SystemVerilog学习——数据类型
SystemVerilog学习——数据类型
- 1. 内建数据类型
-
- 1.1 逻辑数值类型
- 1.2 符号类型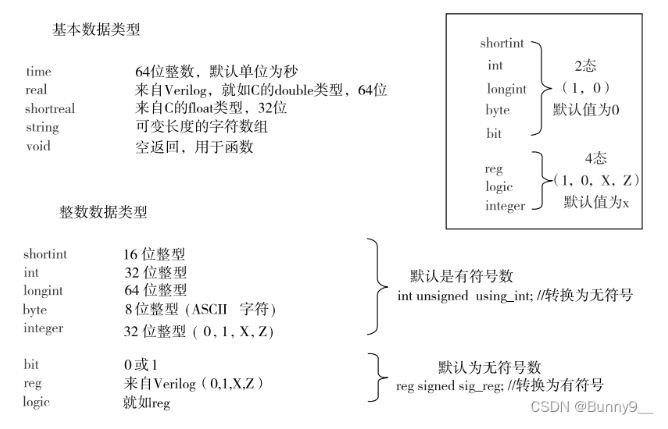
- 1.3 类型转换
- 1.4 补充
- 2. 定宽数组
-
- 2.1 数组声明和初始化
- 2.2 基本数组操作 for 和 foreach循环
- 2.3 基本数组操作 ————复制和比较
- 2.4 动态数组
- 2.5 关联数组
- 2.6 队列
- 2.7 结构体
- 2.8 枚举类型
- 2.9 字符串
- 2.10 结构体和联合体
- 3. 过程块和方法
-
- 3.1 硬件过程块
-
- 3.1.1 initial 和 always
- 3.1.2 initial 和 always 两之间的区别
- 3.2 函数 function
- 3.3 任务 task
- 3.4 软件方法——变量生命周期
1. 内建数据类型
重点:(1)逻辑数值类型 (2)符号类型 (3)矢量位宽
1.1 逻辑数值类型
相比于Verilog将寄存器(register)类型reg和线网(net)类型例如wire区分地如此清楚,在SV中新引入了一个数据类型logic。它们的区分和联系在于:
(1)Verilog作为硬件描述语言,要考虑变量是寄存器,还是线网类型。
(2)SV作为侧重于验证的语言,只会作为单纯的变量进行赋值操作,而这些变量也只属于软件环境构建。
(3) logic为了方便验证人员驱动和连接硬件模块、而省去考虑究竟该使用reg还是wire的精力。这既节省了时间,也避免了出错的可能。
与logic相对应的是bit类型,它们均可以构建矢量类型(vector) ,而它们的区别在于:
(1)logic为四值逻辑,即可以表示0、1、X、Z。
(2)bit为二值逻辑,只可以表示0和1。
问题: SV为什么在已经有了四值逻辑的基础上还要再引入二值逻辑呢?
这是因为,SV在一开始设计的时候,就期望将硬件的世界与软件的世界分离开。在这里,硬件的世界指的就是硬件设计,所以四值逻辑属于那里,而软件的世界即验证环境,更多的是二值逻辑。
1.2 符号类型
按四值逻辑的类型和二值逻辑的类型划分:
四值逻辑类型:integer、logic、reg、net-type(例如wire、tri)
二值逻辑类型:byte、shortint、int、longint、bit
| 四值逻辑 | 二值逻辑 |
|---|---|
| integer | byte |
| logic | shortint |
| reg | int |
| net-type(例如wire、tri) | longint |
| - | bit |
按有无符号的类型划分:
有符号类型:byte、shortint、int、longint、integer
无符号类型:bit、logic、reg、net-type(例如wire、tri)
| 有符号类型 | 无符号类型 |
|---|---|
| byte | bit |
| shortint | logic |
| int | reg |
| longint | net-type(例如wire、tri) |
| integer | - |
例题1:先看是否有无符号,有符号最高位表示负

