页中使用嵌入式,进行修改样式时非常麻烦。单一网页可以考虑使用嵌入式。
3.导入式 将一个独立的.css文件引入HTML文件中,导入式使用CSS规则引入外部CSS文件,
导入式会在整个网页装载完后再装载CSS文件,因此这就导致了一个问题,如果网页比较大则会儿出现先显示无样式的页面,闪烁一下之后,再出现网页的样式。这是导入式固有的一个缺陷。
4.链接式
将一个.css文件引入到HTML文件中,但它与导入式不同的是链接式使用HTML规则引入外部CSS文件,它在网页的
标签对中使用标记来引入外部样式表文件,使用语法使用链接式时与导入式不同的是它会以网页文件主体装载前装载CSS文件,因此显示出来的网页从一开始就是带样式的效果的,它不会像导入式那样先显示无样式的网页,然后再显示有样式的网页,这是链接式的优点。
3、通过css给一个容器设置背景图片,并应用所有背景属性
background-image//设置背景图片的 URL。
background-size//设置背景图片的大小。可以设置为绝对像素值,也可以设置为百分比或 "cover"(填充整个容器)或 "contain"(完整显示图片)。
background-repeat//设置背景图片是否重复。可以设置为 "repeat"(重复)、"no-repeat"(不重复)、"repeat-x"(横向重复)或 "repeat-y"(纵向重复)。
background-position//设置背景图片的位置。可以设置为绝对像素值,也可以设置为百分比或关键字(如 "center"、"top"、"bottom"、"left" 或 "right")。4、实现单行文本,如果超出容器大小,使用...代替
1. 设置超出显示省略号
css设置超出显示省略号可分两种情况:
单行文本溢出显示省略号…
多行文本溢出显示省略号…
但使用的核心代码是一样的:需要先使用 “overflow:hidden;” 来把超出的部分隐藏,然后使用“text-overflow:ellipsis;”当文本超出时显示为省略号。
overflow:hidden; 不显示超过对象尺寸的内容,就是把超出的部分隐藏了;
text-overflow:ellipsis; 当文本对象溢出是显示…,当然也可是设置属性为 clip 不显示点点点;
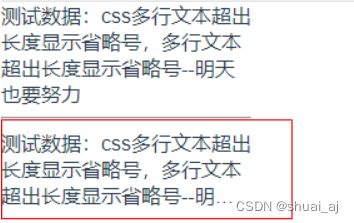
单行文本溢出显示省略号
测试数据:css单行文本超出长度显示省略号--明天也要努力
测试数据:css单行文本超出长度显示省略号--明天也要努力
多行文本溢出显示省略号
思路:
1、使用 overflow:hidden; 语句不显示超过对象尺寸的内容,就是把超出的部分隐藏了;
2、使用 -webkit-line-clamp: 行数; 语句限制显示文本的行数;
3、使用 text-overflow:ellipsis; 语句用省略号“…”隐藏超出范围的文本
测试数据:css多行文本超出长度显示省略号,多行文本超出长度显示省略号--明天也要努力
测试数据:css多行文本超出长度显示省略号,多行文本超出长度显示省略号--明天也要努力
说明: 移动端浏览器绝大部分是 WebKit 内核的,所以该方法适用于移动端;
-webkit-line-clamp 用来限制在一个块元素显示的文本的行数,这是一个不规范的属性(unsupported WebKit property),它没有出现在 CSS 规范草案中;
display: -webkit-box 将对象作为弹性伸缩盒子模型显示 ;
-webkit-box-orient 设置或检索伸缩盒对象的子元素的排列方式 ;
2. 关于 -webkit-line-clamp 属性拓展
-webkit-line-clamp 可以把块容器中的内容限制为指定的行数,它只有在 display 属性设置成 -webkit-box 或 -webkit-inline-box 并且 -webkit-box-orient 属性设置成 vertical 时才有效果。
在大部分情况下,也需要设置 overflow 属性为 hidden, 否则,里面的内容不会被裁减,并且在内容显示为指定行数后还会显示省略号 (ellipsis )。
当他应用于锚 (anchor) 元素时,截取动作可以发生在文本中间,而不必在末尾。
备注: 此属性在 WebKit 中已经实现,但有一些问题。他是旧标准的一种支持。CSS Overflow Module Level 3 规范还定义了一个 line-clamp 属性,用来代替此属性且避免一些问题。
语法:
/* Keyword value */
-webkit-line-clamp: none;
/* values */
-webkit-line-clamp: 3;
-webkit-line-clamp: 10;
/* Global values */
-webkit-line-clamp: inherit;
-webkit-line-clamp: initial;
-webkit-line-clamp: unset;
none:这个值表明内容显示不会被限制。
integer:这个值表明内容显示了多少行之后会被限制。必须大于 0. 5、利用两种方式实现一个div盒子半透明
用CSS控制外层DIV不透明,而内层DIV透明,其实代码也是很简单的,也很好理解,主要是用了CSS的滤镜。
Div的重叠和覆盖可以使用z-index和position:absolute绝定 定位来实现,具体实现代码如下:
6、简述关系选择器有哪些
后代选择器 空格
子代选择器 >
相邻兄弟选择器 + (范围:相邻后面兄弟)
通用兄弟选择器 ~ (范围:后面所有的兄弟)
7、伪类选择器和伪对象选择器分别有哪些
伪类选择器 :link 点击之前 :visited 点击之后 :hover 鼠标悬停 :active 鼠标按下 :first-child 第一个子元素 :last-child 最后一个子元素 :nth-child () 第几个子元素 :only-child 唯一一个子元素 :empty 空的子元素 :not()
伪对象选择器
::before{ Content" ";} 在元素之前插入内容
::after{ Content" ";} 在元素之后插入内容
8、利用css盒子模型属性完成一个容器在页面中的左右居中 (CSS盒模型的几种居中方式)
1.绝对定位 margin负值
.parent{
width:600px;
height:600px;
margin:auto;
position: relative;
background-color: #000;
}
.child{
width:200px;
height:200px;
background-color: red;
position: absolute;
top:50%;
left:50%;
margin:-100px 0 0 -100px;
}2.绝对定位 四个方位为0
.parent{
width:600px;
height:600px;
margin:auto;
position: relative;
background-color: #000;
}
.child{
width:200px;
height:200px;
background-color: red;
position: absolute;
top:0;
left:0;
right:0;
bottom:0;
margin:auto;
}3.绝对定位 translate
.parent{
width:600px;
height:600px;
margin:auto;
position: relative;
background-color: #000; }
.child{
width:200px;
height:200px;
background-color: red;
position: absolute;
top:50%;
left:50%;
transform:translate(-50%,-50%) }4.margin属性居中
.parent{
width:600px;
height:600px;
margin:auto;
overflow: hidden;
background-color: #000;
}
.child{
width:200px;
height:200px;
background-color: red;
margin: 150px auto 0;
}5.table-cell
.parent{
width:600px;
height:600px;
background-color: #000;
display: table-cell;
vertical-align: middle;
}
.child{
width:200px;
height:200px;
background-color: red;
margin: 0 auto;
}6.flex 居中
.parent{
width:600px;
height:600px;
display: flex;
justify-content: center;
align-items: center;
background-color: #000;
margin:0 auto;
}
.child{
width:200px;
height:200px;
background-color: red;
}9、css盒子模型包含哪些属性
内容(content)、内边距(padding)、边框(border)、外边距(margin), CSS盒子模型都具备这些属性。
不同部分的说明:
-
Margin(外边距) - 清除边框外的区域,外边距是透明的。
空白边的属性有五种 ,即margin-top、margin-bottom、margin- left、margin-right以及综合了以上四种方向的快捷空白边属性margin,其具体的设置和使用与填充属性类似。
-
Border(边框) - 围绕在内边距和内容外的边框。
边框的属性有border-style、border-width和border-color 以及综合了以上三类属性的快捷边框属性 border。
-
Padding(内边距) - 清除内容周围的区域,内边距是透明的。
内边距有五个属性:*padding-top*、*padding-bottom*、*padding-left*、*padding-right* 和 *padding*。使用这五种属性可以指定内容区信息内容与各方向边框间的距离。设置盒子背景色属性时,可使背景色延伸到填充区域。
-
Content(内容) - 盒子的内容,显示文本和图像。
块级元素水平居中:当我们对块级元素设置width宽度,同时将左右的外边距设置为auto时,可以使其居中
margin:0 auto; /实现⽔平居中/
margin:5px auto /实现⽔平居中,且上下拉开5px外边距/内外边距的清除的重要性:为了⽅便控制⽹页中的元素,制作⽹页是通常先清除元素的默认内外边距
*{
padding:0;/清除内边距/
margin:0;/清除外边距/
}10、实现一个怪异盒子模型
标准盒子模型 box-sizing :border-content;
怪异盒子模型 box-sizing :border-box
标准盒子模型与怪异盒子模型的区别:
当内边距和边框的宽度<内容width时, 盒子的总宽度=width的值
内容 content区域会被压缩,但是内容同样会显示出来,并且内容多的时候会溢出
当内边距和边框的宽度>内容width时, 盒子的总宽度=内边框+内边距
这时的内容区域就为0,但文本内容同样会显示出来.
-
正常盒子和怪异盒子的记忆方法
border=皮 padding=肉 content=骨骼
-
正常盒子:肉增加,皮有弹性,会撑大,总体增大
-
怪异盒子:皮紧绷,定死,肉增加,会往里压缩骨骼
-
怪异盒子解决的一个问题: 正常盒子下,当增加内边距时,如果想保证盒子和之前一样大,需要手动重新计算 width ,怪异盒子模型则省略该步
为什么会采用怪异盒子模型 因为父盒子无边框时子元素增加 margin 会造成外边距穿透,此时需要给父盒子添加 padding ,添加 padding 会增大父盒子,需要手动重新计算父盒子 width ,因此利用怪异盒子模型省略重新计算 width 这一步。
怪异盒子的应用
优点:
1. 固定盒子区域,在得到盒子大小后,可以自动压缩内容区域的宽度,不需要我们去计算.
2.普通盒子环境下,有些时候我们给盒子里面的内容过大 ,会导致整体盒子被撑大,就会改变设计要求的大小,而怪异盒子模型就不会.
