目录
- 下载数据集
- 定义数据集常量
- 转换example函数
- 预处理常量
- 预处理
- 查看转换后数据
- 模型建立、训练、评估
- 测试预处理函数
- 测试tft函数(可直接使用的)
import math
import os
import pprint
import tempfile
import pathlib
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
import apache_beam as beam
import tensorflow_transform as tft
import tensorflow_transform.beam as tft_beam
from tfx_bsl.public import tfxio
from tfx_bsl.coders.example_coder import RecordBatchToExamplesEncoder
2023-06-26 23:55:49.730378: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-06-26 23:55:50.561378: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/TensorRT/lib:/usr/local/cuda-11.7/lib64
2023-06-26 23:55:50.561477: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/TensorRT/lib:/usr/local/cuda-11.7/lib64
2023-06-26 23:55:50.561486: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
下载数据集
import urllib
train_url_path = 'https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/census/adult.data'
test_url_path = 'https://storage.googleapis.com/artifacts.tfx-oss-public.appspot.com/datasets/census/adult.test'
train_path = os.path.join('./test3','adult.data')
test_path = os.path.join('./test3/','adult.test')
urllib.request.urlretrieve(train_url_path,train_path)
urllib.request.urlretrieve(test_url_path,test_path)
('./test3/adult.test', )
定义数据集常量
CATEGORICAL_FEATURE_KEYS = [
'workclass',
'education',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'native-country',
]
NUMERIC_FEATURE_KEYS = [
'age',
'capital-gain',
'capital-loss',
'hours-per-week',
'education-num'
]
ORDERED_CSV_COLUMNS = [
'age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'sex',
'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'label'
]
LABEL_KEY = 'label'
pandas_train = pd.read_csv(train_path,header=None,names=ORDERED_CSV_COLUMNS)
pandas_train.head(5)
|
age |
workclass |
fnlwgt |
education |
education-num |
marital-status |
occupation |
relationship |
race |
sex |
capital-gain |
capital-loss |
hours-per-week |
native-country |
label |
| 0 |
39 |
State-gov |
77516 |
Bachelors |
13 |
Never-married |
Adm-clerical |
Not-in-family |
White |
Male |
2174 |
0 |
40 |
United-States |
<=50K |
| 1 |
50 |
Self-emp-not-inc |
83311 |
Bachelors |
13 |
Married-civ-spouse |
Exec-managerial |
Husband |
White |
Male |
0 |
0 |
13 |
United-States |
<=50K |
| 2 |
38 |
Private |
215646 |
HS-grad |
9 |
Divorced |
Handlers-cleaners |
Not-in-family |
White |
Male |
0 |
0 |
40 |
United-States |
<=50K |
| 3 |
53 |
Private |
234721 |
11th |
7 |
Married-civ-spouse |
Handlers-cleaners |
Husband |
Black |
Male |
0 |
0 |
40 |
United-States |
<=50K |
| 4 |
28 |
Private |
338409 |
Bachelors |
13 |
Married-civ-spouse |
Prof-specialty |
Wife |
Black |
Female |
0 |
0 |
40 |
Cuba |
<=50K |
COLUMN_DEFAULTS = [
'' if isinstance(v, str) else 0.0
for v in dict(pandas_train.loc[1]).values()]
COLUMN_DEFAULTS
[0.0, '', 0.0, '', 0.0, '', '', '', '', '', 0.0, 0.0, 0.0, '', '']
pandas_test = pd.read_csv(test_path, header=1, names=ORDERED_CSV_COLUMNS)
pandas_test.head(5)
|
age |
workclass |
fnlwgt |
education |
education-num |
marital-status |
occupation |
relationship |
race |
sex |
capital-gain |
capital-loss |
hours-per-week |
native-country |
label |
| 0 |
38 |
Private |
89814 |
HS-grad |
9 |
Married-civ-spouse |
Farming-fishing |
Husband |
White |
Male |
0 |
0 |
50 |
United-States |
<=50K. |
| 1 |
28 |
Local-gov |
336951 |
Assoc-acdm |
12 |
Married-civ-spouse |
Protective-serv |
Husband |
White |
Male |
0 |
0 |
40 |
United-States |
>50K. |
| 2 |
44 |
Private |
160323 |
Some-college |
10 |
Married-civ-spouse |
Machine-op-inspct |
Husband |
Black |
Male |
7688 |
0 |
40 |
United-States |
>50K. |
| 3 |
18 |
? |
103497 |
Some-college |
10 |
Never-married |
? |
Own-child |
White |
Female |
0 |
0 |
30 |
United-States |
<=50K. |
| 4 |
34 |
Private |
