终于要迎来postgresql的《A Tour of PostgreSQL Internals》系列的最后一篇了。学习是不能拖延的事儿,越拖延事情越多。不废话,一起来看看吧~
View 3 Postgresql的查询处理
还是先上图吧。下面这张图从整体上概括了Postgresql的查询处理的步骤以及牵涉到的各个模块。
其中最重要的关键的两个数据结构是查询分析树(parse tree),和查询计划树(plan tree)。
对上图所标示的四个模块,下面一一来分析。
3.1 Parser(查询分析模块)
该模块通过对SQL语句进行分析生成查询树。
查询分析是查询编译的第一个模块,包括词法分析、语法分析和语义分析。它将用户输入的SQL语句进行词法分析(使用Lex工具)和语法分析(Yacc工具)生成分析树,然后进行语义分析得到查询树(parse tree)。
查询树中有几个重要的属性:
1) commandType:查询树对应的命令类型,说明由哪类命令生成该查询树。包括CMD_SELECT、CMD_DELETE、CMD_UPDATE、CMD_INSERT和CMD_UTILITY,如果命令类型为CMD_UTILITY,则查询优化器不会对该查询树进行优化。
2) rtable:范围表,查询中使用的表的列表。
3) resultRelation:结果关系,是涉及数据修改的范围表,该字段只适合INSERT/UPDATE/DELETE命令。
4) targetList:表示目标属性,用于存放查询结构属性的表达式,分四种情况:
a.SELECT语句:目标属性即为SELECT和FROM之间的表达式;
b.DELETE语句:不需要目标属性,因为DELETE语句不返回元组;
c.INSERT语句:目标属性描述插入到结果关系的元组的属性;
d.UPDATE语句:目标属性描述被更新的属性,即SET子句中的属性。5) jointree:连接树,查询的连接树显示了FROM子句中表的连接情况,通常还会附加上WHERE的条件表达式。
比如有如下的SQL语句:
SELECT * FROM tab1, tab2 WHERE tab1.a = tab2.f那么该语句的查询树如下:

3.2 Rewriter(重写模块)
对查询树重写并生成新的查询树,以提供对规则和视图的支持。
查询重写模块使用规则系统判断来进行查询树的重写,如果查询树中的某个目标被定义了转换规则,则该转换规则会被用来重写查询树。
例如:如果3.1中提到的tab2是一个视图,则该视图会被替换为一个对应的子查询。重写模块将会生成一个新的查询树。如下图所示:
查询重写的核心是规则系统。而规则系统由一系列的规则组成。系统表pg_rewrite中存储了重写规则。
根据系统表pg_rewrite的不同属性,规则可以按两种方式分类:
- 按照规则使用的命令类型:可分成SELECT、UPDATE、INSERT和DELETE四种;
- 按照规则执行动作的方式:可分为INSTEAD(替代)规则和ALSO规则。
在插入/更新/删除时规则需要更复杂的转换,并且可能从一个查询中产生多个查询。
3.3 Planner(查询计划模块)
本模块的主要功能是对给定的SQL查询语句,基于代价估计模型,选择最优的查询计划树。
SQL语句不同于JAVA,C语言这样,编写好之后按照固定的顺序和路径执行,相反,SQL只指明要求的查询结果,没有指定具体的查询路线。因此,在数据库管理系统中,用户的请求查询可以用不同的方案来执行。尽管执行结果是相同的,但是执行效率却存在差异。查询计划就用于选择一种代价最小的方案。因此,在数据库查询性能方面起着举足轻重的作用。
举例说明,假如有如下的SQL语句:
SELECT * FROM t WHERE f1 < 100;我们假设在t(f1)上建立了索引。那么我们就可能有两种可能的查询计划:
1.顺序地扫描全表(Full table scan);
2.利用索引t(f1)查找 f1 < 100 的元组(Index scan);查询计划就会计算时间代价(磁盘页的读取和CPU时间),然后选择时间代价较少的查询计划。