在设置怪异后,设置width就为盒子的整体宽度,内容区域的实际宽度会自动挤压(条件是内边距和边框的宽度<提前设置好的内容区域width)
box-sizing: border-box;



11、利用弹性盒子模型,实现单行文本在盒子内上下左右居中
场景
Flex是Flexible Box的缩写,意为”弹性布局”。
怎样使用弹性布局实现页面上下两个元素上下左右垂直居中排列。
实现
1、外层div设置样式
.login {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
}2、display: flex; 设置为弹性布局
3、flex-direction属性决定主轴的方向(即项目的排列方向)。
row(默认值):主轴为水平方向,起点在左端。
row-reverse:主轴为水平方向,起点在右端。
column:主轴为垂直方向,起点在上沿。
column-reverse:主轴为垂直方向,起点在下沿。
4、justify-content属性定义了项目在主轴上的对齐方式。
flex-start(默认值):左对齐
flex-end:右对齐
center: 居中
space-between:两端对齐,项目之间的间隔都相等。
space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
5、align-items属性定义项目在交叉轴上如何对齐。
flex-start:交叉轴的起点对齐。
flex-end:交叉轴的终点对齐。
center:交叉轴的中点对齐。
baseline: 项目的第一行文字的基线对齐。
stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。
6、这样设置之后div里面上下两个元素就会居中
但是两个子元素会紧挨在一起,如果要使其有一定距离。
给下面的子元素设置margin-top属性即可
.login-form {
margin-top: 100px;
}12、脱离文档流有哪几种方式
1.float: 浮动,为元素设置float属性,可以让元素脱离原本的文档流独立开来,单独实现向左或向右,在设置float属性之后元素自动设置为块级元素,并且不会占据原本的位置。
2.absolut: 绝对定位,absolut脱离的文档流是相对于其父元素的,而且这个父元素的position属性不为static(static为position默认属性), 如果absolute所在元素的父元素position属性为static则其继续向上寻找,直到找到符合要求的父元素。脱离文档流之后其他元素会无视此元素,其此元素不再占据原本的位置
3.fixed:设置此属性的元素在位置上总是相对于body标签,也就是说在网页中设计此类标签不会随着网页的上下滑动而变化总是固定在网页的一个位置
13、实现一个导航效果,要求横向摆放,并且清除浮动
清除浮动的三种方法
1、在加浮动的元素的父级元素加overflow: hidden;
2、使用after伪元素清除浮动(推荐使用)
给浮动的元素使用伪元素清除浮动
.clearfix:after{/*伪元素是行内元素 正常浏览器清除浮动方法*/
content: "";
display: block;
height: 0;
clear:both;
visibility: hidden;
}
.clearfix{
*zoom: 1;/*ie6清除浮动的方式 *号只有IE6-IE7执行,其他浏览器不执行*/3、在浮动元素后加个空元素,然后对其设置属性:{clear:both;}
清除 浮动实现导航栏等页面排版
nav_demo

14、描述定位有哪几种方式,并且它们有什么区别
relative 相对定位,正常文档流,相对于自身的位置
absolute 绝对定位,脱离文档流,相对于开启了position非static最近的父辈元素
fixed 固定定位,脱离文档流,相对于浏览器可视窗口(不随滚动条滚动)
15、如果出现元素重叠,如何决定重叠顺序
简单总结及建议
普通元素的堆叠顺序由元素在文档中的先后位置决定,后出现的会在上面,请小心计算好浮动和负边距布局,注意窗口元素的特殊性;非同级关系和非父子关系定位元素之间的堆叠顺序,要向上追溯到其为兄弟关系的父元素上,先比较其z-index值,只有父辈元素中的z-index值较大的后代子元素才能超过z-index值较小的父辈元素及其子孙元素。
为了在编码时就减少z-index值判断的复杂性,我建议对于一般页面内容类定位元素的z-index设置小于99的值(如非必要不使用负值),广告类定位元素的z-index设置100~500的值,公告提示等弹出类定位元素的z-index设置大于500的值;对于比较复杂定位嵌套页面,为了避免ie6/7的显示差异,请为父辈类定位元素显性加上z-index:0或其他值。
css3新特性
1、将一个100*100的盒子,变成圆形
1、实现一个方形的div盒子,将图片放在div盒子里
2、将盒子设置成圆形(利用border-radius属性)
3、设置盒子的overflow属性值伪hidden

2、实现100*100的盒子的阴影效果,阴影值自拟
盒子阴影语法:box-shadow:水平位置,垂直位置,模糊程度,阴影大小,阴影颜色,内/外阴影
水平阴影:必选,可以正负值,正数阴影向右边走,负数则是阴影向左边走。
.a{
width: 100px;
height: 100px;
background-color: aqua;
margin: 0 auto;
box-shadow: 10px 10px 5px red;
}
/*
h-shadow 必需 水平阴影的位置,允许负值
v-shadow 必需 垂直阴影的位置,允许负值
blur 可选 模糊距离
spread 可选 阴影的大小
color 可选 阴影的颜色
inset 可选 从外层的阴影()开始时改变内侧阴影
*/3、什么是响应式布局,有什么优缺点
响应式布局指的是同一页面在不同屏幕尺寸下有不同的布局。
响应式布局是Ethan Marcotte在2010年5月份提出的一个概念,简而言之,就是一个网站能够兼容多个终端——而不是为每个终端做一个特定的版本。这个概念是为解决移动互联网浏览而诞生的。
响应式布局可以为不同终端的用户提供更加舒适的界面和更好的用户体验,而且随着大屏幕移动设备的普及,用“大势所趋”来形容也不为过。随着越来越多的设计师采用这个技术,我们不仅看到很多的创新,还看到了一些成形的模式。
优点:
1、面对不同分辨率设备灵活性强
2、能够快捷解决多设备显示适应问题
缺点:
1、兼容各种设备工作量大,效率低下
2、代码累赘,会出现隐藏无用的元素,加载时间加长
3、其实这是一种折衷性质的设计解决方案,多方面因素影响而达不到最佳效果
4、一定程度上改变了网站原有的布局结构,会出现用户混淆的情况.域名查询 网站注册
4、绘制一个向上的三角形
.san{
width: 0;
height: 0;
border: 10px solid transparent;
border-bottom-color:pink;
}在前端工作中遇到三角形或者需要箭头的样式,我们不仅可以利用图片来实现效果,还可以利用css来实现。
1、利用border来实现
(1)向下三角形
triangle{
width: 0;
height: 0;
border-width: 100px;
border-style: solid;
border-color:#ff0000 transparent transparent transparent;
}
(2)向左三角形
.triangle{
width: 0;
height: 0;
border-width: 50px;
border-style: solid;
border-color: transparent #ff0000 transparent transparent;
}(3)利用 CSS3 transfrom 旋转 45 度实现三角形
css3 transfrom 三角形
总结: transparent是透明的意思,也就是与背景色同化。
2、利用伪类实现箭头
(1)向左箭头
.arrow{
position: relative;
}
.arrow:before,.arrow:after{
position: absolute;
content: '';
border-top: 20px transparent dashed;
border-left: 20px transparent dashed;
border-bottom: 20px transparent dashed;
border-right: 20px #fff solid;
}
.arrow:before{
border-right: 20px #ff0000 solid;
}
.arrow:after{
left: 4px; /*通过覆盖调整箭头粗细*/
border-right: 20px #fff solid;
}(2)向上箭头
.arrow{
position: relative;
}
.arrow:before,.arrow:after{
position: absolute;
content: '';
border-top: 20px transparent dashed;
border-left: 20px transparent dashed;
border-right: 20px transparent dashed;
border-bottom: 20px #fff solid;
}
.arrow:before{
border-bottom: 20px #ff0000 solid;
}
.arrow:after{
top: 4px; /*通过覆盖调整箭头粗细*/
border-bottom: 20px #fff solid;
}(3)利用 CSS3 transfrom 旋转 来实现多方向箭头
比如:向下箭头
.arrow{
position: relative;
}
.arrow:before,.arrow:after{
position: absolute;
content: '';
border-top: 20px transparent dashed;
border-left: 20px transparent dashed;
border-right: 20px transparent dashed;
border-bottom: 20px #fff solid;
}
.arrow:before{
border-bottom: 20px #ff0000 solid;
-webkit-transform:rotate(180deg);
-moz-transform:rotate(180deg);
-o-transform:rotate(180deg);
transform:rotate(180deg);
}
.arrow:after{
border-bottom: 20px #fff solid;
-webkit-transform:rotate(180deg);
-moz-transform:rotate(180deg);
-o-transform:rotate(180deg);
transform:rotate(180deg);
bottom: -36px; /*通过覆盖调整箭头粗细*/
}js
1、javascript引入到html的方式有哪几种
嵌入到HTML文件中
//引入本地独立JS文件
引入网络来源文件
2、ECMAScript和JavaScript的关系
ECMAScript和JavaScript的关系是,前者是后者的规格,后者是前者的一种实现。在日常场合,这两个词是可以互换的。
3、写出10个javascript常见的保留关键字
arguments、break、case、catch、class、const、continue、debugger、default、delete、do、
else、enum、eval、export、extends、false...4、什么是变量提升,会出现什么结果
首先javascript引擎的工作方式,是先解析代码,获取所有被声明的变量,然后在一行一行的运行。这造成的结果就是所有的变量的声明语句,都会被提升到代码的头部,这就叫做变量提升。
console.log(a) //undefined
var a = 1;
function b(){
console.log(a)
}
b() //1
//执行代码顺序:
//第一步:将var a = 1; 拆分为 var a = undefined 和 a = 1
//第二步:将var a = undefined 放到最顶端, a = 1 还在原来的位置
//这样一来代码就是这样的:
var a = undefined
console.log(a) //undefined
a = 1;
function b(){
console.log(a)
}
b() //1
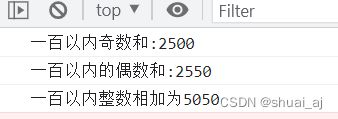
//第二步就是执行,因此js引擎一行一行从上往下执行,就造成的当前的结果,这就叫做变量提升。5、利用循环写出100以内的奇数和偶数的和
js中利用while循环语句各输出一百以内奇数和,偶数和以及总数。
6、javascript中的6中常见的数据类型是什么
基础数据类型String、Number、Boolean、Undefined、Null
引用数据类型: Object、Array、Function、Date等
Symbol、BigInt是ES6之后新增的 属于基本数据类型 Symbol 指的是独一无二的值
BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数
7、描述return和break以及continue有什么区别、作用?