198693 |
10th |
6 |
Never-married |
Other-service |
Not-in-family |
White |
Male |
0 |
0 |
30 |
United-States |
<=50K. |
RAW_DATA_FEATURE_SPEC = dict(
[(name, tf.io.FixedLenFeature([], tf.string))
for name in CATEGORICAL_FEATURE_KEYS] +
[(name, tf.io.FixedLenFeature([], tf.float32))
for name in NUMERIC_FEATURE_KEYS] +
[(LABEL_KEY, tf.io.FixedLenFeature([], tf.string))]
)
SCHEMA = tft.DatasetMetadata.from_feature_spec(RAW_DATA_FEATURE_SPEC).schema
转换example函数
from typing import List,Union,Optional
from tensorflow_metadata.proto.v0 import schema_pb2
import pandas as pd
import tensorflow_data_validation as tfdv
import numpy as np
def create_example_by_schema_from_dataframe(row:pd.Series,column_names:List[str],schema_or_schemapath:Union[str,schema_pb2.Schema]):
"""
根据数据原来的Schema信息将输入的一行数据转换为序列化后的example
input:
row:类型为pd.Series的一行数据
column_names:类型为列表,包含需要转换的列名
schema_or_schemapath:数据的Schema实例或者Schema的路径(需要具体到schema.pbtxt)
output:
example:example数据
"""
features = {}
if isinstance(schema_or_schemapath,str):
schema_or_schemapath=tfdv.load_schema_text(schema_or_schemapath)
for columnName in column_names:
typeCode = tfdv.get_feature(schema_or_schemapath,columnName).type
tempvalue = None
if typeCode == 1:
if pd.isna(row[columnName]):
tempvalue = b''
else:
tempvalue = row[columnName].encode()
features[columnName] = tf.train.Feature(bytes_list=tf.train.BytesList(value=[tempvalue]))
elif typeCode == 2:
if pd.isna(row[columnName]):
tempvalue = 0
else:
tempvalue = int(row[columnName])
features[columnName] = tf.train.Feature(int64_list=tf.train.Int64List(value=[tempvalue]))
elif typeCode == 3:
if pd.isna(row[columnName]):
tempvalue = 0.0
else:
tempvalue = float(row[columnName])
features[columnName] = tf.train.Feature(float_list=tf.train.FloatList(value=[tempvalue]))
example_proto = tf.train.Example(features=tf.train.Features(feature=features))
return example_proto
def create_feature_spec_by_schema_from_columnnames(column_names:List[str],schema_or_schemapath:Union[str,schema_pb2.Schema],all_num_to_float:bool=False):
"""
根据Schema从需要的列中获得它的Feature_spec
input:
column_names:类型为列表,包含需要的列名
schema_or_schemapath:数据的Schema实例或者Schema的路径(需要具体到schema.pbtxt)
all_num_to_float:是否将所有的数值类型设为tf.float64
output:
output_dict:获得的feature_spec
"""
output_dict={}
if isinstance(schema_or_schemapath,str):
schema_or_schemapath=tfdv.load_schema_text(schema_or_schemapath)
for columnName in column_names:
typeCode = tfdv.get_feature(schema_or_schemapath,columnName).type
if typeCode == 1:
output_dict[columnName] = tf.io.FixedLenFeature([],tf.string)
elif typeCode == 2:
if all_num_to_float:
output_dict[columnName] = tf.io.FixedLenFeature([], tf.float32)
else:
output_dict[columnName] = tf.io.FixedLenFeature([], tf.int64)
elif typeCode == 3:
output_dict[columnName] = tf.io.FixedLenFeature([], tf.float32)
return output_dict
tf_example = create_example_by_schema_from_dataframe(pandas_train.loc[0],NUMERIC_FEATURE_KEYS+CATEGORICAL_FEATURE_KEYS,SCHEMA)
tf_example.features.feature['age']
float_list {
value: 39.0
}
created_feature_spec=create_feature_spec_by_schema_from_columnnames(NUMERIC_FEATURE_KEYS+CATEGORICAL_FEATURE_KEYS,SCHEMA)
created_feature_spec
{'age': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'capital-gain': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'capital-loss': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'hours-per-week': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'education-num': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'workclass': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'education': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'marital-status': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'occupation': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'relationship': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'race': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'sex': FixedLenFeature(shape=[], dtype=tf.string, default_value=None),
