人机共生时代,分布式机器学习是如何加速的?

导语 | 机器学习技术在现代社会中发挥着越来越重要的作用,深刻地影响着各行各业。同时,也面对着海量数据和复杂问题的挑战。今天我们主要讨论分布式机器学习技术是如何处理海量数据,利用海量算力加速训练,使得机器学习过程变得越来越快的。
一、前言
近些年来,人工智能技术,尤其是机器学习技术在众多领域都发挥了越来越重要的作用,每个人一天的生活中都在不断地与其打交道。不论是打开短视频App浏览关心的新闻或八卦,还是打开购物App逛一逛,甚至只是打开手机也需要用到人脸解锁,机器学习技术已经完全融入了每个人的生活当中。

图1 使用人脸解锁手机
很多传统的机器学习问题在被不断解决,或者是解决得越来越快,越来越好。包括我们公司内的世界各个团队在ImageNet数据集上不断地降低训练时间,刷新世界纪录。同时,深度强化学习技术在决策智能上进一步迈进,不断地在各种复杂的游戏场景中达到或者超越了人类的专业选手的水平,例如围棋项目中的AlphaGo,Dota游戏中的OpenAI Five,星际争霸游戏中的AlphaStar等,并且,在这些复杂游戏上的训练时间也能够逐渐缩短。
那么机器学习是如何取得这样的成就的呢?一般认为,其主要由于算法,算力,数据三方面的共同作用而来,如图2所示,更多的数据+更强大的算力+适当的算法 ,往往就能得到更好的表现。算力方面,硬件本身性能不断取得进步,单个机器的计算性能越来越强,网络带宽也在增长,然而相对于数据的爆炸式增长和其所期待的计算能力而言,单个机器的算力是远远不够的。因此,利用分布式来解决算力问题的技术在学界和工业界均得到了充足的重视和发展,具体到机器学习而言,则发展出分布式机器学习这一领域,以更好地利用海量算力。
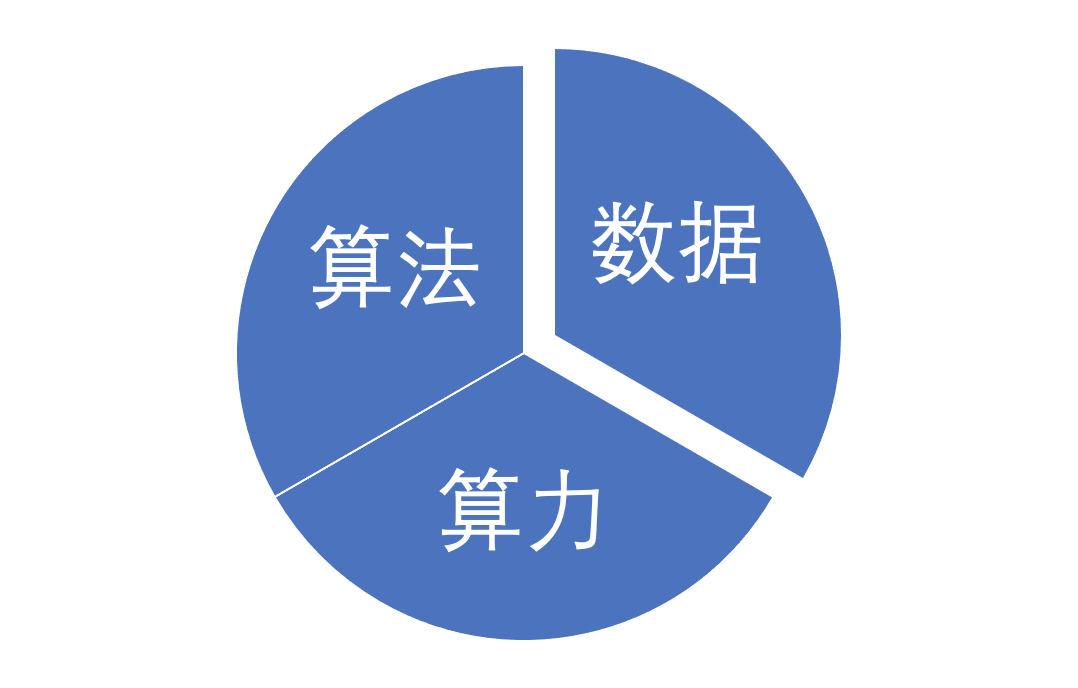
图2 当代机器学习发展三要素
二、分布式机器学习概览
整体上说,分布式机器学习系统需要将大模型或是大数据划分,再分配到不同的机器上进行计算优化,单机的优化结果再通过通信模块进行汇总。不同的系统也根据不同的场景和目标对如何划分模型/数据,单机如何计算优化,如何通信,如何聚合进行了调整,如图3所示。
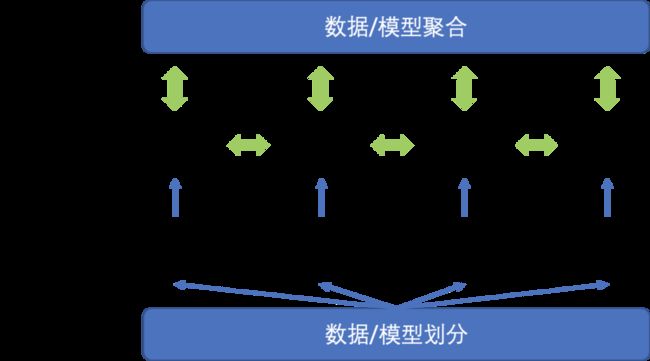
图3 分布式机器学习系统框架
通常而言,数据并行的目的是为了加速训练,而将原始数据分配到不同的worker上并行训练。其中,每一个worker使用不同的部分数据,但是都拥有完整的模型(否则就是模型并行),woker之间一般会同步自己的局部梯度信息,再进行汇总,得到整体的更新结果。而模型并行则有所不同,其一般是由于模型太大,单机无法储存,而采取的将模型的不同部分放在不同的worker上进行训练的方式,常用的方式是每一个worker均使用相同的数据,但是只使用模型的一部分来进行,如图4所示。本文后续所陈述的内容大多以数据并行的视角为主。