break: 直接跳出当前的循环,从当前循环外面开始执行,忽略循环体中任何其他语句和循环条件测试。它只能跳出一层循环,如果你的循环是嵌套循环,那么你需要按照你嵌套的层次,逐步使用break来跳出。
continue: 终止当前的一次循环过程,其不跳出循环,而是继续往下判断循环条件执行语句。
只能结束循环中的一次过程,但不能终止循环继续进行。
return: 从当前的方法中退出,返回到该调用的方法的语句处,继续执行。
1、return语句的作用
(1) return 从当前的方法中退出,返回到该调用的方法的语句处,继续执行
(2) return 返回一个值给调用该方法的语句,返回值的数据类型必须与方法的声明中的返回值的类型一致,可以使用强制类型转换来是数据类型一致
(3) return 当方法说明中用void声明返回类型为空时,应使用这种格式,不返回任何值。
2、break语句的作用
(1) 只能在循环体内和switch语句体内使用break语句。
(2) 当break出现在循环体中的switch语句体内时,其作用只是跳出该switch语句体。
(3) 当break出现在循环体中,但并不在switch语句体内时,则在执行break后,跳出本层循环体。
(4) 在循环结构中,应用break语句使流程跳出本层循环体,从而提前结束本层循环
3、continue语句作用
(1) continue语句的一般形式为:continue;
(2) 其作用是结束本次循环,即跳过本次循环体中余下尚未执行的语句,接着再一次进行循环的条件判定。
(3) 注意:执行continue语句并没有使整个循环终止。在while和do-while循环中,continue语句使得流程直接跳到循环控制条件的测试部分 ,然后决定循环是否继续进行。
(4) 在for 循环中,遇到continue后,跳过循环体中余下的语句,而去对for语句中的“表达式3”求值,然后进行“表达式2”的条件测试,
最后根据“表达式2”的值来决定for循环是否执行。在循环体内,不论continue是作为何种语句中的语句成分,都将按上述功能执行,这点与break有所不同
8、描述==和===的区别
==,当两个运算符相等时,它返回true,即不检查数据类型
===,当两个运算符和数据类型都相等的情况下,才返回true
9、将二维数组转化为一维数组
方法一:使用ES5的reduce
reduce() 方法接收一个函数作为累加器(accumulator),数组中的每个值(从左到右)开始缩减,最终为一个值。arr.reduce(callback,[initialValue]) callback (执行数组中每个值的函数,包含四个参数)
1: previousValue (上一次调用回调返回的值,或者是提供的初始值(initialValue))
2:currentValue(数组中当前被处理的元素)
3:index (当前元素在数组中的索引)
4:array (调用 reduce 的数组)
initialValue (作为第一次调用 callback 的第一个参数。)
var arr=[[0,1],[2,3],[4,5]];
var onearr=arr.reduce(function(a,b){
return a.concat(b);
})
console.log(onearr);//[0,1,2,3,4,5]方法二:使用apply()
语法:apply([thisObj[,argArray]])
定义:应用某一对象的一个方法,用另一个对象替换当前对象
var arr=[[1,2],[3,4],[5,6]];
var onearr=[].concat.apply([],arr);
console.log(onearr);//[0,1,2,3,4,5]方法三:使用Array.prototype.flat()
flat() 方法会递归到指定深度将所有子数组连接,并返回一个新数组语法:var newArray = arr.flat(depth),
参数说明:depth,可选,指定嵌套数组中的结构深度,默认值为1。flat()方法会移除数组中的空项。但undefined、null仍会保留。
var arr=[[1,2],[3,4],[5,6]];
var onearr=arr.flat();
console.log(onearr);//[0,1,2,3,4,5]
方法四:
通过将数组转变成字符串,利用str.split(',')函数把字符串分割到数组中实现,但是这样数字全都变成字符串了
var arr1 = [[0, 1], [2, 3], [4, 5]];
第一种:var arr = (arr1 + '').split(',');
//利用+运算法在和字符串计算时会先转化为字符串,任何相加将其转为字符串
第二种:var arr = arr.toString().split(',');
第三种:var arr = arr.join().split(',');
10、反转数组
reverse 反转数组
1.使用For循环反转数组:
我们将为这种方法使用递减循环,以迭代给定数组的每个元素。 数组的最后一个元素将是循环的起点(arr.length — 1) ,它将一直运行直到到达数组的起点(i ≥ 0) 。
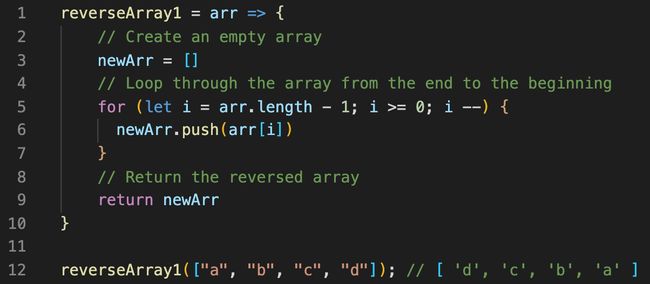
reverseArray1函数将一个数组( arr )作为参数,并通过向后循环遍历给定的数组,以相反的顺序创建一个相同元素的新数组( newArr )( let i = arr.length - 1; i >= 0; i -- )。 此解决方案不会修改原始数组,因为它会将元素推入并存储在新数组中,这会占用额外的空间。
2.使用Unshift()方法反转数组:
这种方法与第一种方法没有很大不同,因为它还使用一个额外的变量来存储反向数组,因此,原始数组保持不变。

reverseArray2函数从头到尾遍历给定数组( arr )。 它在新数组( newArr )上使用unshift方法,并将每个元素插入到数组的开始位置( newArr[0] )。 与第一个解决方案相比,第二个解决方案的空间效率也较低,因为它需要更多内存才能将反向数组存储在其他变量( newArr )中。
3.就地反转阵列:
与reverse方法类似,我们的最后一种方法也通过在原位反转其元素来修改原始数组。 这个解决方案; 与前两个解决方案相比, 就地反转数组要复杂得多。

11、查找一个字符串中是否具有某个字符
var name1 = $("input[name='NAME1']").val();
if(name1.indexOf("-") > 0){
alert("name1中包含 - 字符");
}
indexof的用法:返回 String 对象内第一次出现子字符串的字符位置。
indexOf方法返回一个整数值,指出 String 对象内子字符串的开始位置。如果没有找到子字符串,则返回 -1。
12、完成数组去重
1、使用es6 set方法
[...new Set(arr)]
let arr = [1,2,3,4,3,2,3,4,6,7,6]; let unique =(arr)=>[...newSet(arr); unique(arr);//[1,2,3,4,6,7]
2、利用新数组indexOf查找indexOf()方法可返回某个指定的元素在数组中首次出现的位置。如果没有就返回-1。
3、for双重循环通过判断第二层循环,去重的数组中是否含有该元素,如果有就退出第二层循环,如果没有j==result.length就相等,然后把对应的元素添加到最后的数组里面。13、实现求出数组中的最大值和最小值
//1、借用Math的方法;
var arr = [21,2313,4114,1241424,55,12,3,546,577];
var max = Math.max.apply(this,arr);
var min = Math.min.apply(this,arr);
console.log(min);
console.log(max);
//2、先排序,再取数组第一项和最后一项;
var arr1 = arr.sort(function(a,b){
return a- b;
})
console.log(arr1[0]);
console.log(arr1[arr1.length -1]);
//3、假设法;
//假设数组第一项为最小值;
for (var i = 0;iarr[j]){
max1 = max1;
}else{
max1 = arr[j];
}
}
console.log("最大值是:"+max1); 数组的最大值和最小值
For 循环
一般关于实现数组的某种操作,可能最先想到的就是 for 循环吧!下面是它的实现。
let min = arr => {
let greatest = arr[0]
for (let i = 0; i < arr.length; i++) {
if (greatest > arr[i]) {
greatest = arr[i]
}
}
return greatest
}
let max = arr => {
let greatest = 0
for (let i = 0; i < arr.length; i++) {
if (greatest < arr[i]) {
greatest = arr[i]
}
}
return greatest
}
console.log(max(arr)) // 25
console.log(min(arr)) // 1Math.min()/max()
内置函数 Math.max() 和 Math.min() 可以分别返回一直数中的最大值和最小值,其可以接受任意数量的参数。Math.max(25, 5, 15, 6, 9, 1, 3) // 25
Math.min(25, 5, 15, 6, 9, 1, 3) // 1
这很方便,但它不能直接用于数组。我们需要一些其他的方法来帮助我们使用它。
call/apply
Function.prototype.apply() 方法调用一个具有给定this值的函数,以及以一个数组的形式提供的参数。Function.prototype.call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。
apply() 第二个参数传递 arr 数组,使用数组中的所有值作为函数的参数。
call() 第二个参数传递 arr 数组,并使用扩展运算符,将其展开作为其函数的参数。
let max = arr => Math.max.apply(null, arr)
let min = arr => Math.min.call(null, ...arr)
console.log(max(arr)) // 25
console.log(min(arr)) // 1
扩展运算符
更为简单的方式是,直接使用 ES6 的扩展运算符(...)展开数组。console.log(Math.max(...arr)) // 25
console.log(Math.min(...arr)) // 1
Array.prototype.sort()
使用 Array.prototype.sort 先对数组进行排序,在获取数组的第一个元素。let arr = [25, 5, 15, 6, 9, 1, 3]
let max = arr => arr.sort((a, b) => b - a)[0]
let min = arr => arr.sort((a, b) => a - b)[0]
console.log(max(arr)) // 25
console.log(min(arr)) // 1
如果你还不熟,可以看看 如何在 JavaScript 中对对象数组进行排序?了解 sort() 的用法。
任意数量的最大值
从提供的数组返回 n 个最大元素。
使用 Array.prototype.sort() 和扩展运算符(...)配合,创建数组的浅拷贝,并按降序排序。
使用 Array.prototype.slice() 获取指定数量的元素。
省略第二个参数 n,得到一个单元素数组。
如果 n 大于或等于提供的数组长度,则返回原始数组(按降序排序)。
const maxN = (arr, n = 1) => [...arr].sort((a, b) => b - a).slice(0, n)
maxN([25, 5, 15, 6, 9, 1, 3]) // [25]
maxN([25, 5, 15, 6, 9, 1, 3], 3) // [25, 15, 9]
任意数量的最小值
从提供的数组返回 n 个最小元素。
使用 Array.prototype.sort() 和扩展运算符(...)配合,创建数组的浅拷贝,并按升序排序。
使用 Array.prototype.slice() 获取指定数量的元素。
省略第二个参数 n,得到一个单元素数组。
如果 n 大于或等于提供的数组长度,则返回原始数组(按升序排序)。
const minN = (arr, n = 1) => [...arr].sort((a, b) => a - b).slice(0, n)
minN([25, 5, 15, 6, 9, 1, 3]) // [1]
minN([25, 5, 15, 6, 9, 1, 3], 3) // [1, 3, 5]
这两个示例来自 30 seconds of code 的 maxN 和 minN
复杂情况 — 对象数组
对于更复杂的情况(即在对象数组中查找最小/最大值),您可能需要使用 Array.prototype.map() 等一些方法。
最小值
使用提供的函数将每个元素映射到一个值后,返回数组的最小值。
使用 Array.prototype.map() 将每个元素映射到 fn 所返回的值。
使用 Math.min() 获得的最小- 值。
const minBy = (arr, fn) =>
Math.min(...arr.map(typeof fn === 'function' ? fn : val => val[fn]))
minBy([{ n: 4 }, { id: 2 }, { id: 8 }, { id: 6 }], x => x.id) // 2
minBy([{ id: 4 }, { id: 2 }, { id: 8 }, { id: 6 }], 'id') // 2
最大值
使用提供的函数将每个元素映射到一个值后,返回数组的最大值。
使用 Array.prototype.map() 将每个元素映射到 fn 所返回的值。
使用 Math.max() 获取最大值。
const maxBy = (arr, fn) =>
Math.max(...arr.map(typeof fn === 'function' ? fn : val => val[fn]))
maxBy([{ id: 4 }, { id: 2 }, { id: 8 }, { id: 6 }], x => x.id) // 8
maxBy([{ id: 4 }, { id: 2 }, { id: 8 }, { id: 6 }], 'id') // 8
这两个示例来自 30 seconds of code 的 min-by 和 max-by
14、描述作用域是什么,必要情况可以使用代码增加描述
js中作用域(Scope)是什么?
