进阶JAVA篇-深入了解 Set 系列集合
目录
1.0 Set 类的说明
1.1 Set 类的特点
1.2 Set 类的常用API
2.0 HashSet 集合的说明
2.1 从 HashSet 集合的底层原理来解释是如何实现该特性
2.2 HashSet 集合的优缺点
2.3 深入理解 HashSet 集合去重的机制
2.4 如何快速编写已经重写好的 hashCode 和 equals 方法
3.0 TreeSet 集合的说明
1.0 Set 类的说明
Set 类是 Java 中的一个集合类,它实现了 Set 接口。Set 是一个不允许包含重复元素的集合,它是通过哈希表实现的,不保证元素的顺序。
1.1 Set 类的特点
- 不允许包含重复元素:Set 类中的元素是唯一的,如果试图向 Set 中添加重复元素,则添加操作将被忽略。
- 无序性:Set 类中的元素没有固定的顺序,元素的顺序可能发生变化。
- 不可变性:Set 类中的元素是不可变的,即不能修改 Set 中的元素。如果需要修改元素,需要先将元素从 Set 中删除,然后再添加修改后的元素。
- 元素的唯一性:Set 类中的元素是通过 hashCode() 和 equals() 方法来判断是否相等的。如果两个元素的 hashCode 值相等,并且 equals 方法返回 true,则认为这两个元素相等。
1.2 Set 类的常用API
以代码的形式来介绍:
import java.util.HashSet; import java.util.Set; public class Text_Set { public static void main(String[] args) { //由于 Set 类是子接口,故不能直接创建该类的对象, //所以用 Set 类的实现类 HashSet 类来实现该接口的方法 Setset = new HashSet<>(); //1. add(element):向set中添加一个元素。 set.add("张三"); set.add("李四"); set.add("王五"); set.add("张麻子"); System.out.println(set); //输出结果为:[李四, 张三, 王五, 张麻子] //2. remove(element):从set中删除一个元素。 set.remove("张麻子"); System.out.println(set); //输出的结果为:[李四, 张三, 王五] //3. contains(element):判断set中是否包含指定的元素。 boolean b = set.contains("张麻子"); System.out.println(b); //输出的结果为:false //4. size():获取set的大小,即set中元素的个数。 int i = set.size(); System.out.println(i); //输出的结果为: 3 //5. isEmpty():判断set是否为空,即set中是否没有元素。 boolean a = set.isEmpty(); System.out.println(a); //输出结果为:false //6. clear():清空Set,即删除Set中的所有元素。 set.clear(); System.out.println(set); //输出的结果为:[] } } 运行结果如下:
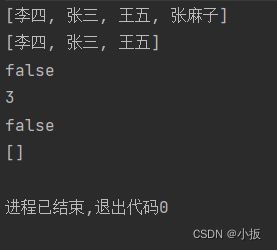
其实这些方法都是 Set 子接口继承了 Collection 父接口的方法,有关 Collection 接口的常用 API 介绍在以下链接:
进阶JAVA篇- Collection 类的常用的API与 Collection 集合的遍历方式-CSDN博客
2.0 HashSet 集合的说明
HashSet 是 Java 中的一个集合类,它实现了 Set 接口。HashSet 基于哈希表实现,不保证元素的顺序,且不允许包含重复元素。简单来说,继承了 Set 的特性:无序、不可重复、无索引。
2.1 从 HashSet 集合的底层原理来解释是如何实现该特性
HashSet 集合是基于哈希表来实现的,又可以简单的认为是基于数组、链表、红黑树来实现的。
补充哈希值的知识点:就是 int 类型的数值,Java 中的每一对象都有一个哈希值,都可以通过调用 Object 类提供的 hashCode() 方法,返回该对象自己的哈希值。
要注意的是:一个相同的对象多次调用 hashCode() 方法返回的哈希值是相同的。对于不同对象调用 hashCode() 方法返回大多数的哈希值是不一致的,但是也有可能会相同(哈希碰撞)。
JDK8之前 HashSet 集合的底层原理:
Setset = new HashSet<>(); 首先,在执行以上代码的时候,底层会创建一个默认为16的数组,默认加载因子为0.75,数组名为table .
set.add("张三");然后,在执行到以上代码的时候,使用该字符串对象的哈希值对长度求余计算出相应存入的位置。比如这个对象的哈希值为 3%16 == 3,应该会放到数组下标为3的数组内存中,因此在这里我们就可以解释了 HashSet() 类的无序性,并不是按添加元素的前后顺序而放到数组内存中的。
在此之前并不着急存入,先要判断当前的位置是否为 null ,如果是 null 直接回存入,如果不是 null,表示有元素,则回调用 equals 方法来比较相等,则不存;不相等,则存入到数组中。因此在这里我们就可以解释了 HashSet() 类的不可重复性。
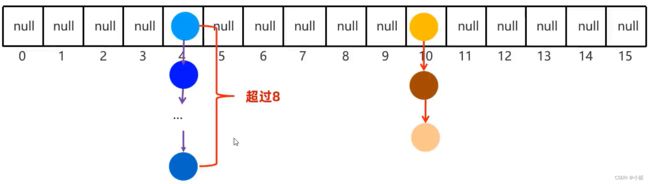
如果数组快占满的时候,链表会过长,导致查询性能下降,这时候就会扩容,如果元素增加超过当前数组长度 * 默认加载因子,即 16 * 0.75 == 12 ,超过12是,就会自动扩容。
从JDK8开始,如果链表长度超过8,且数组长度 >= 64时,会自动将链表转变为红黑树。