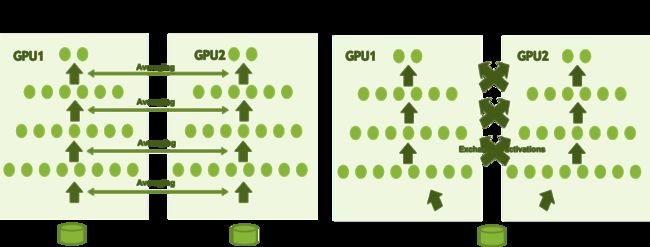
图4 数据并行与模型并行
不幸的是,随着机器数量的增加,其所带来的加速效果可能会越来越差,比如,增加了十倍的机器,理想训练速度能够增加十倍,实际上往往却只增加了一两倍,性价比很低。这实际上是因为机器资源不仅是用于计算,也用于IO和通信。
如之前所说,分布式机器学习中各个worker还需要对梯度信息进行同步,而随着机器数量的增多,通信的开销也会逐渐增大,导致最终的加速比不符预期。因此,期望能够提高加速比,使得分布式机器学习可以更快,就需要降低通信和IO时间开销,提升计算的时间占比,同时,加快计算性能才可以做到。
业界和学界也是在这些方面进行了优化,下图展示了其中的部分内容,通信上,一方面提升通信速度,比如通信拓扑的改进,通信步调和频率的优化,另一方面也可以减少通信内容和次数,比如梯度压缩和梯度融合技术等。IO上,通过代码优化,减少IO的阻塞,尽量使得IO与计算可以overlap。计算上,一方面,可以进一步地优化单机的计算性能,比如图/OP优化,编译器优化等,另一方面,分布式带来了大batch size上的优化问题,又需要解决。当然,这些方面的问题,都或多或少的可以在硬件层面进行一定的优化,比如更大的带宽,降低通信延迟,本文后续不对硬件部分进行讨论,上面所说的优化路径汇总如图5所示。
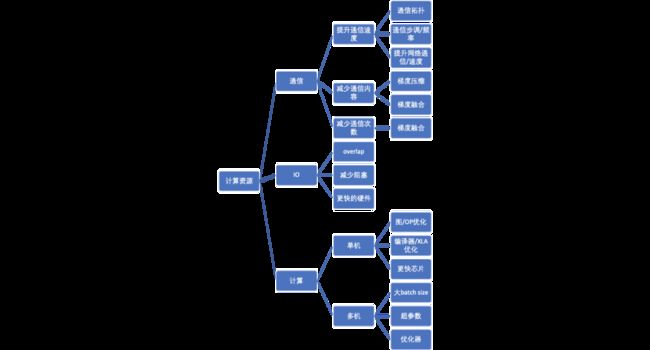
图5 加速分布式机器学习的可能路径
三、通信优化
(一)常用通信原语
第一类通信方式是点对点(point-to-point)通信,这是高性能计算(HPC)中最常使用的模式,通常是与其最近的邻居进行通信,每个实例都是单发送方,单接收方,如图6所示。
图6 点对点通信
第二类通信方式被称为集合(collective)通信,其主要是存在多个发送方和接收方,这里介绍其中的几个常用的通信原语。
Broadcast的方式中,有一个发送方,和多个接收方,即将一方的信息广播到其他所有接受方中去,如图7所示。
Scatter的方式中,有一个发送方,多个接收方,但是发送方中的数据会被切分,然后分散在各个接受方中去,如图8所示。
Gather的方式中,有多个发送方,一个接收方,其是Scatter的反过程,将分散在各个发送方中的数据汇总集中到一个接受方中去,如图9所示。
All-Gather的方式,则是在Gather的基础上更进一步,不仅汇总了信息,还将此信息发送给所有接受方。如图10所示。
