有没有什么可以节省大量时间的 Deep Learning 效率神器?
链接:https://www.zhihu.com/question/384519338
编辑:深度学习与计算机视觉
声明:仅做学术分享,侵删
作者:Fing
https://www.zhihu.com/question/384519338/answer/1160886439
最近发现的一个神库。
深度学习实验结果保存与分析是最让我头疼的一件事情,每个实验要保存对应的log,training curve还有生成图片等等,光这些visualization就需要写很多重复的代码。跨设备的话还得把之前实验的记录都给拷到新设备去。
wandb这个库真是深得我心,只要几行代码就可以把每一次实验打包保存在云端,而且提供了自家的可视化接口,不用每次都自己写一个logger,也省掉了import matplotlib, tensorboard等一大堆重复堆积的代码块。最关键的是,它是免费的:)
作者:jpzLTIBaseline
https://www.zhihu.com/question/384519338/answer/1196326124
关于实验管理,其他人的回答已经写得十分详细了。虽然我自己还是习惯直接Google Sheet然后在表格里的每一行记录【git commit hashcode】、【server name】、【pid】、【bash script to run exp】、【实验具体结果】、【notes】、【log position】、【ckpt position】,而且Google Sheet增加column以及合并格子用起来还是很flexible的。
这里我提一下其他方面的一些有助于提高效率的工具:
给自己的model起一个酷炫的缩写:http://acronymify.com/
现在越来越多的论文标题(尤其是Deep Learning方向)都是 [model缩写]: [正经论文题目] 的格式,而且一个朗朗上口的名字确实有助于记忆与传播。
写paper时候的用词搭配:https://linggle.com/
作为一个non-native speaker,写paper的时候词语搭配真是让人头秃。这个网站可以比较方便地找一些词语搭配。
手写/截图 转 LaTex公式:https://mathpix.com/
LaTex如果所有公式都要自己手打还是很痛苦的。(虽然很多时候一篇Deep Learning方向的paper公式数量只有十个左右(这还是在强行加上LSTM等被翻来覆去写烂的公式的情况下))
颜色搭配(色盲友好型):http://colorbrewer2.org/
这个网站不仅能很方便找到各种常用的 color schemes,而且都是 grayscale friendly and colorblind-friendly,对于paper里画图帮助比较大。
找前人paper的code:https://paperswithcode.com/
有的时候自己复现真是玄学,这个网站和搜索引擎 "[论文题目] site:http://github.com"配合使用即可。
文字转语音:https://cloud.google.com/text-to-speech
有的paper需要做一个video来介绍,对自己口语不是很有信心的话可以用G家的text2speech(这个领域Google应该是当之无愧的霸主),还能调节语速,非常贴心。
作者:一只火山
https://www.zhihu.com/question/384519338/answer/1574144370
MONAI 啊!真不是我给我们英伟达打广告,这个开源工具真的香,我自己天天用。
复现别人代码的时候最怕什么?最怕preprocessing啊!现在大家网络的代码都开源,但再开源,用在你自己的数据集上,你也得preprocessing。懒人不开心。
而MONAI就是拯救懒人的!轻轻松松,几行代码就解决了。

而且MONAI还专门为医学图像预设好了多种preprocessing and data augmentation。妈妈再也不用担心我读取NIfTI文件啦!下面这段代码,从读取文件到normalize,甚至crop ROI一条龙服务。而且这个库代码风格极好,看函数名就能猜到在干嘛。
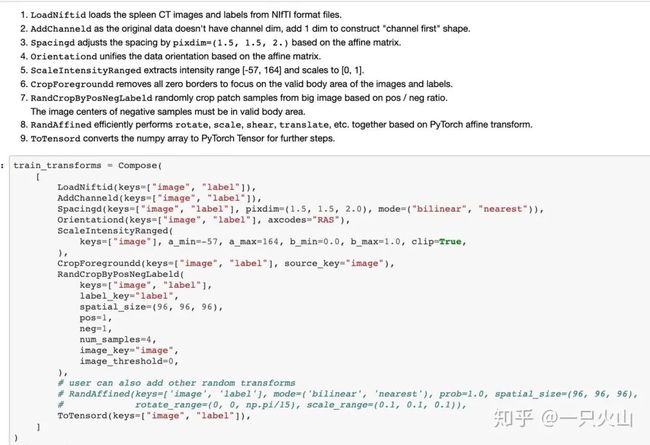
真的,MONAI,搞医学图像的必须尝试!搞自然图像的也很方便!绝对效率神器!
