flink源码解析
一、启动流程解析
flink的启动从命令行提交开始:
[yooh@hadoop101 bin]$ pwd
/home/yooh/app/flink-1.11.1/bin
[yooh@hadoop101 bin]$ cat flink
...上边都是获取环境配置相关信息
# get flink config
. "$bin"/config.sh
.....最后调用 java类
exec $JAVA_RUN $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"在flink脚本中读取环境配置相关信息使用 exec 命令调用程序入口类 org.apache.flink.client.cli.CliFrontend 类,然后在该类的main方法中先获取flink的conf目录位置信息,然后根据conf目录位置加载配置,接着将flink提交时候的命令行参数封装成一个 CommandLine 对象(按顺序依次添加 Generic、Yarn、Default到一个list里面 ,后边根据其boolean属性 isActive 是否活跃来依次匹配,活跃的话即可匹配的上,否则匹配不上),然后创建该类 CliFrontend 实例,根据不同的参数动作(比如 run cancel等等,我们这里以run为例),然后调用run方法,将默认参数配置和我们自己传进来的参数配置进行合并,然后根据之前封装的 CommandLine 对象中添加的客户端类型(Generic、Yarn、Default,我们这里以yarn为例)根据 isActive 进行判断,然后获取用户的jar包以及相关依赖,将配置封装成一个 Configuration 对象(里面会设置 yarn HA的id、Target(session、per-job)、JobManager内存、TaskManager内存、每个TM的slot数等等),然后调用 CliFrontend.executeProgram 实际调用-----> ClientUtils.executeProgram,然后在这个方法里面设置
1、当前线程的类加载器为我们flink代码的主类
2、配置环境的上下文,用户代码里的 val env = StreamExecutionEnvironment.getExecutionEnvironment() 就会拿到这些环境信息,
3、通过反射 调用我们的flink代码中的 main 方法
然后接下来都是我们代码中定义的一些处理逻辑,比如map......
跟Spark一样,Flink也是懒执行,用户逻辑代码会在Flink封装并执行完所有流程图后才开始运行,在调用 env.execute() 的时候才真正开始执行我们写的代码 ,然后获取到 StreamGraph 作业图(如何生成的??),如果是向yarn上提交程序的话会获取 yarn 的执行器,即调用 env.execute() --->实际调用的是 AbstractJobClusterExecutor.execute,在这个方法里:
1、将 流图(StreamGraph) 转换成 作业图(JobGraph),如何转换的???
2、然后创建、初始化并启动yarn的客户端 YarnClient, 包含了一些yarn、flink的配置和环境信息,返回一个集群描述器 ClusterDescriptor接口 ,如果是yarn的话就是 YarnClusterDescriptor
3、创建集群特有资源配置对象 ClusterSpecification :在这里比如设置JobManager内存、TaskManager内存、每个Tm的slot数等等
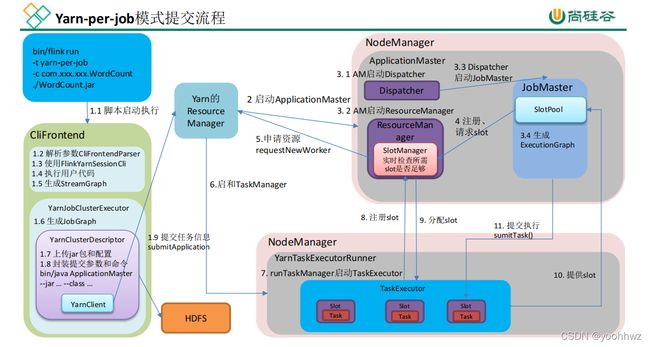
然后通过yarn的 集群描述器 YarnClusterDescriptor调用其 deployJobCluster方法,最终调用的是 YarnClusterDescriptor.deployInternal,在这个方法里面会做一个前置检查(比如flink jar包,conf路径是否为空,检查指定的队列是否存在,然后yarn的资源是否足够等等),然后开始启动 yarn的 applicationMaster,上传用户jar包、flink的依赖、flink的配置文件以及其他相关环境到hdfs上,然后使用 yarnClient.submitApplication 向yarn上提交flink应用。
后边向yarn上提交应用的详细过程没有写。。。可以直接看总结
总结: 用户通过flink命令行提交应用,实际上是执行的CliFrontend java类,然后会解析用户的命令行参数,封装为 CommandLine 对象,然后调用executeProgram方法,在该方法里面通过反射(invoke调用我们的flink代码中的main方法)调用执行我们flink代码,然后真正执行是通过我们代码中的env.execute()会生成StreamGraph, 然后如果是向yarn提交的话调用yarn相关的执行器(AbstractJobClusterExecutor)的execute方法将StreamGraph转化为JobGraph,然后创建一个yarn的集群描述器(YarnClusterDescriptor ),上传flink jar包和一些配置到hdfs上,然后封装启动ApplicationMaster所需的相关环境信息等,使用yarn的客户端(yarnClient)向yarn的ResourceManager通过submitApplication()方法提交应用,然后启动applicationMaster,applicationMaster启动之后会启动flink的Dispatcher和flink的ResourceManager
Dispatcher启动之后Dispatcher会去启动JobMaster,启动JobMaster的时候会启动SlotPool,这个才是真正请求注册资源的角色,启动JobMaster的同时会生成ExecutionGraph
ResourceManager启动之后里面真正做资源操作的是SlotManager角色
都启动成功后JobMaster中的SlotPool会向flink 的ResourceManager中SlotManager请求注册Slot,SlotManager会向yarn的ResourceManager去申请资源,然后yarn的ResourceManager在对应的NodeManager中启动TaskManager,然后启动TaskExecutor,当TaskExecutor收到slot资源后会向slotManager中进行注册,由slotManager进行slot的分配,分配之后,TaskExecutor会告知SlotPool资源,然后由JobMaster通过submitTask()方法提交任务到TaskExecutor上边进行执行。
二、组件通信
RPC(Remote Procedure Call)远程过程调用协议,简单的理解是一个节点请求另一个节点提供的服务,RPC的具体实现框架为Akka和Netty。
Flink 内部节点之间的通信是用 Akka,比如 JobManager 和 TaskManager 之间的通信。而 operator算子 之间的数据传输是利用 Netty。使用 Akka,所有远程过程调用现在都实现为异步消息。
三、flink任务调度