作用域是可访问的变量的集合。在JavaScript中,作用域为可访问变量,对象,函数的集合,它分为局部作用域和全局作用域。作用域决定了这些变量的可访问性(可见性)。
1. 全局作用域(Global Scope)
在代码中任何地方都能访问到的对象拥有全局作用域,一般来说以下几种情形拥有全局作用域:
(1)最外层函数和在最外层函数外面定义的变量拥有全局作用域.
var outValue = "最外层变量"; //最外层变量
function outFun() { //最外层函数
var inValue = "内层变量";
function innerFun() { //内层函数
console.log(inValue );
}
innerFun();
}
console.log(outValue ); //最外层变量
outFun(); //最外层函数
console.log(inValue ); //inValue is not defined 内层变量是局部作用域,函数以外访问不到他
innerFun(); //innerFun is not defined 内层函数是局部作用域,函数以外访问不到他
(2)所有末定义直接赋值的变量自动声明为拥有全局作用域,
function outFun2() {
value1= "未定义直接赋值的变量";
var value2= "内层变量2";
}
outFun2();//要先执行这个函数,
console.log(value1); //未定义直接赋值的变量
console.log(value2); //value2not defined 内层变量2是局部作用域,函数以外访问不到他
(3)所有window对象的属性拥有全局作用域
2. 局部作用域(Local Scope)
和全局作用域相反,局部作用域一般只在固定的代码片段内可访问到,最常见的例如函数内部,所有在一些地方也会看到有人把这种作用域称为函数作用域,例如下列代码中的blogName和函数innerSay都只拥有局部作用域。上面例子也做说明。
3. 块级作用域
ES6 之前 JavaScript 没有块级作用域,只有全局作用域和函数作用域。ES6 的到来,为我们提供了‘块级作用域’,可通过新增命令 let 和 const 来体现。
块级作用域所声明的变量在指定块的作用域外无法被访问。块级作用域在如下情况被创建:
在一个函数内部、在一个代码块(由一对花括号包裹)内部let 声明的语法与 var 的语法一致。你可以用 let 来代替 var 进行变量声明,但会将变量的作用域限制在当前代码块中。块级作用域有以下几个特点:
1、声明变量不会提升到代码块顶部
let/const 声明并不会被提升到当前代码块的顶部,因此你需要手动将 let/const 声明放置到顶部,以便让变量在整个代码块内部可用。
console.log(color);
var color='red';
undefined
console.log(color2);
let color2='red';
Uncaught ReferenceError: Cannot access 'colo' before initialization
2、禁止重复声明
如果一个标识符已经在代码块内部被定义,那么在此代码块内使用同一个标识符进行 let 声明就会导致抛出错误。例如:
var count = 30;
let count = 40; // Uncaught SyntaxError: Identifier 'count' has already been declared3、循环中的绑定块作用域的妙用
这样就不会出现点击任意一个按钮,后台都是弹出“第四个”,这是因为 i 是全局变量,执行到点击事件时,此时 i 的值为 3。那该如何修改,最简单的是用 let 声明 i
// 第1个
// 第2个
// 第3个
15、实现一个函数,要求传递2个参数,返回两个参数的和
定义一个接受两个数字的方法,返回两个数字的和 →(javascript代返回值的函数的申明和调用)
16、描述函数return的作用
return语句的作用
(1) return 从当前的方法中退出,返回到该调用的方法的语句处,继续执行
(2) return 返回一个值给调用该方法的语句,返回值的数据类型必须与方法的声明中的返回值的类型一致,可以使用强制类型转换来使数据类型一致
(3) return 当方法说明中用void声明返回类型为空时,应使用这种格式,不返回任何值
1、返回函数结果 语法为:return+表达式
语句结束函数执行,返回调用函数,而且把表达式的值作为函数的结果。
return 表示从被调函数返回到主调函数继续执行,返回时可附带一个返回值, 由return后面的参数指定。
return通常是必要的,因为函数调用的时候计算结果通常是通过返回值带出的。return语句只能出现在函数体内,出现在代码中的其他任何地方都会造成语法错误!当执行return语句时,即使函数主体中还有其他语句,函数执行也会停止!
2、返回函数控制 语法为:return;
通常情况下return后面跟有表达式,但是并不是绝对的。此情况就是单纯的将控制权转交给主调函数继续执行。
在大多数情况下,为事件处理函数返回false,可以防止默认的事件行为。 例如,默认情况下点击一个a元素,页面会跳转到该元素href属性指定的页,但我们可以用return flase来阻止它的跳转。
在js中,我们常用return false来阻止提交表单或者继续执行下面的代码。
17、利用数学函数实现一个数组的最大值和最小值
// 1.排序法
先把数组从大到小排序,数组第一个即为最大值,最后一个即为最小值
let arr = [9, 5, 2, 1, 4];
arr.sort(function(a,b){
return b-a;
})
console.log(arr);//(5) [9, 5, 4, 2, 1]
max = arr[0];
min = arr[arr.length-1];
console.log('最大值 '+max,'最小值 '+min);
// 2.字符串拼接法
利用toString和join把数组转换为字符串,再和Math的max和min方法分别进行拼接,最后执行eval方法
let arr = [9, 5, 2, 1, 4];
let max = eval('Math.max(' + arr.toString() + ')');
let min = eval('Math.min(' + arr.toString() + ')');
console.log('最大值 '+max,'最小值 '+min);
// 3、假设法
假设数组第一个为最大(或最小值),和后边进行比较,若后边的值比最大值大(或比最小值小),则替换最大值(或最小值)
let arr = [9, 5, 2, 1, 4];
let max = arr[0];
let min = arr[0];
for (let i = 1; i < arr.length; i++) {
let temp = arr[i];
temp > max ? (max = temp) : null;
temp < min ? (min = temp) : null;
}
console.log('最大值 ' + max, '最小值 ' + min);
// 4、Math的max和min方法
使用apply方法使数组可以作为传递的参数
let arr = [9, 5, 2, 1, 4];
let max = Math.max.apply(null, arr);
let min = Math.min.apply(null, arr);
console.log(max, min);给定一个数组[1,8,5,4,3,9,2],编写一个算法,得到数组的最大值 9,和最小值 1。
1、通过prototype属性扩展min()函数和max()函数
算法1的思路是在自定义min()和max()函数中,通过循环由第一个值依次与后面的值作比较,动态更新最大值和最小值,从而找到结果。
// 最小值
Array.prototype.min = function () {
let min = this[0];
let len = this.length;
for (let i = 1; i < len; i++) {
if (this[i] < min) min = this[i]
}
return min
}
// 最大值
Array.prototype.max = function () {
let max = this[0];
let len = this.length;
for (let i = 1; i < len; i++) {
if (this[i] > max) max = this[i]
}
return max
}
// 结果
console.log(arr.min()); // 1
console.log(arr.max()); // 92、借助Math对象的min()函数和max()函数
算法2的主要思路是通过apply()函数改变函数的执行体,将数组作为参数传递给apply()函数。这样数组就可以直接调用Math对象的min()函数和max()函数来获取返回值
Array.min = function(array) {
return Math.min.apply(Math, array)
}
// 最大值
Array.max = function (array) {
return Math.max.apply(Math, array)
}
// 结果
console.log(Array.min(arr)); // 1
console.log(Array.max(arr)); // 93、算法2的优化
在算法2中将min()函数和max()函数作为Array类型的静态函数,但不支持链式调用,我们可以利用对象字面量进行简化。
// 最小值
Array.prototype.min = function() {
return Math.min.apply({}, this)
}
// 最大值
Array.prototype.max = function () {
return Math.max.apply({}, this)
}
// 结果
console.log(arr.min()); // 1
console.log(arr.max()); // 9与算法2不同的是,在验证时,因为min()函数和max()函数属于实例方法,所以可以直接通过数组调用。
上面的算法代码中apply()函数传入的第一个值为{},实际表示当前执行环境的全局对象。第二个参数this指向需要处理的数组。
由于apply函数的特殊性第一个参数,指定为 null 或 undefined 时会自动替换为指向全局对象,原始值会被包装。所以我们也可以将第一个参数设置为null、undefind。
4、借助Array类型的reduce()函数
算法4的主要思想是reduce()函数不设置initialValue初始值,将数组的第一个元素直接作为回调函数的第一个参数,依次与后面的值进行比较。当需要找最大值时,每轮累加器返回当前比较中大的值;当需要找最小值时,每轮累加器返回当前比较中小的值。
// 最小值
Array.prototype.min = function () {
return this.reduce((pre, cur) => {
return pre < cur ? pre : cur
})
}
// 最大值
Array.prototype.max = function () {
return this.reduce((pre, cur) => {
return pre > cur ? pre : cur
})
}
// 结果
console.log(arr.min()); // 1
console.log(arr.max()); // 95、借助Array类型的sort()函数
算法5的主要思想时借助数组的原生sort()函数对数组进行排序,排序完成后首尾元素即是数组的最小、最大元素。
默认的sort()函数在排序时时按照字母顺序排序的,数字会被按照字符串处理。例如数字 18 会被当做"18"处理,数字 6 被当"6"来处理,在排序时是按照字符串的每一位进行比较的,因为"1"比"6"要小,所以"11"排序时要比"6"小。对于数值类型的数组来说,这显然不合理。所以我们需要进行自定义排序
let sortArr = arr.sort((a, b) => a - b)
// 最小值
sortArr[0]
// 最大值
sortArr[sortArr.length - 1]
// 结果
console.log(sortArr[0]); // 1
console.log(sortArr[sortArr.length - 1]); // 96、借助ES6的扩展运算符