'native-country': FixedLenFeature(shape=[], dtype=tf.string, default_value=None)}
decoded_tensor = tf.io.parse_single_example(
tf_example.SerializeToString(),
features=created_feature_spec
)
decoded_tensor
2023-06-26 23:55:59.068527: I tensorflow/compiler/xla/stream_executor/cuda/cuda_gpu_executor.cc:967] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2023-06-26 23:55:59.099139: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudnn.so.8'; dlerror: libcudnn.so.8: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/TensorRT/lib:/usr/local/cuda-11.7/lib64
2023-06-26 23:55:59.099171: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1934] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2023-06-26 23:55:59.099783: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
{'age': ,
'capital-gain': ,
'capital-loss': ,
'education': ,
'education-num': ,
'hours-per-week': ,
'marital-status': ,
'native-country': ,
'occupation': ,
'race': ,
'relationship': ,
'sex': ,
'workclass': }
'marital-status' in tf_example.features.feature.keys()
True
预处理常量
NUM_OOV_BUCKETS = 1
EPOCH_SPLITS = 10
TRAIN_NUM_EPOCHS = 2*EPOCH_SPLITS
NUM_TRAIN_INSTANCES = len(pandas_train)
NUM_TEST_INSTANCES = len(pandas_test)
BATCH_SIZE = 128
STEPS_PER_TRAIN_EPOCH = tf.math.ceil(NUM_TRAIN_INSTANCES/BATCH_SIZE/EPOCH_SPLITS)
EVALUATION_STEPS = tf.math.ceil(NUM_TEST_INSTANCES/BATCH_SIZE)
TRANSFORMED_TRAIN_DATA_FILEBASE = 'train_transformed'
TRANSFORMED_TEST_DATA_FILEBASE = 'test_transformed'
EXPORTED_MODEL_DIR = 'exported_model_dir'
预处理
def preprocessing_fn(inputs):
outputs = inputs.copy()
for key in NUMERIC_FEATURE_KEYS:
outputs[key] = tft.scale_to_0_1(inputs[key])
for key in CATEGORICAL_FEATURE_KEYS:
outputs[key] = tft.compute_and_apply_vocabulary(
tf.strings.strip(inputs[key]),
num_oov_buckets=NUM_OOV_BUCKETS,
vocab_filename=key
)
table_keys = ['>50K','<=50K']
with tf.init_scope():
initializer = tf.lookup.KeyValueTensorInitializer(
keys=table_keys,
values=tf.cast(tf.range(len(table_keys)),tf.int64),
key_dtype=tf.string,
value_dtype=tf.int64
)
table = tf.lookup.StaticHashTable(initializer,default_value=-1)
label_str = inputs[LABEL_KEY]
label_str = tf.strings.regex_replace(label_str,r'\.$','')
label_str = tf.strings.strip(label_str)
data_labels = table.lookup(label_str)
transformed_label = tf.one_hot(
indices=data_labels,depth=len(table_keys),on_value=1.0,off_value=0.0
)
outputs[LABEL_KEY] = tf.reshape(transformed_label, [-1, len(table_keys)])
return outputs
def transform_data(train_data_file,test_data_file,working_dir):
with beam.Pipeline() as pipeline:
with tft_beam.Context(temp_dir=tempfile.mkdtemp()):
train_csv_tfxio = tfxio.CsvTFXIO(
file_pattern=train_data_file,
telemetry_descriptors=[],
column_names=ORDERED_CSV_COLUMNS,
schema=SCHEMA
)
raw_data = (
pipeline |
'ReadTrainCsv' >> train_csv_tfxio.BeamSource()
)
cfg = train_csv_tfxio.TensorAdapterConfig()
raw_dataset = (raw_data,cfg)
transformed_dataset, transform_fn = (
raw_dataset | tft_beam.AnalyzeAndTransformDataset(
preprocessing_fn,output_record_batches=True)
)
transformed_data, _ = transformed_dataset
coder = RecordBatchToExamplesEncoder()
_ = (
transformed_data
| 'EncodeTrainData' >>
beam.FlatMapTuple(lambda batch, _: coder.encode(batch))
| 'WriteTrainData' >> beam.io.WriteToTFRecord(
os.path.join(working_dir,TRANSFORMED_TRAIN_DATA_FILEBASE))
)
test_csv_tfxio = tfxio.CsvTFXIO(
file_pattern=test_data_file,
skip_header_lines=1,
telemetry_descriptors=[],
column_names=ORDERED_CSV_COLUMNS,
schema=SCHEMA
)
raw_test_data = (
pipeline | 'ReadTestCsv' >> test_csv_tfxio.BeamSource()
)