Reduce的方式中,有多个发送方,一个接受方,其是合并来自所有发送方的数据,再将结果传递给接收方,如图11所示。
All-Reduce又在Reduce的基础上进一步地将合并后的数据发送给了所有的接收方,如图12所示。
Reduce-Scatter则是一方面合并来自所有发送者的数据,另一方面又在参与者之间分配结果,如图13所示。

图7 集合通信之broadcast

图8 集合通信之scatter
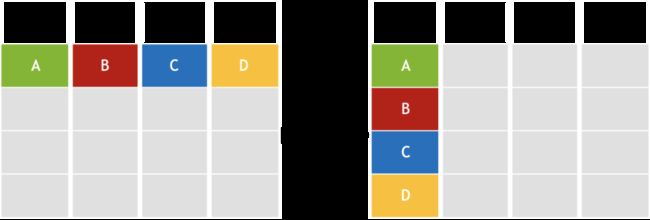
图9 集合通信之gather
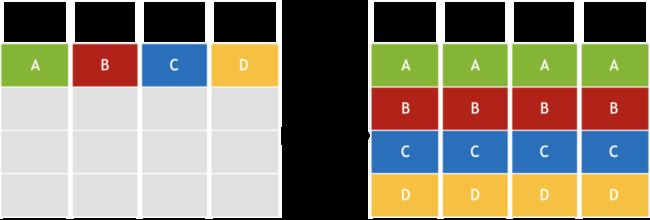
图10 集合通信之all-gather

图11 集合通信之reduce

图12 集合通信之all-reduce
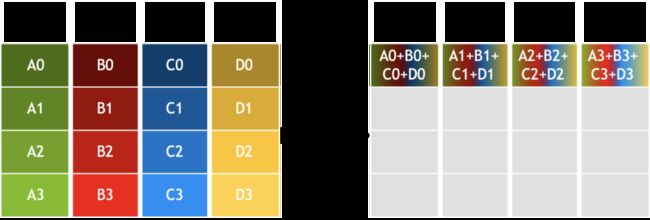
图13 集合通信之reduce-scatter
(二)参数服务器(Parameter Server)
参数服务器的概念最早大概可以追溯到Alex Smola于2010年提出的并行LDA的框架,其采用一个分布式的Memcached作为存放参数的存储,用于在分布式系统不同的Worker节点之间同步模型参数,而每个Worker只需要保存它计算时所依赖的一小部分参数。
在此之后,PS又有了很多改进,其中又以李沐2014年提出的ps-lite(所谓第三代PS架构)为主要代表,也进一步加快了业界广泛使用参数服务器的步伐,在广告,推荐等各领域内大放异彩,时至今日,依然在各大公司内发挥着重要作用。
ps-lite的主要架构示意图如图14所示。其中,resource manager用来对当前的各个计算资源进行管理,可以直接利用资源管理组件如yarn、mesos或者k8s来实现,而底下的training data就是用来采集训练数据,在大规模场景下,一般需要类似GFS的分布式文件系统的支持,剩下的server group和worker group部分就是参数服务器的核心组件了。
Paraeter Server框架中,每个server都只负责分到的部分参数(server共同维持一个全局共享参数)。server节点可以和其他server节点通信,每个server负责自己分到的参数,server group 共同维持所有参数的更新。server manage node负责维护一些元数据的一致性,例如各个节点的状态,参数的分配情况。worker节点之间没有通信,只和对应的server有通信。