作者:张骞晖
https://www.zhihu.com/question/384519338/answer/1154117461
都是鄙人的一些经验,不一定有用
(1) 个人经验就是一定要有自己的代码风格,代码仓库。
代码风格可以学习别人的,代码仓库可以上传到github上。
风格可以帮助你快速的实现改动自己的代码,复现Baseline。
写的好了,就可以传到github上,不断地更新,优化。尤其是
深度学习算法,保证可以快速的查询到。
(2) xshell每次连接服务器,可能都要配置一下运行环境, 比如 conda activate tf19, tf14,切到工作目录, 项目很多就会乱。
首先:我们可以再自己用户的 bashrc 建立别名 alias
比如:
alias ns='nvidia-smi'
alias TF19='conda activate TF19'
运行TF19就可以配置好TF环境。每次打开xshell,为了避免每次键入TF19
可以再Session->Properties->Login scripts, Send
加入TF19
对于工作目录,按照同样的步骤,即可。
对于每个工作环境,工作目录,我们都可以建立一个不同的Session。这样打开Session
之后,所有都会配置好了。而且,我们给Session命好名,方便区分。
(3)深度学习环境迁移
我们配置好的环境,如果切换到另外的服务器,可以使用
pip freeze > requirements.txt 得到配置文件。
这个配置文件,到了另外的服务器,可以使用
pip install -r requirements.txt
另外这个文件可以提交到github上,方便别人使用我们的项目。
相似的命令:conda list
(4)磁盘检查,服务器上跑程序难免把磁盘占满,造成程序停掉
可以利用shutil包,来得到所在磁盘的free space,然后传入挂载点即可。例如
def getFreeDisk(mount_point='/'):
total, used, free = shutil.disk_usage(mount_point)
return free // (2**30)
之后,我们可以利用assert
assert getFreeDisk(config.mount_point) > 100
如果小于100,程序会报错。当然也有其他写法。只要在磁盘还有free space之前
给出警告即可。
作者:取栗
https://www.zhihu.com/question/384519338/answer/1153464864
我猜应该会有人提的,就当我重复一下吧:
1.apex 半精度训练 https://github.com/apex/apex
2.ALI (亲测效果很好,用在训练上还是推理上都是效率神器)https://github.com/NVIDIA/DALI
3.ncnn 仅限于推理加速https://github.com/Tencent/ncnn
作者:Ironboy
https://www.zhihu.com/question/384519338/answer/1145476709
计算资源对效率太重要了,几块好一些的显卡能支持你迅速复现别人的工作,验证自己的想法是不是work,以及在通用数据集/比赛上快速迭代刷分
听过一个故事:一名社畜在实验室服务器上训了三个月的模型,各种调参准确率都一直上不去,然后尝试向老板申请租了几块百度云的高性能GPU,单单把batch size调高到128,准确率就唰的上去了,然后一篇CVPR paper诞生。
不说了,调参去了,ImageNet训了好几天,怎么还会把人分成了狗!
作者:Tommey
https://www.zhihu.com/question/384519338/answer/1190380101
上面的回答都是一些大神的经验,非常有用。作为一个早期新人来说,我谈一点个人的看法。我觉得入门早期来说有四个门槛,数据,算力、环境和源码。
一、数据
数据的收集和下载费时费力,而且有些时候一些国外的服务器还经常断线。
二、算力
GPU的加速性能大家应该都知道,这也是N卡这些年火爆的一个主要原因,但是相应的CPU和内存其实也是需要能够配套的。好马还要配好鞍。
三、环境
现在环境安装已经非常方便了,大部分的包用PIP就能解决。但是单机上版本冲突的问题也是很麻烦的,比如有的TF版本要求cuda版本是9,有的又要求是8。这些对于新手来说无疑是满头的包。
四、源码
大神们都说github上别人的源码,但是绝大部分的源码直接下载下来是很难跑起来的。
作为一个预算有限,而且是自己探索的DLer来说,这四道门槛哪一道都不容易过。自己跳过这些坑,花了不少精力和银子,也试用过谷歌的免费GPU(一小时会重重置一次),用过亚马逊的服务器和一些国内的GPU服务商的产品,总体而言感觉@街道口扛把子推荐的这个平台还不错。附上链接:街道口扛把子:推荐一个GPU资源租赁台https://zhuanlan.zhihu.com/p/59905068
作者:zhangxiaoyang
https://www.zhihu.com/question/384519338/answer/1159695551
1. 离线效率:balance/转移成本
搞多个GPU、更多更好的样本(可以是巨量app的日志、找多人标注、自己重点修正边界)、用别人训好的模型(或finetune)、借助规则解决一些明确问题等。
2. 在线效率:通用机制建设
通用的模型serving、复杂模型transfer到简单模型、方便的干预/实验机制。
3. 日常效率:一键脚本
把重复性的操作一键脚本化,就能大大提升效率了。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