raw_test_dataset = (raw_test_data,test_csv_tfxio.TensorAdapterConfig())
transformed_test_dataset = (
(raw_test_dataset, transform_fn)
| tft_beam.TransformDataset(output_record_batches=True)
)
transformed_test_data, _ = transformed_test_dataset
_ = (
transformed_test_data
| 'EncodeTestData' >>
beam.FlatMapTuple(lambda batch, _ :coder.encode(batch))
| 'WriteTestData' >> beam.io.WriteToTFRecord(
os.path.join(working_dir,TRANSFORMED_TEST_DATA_FILEBASE))
)
_ = (
transform_fn
| 'WriteTransformFn' >> tft_beam.WriteTransformFn(working_dir)
)
查看转换后数据
output_dir = os.path.join(tempfile.mkdtemp(), 'keras')
transform_data(train_path, test_path, output_dir)
WARNING:apache_beam.runners.interactive.interactive_environment:Dependencies required for Interactive Beam PCollection visualization are not available, please use: `pip install apache-beam[interactive]` to install necessary dependencies to enable all data visualization features.
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow_transform/tf_utils.py:324: Tensor.experimental_ref (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use ref() instead.
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow_transform/tf_utils.py:324: Tensor.experimental_ref (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use ref() instead.
INFO:tensorflow:Assets written to: /tmp/tmpg4n8yfpg/tftransform_tmp/631aea06548b4fb38aaa5e855fd97e70/assets
INFO:tensorflow:Assets written to: /tmp/tmpg4n8yfpg/tftransform_tmp/631aea06548b4fb38aaa5e855fd97e70/assets
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_text is not available.
INFO:tensorflow:tensorflow_text is not available.
INFO:tensorflow:Assets written to: /tmp/tmpg4n8yfpg/tftransform_tmp/2c585badca494ed8939abc241f42206a/assets
INFO:tensorflow:Assets written to: /tmp/tmpg4n8yfpg/tftransform_tmp/2c585badca494ed8939abc241f42206a/assets
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_text is not available.
INFO:tensorflow:tensorflow_text is not available.
WARNING:apache_beam.io.tfrecordio:Couldn't find python-snappy so the implementation of _TFRecordUtil._masked_crc32c is not as fast as it could be.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_text is not available.
INFO:tensorflow:tensorflow_text is not available.
!ls {output_dir}
test_transformed-00000-of-00001 transform_fn
train_transformed-00000-of-00001 transformed_metadata
a
tf_transform_output = tft.TFTransformOutput(output_dir)
tf_transform_output.transformed_feature_spec()
{'age': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'capital-gain': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'capital-loss': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'education': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'education-num': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'hours-per-week': FixedLenFeature(shape=[], dtype=tf.float32, default_value=None),
'label': FixedLenFeature(shape=[2], dtype=tf.float32, default_value=None),
'marital-status': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'native-country': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'occupation': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'race': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'relationship': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'sex': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None),
'workclass': FixedLenFeature(shape=[], dtype=tf.int64, default_value=None)}
def _make_training_input_fn(tf_transform_output, train_file_pattern,
batch_size):
"""An input function reading from transformed data, converting to model input.
Args:
tf_transform_output: Wrapper around output of tf.Transform.
transformed_examples: Base filename of examples.
batch_size: Batch size.
Returns:
The input data for training or eval, in the form of k.