每个worker group有一个task scheduler,负责向worker分配任务。一个具体任务运行的时候,task schedule负责通知每个worker加载自己对应的数据,然后去server node上拉取一个要更新的参数分片,用本地数据样本计算参数分片对应的变化量,然后同步给server node;server node在收到本机负责的参数分片对应的所有worker的更新后,对参数分片做一次update。
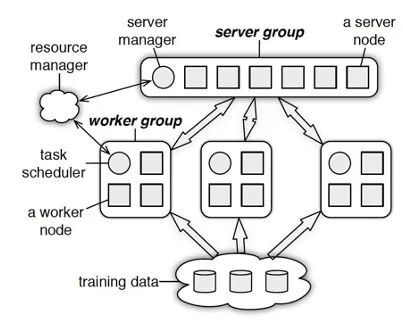
图14 ps-lite主要架构图
从通信视角上看,其是一种比较朴素直观的算法过程,可以看成是reduce+broadcast的过程,先是将worker上的信息reduce到server节点上,之后server节点汇总了信息后,再broadcast到worker节点上去,完成了一次信息的处理过程,如图15所示。在这个结构中也能看到,worker之间不通信,而全部依赖于server节点,worker之间的通信能力未得到充分利用, 并且是单工通信,没有同时利用上行带宽和下行带宽,当参数非常稠密,需要通信的信息比较时,server节点有可能成为瓶颈。
但是如果参数是高维稀疏,单机无法保存全部参数,且每个worker无需访问全部的参数的情况,如推荐中的百亿级feature的LR,LDA,小数据量的通信延迟较低,加上PS架构支持异步更新,可以减少阻塞,加快训练速度。粗略地说,原始的PS架构更适合稀疏超大模型,且更容易容灾,也因此在推荐领域内广泛应用。
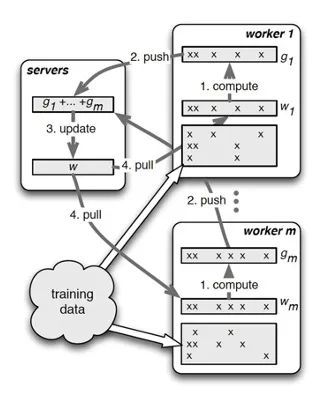
图15 ps-lite运行过程
(三)Ring AllReduce
PS架构虽然在很多领域内大放异彩,应用广泛,但是当模型稠密,需要大量交换信息的情况下,Server节点很容易成为瓶颈,限制了其作用,也因此有了将Ring AllReduce这一类通信方法应用到机器学习领域的尝试。
实际上,Ring AllReduce算法在高性能计算领域中已经有了比较长的历史,OpenMPI中至少在2007年就有了关于其的开源实现。然而机器学习领域内的对此知之甚少,更加不知道怎么利用其来加速分布式机器学习的速度。直到2016年,百度的研究人员首次尝试将Ring AllReduce算法应用到深度学习领域内,并在很多问题上取得了明显比PS架构更显著的加速效果,在深度学习领域取得了广泛的关注。