// 最小值
Math.min(...arr)
// 最大值
Math.max(...arr)
// 结果
console.log(Math.min(...arr)); // 1
console.log(Math.max(...arr)); // 918、利用随机数,完成一个随机生成的名字(2-3个汉字)
实现思路:
1.随机生成 中文范围内的Unicode码
2.将Unicode码转换成中文
3.循环多次进行拼接
1.随机生成 中文范围内的Unicode码
首先定义一个获取指定范围随机数的方法 (Unicode中文范围:4e00,9fa5)注意: 这个范围是十六进制的所以要么转换成10进制传参进去或者使用js中的十六进制传入 0x代表是十六进制
// 获取指定范围内的随机数
function randomAccess(min,max){
return Math.floor(Math.random() * (min - max) + max)
}
// Unicode中文范围:4e00,9fa5
// 因为这个范围是十六进制所以用十六进制的表示进行传参
//这样我们就拿到了中文范围的Unicode码
randomAccess(0x4e00,0x9fa5)2.将Unicode码转换成中文
我们需要将刚刚获取到的Unicode转换成中文,在页面上的Unicode显示方式是\u4e00
// 解码
function decodeUnicode(str) {
//Unicode显示方式是\u4e00
str = "\\u"+str
str = str.replace(/\\/g, "%");
//转换中文
str = unescape(str);
//将其他受影响的转换回原来
str = str.replace(/%/g, "\\");
return str;
}
注意:
randomAccess(0x4e00,0x9fa5) 方法获取出来的是 十进制的而页面显示是16进制否则我们拿到的是一些符号而不是中文
// randomAccess(0x4e00,0x9fa5) 方法获取出来的是十进制的
let chineseUnicode = randomAccess(0x4e00,0x9fa5);
let chinese = decodeUnicode(chineseUnicode);
console.log(chinese) // 输出的内容:ぷ所以我们要转成16进制传参
// 拿到十六进制的 Unicode码
let chineseUnicode = randomAccess(0x4e00,0x9fa5).toString(16);
let chinese = decodeUnicode(chineseUnicode);
console.log(chinese) // 输出的内容:定3.循环多次进行拼接
我们常用的汉字大概3000多个,所以会大概率的出现不是常用的,有心的朋友可以在继续完善一下
/*
*@param Number NameLength 要获取的名字长度
*/
function getRandomName(NameLength){
let name = ""
for(let i = 0;i完整代码
// 获取指定范围内的随机数
function randomAccess(min,max){
return Math.floor(Math.random() * (min - max) + max)
}
// 解码
function decodeUnicode(str) {
//Unicode显示方式是\u4e00
str = "\\u"+str
str = str.replace(/\\/g, "%");
//转换中文
str = unescape(str);
//将其他受影响的转换回原来
str = str.replace(/%/g, "\\");
return str;
}
/*
*@param Number NameLength 要获取的名字长度
*/
function getRandomName(NameLength){
let name = ""
for(let i = 0;i2023-04-19 网友优化写法
function getRandomName(length){
function randomAccess(min,max){
return Math.floor(Math.random() * (min - max) + max)
}
let name = ""
for(let i = 0;i19、实现获得页面滚动高度
document.documentElement.scrollTop || document.body.scrollTop有的时候确实有这样的业务 当浏览器滚动到 一定得高度之后 做一些 操作
这个时候就需要获取到我们滚动的高度了
但是 我看网上写的那个 document.body.scrollTop 好像获取不到
document.documentElement.scrollTop 这个才可以
window.scrollY, window.pageYOffset 这个两个也都可以
window.addEventListener( 'scroll', function() {
console.log(window.scrollY, window.pageYOffset)
}) 20、描述什么是闭包,并且描述出优缺点
闭包:是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包可以突破作用链域,将函数内部的变量和方法传递到外部。
闭包的优缺点
优点:延长变量生命周期、私有化变量
缺点:过多的闭包可能会导致内存泄漏
21、获取浏览器的宽度和高度
//原生js
document.body.clientWidth; //网页可见区域宽(body)
document.body.clientHeight; //网页可见区域高(body)
document.body.offsetWidth; //网页可见区域宽(body),包括border、margin等
document.body.offsetHeight; //网页可见区域宽(body),包括border、margin等
document.body.scrollWidth; //网页正文全文宽,包括有滚动条时的未见区域
document.body.scrollHeight; //网页正文全文高,包括有滚动条时的未见区域
document.body.scrollTop; //网页被卷去的Top(滚动条)
document.body.scrollLeft; //网页被卷去的Left(滚动条)
window.screenTop; //浏览器距离Top
window.screenLeft; //浏览器距离Left
window.screen.height; //屏幕分辨率的高
window.screen.width; //屏幕分辨率的宽
window.screen.availHeight; //屏幕可用工作区的高
window.screen.availWidth; //屏幕可用工作区的宽//jquery
$(window).height(); //浏览器当前窗口可视区域高度
$(document).height(); //浏览器当前窗口文档的高度
$(document.body).height(); //浏览器当前窗口文档body的高度
$(document.body).outerHeight(true); //浏览器当前窗口文档body的总高度 包括border padding margin
$(window).width(); //浏览器当前窗口可视区域宽度
$(document).width(); //浏览器当前窗口文档对象宽度
$(document.body).width(); //浏览器当前窗口文档body的宽度
$(document.body).outerWidth(true); //浏览器当前窗口文档body的总宽度 包括border padding margin//pc端
按屏幕宽度大小排序(主流的用橙色标明)
分辨率 比例 | 设备尺寸
1024*500 (8.9寸)
1024*768 (比例4:3 | 10.4寸、12.1寸、14.1寸、15寸; )
1280*800(16:10 |15.4寸)
1280*1024(比例:5:4 | 14.1寸、15.0寸)
1280*854(比例:15:10 | 15.2)
1366*768 (比例:16:9 | 不常见)
1440*900 (16:10 17寸 仅苹果用)
1440*1050(比例:5:4 | 14.1寸、15.0寸)
1600*1024(14:9 不常见)
1600*1200 (4:3 | 15、16.1)
1680*1050(16:10 | 15.4寸、20.0寸)
1920*1200 (23寸)通过上面的电脑屏蔽及尺寸的例表上我们得到了几个宽度 1024 1280 1366 1440 1680 1920 PC端响应式媒体断点
@media (min-width: 1024px){
body{font-size: 18px} /*>=1024的设备*/
}
@media (min-width: 1100px) {
body{font-size: 20px} /*>=1100的设备*/
}
@media (min-width: 1280px) {
body{font-size: 22px;} /*>=1280的设备*/
}
@media (min-width: 1366px) {
body{font-size: 24px;}
}
@media (min-width: 1440px) {
body{font-size: 25px;}
}
@media (min-width: 1680px) {
body{font-size: 28px;}
}
@media (min-width: 1920px) {
body{font-size: 33px;}
}
1、使用jQuery获取浏览器的宽度
//JQuery 获取浏览器宽度 :浏览器的可视宽度-滚动条的宽度(如果出现垂直方向滚动条)
var winWidth = $(window).width();2、使用Js 获取浏览器宽度
● window.outerWidth: 浏览器宽度,包含了浏览器边框所以这种方式不常用。
● window.outerHeight: 浏览器高度
● window.innerWidth: 浏览器内页面可用宽度,此宽度包含了垂直滚动条的宽度(若存在)。
● window.innerHeight: 浏览器内页面可用高度,此高度包含了水平滚动条的高度(若存在)。、
从window.resize 事件中获取浏览器宽度:
$(window).resize(function (e) {
//var innerWidth = e.currentTarget.innerWidth;
var innerWidth = window.innerWidth;22、事件处理程序有几种,分别实现
Javascript事件处理程序的3种方式
产生了事件,我们就要去处理他,据马海祥了解Javascript事件处理程序主要有3种方式:
1、HTML事件处理程序
即我们直接在HTML代码中添加事件处理程序,如下面这段代码:
从上面的代码中我们可以看出,事件处理是直接嵌套在元素里头的,这样有一个毛病:就是html代码和js的耦合性太强,如果哪一天我想要改变js中showmsg,那么我不但要再js中修改,我还需要到html中修改,一两处的修改我们能接受,但是当你的代码达到万行级别的时候,修改起来就需要劳民伤财了,所以,这个方式我们并不推荐使用。
2、DOM0级事件处理程序
即为指定对象添加事件处理,看下面的一段代码
从上面的代码中,我们能看出,相对于HTML事件处理程序,DOM0级事件,html代码和js代码的耦合性已经大大降低。但是,聪明的程序员还是不太满足,期望寻找更简便的处理方式,下面马海祥就来说说第三种处理方法。
3、DOM2级事件处理程序
DOM2也是对特定的对象添加事件处理程序(具体可查看马海祥博客的《JavaScript对象属性的基础教程指南》相关介绍),但是主要涉及到两个方法,用于处理指定和删除事件处理程序的操作:addEventListener()和 removeEventListener()。
它们都接收三个参数:要处理的事件名、作为事件处理程序的函数和一个布尔值(是否在捕获阶段处理事件),看下面的一段代码:
这里我们可以看到,在添加删除事件处理的时候,最后一种方法更直接,也最简便。但是马海祥提醒大家需要注意的是,在删除事件处理的时候,传入的参数一定要跟之前的参数一致,否则删除会失效!