"""
def input_fn():
return tf.data.experimental.make_batched_features_dataset(
file_pattern=train_file_pattern,
batch_size=batch_size,
features=tf_transform_output.transformed_feature_spec(),
reader=tf.data.TFRecordDataset,
label_key=LABEL_KEY,
shuffle=True)
return input_fn
train_file_pattern = pathlib.Path(output_dir)/f'{TRANSFORMED_TRAIN_DATA_FILEBASE}*'
input_fn = _make_training_input_fn(
tf_transform_output=tf_transform_output,
train_file_pattern = str(train_file_pattern),
batch_size = 10
)
for example, label in input_fn().take(5):
break
pd.DataFrame(example)
|
age |
capital-gain |
capital-loss |
education |
education-num |
hours-per-week |
marital-status |
native-country |
occupation |
race |
relationship |
sex |
workclass |
| 0 |
0.150685 |
0.000000 |
0.000000 |
2 |
0.800000 |
0.500000 |
0 |
0 |
4 |
0 |
0 |
0 |
0 |
| 1 |
0.000000 |
0.010550 |
0.000000 |
10 |
0.266667 |
0.234694 |
1 |
0 |
5 |
0 |
2 |
0 |
0 |
| 2 |
0.397260 |
0.000000 |
0.000000 |
0 |
0.533333 |
0.377551 |
2 |
0 |
6 |
0 |
1 |
1 |
0 |
| 3 |
0.068493 |
0.000000 |
0.000000 |
1 |
0.600000 |
0.397959 |
1 |
0 |
8 |
0 |
1 |
0 |
0 |
| 4 |
0.287671 |
0.000000 |
0.453857 |
9 |
0.933333 |
0.500000 |
0 |
0 |
0 |
0 |
0 |
0 |
6 |
| 5 |
0.027397 |
0.000000 |
0.000000 |
0 |
0.533333 |
0.397959 |
1 |
0 |
6 |
1 |
2 |
1 |
0 |
| 6 |
0.191781 |
0.000000 |
0.000000 |
2 |
0.800000 |
0.397959 |
0 |
0 |
0 |
0 |
4 |
1 |
0 |
| 7 |
0.657534 |
0.200512 |
0.000000 |
3 |
0.866667 |
0.397959 |
0 |
0 |
4 |
0 |
0 |
0 |
0 |
| 8 |
0.534247 |
0.000000 |
0.000000 |
2 |
0.800000 |
0.397959 |
4 |
0 |
5 |
0 |
1 |
1 |
0 |
| 9 |
0.315068 |
0.000000 |
0.000000 |
2 |
0.800000 |
0.367347 |
1 |
0 |
5 |
0 |
1 |
0 |
0 |
label
模型建立、训练、评估
def build_keras_inputs(working_dir):
tf_transform_output = tft.TFTransformOutput(working_dir)
feature_spec = tf_transform_output.transformed_feature_spec().copy()
feature_spec.pop(LABEL_KEY)
inputs={}
for key, spec in feature_spec.items():
if isinstance(spec,tf.io.VarLenFeature):
inputs[key] = tf.keras.layers.Input(
shape=[None],name=key,dtype=spec.dtype,sparse=True)
elif isinstance(spec,tf.io.FixedLenFeature):
inputs[key] = tf.keras.layers.Input(
shape=spec.shape,name=key,dtype=spec.dtype)
else:
raise ValueError('Spec type is not supported:',key,spec)
return inputs
def encode_inputs(inputs):
encoded_inputs = {}
for key in inputs:
feature = tf.expand_dims(inputs[key],-1)
if key in CATEGORICAL_FEATURE_KEYS:
num_buckets = tf_transform_output.num_buckets_for_transformed_feature(key)
encoding_layer = (
tf.keras.layers.CategoryEncoding(
num_tokens=num_buckets,output_mode='binary',sparse=False))
encoded_inputs[key] = encoding_layer(feature)
else:
encoded_inputs[key] = feature
return encoded_inputs
def build_keras_model(working_dir):
inputs = build_keras_inputs(working_dir)
encoded_inputs = encode_inputs(inputs)
stacked_inputs = tf.concat(tf.nest.flatten(encoded_inputs),axis=1)
output = tf.keras.layers.Dense(100,activation='relu')(stacked_inputs)
output = tf.keras.layers.Dense(50,activation='relu')(output)
output = tf.keras.layers.Dense(2)(output)
model = tf.keras.Model(inputs=inputs,outputs=output)
return model
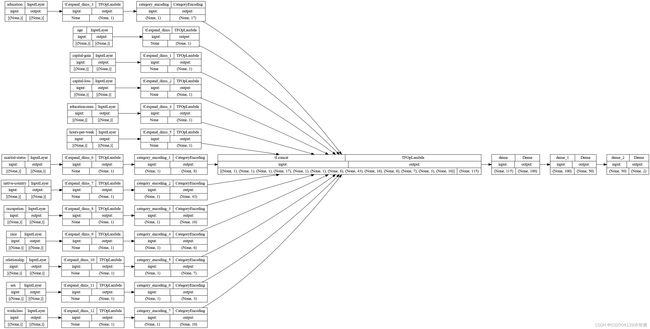
model = build_keras_model(output_dir)
tf.keras.utils.plot_model(model,rankdir='LR', show_shapes=True)
def get_dataset(working_dir, filebase):
tf_transform_output = tft.TFTransformOutput(working_dir)
data_path_pattern = os.path.join(
working_dir,
filebase + '*')
input_fn = _make_training_input_fn(
tf_transform_output,
data_path_pattern,
batch_size=BATCH_SIZE)
dataset = input_fn()
return dataset
def train_model(model, train_dataset, validation_dataset):
model.compile(optimizer='adam',
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_dataset, validation_data=validation_dataset,
epochs=TRAIN_NUM_EPOCHS,
steps_per_epoch=STEPS_PER_TRAIN_EPOCH,
validation_steps=EVALUATION_STEPS)
return history
def train_and_evaluate(
model,
working_dir):
"""Train the model on training data and evaluate on test data.