正如名字中所表达,Ring AllReduce算法首先需要将集群内各个节点按照环状的形式排列,在这个环中,每一个节点都只接收其左邻居节点的信息,且都只发送信息给自己的右邻居节点。在具体的通信内容和方式的组织上,大概可以分为两部分,第一部分,对于N个节点的集群,将每个节点上数据切分为N份,然后经过N-1轮的Reduce-Scatter过程。具体地,每一轮中,每个GPU将自己的一个chunk发给右邻居,并接收左邻居发来的chunk,并累加,经过这样的步骤,每一个节点都拥有一部分数据的最终结果。第二部分,与上部分相类似,进行N-1轮的AllGather过程,将每一个节点上的一部分的完整信息传递到所有节点上,经过此步骤,每一个节点上就拥有了所有数据的完整信息,如图16所示。

图16 Ring AllReduce运行过程
我们粗略地计算上述Ring Allreduce的时间开销。我们以α表示一次通信的latency,其表示的是信号在两点之间的介质上传输所需的时间,以S(ize)表示要传输的数据块大小,以B(andwidth)表示要通信的两个节点之间的带宽,以一群人过桥为例,延迟α是一个人从桥这头走到那一头的时间,而S/NB则是数据排队上桥的开销,显然,桥越宽(带宽越大), 最终的时间开销就越小。根据上面所述,总共两部分的传输过程,每部分均有N−1轮,则总的时间开销为2∗(N−1)∗[α+S/(NB)], 当N较大时,2∗(N−1)/N∗S≈2∗S,即最终的时间开销与节点个数无关,只与数据大小相关,这个优良的特性保证了其很好的扩展性。
基于上述优化,英伟达公司开发并发布了集合通信库NVIDIA Collective Communications Library (NCCL), 读作nickle。作为硬件厂商,他们可以做更多优化,包括根据当前集群中的硬件环境,显卡型号,通信方式等进行适配,比如建立性能更好的环状通信。更进一步地,他们也引入了其他的通信拓扑结构,比如tree-based的通信,并根据当前集群中的硬件属性和节点个数等来决定采取何种通信拓扑等。在此基础上,Uber公司与英伟达公司合作,在NCCL基础上,推出了Horvod这一分布式深度学习框架,可以支持TensorFlow, Keras, PyTorch, an以Apache MXNet,以对用户更加友好的方式来加速分布式训练。以Tensorflow为例,只需要简单的加入几行代码,就可以使用Horvod,如下所示,Horovod目前在学界和业界也越来越被广泛使用。
cimport tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
(四)减少通信内容——梯度压缩
为了进一步地加快训练速度,减少通信时间,一个可能的方向就是对通信的内容即梯度进行压缩。梯度压缩里有两大类主要的方案,一是梯度量化的方法,二是梯度稀疏化的方法。