23、描述事件流的冒泡和捕获的区别
DOM事件模型分为捕获和冒泡。
一个事件发生后,会在子元素和父元素之间传播(propagation)。
这种传播分成三个阶段。
(1)捕获阶段:事件从window对象自上而下向目标节点传播;
(2)目标阶段:真正的目标节点正在处理事件;
(3)冒泡阶段:事件从目标节点自下而上向window对象传播。
冒泡流:事件由最具体的元素响应 然后组件冒泡到最不具体的元素(html)
捕获流:从最不具体的元素捕获事件
开启捕获 addEventListenter第三个参数 true
阻止事件冒泡:e.stopPropagation()
24、描述this关键字在不同情况下的指向
this的指向主要有下面几种:
1、this出现在全局函数中,永远指向window
2、this出现在严格模式中 永远不会指向window
3、当某个函数为对象的一个属性时,在这个函数内部this指向这个对象
4、this出现在构造函数中,指向构造函数实例
5、当一个元素被绑定事件处理函数时,this指向被点击的这个元素
6、this出现在箭头函数中时,this和父级作用域的this指向相同
25、什么是回流和重绘
重排:当页面元素的尺寸、结构、或某些属性发生改变时,浏览器重新渲染部分或全部文档的过程叫做重排也叫做回流。
重绘:当页面元素样式的改变不影响布局时,浏览器重新对元素进行更新的过程叫做重绘。
重绘是小改变,重绘不一定会发生重排。 重排就是大改变,重排一定会触发重绘,重排会产生比重绘更大的开销。
26、利用定时器实现节流
----节流
指连续触发事件但是在n秒中只执行一次函数
节流会稀释函数的执行频率
策略:固定周期内,只执行一次动作,若没有新事件触发,不执行;周期结束后,又有事件触发,开始新的周期
特点:连续高频触发事件时,动作会被定期执行,响应平滑
计时器版节流
// 节流,使用时间戳
function throttle(fn, delay) {
let start = Date.now();
return function() {
let that = this;
let args = arguments;
// 获取当前时间,通过 当前时间 - 起点时间 = 时间差,,, 判断 时间差和 delay的关系
let diff = Date.now() - start
if (diff > delay) {
fn.apply(that, args)
// 初始化时间
start = Date.now()
}
}
}
// 真正的逻辑处理函数
function print() {
console.log("逻辑处理");
}
window.onscroll = throttle(print, 2000)//节流函数:连续触发事件时 n秒内只能执行一次处理函数。
function throttle(fn, delay) {
let previous = 0;//因为内部函数会调用这个变量,所以在函数执行完之后,这个变量不会被销毁
return function () {//节流的函数
let args = arguments;//argument是传入函数的参数
let now = new Date();
console.log(this)
if (now - previous > delay) {
// fn.apply(this, args);
fn()
previous = now;
}
}
}
function testThrottle() {
console.log("需要节流的函数");
}
let testThrottleFn = throttle(testThrottle, 2000); // 节流函数
testThrottleFn('popop', 'pl')
document.getElementById('btn').onclick = function () {
testThrottleFn('popop', 'pl')
}
27、利用定时器实现防抖
----防抖
指触发事件后在n秒内函数只能执行一次,如果在n秒内又触发了事件,则会重新计算函数执行时间
策略:当事件被触发时,设定一个周期延迟执行动作,若周期又被触发,则重新设定周期,直到周期结束,执行动作
//防抖,使用定时器
function debounce(fn, delay) {
let timer = null
return function() {
if (timer) {
clearTimeout(timer)
}
// timer = setTimeout(fn, delay)
// 考虑到this指向和传参的问题
let that = this;
let args = arguments;
timer = setTimeout(function() {
fn.apply(that, args)
}, delay)
}
}
// 真正的逻辑处理函数
function print() {
console.log("逻辑处理");
}
window.onscroll = debounce(print, 2000)28、简述什么是cookie有什么作用
Cookie就是一个头,Cookie由服务器创建,服务器以响应头的形式发送给客户端,客户端收到Cookie以后,会将其自动保存,在下次向服务器发送请求时会自动将Cookie以请求的形式发出,服务器收到以后就可以检查请求头中的Cookie并且可以根据Cookie中的信息来识别出不同的用户。
cookie有两个作用:
1.记录用户身份
用户A第一次访问a网站的时候,a网站发现A没有附带uID数据,此时就会返回给用户A一段数据[uID=1],这样A每次访问a网站就会带上[uID=1]这个数据
2.记录用户历史
假设一个购物车网站b,用户B[uID=2],此时他把B1,B2商品加入购物车,[uID=2,CART=B1,B2],过去了几天,B再次打开b网站,发现商品仍在购物车中,因为浏览器不会轻易删除cookie。
简单理解就是:
其实cookies是由网络服务器存储在你电脑硬盘上的一个txt类型的小文件,它和你的网络浏览行为有关,所以存储在你电脑上的cookies就好像你的一张身份证,你电脑上的cookies和其他电脑上的cookies是不一样的;cookies不能被视作代码执行,也不能成为病毒,所以它对你基本无害。
cookies的作用主要是,当你访问了某些网页,并且对网页的一些设置进行修改,cookies就能跟踪并记录到这些修改,当你下一次访问这个网页的时候,这个网页会分析你电脑上的cookies,进而采取措施像你返回更符合你个性化的网页;
29、简述原型与原型链
原型:
所有的构造方法中都会有一个属性__prototype属性,这个属性会指向一个对象prototype原型, 这个对象被称为原型对象,简称原型。原型中存储的是该构造方法创建出来的所有实例可以共享的内容
原型链: 当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么它就会去它的原型对象里找这个属性,这个原型对象又会有自己的原型,于是就这样一直找下去,也就是原型链的概念。原型链的尽头一般来说都是Object.prototype所以这就是我们新建的对象为什么能够使用toString()等方法的原因
30、实现一个对象的继承(js对象继承的5种方式)
1、原型链继承
通过b函数的原型(b.prototype)指向a的实例(new a())来实现,这种继承方法就称为原型链继承。
代码实现:
这里用 parent 和 child 分别表示上述的 a 和 b
function parent(){
this.data = '111'
}
function child(){}
child.prototype = new parent()
var c = new child()
console.log(c.data) //111
这种方式存在缺点:
存在引用值共享问题,就是当a中某个属性是引用数据类型的时候,b实例如果修改了这个属性的内容则其他的b实例中这个属性也会一起改变(正常来说应该是互不干扰的,原始数据类型属性就是互不干扰的)
2、构造函数继承
通过在b函数中独立执行a( 此时a的this指向window ),然后通过call方法改变a的指向指向b实例( a.call(this) ),这样new出来的b实例就能访问到a中的属性和方法了。这种方法就称为构造函数继承。
代码实现:
这里用 parent 和 child 分别表示上述的 a 和 b
function parent(){
this.data = '111'
}
function child(){
parent.call(this)
}
var c = new child()
console.log(c.data)//111
这种方式同样存在缺点:
使用这种方法b实例没有办法拿到a函数原型上的属性和方法。
function parent(){
this.data = '111'
}
parent.prototype.say = function(){
console.log("222")
}
function child(){
parent.call(this)
}
var c = new child()
console.log(c.data)
c.say()

3、组合继承(伪经典继承)
这个方法是结合了上述的两个方法,用构造函数继承中的b函数独立执行a来解决原型链继承的引用值共享问题,用原型链继承中b函数的原型指向a的实例来解决构造函数中b实例无法访问a原型上属性和方法的问题。
代码实现:
这里用 parent 和 child 分别表示上述的 a 和 b
function parent(){
this.data = '111'
}
parent.prototype.say = function(){
console.log("222")
}
function child(){
parent.call(this)
}
child.prototype = new parent()
var c = new child()
console.log(c.data)
c.say()
伪经典继承相比于经典继承,new了两次parent,会产生了属性与方法重叠的问题。
4、寄生组合继承(经典继承)
对组合继承中b函数原型指向a实例进行修改,通过使用es5的Object.create方法来将b函数原型直接指向a的原型,省去了 new a() 的步骤。
代码实现:
这里用 parent 和 child 分别表示上述的 a 和 b
function parent(){
this.data = '111'
}
parent.prototype.say = function(){
console.log("222")
}
function child(){
parent.call(this)
}
//es5之前就重写Object.create方法
if(!Object.create){
Object.create = function(proto){
function F(){}
F.prototype = proto
return new F()
}
}
child.prototype = Object.create(parent.prototype)
var c = new child()
console.log(c.data)
c.say()
缺点:
通过Object.create改变b原型的指向后,b原型上原有的属性和方法就消失了。
5、es6的extends类继承
child类通过extends继承了parent类的属性和方法。
class parent {
constructor(a){
this.filed1 = a;
}
filed2 = 2;
func1 = function(){}
}
class child extends parent {
constructor(a,b) {
super(a);
this.filed3 = b;
}
filed4 = 1;
func2 = function(){}
}
31、什么是面向对象编程
面向对象编程(Object Oriented Programming,缩写为 OOP)是目前主流的编程范式
面向对象编程 (OOP) 是一种编码设计,它使用数据来表示一组指令。OOP 设计围绕可实例化为对象的专用类展开。
与过程式或函数式编程不同,OOP 为我们提供了更全面地表达代码的余地。虽然以前的范式通常没有结构,但 OOP 鼓励使用称为类的专用结构。
方法是在类中执行特定任务的函数。属性就像描述类特征或特性的变量。方法可以独立运行,也常常基于类的属性。最终,两者共同作用,实现了OOP的概念。
为什么要使用面向对象?
可维护、可复用、可扩展、灵活性好
面向对象编程的优点 那么面向对象编程如何帮助你编写更好的程序呢?
OOP 降低了代码库的复杂性。
它可以帮助我们清楚地表达我们的代码,使其更具可读性。
用 OOP 编写的程序通常更具可扩展性。
它简化了代码测试和调试。
OOP消除了代码重复,建立了DRY(不要重复自己)原则。
OOP 代码通常更加模块化,鼓励关注点分离。
类组合和继承使代码更易于重用。
抽象提高了代码库的安全性。
面向对象编程的缺点 虽然OOP的优点大于缺点,但缺点也不能忽视:
1、它可能比函数式编程慢。
2、OOP陡峭的学习曲线很陡峭。
3、脚本文件夹和文件随着应用程序的扩展而增加。
面向对象的编程结构
OOP 围绕严格的架构展开。以下是我们将了解的一些术语:
类 类是作为执行类似操作的数据表示的代码集合。我们可以将类视为对象处理程序,因为我们可以使用对象处理程序来实例化对象。
方法 方法定义类如何完成其任务。一个类可以包含一个或多个方法。我们可以将方法视为类在其内部分担职责的方式。
例如,单位转换器类可能包含将摄氏度转换为华氏度的方法。它可能包括另一种将克更改为千克的方法。
属性 属性是描述类的要素或属性。例如,单位转换器类可能包含转换单位等属性。我们可以定义作用于这些属性的方法。
与方法一样,我们可以从类实例访问(某些)属性。
对象 简单地说,对象是一个类的实例。实例化类时,生成的对象将使用该类作为其属性和方法的蓝图。
面向对象编程的原则 面向对象编程为编程表带来了一些原则。这些中的每一个都使其领先于传统编程。
32、写出一个邮箱的正则验证
实例1、只允许英文字母、数字、下划线、英文句号、以及中划线组成
分析邮件名称部分:
26个大小写英文字母表示为a-zA-Z 数字表示为0-9 下划线表示为_ 中划线表示为- 由于名称是由若干个字母、数字、下划线和中划线组成,所以需要用到+表示多次出现
根据以上条件得出邮件名称表达式:[a-zA-Z0-9_-]+ 分析域名部分:
一般域名的规律为“N级域名二级域名.顶级域名”,比如“qq.com”、“www.qq.com”、“mp.weixin.qq.com”、“12-34.com.cn”,分析可得域名类似“** .** .** .”组成。“”部分可以表示为[a-zA-Z0-9_-]+
“.”部分可以表示为.[a-zA-Z0-9-]+多个“.”可以表示为(.[a-zA-Z0-9-]+)+
综上所述,域名部分可以表示为[a-zA-Z0-9-]+(.[a-zA-Z0-9-]+)+
最终表达式:由于邮箱的基本格式为“名称@域名”,需要使用“^”匹配邮箱的开始部分,用“$”匹配邮箱结束部分以保证邮箱前后不能有其他字符,所以最终邮箱的正则表达式为:
^[a-zA-Z0-9-]+@[a-zA-Z0-9-]+(.[a-zA-Z0-9_-]+)+$
例2、名称允许汉字、字母、数字,域名只允许英文域名
举例:杨元庆[email protected]
分析邮件名称部分:
汉字在正则表示为[\u4e00-\u9fa5] 字母和数字表示为A-Za-z0-9 通过分析得出邮件名称部分表达式为[A-Za-z0-9\u4e00-\u9fa5]+ 分析邮件域名部分
邮件部分可以参考实例1中的分析域名部分。 得出域名部分的表达式为[a-zA-Z0-9-]+(.[a-zA-Z0-9-]+)+ 最终表达式:我们用@符号将邮箱的名称和域名拼接起来,因此完整的邮箱表达式为
^[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9-]+(.[a-zA-Z0-9-]+)+$
jQuery
1、添加一个滚动事件,实现滚动到200px部分,隐藏一个元素
2、利用jQuery的遍历,获取每一个li标签元素,修改元素内容
jquery each()方法可用于遍历一个列举元素,如Li标签,本文介绍两个不同的写法。
用each()方法遍历Li标签,获取每个Li标签的文本。
// 第一种写法:
$("#ul_Items li").each(function(){
var self=$(this);
console.log(self.text());
});
// 第二种写法:
$.each($("#ul_Items li"),function(){
var self=$(this);
console.log(self.text());
});这两种写法都能实现同样的功能,最后输出结果如图所示:
我们精简代码后看看,其实是$().each()和$.each()的两种写法结构,选择哪种完全按个人喜好。
//$().each()和$.each()的区别?