Args:
working_dir: The location of the Transform output.
num_train_instances: Number of instances in train set
num_test_instances: Number of instances in test set
Returns:
The results from the estimator's 'evaluate' method
"""
train_dataset = get_dataset(working_dir, TRANSFORMED_TRAIN_DATA_FILEBASE)
validation_dataset = get_dataset(working_dir, TRANSFORMED_TEST_DATA_FILEBASE)
model = build_keras_model(working_dir)
history = train_model(model, train_dataset, validation_dataset)
metric_values = model.evaluate(validation_dataset,
steps=EVALUATION_STEPS,
return_dict=True)
return model, history, metric_values
model, history, metric_values = train_and_evaluate(model, output_dir)
Epoch 1/20
26/26 [==============================] - 2s 30ms/step - loss: 0.5085 - accuracy: 0.7623 - val_loss: 0.4191 - val_accuracy: 0.7864
Epoch 2/20
26/26 [==============================] - 0s 18ms/step - loss: 0.4029 - accuracy: 0.8092 - val_loss: 0.3704 - val_accuracy: 0.8270
Epoch 3/20
26/26 [==============================] - 1s 22ms/step - loss: 0.3721 - accuracy: 0.8302 - val_loss: 0.3596 - val_accuracy: 0.8329
Epoch 4/20
26/26 [==============================] - 1s 21ms/step - loss: 0.3517 - accuracy: 0.8332 - val_loss: 0.3527 - val_accuracy: 0.8349
Epoch 5/20
26/26 [==============================] - 0s 19ms/step - loss: 0.3494 - accuracy: 0.8389 - val_loss: 0.3467 - val_accuracy: 0.8388
Epoch 6/20
26/26 [==============================] - 0s 19ms/step - loss: 0.3401 - accuracy: 0.8425 - val_loss: 0.3477 - val_accuracy: 0.8396
Epoch 7/20
26/26 [==============================] - 0s 19ms/step - loss: 0.3461 - accuracy: 0.8419 - val_loss: 0.3444 - val_accuracy: 0.8395
Epoch 8/20
26/26 [==============================] - 0s 20ms/step - loss: 0.3570 - accuracy: 0.8305 - val_loss: 0.3427 - val_accuracy: 0.8417
Epoch 9/20
26/26 [==============================] - 1s 24ms/step - loss: 0.3387 - accuracy: 0.8447 - val_loss: 0.3406 - val_accuracy: 0.8420
Epoch 10/20
26/26 [==============================] - 1s 20ms/step - loss: 0.3419 - accuracy: 0.8431 - val_loss: 0.3386 - val_accuracy: 0.8433
Epoch 11/20
26/26 [==============================] - 1s 23ms/step - loss: 0.3423 - accuracy: 0.8401 - val_loss: 0.3391 - val_accuracy: 0.8422
Epoch 12/20
26/26 [==============================] - 1s 25ms/step - loss: 0.3364 - accuracy: 0.8459 - val_loss: 0.3360 - val_accuracy: 0.8442
Epoch 13/20
26/26 [==============================] - 1s 20ms/step - loss: 0.3325 - accuracy: 0.8543 - val_loss: 0.3350 - val_accuracy: 0.8436