模型量化等技术在模型推理上发展的相对成熟,也已经有很多成功的应用,可以有效的减少模型尺寸,降低模型推理成本。然而,在训练中,目前还不能做到直接用很小的或是量化的模型进行训练,其往往会导致训练的效果变差,达不到预期的效果。因此一些研究人员从梯度着手,期望能够在不改变模型本身大小和性能的情况下,降低梯度通信的时间。默认情况下,梯度是用32比特的浮点数来表示,梯度量化就是用更低的精度来表示梯度的方式降低梯度通信的开销。
基于误差补偿机制的1-bit SGD是梯度量化领域内比较有代表性的工作,其是由微软亚研的研究人员们在2014年发表的。1-bit SGD的思路也比较简单,就是直接用1-bit来表示传统的梯度,且直接用0来作为量化的阈值,可以认为其只保留了梯度中的方向信息,而减少了梯度的具体数值信息,再使用一般的SGD方法来进行优化。当然,为了减少梯度损失的影响,他们也引入了两个技巧,一是使用误差补偿机制,以减少梯度误差逐渐放大,二是在训练初期,仍然使用完整的浮点精度的SGD来进行预训练,再之后才转用1-bit SGD进行训练,以使得训练更加稳定。
在1-bit SGD后,又有了Terngrad量化的方法。相对于1-bit SGD,其主要区别是会将梯度量化为-1,0,+1三个值,并且通过加入随机的二元向量的方式引入更多的随机性。具体地,其梯度量化的公式是gt′=ternarize(gt)=st∗sign(gt)∗bt,其中,st是梯度值的范围,即wt=max(abs(gt)),而bt则是随机的二元向量。除此之外,其会对每一层layer的梯度做三元化处理和梯度裁剪方法。实际过程中,对每一层采用不同的缩放因子,同时区分权重和偏置。经过上述处理后,Terngrad量化在一些问题上的精度下降已经很少,甚至没有损失,但是其通信开销得到了16+倍的提升,如图17所示。
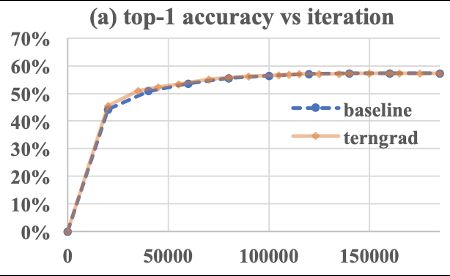
图17 Terngrad量化的效果
除了梯度量化外,另一类梯度压缩的方法就是梯度稀疏化,其主要思想就是在通信时只通信少部分重要的(大的)梯度,而其他的则不通信,累加到下一个迭代中去。Gradient Dropping是梯度稀疏化领域中的一个代表性工作,其主要做法是通过设定梯度丢弃的比例Drop ratio,再通过计算找到满足需要丢弃的梯度的阈值Threshold,来对梯度进行稀疏化,未通信的梯度会累加到下一次迭代,如图18所示。
Drop ratio的选择方面,他们比较了90%, 99%, 99.9%的区别,99.9%的情况下,loss曲线还是呈现下降趋势,但是会收敛到一个比较差的结果,而99%的drop比重不会带来太大的影响,通信数据降低了50倍,如图19所示。另外,通过layer normalize(层归一化)的方法,把每层的参数归一化到一个范围,然后选取drop比重,从而确定阈值,这样对每层网络都可以保留原始的泛化能力,从而有利于收敛性。