//$().each()和$.each() 这两种写法,在实际编程时有什么区别呢?
$(selector).each(function(index,element))
$.each(dataresource,function(index,element))下面就对这两个函数做深入的探讨:
1、$(selector).each(function(index,element))
作用:在dom处理上面用的较多
示例:
$("#each_id li").each(function(){ console.log($(this).text())
});2、$.each(dataresource,function(index,element))
作用:在数据处理上用的比较多
示例:
此处没有html代码,只有js代码,如下:
var jsonResourceList = '[{"id":"1","tagName":"apple"},{"id":"2","tagName":"orange"},{"id":"3","tagName":"banana"},{"id":"4","tagName":"watermelon"}]';
if(jsonResourceList.length >0){
$.each(JSON.parse(jsonResourceList), function(index, obj) {
console.log(obj.tagName);
});
}3、结论:
在遍历DOM时,通常用$(selector).each(function(index,element))函数。
在遍历数据时,通常用$.each(dataresource,function(index,element))函数。
3、jquery提供的选择器eq()是具体可以做什么
jquery :eq选择器和eq()方法的用法与比较
:eq(index)
匹配一个给定索引值的元素
index:从 0 开始计数
$("ul li:eq(3)") // 元素的index位置工0开始计数,所以这里的3实际为第4个元素
$("ul").find("li").eq(3) //使用jquery遍历方法eq()eq(index|-index)
获取第N个元素
index:一个整数,指示元素基于0的位置,这个元素的位置是从0算起。
-index:一个整数,指示元素的位置,从集合中的最后一个元素开始倒数。(1算起)
获取匹配的第二个元素
This is just a test.
So is this
$("p").eq(1) 或者 $("p").eq(-1)
应用:tab选项卡
若是
$('div.tab_box > div') //选取子节点
.eq(index).show().siblings().hide();这样写就可以实现tab切换的效果,
若是
$('div.tab_box > div:eq(index)')
.show().siblings().hide()就不能切换。
解释:
:eq()选择器中要写变量,即index是动态变化的,则需要用+ +连接,
即:$(‘div.tab_box > div:eq(‘+index+’)’)
注意:是前面的引号为一对,后面的引号为一对,也可以前面一对引号为双引号,后面为单引号。
这样两种方法即都可实现动态选择 tab选项卡。
如果两个性能是有区别的话,估计第一个性能会比较好点。
$('#????:eq(0)') 返回 符合#????选择器的元素集合第一个,它的类型是jQuery对象
$('#????').eq(0) 返回 $('#????') jquery元素集合的第一个元素,并将之转换为 javascript对象
4、利用jQuery实现回到顶部效果
1、首先,我们要准备HTML代码:
这里的标签里面的href=“#top”就表示点击它就可以回到顶部,就不写回到顶部的代码了
2、设置其CSS样式:
#return-top{
width: 50px;
height: 50px;
background-color: #8FBC8F;/*背景颜色*/
color: white;/*字体颜色*/
position: fixed;/*固定按钮的位置,不随页面滚动*/
bottom: 40px;/*距离浏览器窗口底部的距离*/
right: 40px;/*距离浏览器窗口最右侧的距离*/
text-align: center;
display:none;/*重点!我们打开页面时不需要看到这个按钮,设置为不显示*/
}
#return-top a{
color:white;
text-decoration:none;/*不要下划线*/
line-height:20px;/*行高*/
display:block;/*不使用这个属性的话,文字对不齐。。。具体原因我没了解过*/
margin:5px;/*元素四周的外边距为5像素,加上行高*2(因为有两行),刚好是50px(div的高)*/
}一顿胡乱操作之后,“返回顶部”按钮就有了如下这个外观:
3、重点来了,jQuery代码部分:
解释一下:首先我们要做的功能是:用户打开网页,看不到按钮,滚动到了离页面顶端较远的地方,按钮自己出来了,点击按钮回到顶部,按钮又消失了
代码思路:当浏览器的滚动条靠近顶端的时候,“回到顶部”按钮始终隐藏(包括刚打开网页的时候,设置display:none),使用hide()方法;
当滚动条位置有了变化,触发浏览器窗口的滚动事件(scroll()方法),当滚动条位置距离初始位置大于一定数值(像素值)时,按钮显示(show()方法)
提示:使用jQuery代码,要先引入js文件哦哦!
5、利用jQuery实现轮播图效果
一.html部分的代码如下
<
>
-

-

-

-

-

注意我们要在最后加上一张和第一张重复的图片,方便后续功能的实现
ol中装的li时下面的小圆点,left,right分别就是左右切换按钮
二 .css部分如下
三. jQuery实现
6、立即执行函数的优势
声明一个函数,并马上调用这个匿名函数就叫做立即执行函数; 也可以说立即执行函数是一种语法,让你的函数在定义后立即执行;
立即执行函数的作用:
1.不必为函数命名,避免了污染全局变量。
2.立即执行函数内部形成了一个单独的作用域,可以封装一些外部无法读取的私有变量。
3.封装变量。
php 前后端交互
1、描述服务器的作用与前端的关系【简答】
服务器的作用
1、服务器作为网络的节点,存储、处理网络上80%的数据、信息,因此也被称为网络的灵魂。
2、做一个形象的比喻:服务器就像是邮局的交换机,而微机、笔记本、PDA、手机等固定或移动的网络终端,就如散落在家庭、各种办公场所、公共场所等处的电话机。
3、我们与外界日常的生活、工作中的电话交流、沟通,必须经过交换机,才能到达目标电话;同样如此,网络终端设备如家庭、企业中的微机上网,获取资讯,与外界沟通、娱乐等,也必须经过服务器,因此也可以说是服务器在"组织"和"领导"这些设备。
4、它是网络上一种为客户端计算机提供各种服务的高可用性计算机,它在网络操作系统的控制下,将与其相连的硬盘、磁带、打印机、Modem及各种专用通讯设备提供给网络上的客户站点共享,也能为网络用户提供集中计算、信息发表及数据管理等服务。
5、它的高性能主要体现在高速度的运算能力、长时间的可靠运行、强大的外部数据吞吐能力等方面。
前后端的关系(客户端和服务器端)
服务器端是为客户端服务的,客户端就是为真正的“客户”来服务的,所以这两者之间不同,但又密切相连,客户端是请求方或者说 是指令发出方,而服务器端是响应方
前台与后台
前台:呈现给用户的视觉和基本的操作。
后台:用户浏览网页时,我们看不见的后台数据跑动。
重要概念:后台包括前端,后端。
前端与后端
前端:对应我们写的html 、javascript 等网页语言作用在前端网页。
后端:对应jsp、javaBean 、dao层、action层和service层的业务逻辑代码。(包括数据库)
为什么jsp是后端呢?主要是:jsp的运行原理----在tomcat服务器运行的。
2、独立安装php运行环境【实操】
3、实现Mysql语句的增删改查
数据库语句_增加
INSERT INTO `user` VALUES (null,'ime','helloime','[email protected]');温馨提示
字段必须一一对应
id字段为主键自增,不需要指定内容
查询表名或者字段名字需要用反引号(``)
数据库语句_删除
DELETE FROM `user` WHERE id=2温馨提示
删除的时候,需要指定条件,例如
where id=2
数据库语句_修改
UPDATE `user` SET `password`='itbaizhan',`email`='[email protected]' WHERE id=1数据库语句_查询
查询整张表
SELECT * FROM `user`条件查询
SELECT * FROM `user` WHERE id=1;
SELECT * FROM `user` WHERE `username`='ime'多条件查询
and 是与
or 是 或
SELECT * FROM `user` WHERE `username`='ime' and `password`='helloime'
SELECT * FROM `user` WHERE `username`='ime' or `username`='iwen'4、安装MySQL可视化工具[实操]
6、实现PHP从前端到服务器到数据库的交互操作
PHP+MySQL完成前后端交互
Document
$username = $_POST['username'];
$password = $_POST['password'];
$con=mysqli_connect('localhost','root','','itbaizhan');
if($con){
// 设置编码格式utf8
mysqli_query($con,'set names utf8');
// 编写数据库语句
$sql="select * from user where username='$username' and password='$password'";
// 执行数据库语句
$result=mysqli_query($con,$sql);
// 格式化
$data = mysqli_fetch_all($result,MYSQLI_ASSOC);
// 关闭数据库
mysqli_close($con);
if (count($data) > 0) {
echo '登陆成功';
} else {
echo '账户或者密码错误';
}
}else{
echo '连接失败';
}7、完成PHP与MySQL的增删改查
'; // 格式化
print_r($data);
} else {
echo '数据库连接失败';
}
?>
// 1、增加语句:INSERT INTO 语法
需指定要插入数据的列名,只需提供被插入的值即可
INSERT INTO table_name VALUES (value1,value2,value3,...);
需要指定列名及被插入的值
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
不指定列名向表格插入一条数据
INSERT INTO stu VALUES (null,'提莫', 1,30);
我们用第二种语法向表格插入一条数据
INSERT INTO stu (name, gender, age) VALUES ('Faker', 0,24);
// 2、查询语句
SQL SELECT 语句
SELECT column_name,column_name FROM table_name;
SELECT * FROM table_name;
查询id一列
select id from stu;
查询当id为1的语句
select * from stu where id = 1;
因为id是唯一的,所以找到了该条数据则不用再继续
select * from stu where id = 1 limit 1;
// 3、修改语句
SQL UPDATE 语句 需要加上where语句,否则整个表格都会更新
UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
修改名字当id为1的时候
update stu set name='the shy' where id=1;
// 4、删除语句
SQL DELETE 语法 WHERE 子句规定哪条记录或者哪些记录需要删除。如果您省略了 WHERE 子句,所有的记录都将被删除!