2.2 HashSet 集合的优缺点
HashSet 集合基于这种哈希表的数据结构,查询、增加、删除、修改元素速度都很快,性能很高。
2.3 深入理解 HashSet 集合去重的机制
由于 HashSet 集合默认不能对内容相同的不同对象去重。
代码如下:
import java.util.HashSet; import java.util.Set; public class Text_Set { public static void main(String[] args) { Student s1 = new Student("张三",19); Student s2 = new Student("张三",19); SetstudentSet = new HashSet<>(); studentSet.add(s1); studentSet.add(s2); System.out.println(studentSet); } } 运行结果如下:
内容相同的两个不同对象。

HashSet 中的元素是通过 hashCode 和 equals 方法来判断是否相等的。如果两个元素的hashCode 值相等,并且 equals 方法返回 true,则认为这两个元素相等。
具体的解决办法就是将两个内容相同的不同对象改为相同的哈希值。需要重写两个方法,hashCode 和 equals 方法 。
完整代码如下:
Student 类:
import java.util.Objects; public class Student { private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, age); } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } }import java.util.HashSet; import java.util.Set; public class Text_Set { public static void main(String[] args) { Student s1 = new Student("张三",19); Student s2 = new Student("张三",19); SetstudentSet = new HashSet<>(); studentSet.add(s1); studentSet.add(s2); System.out.println(studentSet); } } 运行结果如下:

2.4 如何快速编写已经重写好的 hashCode 和 equals 方法
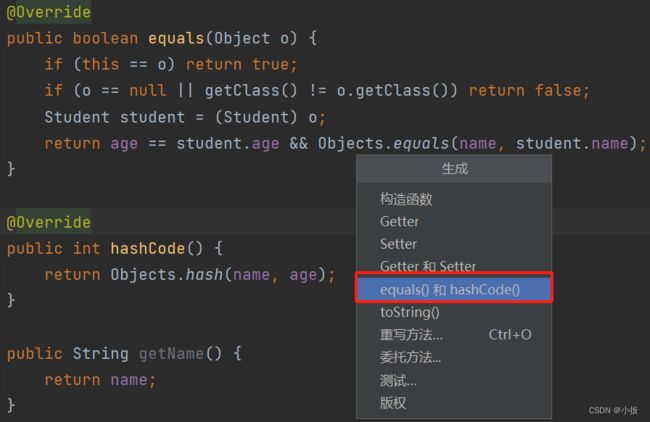
在 IDEA 中已经帮我们写好了这些方法。在该类中点击右键,选择点击”生成“,最后选择重写这两个方法即可。

3.0 TreeSet 集合的说明
TreeSet 是 Java 中的一个集合类,它实现了 Set 接口,是一个有序的集合。TreeSet 底层是通过红黑树来实现的,可以保证元素的有序性。其特性是有序(升序)、不可重复、无索引。
对于自定的类型如 Student 类型,TreeSet 默认是不能排序的。
- Comparable接口: Comparable 接口是 Java 提供的一个用于比较对象的接口,它定义了一个 compareTo 方法,用于比较当前对象和另一个对象的大小关系。如果一个类实现了Comparable 接口,就表示该类的对象是可比较的,可以用于排序。
- Comparator 接口: Comparator 接口是 Java 提供的一个用于比较对象的接口,它定义了一个 compare 方法,用于比较两个对象的大小关系。与 Comparable 接口不同的是,Comparator 接口可以在排序时动态地指定比较规则,而不需要修改被比较的类。
具体解决代码如下:
方法一:
Student 类
public class Student implements Comparable{ private String name; private int age; public Student() { } public Student(String name, int age) { this.name = name; this.age = age; } @Override public int compareTo(Student o) { return this.age - o.age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + '}'; } } import java.util.Set; import java.util.TreeSet; public class Text_TreeSet { public static void main(String[] args) { Student s1 = new Student("张三",19); Student s2 = new Student("李四",33); Student s3 = new Student("王五",21); SetstudentSet = new TreeSet<>(); studentSet.add(s1); studentSet.add(s2); studentSet.add(s3); System.out.println(studentSet); } } 运行结果如下:

方法二:(为了区分前面的方法,按降序的方法来排序)
import java.util.Comparator; import java.util.Set; import java.util.TreeSet; public class Text_TreeSet { public static void main(String[] args) { Student s1 = new Student("张三",19); Student s2 = new Student("李四",33); Student s3 = new Student("王五",21); SetstudentSet = new TreeSet<>(new Comparator () { @Override public int compare(Student o1, Student o2) { return o2.getAge()-o1.getAge(); } }); studentSet.add(s1); studentSet.add(s2); studentSet.add(s3); System.out.println(studentSet); } }