Epoch 14/20
26/26 [==============================] - 1s 23ms/step - loss: 0.3287 - accuracy: 0.8474 - val_loss: 0.3334 - val_accuracy: 0.8441
Epoch 15/20
26/26 [==============================] - 0s 20ms/step - loss: 0.3395 - accuracy: 0.8404 - val_loss: 0.3348 - val_accuracy: 0.8434
Epoch 16/20
26/26 [==============================] - 0s 19ms/step - loss: 0.3307 - accuracy: 0.8537 - val_loss: 0.3352 - val_accuracy: 0.8435
Epoch 17/20
26/26 [==============================] - 0s 19ms/step - loss: 0.3197 - accuracy: 0.8483 - val_loss: 0.3336 - val_accuracy: 0.8443
Epoch 18/20
26/26 [==============================] - 1s 22ms/step - loss: 0.3479 - accuracy: 0.8332 - val_loss: 0.3303 - val_accuracy: 0.8455
Epoch 19/20
26/26 [==============================] - 1s 22ms/step - loss: 0.3300 - accuracy: 0.8459 - val_loss: 0.3343 - val_accuracy: 0.8411
Epoch 20/20
26/26 [==============================] - 1s 20ms/step - loss: 0.3393 - accuracy: 0.8374 - val_loss: 0.3311 - val_accuracy: 0.8438
128/128 [==============================] - 1s 2ms/step - loss: 0.3304 - accuracy: 0.8441
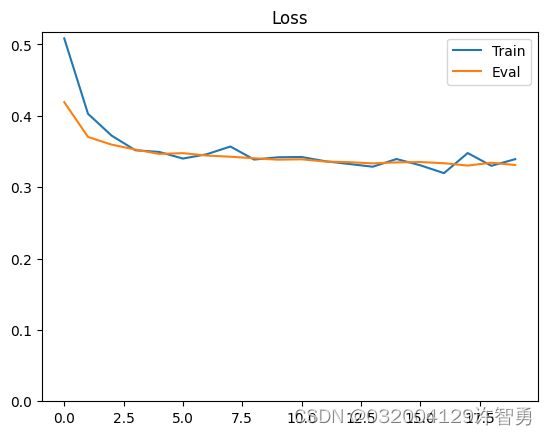
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Eval')
plt.ylim(0,max(plt.ylim()))
plt.legend()
plt.title('Loss');
测试预处理函数
def read_csv(file_name, batch_size):
return tf.data.experimental.make_csv_dataset(
file_pattern=file_name,
batch_size=batch_size,
column_names=ORDERED_CSV_COLUMNS,
column_defaults=COLUMN_DEFAULTS,
prefetch_buffer_size=0,
ignore_errors=True)
for ex in read_csv(test_path, batch_size=5):
break
ex2 = ex.copy()
ex2.pop('fnlwgt')
tft_layer = tf_transform_output.transform_features_layer()
t_ex = tft_layer(ex2)
label = t_ex.pop(LABEL_KEY)
pd.DataFrame(t_ex)
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow/python/data/experimental/ops/readers.py:572: ignore_errors (from tensorflow.python.data.experimental.ops.error_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.ignore_errors` instead.
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow/python/data/experimental/ops/readers.py:572: ignore_errors (from tensorflow.python.data.experimental.ops.error_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.data.Dataset.ignore_errors` instead.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:struct2tensor is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_decision_forests is not available.
INFO:tensorflow:tensorflow_text is not available.
INFO:tensorflow:tensorflow_text is not available.