虽然大多数情况下,Index scan 会比 Full table scan 要快一些,但是这并非必然。这还和被检索的行数有关,这个问题在此处就不展开了。
3.4 Executor(执行模块)
执行模块的基本工作是执行一个查询计划树。
一个查询计划树的执行是一个像流水线一样对节点进行处理的网络。每次被调用时,每个节点将产生的元组放在它的输出序列中。上层节点调用下层子节点获取输入元组,利用这些输入元组计算本节点的输出元组。对于这些节点,有以下区别:
1) 底层节点直接对物理表进行扫描,要么是全表扫描,要么是通过索引扫描(index scan);
2) 上层节点主要是进行join(nested-loop, merge, hash join)操作的节点;
3) 当然,也有特殊用途的节点类型,如用于排序和聚合。
听起来很绕,我们看个例子。
对于下面的SQL语句:
SELECT SUM(a1)+1 FROM a WHERE a2 < a3;模块执行的查询计划树如下图: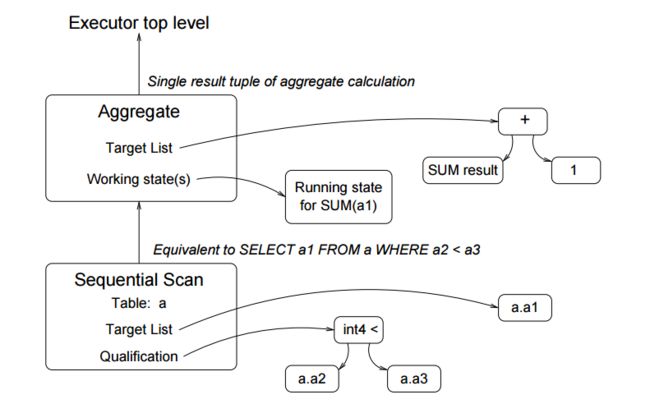
再来一个两表之间join+聚集函数例子:
SELECT DISTINCT a1, b1 FROM a, b WHERE a2 = b2 AND a3 = 42;对应的查询计划树如下图:
3.5 和join相关的查询计划
在多表(表的个数为n)查询的情形下,查询计划首先估算每个表分别采用Index scan(如果有的话) 和Full table scan的查询代价,然后建立一个join的树型结构,在树中包括了每一对两两连接的路径。这样,在树的第k层给出k个表执行join的最小代价的执行方式,那么递归地,在顶层(第n层)获得执行这n个表join操作的最佳查询方式。至此,就获得了查询n个表join操作的查询计划。
当然,我们不得不考虑的是,由于搜索最佳join方式的代价呈指数式上升,当参与join的表很多时(例如,超过10个),彻底地全局搜索最优join组合的代价会变得很大导致显著地降低系统性能。因此,我们退而求其次,使用概率搜索算法来代替全局搜索。这里,postgresql使用的是遗传算法。
3.6 non-SELECT语句的执行
什么是non-SELECT语句?简而言之,就是INSERT、UPDATE和DELETE语句。
1) 对于INSERT语句来说,其基本过程和SELECT语句是相似的,只不过最后的查询结果行不是返回到查询端,而是插入到表中;
2) 对于UPDATE/DELETE语句来说,查询计划模块会使用查询树的targetList项来存储选中的行,targetList项会被返回给executor模块的顶层来决定哪些行要被update/delete。
所以我们可以看出,对于查询计划模块和executor的大部分来说,所有的查询语句看起来都像是SELECT。只有顶层的executor会根据查询类型的不同有不同的操作。
小结
说了这么多,该总结一下了。对于postgresql的查询处理模块评价如下:
优点:
- 显而易见,系统可以自己分析决定去选择一个好的查询计划,而不需要人工协助。
缺点:
我们评价一个查询计划的好坏是基于系统的代价计算模型和历史的统计数据,代价计算模型本身不可能尽善尽美,有其自身的缺陷;再者,历史数据可能有时也不那么可靠。
凡事都有代价,生成一个查询计划也是要花费时间的。因此对一个频繁的重复查询而言,生成的查询计划的时间代价就会比较大。
以上就是《A Tour of PostgreSQL Internals》系列的全部内容了,欢迎大家讨论,有不对的地方还请各位批评指正。
对了,本篇随笔还参考了《PostgreSQl数据库内核分析》一书,在此对书的作者表示感谢,有兴趣的朋友可以查看这本书查看详细的解释与分析。
终于,《A Tour of PostgreSQL Internals》系列到此就要完结了,欠的债终于还清了,下面该干嘛?前面还有好多坑等我去填呢~
以上です