1.3 类型转换
例题2:有无符号位转换

- 通过上面的例子我们可以发现,在编码时一定要注意操作符左右两侧的符号类型是否一致,如果不一致,应该首先将其转换为同一类型再进行运算。
- 对于转换方式,我们已经上面已经展示了一种转换方式----静态转换,即需要在转换的表达式前加上单引号即可,而该方式并不会对转换值做检查。如果发生转换失败,我们也无从得知,所以与之对应的动态转换
$cast(tgt, src)也被经常运用到转换操作中。 - 静态转换和动态转换均需要操作符号或者系统函数介入,我们统称为显式转换。
- 而不需要进行转换的一些操作,我们称之为隐式转换。
例题3:有无符号位转换

1.4 补充
Verilog并没有严格区分信号的类型,变量和线网类型均是四值逻辑;
SV中将硬件信号区分为“类型”和数据类型;类型即表示该信号为变量(variables)或者线网类型(nets)。
对于线网类型赋值只能使用连续赋值语句(assign),对于变量类型赋值可以使用连续赋值、或者过程赋值;
数据类型则表示数据是四值逻辑(logic)还是二值逻辑(bit);
出个题:下面对于Verilog和SV数据类型赋值说法正确的有哪些:
A. Verilog中的变量类型只能使用过程赋值
B. Verilog中的线网类型只能使用连续赋值
C. SV中的变量类型只能使用过程赋值
D. SV中的线网类型只能使用连续赋值
SV中的assign连续赋值可以赋值给logic(var)类型吗?
在SV中,数据类型可以分为线网(net)和变量(variables)。线网的赋值设定,与Verilog的要求相同,即线网赋值只能使用连续赋值语句(assign),而不能出现在过程块(initial / always);相比于线网驱动的限制,变量(var)类型的驱动要求就没那么多了,例如 logic[3:0] a,该变量默认类型是var(变量),对它可以使用连续赋值、或者过程赋值;
避坑:可以在tb中大量使用logic类型变量,而很少使用wire。什么时候需要wire?多于一个驱动源的时候,或者设计模块端口是双向(inout)的时候;
2. 定宽数组
2.1 数组声明和初始化
(1)数组声明
int lo_hi [ 0:15]; // 16 ints [ 0]..[15]
int c_style [16]; // 16 ints [ 0]..[15]
(2)多维数组声明和使用
int array2 [ 0: 7][ 0: 3]; // 完整声明
int array3 [8][4]; // 紧凑声明
array2[7][3] = 1; // 设置最后一个元素
(3)初始化和赋值
int ascend[4] = '{0, 1, 2, 3}; // 对4个元素初始化
int descend[5];
descend = '{4, 3, 2, 1, 0}; // 为5个元素赋值
descend[0:2] = '{5, 6, 7}; // 为前三个元素赋值
sacend = '{4{8}}; // 4个值全部为8
descend = '{0:9, 1:8, default:-1}; // {9, 8, -1, -1, -1}
(4)存储空间考量