|
sex |
marital-status |
occupation |
native-country |
relationship |
education |
workclass |
capital-gain |
education-num |
hours-per-week |
capital-loss |
race |
age |
| 0 |
1 |
0 |
3 |
0 |
4 |
2 |
0 |
0.0 |
0.800000 |
0.397959 |
0.0 |
0 |
0.109589 |
| 1 |
1 |
1 |
5 |
0 |
3 |
4 |
0 |
0.0 |
0.666667 |
0.091837 |
0.0 |
0 |
0.219178 |
| 2 |
0 |
1 |
7 |
1 |
1 |
13 |
3 |
0.0 |
0.133333 |
0.244898 |
0.0 |
0 |
0.041096 |
| 3 |
1 |
1 |
0 |
0 |
1 |
3 |
0 |
0.0 |
0.866667 |
0.397959 |
0.0 |
0 |
0.520548 |
| 4 |
0 |
1 |
7 |
0 |
1 |
2 |
3 |
0.0 |
0.800000 |
0.346939 |
0.0 |
0 |
0.082192 |
pdex2=pd.DataFrame(ex2)
pdex2
|
age |
workclass |
education |
education-num |
marital-status |
occupation |
relationship |
race |
sex |
capital-gain |
capital-loss |
hours-per-week |
native-country |
label |
| 0 |
25.0 |
b' Private' |
b' Bachelors' |
13.0 |
b' Married-civ-spouse' |
b' Adm-clerical' |
b' Wife' |
b' White' |
b' Female' |
0.0 |
0.0 |
40.0 |
b' United-States' |
b' <=50K.' |
| 1 |
33.0 |
b' Private' |
b' Assoc-voc' |
11.0 |
b' Never-married' |
b' Other-service' |
b' Unmarried' |
b' White' |
b' Female' |
0.0 |
0.0 |
10.0 |
b' United-States' |
b' <=50K.' |
| 2 |
20.0 |
b' ?' |
b' 5th-6th' |
3.0 |
b' Never-married' |
b' ?' |
b' Not-in-family' |
b' White' |
b' Male' |
0.0 |
0.0 |
25.0 |
b' Mexico' |
b' <=50K.' |
| 3 |
55.0 |
b' Private' |
b' Masters' |
14.0 |
b' Never-married' |
b' Prof-specialty' |
b' Not-in-family' |
b' White' |
b' Female' |
0.0 |
0.0 |
40.0 |
b' United-States' |
b' <=50K.' |
| 4 |
23.0 |
b' ?' |
b' Bachelors' |
13.0 |
b' Never-married' |
b' ?' |
b' Not-in-family' |
b' White' |
b' Male' |
0.0 |
0.0 |
35.0 |
b' United-States' |
b' <=50K.' |
pdex2['age']
0 25.0
1 33.0
2 20.0
3 55.0
4 23.0
Name: age, dtype: float32
测试tft函数(可直接使用的)
tft.apply_buckets(pdex2['age'],[[10,20,30,40,50,60]])
tft.apply_buckets_with_interpolation(tf.constant(pdex2['age'],dtype=tf.float32),[[10,20,30,40,50,60]])
sparse = tf.SparseTensor(indices=[[0, 0], [0, 1], [2, 2]],
values=['a', 'b', 'c'], dense_shape=(4, 4))
sparse
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 1]
[2 2]], shape=(3, 2), dtype=int64), values=tf.Tensor([b'a' b'b' b'c'], shape=(3,), dtype=string), dense_shape=tf.Tensor([4 4], shape=(2,), dtype=int64))
tft.bag_of_words(sparse,(1,2),' ')
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow_transform/mappers.py:1396: calling while_loop_v2 (from tensorflow.python.ops.control_flow_ops) with back_prop=False is deprecated and will be removed in a future version.
Instructions for updating:
back_prop=False is deprecated. Consider using tf.stop_gradient instead.
Instead of:
results = tf.while_loop(c, b, vars, back_prop=False)
Use:
results = tf.nest.map_structure(tf.stop_gradient, tf.while_loop(c, b, vars))
WARNING:tensorflow:From /home/xzy/anaconda3/envs/tf/lib/python3.8/site-packages/tensorflow_transform/mappers.py:1396: calling while_loop_v2 (from tensorflow.python.ops.control_flow_ops) with back_prop=False is deprecated and will be removed in a future version.
Instructions for updating:
back_prop=False is deprecated. Consider using tf.stop_gradient instead.
Instead of:
results = tf.while_loop(c, b, vars, back_prop=False)
Use:
results = tf.nest.map_structure(tf.stop_gradient, tf.while_loop(c, b, vars))
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 1]
[0 2]
[2 0]], shape=(4, 2), dtype=int64), values=tf.Tensor([b'a' b'a b' b'b' b'c'], shape=(4,), dtype=string), dense_shape=tf.Tensor([4 3], shape=(2,), dtype=int64))
tft.ngrams(sparse,(1,2),' ')
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 1]
[0 2]
[2 0]], shape=(4, 2), dtype=int64), values=tf.Tensor([b'a' b'a b' b'b' b'c'], shape=(4,), dtype=string), dense_shape=tf.Tensor([4 3], shape=(2,), dtype=int64))
tft.deduplicate_tensor_per_row(tf.constant([[1,1,2],[2,3,2]]))
SparseTensor(indices=tf.Tensor(
[[0 0]
[0 1]
[1 0]
[1 1]], shape=(4, 2), dtype=int64), values=tf.Tensor([1 2 2 3], shape=(4,), dtype=int32), dense_shape=tf.Tensor([2 2], shape=(2,), dtype=int64))
tft.hash_strings(tf.constant(pdex2['sex'],dtype=tf.string),3)
tft.word_count(sparse)