深入mysql底层索引底层数据与算法
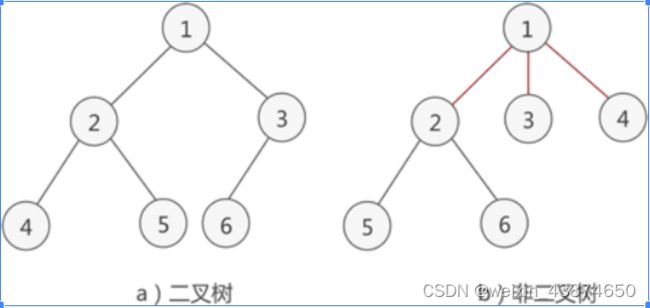
二叉树:
1. 本身是有序树;
2. 树中包含的各个节点的度不能超过 2,即只能是 0、1 或者 2;
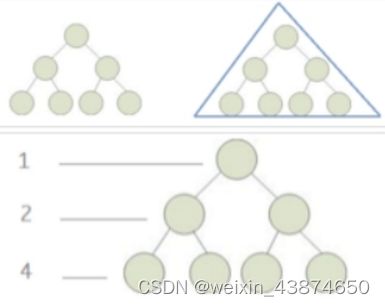
满二叉树:
如果二叉树中除了叶子结点,每个结点的度都为 2,则此二叉树称为满二叉树。
1. 满二叉树中第 i 层的节点数为 2n-1 个。
2. 深度为 k 的满二叉树必有 2k-1 个节点 ,叶子数为 2k-1。
3. 满二叉树中不存在度为 1 的节点,每一个分支点中都两棵深度相同的子树,且叶子节点都在最底层。
4. 具有 n 个节点的满二叉树的深度为 log2(n+1)。
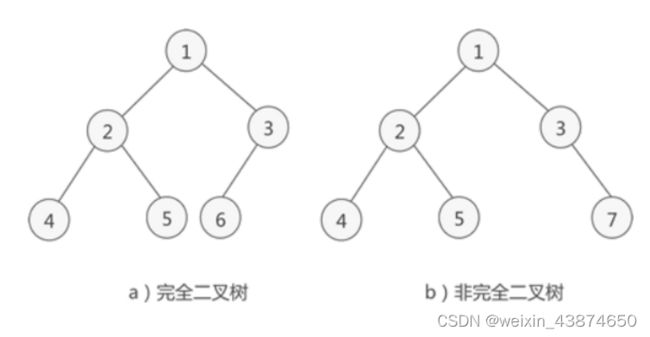
完全二叉树:
如果二叉树中除去最后一层节点为满二叉树,且最后一层的结点依次从左到右分布,则此二叉树被称为完全二叉树。
1.所有叶子节点都出现在 k 或者 k-1 层,而且从 1 到 k-1 层必须达到最大节点数;
2.第 k 层可以不是满的,但是第 k 层的所有节点必须集中在最左边。
需要注意的是不要把完全二叉树和“满二叉树”搞混了,完全二叉树不要求所有树都有左右子树,但它要求:
3.任何一个节点不能只有左子树没有右子树
4.叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
索引:是帮助mysql高效获取数据的排好序的数据结构
索引的数据结构:二叉树,红黑树,hash表,b-tree
二叉树的特点:右节点的元素比父元素大,左节点的元素比父元素小。
红黑树的特点:若右节点元素比父元素大很多,并且红黑树会自动平衡树结构,使之不会出现单边树结构,缺点是可能会出现树的高度很高。
B-tree的特点(没有冗余索引):
1. 叶节点具有相同的深度,叶节点的指针为空。
2. 所有索引元素不重复
3. 节点中的数据索引从左到右递增排列
B+tree(是B-tree的变种)的特点:
1. 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
2. 叶子节点包含所有的索引字段
3. 叶子节点用指针连接,提高区间之间的访问性能
Mysql磁盘是16kb,mysql底层用的是B+tree数据结构。
Show global status ‘innodb_page_size’ // 查询mysql数据库的叶节点大小是16kb;16*1024/(8b+6b)=1170个索引,若一个叶子节点可以存1kb的数据,b+tree树的高度为3,可以存2000多万的数据;而b-tree高度为3则只能存1170*16*16=200万左右的数据
B-tree与B+tree的区别:
1.B-tree结构中的非叶子节点中的data数据移到B+tree中叶子节点中
2.B-tree叶子节点是没有用指针连接的,B+tree叶子节点是用指针连接的
Myisam(对应三个文件):
.frm文件表示使用的结构框架,.MYD文件表示存储的具体数据,.MYI文件表示存储的索引
INNODB(对应两个文件):
.frm文件表示使用的结构框架,.idb存放索引和整张表的数据
非聚集索引:表示索引与数据是分开存储的。
复合索引就是联合索引
Mysql表中有Myisam和InnoDB两种存储格式:
Myisam索引文件和数据文件是分离的(非聚集索引)。
InnoDB索引实现(聚集):
1. 表数据文件本身就是按B+tree组织的一个索引结构文件
2. 聚集索引-叶节点包含了完整的数据记录
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
A. 如果不建立一个主键,那么mysql会自动帮你任意选择一列不相等的数据作为主键(或者隐形的)
B. 如果不是用的自增的话,那么在添加数据时,容易造成新的数据的同时也会增加一个冗余索引,还要做一次平衡,造成性能降低;如果用了自增就不会轻易频繁的新增冗余索引和做平衡了
另外自增涉及到排序
C. 如果不使用整形,如使用了uuid成生的id,那么会进行ASCII表对比找数据,比较花时间。
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
一致性则是表示,在叶子节点存储的数据是主键的值。
二级索引也是非聚集索引,只有主键才有可能是聚集索引
Hash数据结构存储特点:
1. 对索引的key进行一次hash计算就可以定位出数据存储的位置
2. 很多时候Hash索引要比B+tree索引更高效
3. 仅能满足“=”,“IN”,但不支持范围查询
4. Hash冲突
联合索引的底层存储结构长什么样?
联合主键索引特点:最左列原理 (name,age,position)