例题

1字(word)= 4字节(byte)=32(bit)
logic是四值类型,24bit,每个bit需要2个位来存储,所以需要48位,连续存储所以需要2个word。
非合并型pack,3 * 8 * 2位 所以需要 3个word
2.2 基本数组操作 for 和 foreach循环
initial begin
bit [31: 0] src[5], dst[5];
for (int i = 0; i < $size(src); i++)
src[i] = i;
foreach (dst[j])
dst[j] = src[j]*2; // dst doubles src values
end
$size(src) 用的是系统函数,数组大小。
2.3 基本数组操作 ————复制和比较
对于赋值,可以利用赋值符号“ = ”直接进行数组的复制;
对于比较,在不适用循环的情况下,也可以利用” == “或者” != “来比较数组的内容,不过结果仅限于内容相同或者不同;
bit [31: 0] src[5] = '{0, 1, 2, 3, 4},
dst[5] = '{5, 4, 3, 2, 1};
if (src == dst) // 比较数组
$display ("src == dst");
else
$display ("src != dst");
dst = src; // 数组复制
src[0] = 5; // 修改数组中的一个元素
2.4 动态数组
(1)定宽数组类型的宽度在编译时就确定了,但如果像在程序运行时再确定数组的宽度就需要使用【动态数组】了。
(2)动态数组最大的特点即是可以在仿真运行时灵活调节数组的大小即存储量。
(3)动态数字在一开始声明时,需要利用’[ ]'来声明,而数组此时是空的,即0容量。其后,需要使用’new[ ]'来分配空间,在方括号中传递数组的宽度。
(4)此外,也可以在调用new[ ]时将数组名也一并传递,将已有数组的值复制到新数组中。
data_type时数组成员的数据类型,动态数组与静态数组支持相同的数据类型。空的“[ ]”意味着我们不需要在编译的时候指定数组的大小,在运行的过程中可以动态分配。动态数组初始化时是空的,没有分配空间,使用前必须通过调用new[ ],并在“[ ]”中输入期望的长度数值来分配空间。
int dyn[], d2[]; // 声明动态数组
initial begin
dyn = new[5]; // 分配5个元素
foreach (dyn[j]) dyn[j] = j; // 动态数组初始化
d2 = dyn; // 复制一个动态数组
d2[0] = 5; // 修改复制值
$display (dyn[0], d2[0]); // 显示数值0和数值5
dyn = new[20](dyn); // 分配20个数值并进行复制,{0, 1, 2, 3, 4, 0, 0, ..., 0};
dyn = new[100]; // 重新分配100个数值,而旧值不复存在,{0, 0, ..., 0};
dyn.delete(); // 删除所有元素
// dyn = new[0];
// dyn = '{};
end
例题1

第三句,把空间都释放掉了。
2.5 关联数组
(1)如果你只是偶尔需要创建一个大容量的数组,那么动态数组就足够了,但是如果你需要一个超大容量的呢?动态数组的限制在于其存储空间在一开始创建时即被固定下来,那么对于超大容量的数组这种方式无疑存在着浪费,因为很有可能该大容量的数组中有相当多的数据不会被存储和访问。

(2)【关联数组】可以用来保存稀疏矩阵的元素。当你对一个非常大的地址空间寻址时,该数组只为实际写入的元素分配空间,这种实现方法所需要的空间比定宽或动态数组所占用的空间要小得多。
(3)此外,关联数组有其它灵活的应用,在其它软件语言也有类似的数据存储结构,被称乏为哈希(Hash)或者词典(Dictionary),可以灵活赋予键值(key)和数值(value) 。
相关数组的声明、初始化、和使用

2.6 队列
(1)【队列】结合了链表和数组的优点,可以在它的任何地方添加或删除元素,并且通过索引实现对任一元素的访问。
(2)队列的声明是使用带有美元符号的下标:[ $],队列元素的标号从0到 $。
(3)队列不需要new [ ]去创建空间,你只需要使用队列的方法为其增减元素,一开始其空间为0。
(4)队列的一个简单使用即是通过其自带方法push_back ( )和pop_front( )的结合来实现FIFO的用法。