图18 Gradient Dropping算法流程
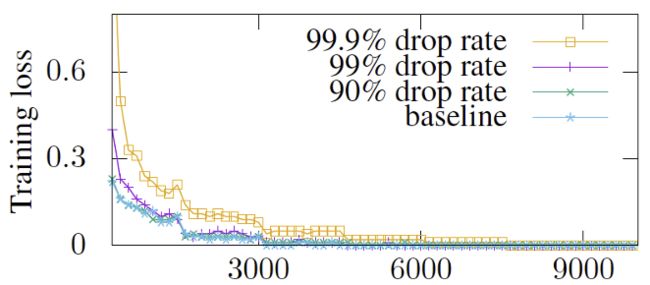
图19 Gradient Dropping中不同Drop Ratio的影响
Deep Gradient Compression则进一步地通过各项技巧来降低了梯度稀疏化后的精度损失,相对于Gradient Dropping而言,其增加了Momentum Correction, Local Gradient Clipping, Momentum actor Masking,以及Warm-up Training等技术。通过这些技术,进一步地降低了精度损失,在不少数据集上都达到甚至超过了原始baseline的表现,如图20, 图21所示。
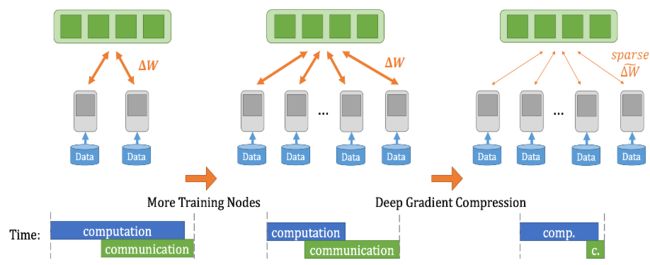
图20 Deep Gradient Compression的流程图
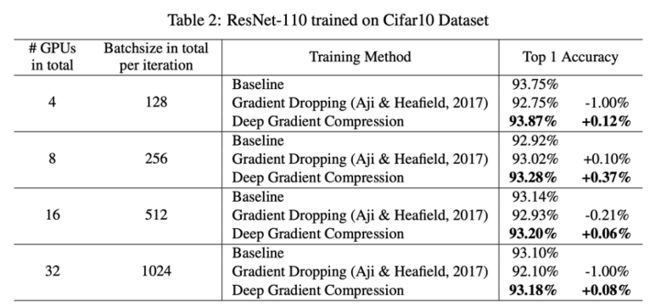
图21 Deep Gradient Compression在RestNet-110上的效果比较
四、IO优化
(一)机器学习上的IO问题
机器学习系统中,通常需要先加载处理样本,再利用样本进行训练,当样本不够时,会阻塞等待,batch size变大时,其阻塞时间也会变长,如图23所示。更进一步地,多leaner分布式训练时,同步训练的整体进度会由最慢的learner决定(木桶效应)。这就使得,如果IO上优化的不好,就会导致大量的昂贵GPU资源空载,算力没有被充分利用,其利用率可能会偶尔到很高,而很多时候在很低的水平,如图22所示。

图22 IO没有优化好的GPU利用率变化情况
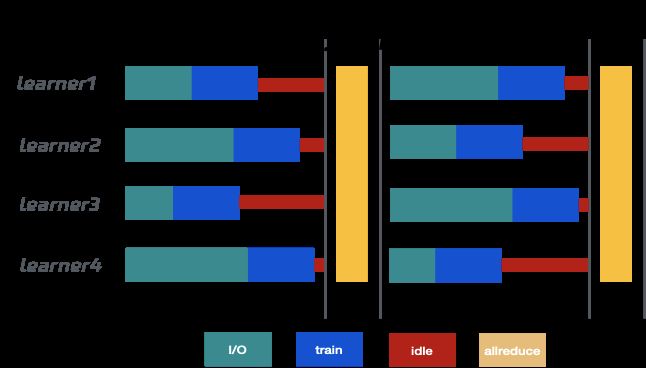
图23 IO与计算的交叉情况
(二)监督学习上常用的IO优化
针对IO方面的优化,对于监督学习而言,目前已有一系列的处理方案,比如通过数据预取和缓存prefetch,比如通过并行处理的方式(num_parallel_calls),以及尽量使tf.record,tf.data减少sess.run, placeholders的方式来优化IO,使得计算与IO可以尽量多地overlap,以提升算力的应用。
(三)强化学习平台Avatar上的部分IO优化