DELETE FROM table_name WHERE some_column=some_value;
删除id为2的该条学生信息
delete from stu where id = 2;原文链接:https://blog.csdn.net/weixin_41105030/article/details/89357205/
8、描述前后端交互的方式,前后端分离的优势
方式一:表单提交
表单(form):表单用于收集用户输入信息,并将数据提交给服务器。是一种常见的与服务端数据交互的一种方式
1. action:指定表单的提交地址
2. method:指定表单的提交方式,get/post,默认get
3. input的数据想要提交到后台,必须指定name属性,后台通过name属性获取值
4. 想要提交表单,不能使用input:button 必须使用input:submit
php获取表单数据:
$_GET是PHP系统提供的一个超全局变量,是一个数组,里面存放了表单通过get方式提交的数据。
$_POST是PHP系统提供的一个超全局变量,是一个数组,里面存放了表单通过post方式提交的数据。
get与post的区别?1. get方式
1.1 数据会拼接在url地址的后面?username=hcc&password=123456
1.2 地址栏有长度限制,因此get方式提交数据大小不会超过4k
2. post方式
2.1 数据不会在url中显示,相比get方式,post更安全
2.2 提交的数据没有大小限制根据HTTP规范,GET用于信息获取,POST表示可能修改变服务器上的资源的请求
http协议
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则
HTTP协议,即超文本传输协议(Hypertext transfer protocol)。是一种详细规定了浏览器和服务器之间互相通信的规则,HTTP协议分为请求 和响应 两个部分组成。
方式二:Ajax
即 Asynchronous [e’sɪŋkrənəs] Javascript And XML, AJAX 不是一门的新的语言,而是对现有技术的综合利用。 本质是在HTTP协议的基础上以异步的方式与服务器进行通信。
XMLHttpRequest
浏览器内建对象,用于与服务器通信(交换数据) , 由此我们便可实现对网页的部分更新,而不是刷新整个页面。这个请求是异步,即在往服务器发送请求时,并不会阻碍程序的运行,浏览器会继续渲染后续的结构。
发送get请求
XMLHttpRequest以异步的方式发送HTTP请求,因此在发送请求时,一样需要遵循HTTP协议。
//使用XMLHttpRequest发送get请求的步骤
//1. 创建一个XMLHttpRequest对象
var xhr = new XMLHttpRequest;//构造函数没有参数的情况,括号可以省略
//2. 设置请求行
//第一个参数:请求方式 get/post
//第二个参数:请求的地址 需要在url后面拼上参数列表
xhr.open("get", "08.php?name=hucc");
//3. 设置请求头
//浏览器会给我们默认添加基本的请求头,get请求时无需设置
//4. 设置请求体
//get请求的请求体为空,因为参数列表拼接到url后面了
xhr.send(null);get请求,设置请求行时,需要把参数列表拼接到url后面
get请求不用设置请求头
get请求的请求体为null
发送post请求
var xhr = new XMLHttpRequest;
//1. 设置请求行 post请求的参数列表在请求体中
xhr.open("post", "09.php");
//2. 设置请求头, post请求必须设置content-type,不然后端无法获取到数据
xhr.setRequestHeader("content-type", "application/x-www-form-urlencoded");
//3. 设置请求体
xhr.send("name=hucc&age=18");post请求,设置请求行时,参数列表不能拼接到url后面
post必须设置请求头中的content-type为application/x-www-form-urlencoded
post请求需要将参数列表设置到请求体中.
获取响应
HTTP响应分为3个部分,状态行、响应头、响应体。
//给xhr注册一个onload事件,当xhr的状态发生状态发生改变时,会触发这个事件。
xhr.onload = function () {
//1. 获取状态行
console.log("状态行:"+xhr.status);
//2. 获取响应头
console.log("所有的相应头:"+xhr.getAllResponseHeaders());
console.log("指定相应头:"+xhr.getResponseHeader("content-type"));
//3. 获取响应体
console.log(xhr.responseText);
}原文链接:https://blog.csdn.net/qq_44704740/article/details/103464168
优点
有更好的性能优化
更具有专一性
更利于后期维护
优点:
1、提高开发效率 前后端各负其责, 前端和后端都做自己擅长的事情,不互相依赖,开发效率更快,而且分工比较均衡,会大大提高开发效率
2、用户访问速度快,提升页面性能,优化用户体验。
前后端不分离,稍不留神会触发浏览器的重排和重绘,加载速度慢
3、降低用户的体验 增强代码可维护性,降低维护成本,改善代码的质量。
前后端不分离,代码较为繁杂,维护起来难度大,成本高
4、减轻了后端服务器的请求压力 公共资源只需要加载一次,减少了HTTP请求数 同一套后端程序代码,不用修改就可以用于Web界面、手机、平板等多种客户端
缺点:
1、首屏渲染的时间长
将多个页面的资源打包糅合到一个页面,这个页面一开始需要加载的东西会非常多,而网速是一定的,所以会导致首屏渲染时间很长,首屏渲染后,就是无刷新更新,用户体验相对较好
2、不利于搜索引擎的优化(SEO)
现有的搜索引擎都是通过爬虫工具来爬取各个网站的信息,这些爬虫工具一般只能爬取页面上(HTML)的内容,而前后端分离,前端的数据基本上都是存放在行为逻辑(JavaScript)
文件中,爬虫工具无法爬取,无法分析出你网站到底有什么内容,无法与用户输入的关键词做关联,最终排名就低
3、不能使用浏览器里面的前进后退功能 一些版本较低的浏览器对其支持度不足
9、独立完成XHR网络请求对象的封装操作
// 封装AJAX
function ajax(jsonData){
var xhr = new XMLHttpRequest();
var newData =""; // 存储最终参数格式
if(jsonData.data){
var str = ""; // 存储最终的字符串
var arr = []; // 存储 ""=""的形式
for(var key in jsonData.data){
str = key + "=" + jsonData.data[key]
arr.push(str)
}
newData = arr.join("&") // 最终处理的数据拼接结果
}
// 类型 get|post
if(jsonData.type === "get"){
// get请求
jsonData.url += "?" + newData
xhr.open(jsonData.type,jsonData.url);
xhr.send();
}else if(jsonData.type === "post"){
// post请求
xhr.open(jsonData.type,jsonData.url);
xhr.setRequestHeader('content-type','application/x-www-form-urlencoded');
xhr.send(newData);
}
// 接收服务器返回的数据,监听前后端交互的数据状态
xhr.onreadystatechange = function(){
if(xhr.readyState === 4){
if(xhr.status === 200){
jsonData.success(JSON.parse(xhr.responseText))
}else{
jsonData.error(xhr.statusText)
}
}
}
}10、实现前后端交互的登录与注册功能
登录服务器实现
"查询成功",
"data"=>$data
));
}else{
echo json_encode(array(
"msg"=>"暂无数据"
));
}
}else{
echo "连接数据库失败";
}
?>
登录前端实现
Document
注册服务器实现
"注册成功","code"=>"1001"));
}else{
echo json_encode(array("msg"=>"注册失败","code"=>4001));
}
}else{
echo "连接数据库失败";
}
?>
注册前端实现
Document
用户名:
密码:
邮箱:
11、实现JSONP的跨域解决方案
利用script标签自身的跨域能力,动态创建script标签,让src属性访问网上的资源,后台资源返回的数据一般是函数,前端用函数接收数据。
京东的商品价格接口
12、描述什么情况下会产生跨域
1、在后端没有做跨域处理的情况下,前端部署在 http://127.0.0.1:5500,后端部署在8818,很明显不符合上述讲到的同源情况,端口不相同,所以会触发跨域问题
2、跨域是是因为浏览器的同源策略限制,是浏览器的一种安全机制,服务端之间是不存在跨域的。所谓同源指的是两个页面具有相同的协议、主机和端口,三者有任一不相同即会产生跨域。
ES6
1、利用let命令解决循环中闭包的问题
闭包简单来说,就是函数f内的变量 i 被外部函数s引用到了,而且i不能释放,一直在内存中,形成了闭包
- 1
- 2
- 3
- 4
window.onload = function(){
var lists = document.getElementsByTagName('li');
for(var i = 0 ; i< lists.length;i++){
lists[i].onclick = function(){
console.log(i)//点击时都会打印4
}
}
}let是es6里面的,那它与闭包又有什么关系呢?看一下let如何解决
- 1
- 2
- 3
- 4
由于es6里面是有块级作用域的。
在每次遍历之前就会生成一个块级的作用域,而每个作用域互不干扰
也就是会生成lists.length个这种作用域来分别保存变量i的值,作为局部变量
既然是局部变量,那么 点击第一个li,在执行的时候根据作用域链的规则 访问的肯定是当前作用域里的 i
即:点击第一个li访问到了 第一个作用域(局部) 里的变量,这样看的话,是符合闭包的概念的,当然也是闭包
为什么let可以解决闭包?
var声明的变量,在全局范围内都有效,所以全局只有一个变量i。每一次循环,变量i的值都会发生改变。
let声明的变量,仅在块级作用域内有效,当前的i只在本轮循环有效,所以每一次循环的i其实都是一个新的变量。而JavaScript 引擎内部会记住上一轮循环的值,初始化本轮的变量i时,就在上一轮循环的基础上进行计算。
原文链接:https://blog.csdn.net/weixin_45846805/article/details/106972978
2、利用promise,async,fatch完成对任意接口的数据请求
有些需求,需要同时请求多个接口,等待完多个接口都完成请求后,再进行下一步逻辑处理。这里就需要用到Promise.all()。该方法用于将多个Promise实例,包装成一个新的Promise实例。
例如下面例子的代码:同时请求 getData1 和 getData2,等它们都完成请求后,执行 then() 或 error()。其中,api1 和 api2 是封装好的接口请求的方法。
Promise.all([
this.getData1(),
this.getData2()
]).then((result)=>{
console.log('result: >>', result)
})catch((error) => {
console.log('error: >>', error)
})
async getData1() {
await api1()
},
async getData2() {
await api2()原文链接:https://blog.csdn.net/ljtjianting/article/details/126579540
3、简述Babel的作用?
Babel含义:
Babel 是一个 JavaScript 编译器,它能让开发者在开发过程中,直接使用各类方言(如 TS、Flow、JSX)或新的语法特性,而不需要考虑运行环境,因为 Babel 可以做到按需转换为低版本支持的代码;Babel 内部原理是将 JS 代码转换为 AST,对 AST 应用各种插件进行处理,最终输出编译后的 JS 代码。
Babel是将ES6及以上版本的代码转换为ES5的工具。
它用 babel.config.js 或 .babelrc 文件作为配置文件,其中最为重要的配置参数是presets和plugins。
plugins:Babel插件可以将输入源码进行转换,输出编译后的代码。
presets:一组Babel插件,目的是方便使用。官方已经内置了一些preset,如babel-preset-env。
4、利用Set数据结构实现数组去重?
let arr=[1,2,3,4,5,,4,3,2,1]
const onlyArr=new Set(arr)
console.log(onlyArr) //[1,2,3,4,5]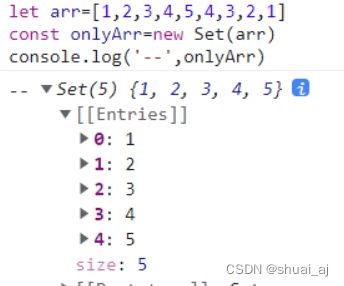
5、利用...扩展运算符实现数组的合并
ES5合并数组的方式之一如下:
var param =['hi',true,666]
var other =[1,2,3].concat(param)
console.log(other)//打印下看看ES6合并数组:
var param =['hi',true,666]
var other =[1,2,3,...param]//展开运算符...
console.log(other)//打印下看看