SV提供下面几种预定义的方法来访问和操作队列,
- function int size ( ):返回队列中成员的数目。如果队列空,返回0;
- function void insert (int index, queue_type item):在指定的索引位置插入指定的成员;
Q.insert(i, e)等效于Q= {Q[0:i-1], e, Q[i, $]}; - function void delete (int index):删除指定索引位置的成员;
Q.delete(i)等效于Q = {Q[0:i-1], Q[i+1, $]}; - function queue_type pop_front ( ):删除并返回队列的第一个成员;
e = Q.pop_front( )等效于e = Q[0], Q = Q[1, $]; - function queue_type pop_back ( ):删除并返回队列的最后一个成员;
e = Q.pop_back ( )等效于e = Q[$], Q = Q[0, $-1]; - function void push_front (queue_type item):在队列的前端插入指定的成员;
Q.push_front(e)等效于Q = [e, Q]; - function void push_back (queue_type item):在队列的尾部插入指定的成员;
Q.push_back(e)等效于Q = [Q, e];
上面的方法可以用来建模堆栈、FIFO、队列
2.7 结构体
(1) verilog的最大缺陷之一是没有数据结构,在sV中可以使用struct语句创建结构,跟c语言类似。
(2)不过struct的功能少,它只是一个数据的集合,其通常的使用的方式是将若干相关的变量组合到一个struct结构定义中。
(3)伴随typedef可以用来创建新的类型,并利用新类型来声明更多变量。

2.8 枚举类型
(1)规范的操作码和指令例如ADD、WRITE、IDLE等有利于代码的编写和维护,它比直接使用h01这样的常量使用起来可读性和可维护性更好。
(2)枚举类型enum经常和typedef搭配使用,由此便于用户自定义枚举类型的共享使用。
(3)枚举类型的出现保证了一些非期望值的出现,降低的设计风险。

2.9 字符串
(1)感谢字符串string的出现,让我们可以脱离VHDL和verilog这种"荒蛮时代”,可以完整想用string类型带来的便利(尽管它与其它软件语言的字符串功能使用仍然有差距)。
(2)所有与字符串相关的处理,都请使用string来保存和处理。
(3)与字符串处理相关的还包括字符串的格式化函数即如何形成一个你想要的字符串句子呢?可以使用sv系统方法$sformatf (),如果你只需要将它打印输出,那么就使用$display ()吧。

// string_test
module string_test ;
string s; // "xxxx",最后没有"\0"
initial begin
s = "IEEE ";
$display (s.getc(0)); // 显示“I”
$display (s.tolower()); // 显示ieee
s.putc(s.len()-1, "-"); // 将空格变为“-”
s = {s, "P1800"}; // 字符串拼接,"IEEE-P1800"
$display (s.substr(2, 5)); // 显示EE-P
// 创建一个临时字符串并将其打印
my_log ($sformatf("%s %5d", s, 42));
end
task my_log (string message); // 打印消息
$display ("@%0t: %s", $time, message);
endtask
endmodule
2.10 结构体和联合体
Verilog的最大缺陷之一就是没有数据结构,在SV中可以使用struct语句创建结构,跟c语言类似;
不过struct的功能少,它只是一个数据的集合,其通常的使用的方式是将若干相关的变量组合到一个struct的结构定义中;
伴随typedef可以来创建新的类型,并利用新类型类声明更多变量;
struct { bit [7:0] r, g, b;} pixel; // 创建一个pixel结构体
// 为了共享该类型,通过typedef来创建新类型
typedef sturct {bit [7:0] r, g, b;} pixel_s;
pixel_s my_pixel; // 声明变量
my_pixel = '{'h10, 'h10, 'h10}; // 结构体类型赋值
结构体的成员被连续的存储,而联合体的所有成员共享用统一片存储空间,也就是联合体中最大成员的空间。
结构体和联合体的声明遵从C语言的语法,但在“{”之前没有可选的结构体标识符。如下,
// eg1:
struct {
bit [ 7: 0] opcode;
bit [23: 0] addr;
}IR; // 未命名结构体,定义结构体变量IR
IR.opcode = 1; // 对IR的成员opcode赋值
// eg2:
typedef struct {
bit [ 7: 0] opcode;
bit [23: 0] addr;
}instruction; // 命名为instruction的结构体类型
instruction IR; // 定义结构体变量
// eg3:
tyoedef union {
int i;
shortreal f;
}num; // 命名为num的联合体类型
num n;
n.f = 0.0; // 以浮点数合适设置n
一个结构体可以作为一个整体赋值,并且可以作为一个整体作为接口参数在一个函数或任务中传递。
// struct_example
module test_struct ( );
struct {
bit [ 7: 0] my_byte;
int my_data;
real pi;
}my_struct;
initial begin
my_struct.my_byte = 8'hab;
$display ("my_byte = %h, my_data = %2d, pi = %f", my_struct.my_byte, my_struct.my_data, my_struct.pi);
my_struct = '{0, 99, 3.14};
$display ("my_byte = %h, my_data = %2d, pi = %f", my_struct.my_byte, my_struct.my_data, my_struct.pi);
end
endmodule

