在PowerBI中提取IFC文件中的数据

推荐:用 NSDT编辑器 快速搭建可编程3D场景
在这篇文章中,我将逐步介绍从IFC文件中提取数据以创建 Shift IFC4PowerBI 函数的步骤。通过了解此工作流程,你能够更轻松地将 IFC 数据合并到自己的流程中。
在本文中,我们将重点关注文件中的元数据,但你也可以应用相同的逻辑来提取几何图形。 当然你也可以利用 NSDT 3DConvert这个强大的在线工具预览IFC几何模型(企业版可查看IFC属性数据并提供API)或者将IFC文件转换为GLTF、OBJ、STL等其他3D格式,而无需安装任何本地文件:

1、文件格式
关于 IFC 文件,首先要了解的是它们是文本文件,非常长且复杂的文本文件,但仍然是文本文件。 从数据的角度来看,这非常好,因为你通常会在建筑业遇到几种类型的本机文件:
- 基于文本的文件,例如 IFC 和 P6 XML
- 数据库文件,例如 Asta Powerproject 文件
- 二进制文件,例如 Revit 或 DWG
可以使用标准工具读取文本和数据库文件,并将其引入 PowerBI 等工具或合并到数据工作流程中,而二进制文件通常只能由其源工具或其他经过认证的工具进行解释。 这使得基于文本的文件格式成为长期存储的绝佳解决方案,因为我们不依赖特定的软件来稍后查询数据。 Microsoft 的免费 VSCode 是我打开文本文件的首选工具,但你始终可以使用记事本、notepadd++ 或任何其他工具。 下面可以看到Github 上的一个 IFC 文件部分的屏幕截图:

使用 IFC 语法插件在 VSCode 中打开 IFC 文件
IFC 文件以 EXPRESS 结构编写,该结构涉及一大堆使用行号相互引用的行。 有一些与该文件相关的序言,但数据的主要内容是 DATA;行之后的所有内容。
2、处理 IFC
第一步是使用以下 PowerQuery 将数据从简单行转换为 PowerBI 中的智能表:
let
Source = Table.FromColumns({Lines.FromBinary(#"IFC Binary", null, null, 1252)}),
// Split by Equal Sign
SplitByEquals = Table.SplitColumn(
Source,
"Column1",
Splitter.SplitTextByEachDelimiter({"="}, QuoteStyle.Csv, false),
{"Element ID", "Values"}
),
// Replace Single Quotes
ReplaceSingleQuotes = Table.ReplaceValue(
SplitByEquals,
"'",
"""",
Replacer.ReplaceText,
{"Values"}
),
// Trim Text
TrimValues = Table.TransformColumns(
ReplaceSingleQuotes,
{{"Values", Text.Trim, type text}, {"Element ID", Text.Trim, type text}}
),
// Filter Non-null Rows
FilterNonNullValues = Table.SelectRows(TrimValues, each ([Values] <> null)),
// Split by Open Parenthesis
SplitByOpenParenthesis = Table.SplitColumn(
FilterNonNullValues,
"Values",
Splitter.SplitTextByEachDelimiter({"("}, QuoteStyle.None, false),
{"Category", "Values"}
),
// Extract Data Before Close Parenthesis
ExtractBeforeCloseParenthesis = Table.TransformColumns(
SplitByOpenParenthesis,
{{"Values", each Text.BeforeDelimiter(_, ")", {0, RelativePosition.FromEnd}), type text}}
)
采取的基本步骤是:
- 加载 IFC 文件
- 使用 =符号作为分隔符分割每一行。 在此步骤中,包含 QuoteStyle.csv参数非常重要,以确保忽略行实际值中包含的任何 =。 这为我们提供了一列包含行号的列和一列包含该行内容的列。
- 将单引号替换为双引号,因为 PowerBI 理解引号的方式有点奇怪,这有助于我们稍后拆分数据。
- 修剪值可以帮助我们删除前导或尾随空格,以保持一切整洁。
- 过滤掉空值以可靠地删除与行数据无关的任何内容,你可以选择单独处理此标题数据。
- 从值字段中删除前括号和尾括号。
现在我们有一个可爱的干净数据集,显示行号、数据类别和该类别中的数据值。