3. 过程块和方法
3.1 硬件过程块
3.1.1 initial 和 always
(1)在SV中同学们首先需要清楚哪些语句应该被放置于硬件世界,哪些程序应该被放置于软件世界。
(2)怎么来区分硬件世界和软件世界呢?我们先引申出一个概念域( scope)。为了区分硬件设计、软件世界,我们将定义的软件变量或者例化的硬件其所在的空间称之为域。
(3)因此,module/endmodule,interface/endinterface可以被视为硬件世界,program/endprogram和class/endclass可以被视为软件世界。掌握了这一清晰的概念,有助于我们接下来分析initial和always的使用域。
(4)always是为了描述硬件的行为,而在使用时需要注意哪种使用方式是时序电路描述,哪种使用方式是组合电路描述。
(5)always中的@(event…)敏感列表是为了模拟硬件信号的触发行为,同学们需要正确对标硬件行为和always过程块描述。需要理解硬件行为的核心要素有哪些?
(6)所以说,always过程块是用来描述硬件时序电路和组合电路的正确打开方式,因此只可以在module或者interface中使用。
例题
哪些是正确使用always的方式:
(1)由时钟驱动
(2)由其它非时钟信号驱动
(3)不同always语句块之间是并行执行的
3.1.2 initial 和 always 两之间的区别
(1)initial从名字也可以看得出来,与always在执行路径上有明显区别,即initial非常符合软件的执行方式,即只执行一次。
(2)initial和always一样,无法被延迟执行,即在仿真一开始它们都会同时执行,而不同initial和always之间在执行顺序上是没有顺序可言的,因此小白们不应该将它们在代码中的**前后顺序与它们的执行顺序(无关)**画上等号。
(3)initial从其执行路径的属性来看,它不应该存在于硬件设计代码中,它本身不可综合,对于描述电路没有任何帮助。
initial就是为了测试而生的,由于测试需要按照时间顺序的习惯即软件方式来完成,所以initial便可以实现这一要求。
(4)在Verilog时代,所有的测试语句都可以被放置在initial中,为了便于统一管理测试顺序,建议将有关测试语句都放置在同一个initial过程块中。
(5)initial过程块可以在module、interface和program中使用。。对于过程块的书写方式,请记住用begin…end将其作用域’包’住,这一建议同样适用于稍后提到的控制语句、循环语句等等,初学者可以将其对应于C语言中的花括号{ },方便记忆。
3.2 函数 function
SV函数定义同C语言非常类似
(1)可以在参数列表中指定输入参数( input)、输出参数(output)、输入输出参数(inout)或者引用参数(ref)。
(2) 可以返回数值或者不返回数值(void)。

除此之外,function还有以下的属性:
(1) 默认的数据类型是为logic,例如input [7:0] addr。
(2)数组可以作为形式参数传递。
(3) function可以返回或者不返回结果,如果返回即需要用关键词return,如果不返回则应该在声明function时采用void function()。
(4)只有数据变量可以在形式参数列表中被声明为ref类型,而线网类型则不能被声明为ref类型。
(5)在使用ref时,有时候为了保护数据对象只被读取不被写入,可以通过const的方式来限定ref声明的参数。
(6)在声明参数时,可以给入默认数值,例如 input [7:0] addr = 0,同时在调用时如果省略该参数的传递,那么默认值即会被传递给
function。
3.3 任务 task
任务相比于函数要更加灵活,且以下不同点:
(1) task无法通过return返回结果,因此只能通过output、inout或者ref的参数来返回。
(2)task内可以置入耗时语句,而function则不能。常见的耗时语句包括@event、wait event、# delay等。
task mytask1 (output logic [31:0] x,input logic y);
......
endtask
通过上面的比较,我们对function和task建议的使用方式是:
(1)对于初学者,傻瓜式用法即全部采用task来定义方法,因为它可以内置常用的耗时语句。
(2)对于有经验的使用者,请今后对这两种方法类型加以区别,在非耗时方法定义时使用function,在内置耗时语句时使用task。这么做的好处是在遇到了这两种方法定义时,就可以知道function只能运用于纯粹的数字或者逻辑运算,而task则可能会被运用于需要耗时的信号采样或者驱动场景。
(3)如果要调用function,则使用function和task均可对其调用;而如果要调用task,我们建议使用task来调用,这是因为如果被调用的task内置有耗时语句,则外部调用它的方法类型必须为task。
typedef struct {
bit [ 1:0] cmd ;
bit [ 7:0] addr;
bit [31: 0] data;
}trans;
function automatic void op_copy(trans t, trans s);
t = s;
endfunction
3.4 软件方法——变量生命周期
(1)在SV中,我们将数据的生命周期分为动态(automatic)和静态(static) 。
(2)局部变量的生命周期同其所在域共存亡,例如function/task中的临时变量,在其方法调用结束后,临时变量的生命也将终结,所以它们是动态生命周期。
(3)全局变量即伴随着程序执行开始到结束一直存在,例如module中的变量默认情况下全部为全局变量,用户也可理解为module中的变量由于在模拟硬件信号,所以它们是静态生命周期。
(4)如果数据变量被声明为automatic,那么在进入该进程/方法后,automatic变量会被创建,而在离开该进程/方法后,automatic变量会被销毁。而static变量在仿真开始时即会被创建,而在进程/方法执行过程中,自身不会被销毁,且可以被多个进程和方法所共享。
------------------------------------------------------
function automatic int auto_cnt (input a);
int cnt = 0;
cnt += a;
return cnt;
endfunction
------------------------------------------------------
function static int static_cnt (input a) ;
static int cnt = 0 ;
cnt +=a;
return cnt;
endfunction
------------------------------------------------------
function int def_cnt (input a) ;
static int cnt = 0;
cnt += a;
return cnt;
endfunction
------------------------------------------------------
// 结果:
initial begin
$display ("@1 auto_cnt = %0d",auto__cnt (1)) ;
$display ("R2 auto_cnt = SOd",auto_cnt (1) ) ;
$display ("e1 static_cnt = 老Od",static_cnt ( 1 ) );
$display ("R2 static_cnt = %0d", static_ent (1) ) ;
$display ("e1 def_cnt = %0d",def_cnt (1) ) ;
$display ( "@2 def_cnt = 50d", def_cnt (1)) ;
end
输出结果:
#@1 auto_cnt = 1
#@2 auto_cnt = 1
#@1 static_cnt = 1
#@2 static_cnt = 2
#@1 def_cnt = 1
#@2 def_cnt = 2
(1)上面的三个function被定义在了module内,分别被声明为了automatic、static和默认类型。
(2)对于automatic方法,其内部的所有变量默认也是automatic,即伴随automatic方法的生命周期建立和销毁。
(3)对于static方法,其内部的所有变量默认也是static类型。
(4)对于automatic或者static方法,用户可以对其内部定义的变量做单个声明,使其类型被显式声明为automatic或者static。
(5)对于static变量,用户在声明变量时应该同时对其做初始化,而初始化只会伴随它的生命周期发生一次,并不会随着方法调用被多次初始化。