由于我们希望以最有效的方式处理该文件,因此我们将稍微改变一下数据。

IFC 数据结构的非常简单的近似
由于 IFC 数据使用一对多方法,这意味着相同的参数可以应用于多个父项,因此从参数开始并返回到几何元素更有意义,而不是循环遍历每个元素并多次重新处理相同的参数。
// Filtering & Transformation for IFCPROPERTYSINGLEVALUE
FilterSingleValue = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each ([Category] = "IFCPROPERTYSINGLEVALUE")
),
SplitSingleValueDetails = Table.SplitColumn(
FilterSingleValue,
"Values",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
{"Property Name", "Property Description", "Property Value", "Property Unit"}
),
ExtractSingleValue = Table.TransformColumns(
SplitSingleValueDetails,
{{"Property Value", each Text.BetweenDelimiters(_, "(", ")"), type text}}
),
因此,我们将首先过滤所有 IFCPROPERTYSINGLEVALUE 行,然后从那里开始:
- 用逗号分割值(记住之前的 QuoteStyle.csv)以获取属性名称、说明、值和度量单位。
- 从“属性值”列中提取值,目前我们不担心值类型,但我们可能会在将来的版本中返回并检索它以帮助自动计算。
这给我们留下了一组很好的属性:
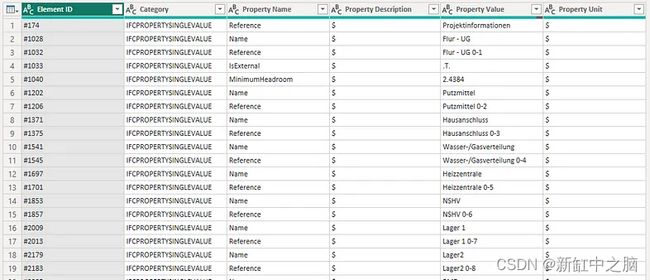
PowerBI 的有趣之处在于,我们现在可以一路回到第一步并从那里继续,将该表保留在内存中并稍后调用。 因此,接下来我们对 IFCPROPERTYSET 值执行相同的操作,最后合并到 IFCPROPERTYSINGLEVALUE 表中:
// Filtering & Transformation for IFCPROPERTYSET
FilterPropertySet = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each [Category] = "IFCPROPERTYSET"
),
ExtractPropertyID = Table.AddColumn(
FilterPropertySet,
"Property ID",
each Text.BetweenDelimiters([Values], "(", ")"),
type text
),
ExtractPsetName = Table.TransformColumns(
ExtractPropertyID,
{{"Values", each Text.BetweenDelimiters(_, ",", ",", 1, 0), type text}}
),
RemoveQuotes = Table.ReplaceValue(ExtractPsetName, """", "", Replacer.ReplaceText, {"Values"}),
ExpandPropertyID = Table.ExpandListColumn(
Table.TransformColumns(
RemoveQuotes,
{
{
"Property ID",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
let
itemType = (type nullable text) meta [Serialized.Text = true]
in
type {itemType}
}
}
),
"Property ID"
),
RenamePsetColumns = Table.RenameColumns(ExpandPropertyID, {{"Values", "Pset Name"}}),
JoinSingleValueAndPset = Table.NestedJoin(
RenamePsetColumns,
{"Property ID"},
ExtractSingleValue,
{"Element ID"},
"Properties",
JoinKind.LeftOuter
),
ExpandProperties = Table.ExpandTableColumn(
JoinSingleValueAndPset,
"Properties",
{"Property Name", "Property Value"},
{"Property Name", "Property Value"}
),
然后我们再做两次同样的事情,一直回到 IFCBUILDINGELEMENT和他们所有的子节点。
// Filtering & Transformation for IFCRELDEFINESBYPROPERTIES
FilterRelDefines = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each [Category] = "IFCRELDEFINESBYPROPERTIES"
),
ExtractObjectID = Table.AddColumn(
FilterRelDefines,
"Object ID",
each Text.BetweenDelimiters([Values], "(", ")", {0, RelativePosition.FromEnd}, 0),
type text
),
ExtractPsetID = Table.TransformColumns(
ExtractObjectID,
{{"Values", each Text.AfterDelimiter(_, ",", {0, RelativePosition.FromEnd}), type text}}
),
RenameForRelDefines = Table.RenameColumns(ExtractPsetID, {{"Values", "Pset ID"}}),
ExpandObjectID = Table.ExpandListColumn(
Table.TransformColumns(
RenameForRelDefines,
{
{
"Object ID",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
let
itemType = (type nullable text) meta [Serialized.Text = true]
in
type {itemType}
}
}
),
"Object ID"
),
JoinRelDefinesAndPset = Table.NestedJoin(
ExpandObjectID,
{"Pset ID"},
ExpandProperties,
{"Element ID"},
"Property Sets",
JoinKind.LeftOuter
),
ExpandPropertySets = Table.ExpandTableColumn(
JoinRelDefinesAndPset,
"Property Sets",
{"Pset Name", "Property Name", "Property Value"},
{"Pset Name", "Property Name", "Property Value"}
),
// Final Join and Expansion
JoinMain = Table.NestedJoin(
ExpandPropertySets,
{"Object ID"},
ExtractBeforeCloseParenthesis,
{"Element ID"},
"Model",
JoinKind.LeftOuter
),
ExpandModel = Table.ExpandTableColumn(
JoinMain,
"Model",
{"Category", "Values"},
{"Ifc Type", "Values"}
),
FinalSplit = Table.SplitColumn(
ExpandModel,
"Values",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
{"GUID"}
)
in
FinalSplit
剩下的最终表是每个属性引用其所有父项,一直到 IFC 元素的 IFCGUID。
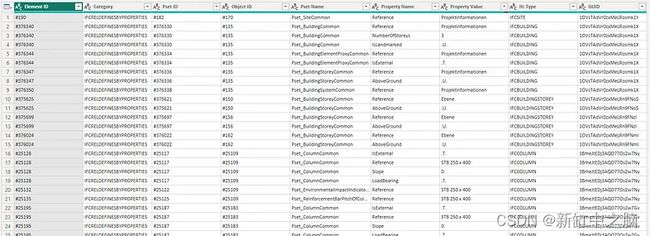
此时,你可能想知道为什么我们有一个很长的属性列表,而不是每个项目单独一行,并在列中包含各种参数。 有几个原因:
- 它可能会导致无限数量的列,具体取决于 IFC 文件
- 不能再将属性集合并到数据集中
- 过滤和利用仪表板内的数据要容易得多
发布项目涉及的最后一件事是使用 PowerBI 中的 let指令将其转换为函数:
let
Source = (#"IFC File" as any) => let
// REST OF THE CODE GOES HERE
in
FinalSplit
in
Source
原文链接:PowerBI提取IFC数据 — BimAnt