与监督学习不同的是,强化学习中的样本需要主动地通过交互而来,这也就带来了更多更复杂的IO问题。Avatar就是一个公司内开源的大规模分布式强化学习平台,其已经可以支持包括MOBA,FPS,动作格斗,竞速等各种品类的游戏AI的研发,其在IO优化上也做了很多的工作,这里简单阐述其中的部分内容。
一是通过大量的处理来优化内存,包括通过snapp快速压缩解压样本,通过bytesarray预先分配buff池,通过memoryview避免内存拷贝,利用tcmalloc优化python内存管理等。
二是对于大量的计算逻辑进行优化,以降低样本处理的时间,对样本处理相关模块进行重构,向量化处理并且从trainer中解耦,利用Connectors多进程多cpu优势并行处理。
三是自定义ZMQ Op,包括C++实现ZmqConnectionHandleOp和ZmqPullOp,注册&编译成.so,Python实现ZmqPullSocket包装类加载so并暴露pull接口(返回op)供python侧构建tf graph。
四是TF多线程、多核调度ZMQ Op,包括TF QueueRunner和TF Coordinator用多线程来衔接zmq_op和后续其他依赖op,并发拉取数据,以及Trainer预处理剩余逻辑全部使用tf op来并行处理。
五是自定义实现Replay Buffer,进一步地满足数据预取功能和算法上的其他需求。通过上述处理后,Avatar上的IO和计算可以实现更多的重叠,如图24所示,训练速度变得更快。同时,Leaner(GPU)的资源利用率得到了极大的上升,能够达到90%以上,如图25所示。
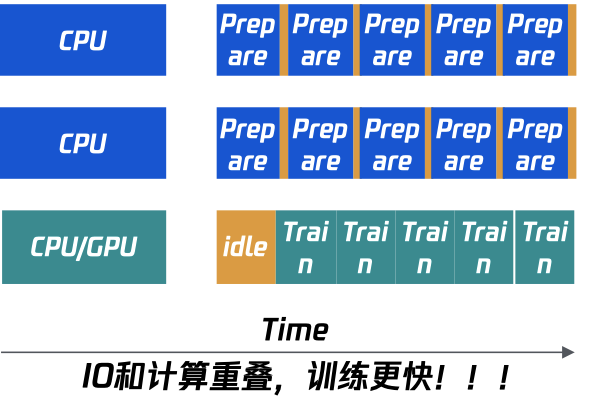
图24 IO与计算的尽量重叠
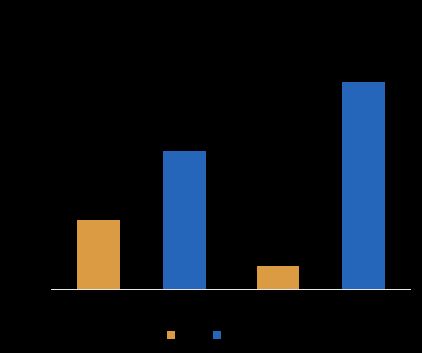
图25 IO优化前后资源利用率情况
五、计算优化
(一)分布式可以加速?
利用分布式机器学习训练模型,算法层面上的一个主要区别是,多个节点并行会使得实际的batch size变大,比如单机的batch size是B,则N卡同时计算的batch size就变成了N∗B,这会给训练优化过程带来一些改变。
以单机上的batch size变大的影响为例,在ImageNet-1K数据集上训练AlexNet模型,可以发现随着batch size变大,其训练速度会逐渐变快,其中的一个原因是,大batch size减少了通信和IO的时间和次数,计算的时间占比会增加,且减少了迭代次数,如图26所示。以具体的案例来考察多机扩展的情形,假设单卡上的batch size为512,总的Epochs固定为100,即总的浮点数计算次数相同,以公平可比,此种设定下总的迭代步数为250000。如果将此扩展到分布式训练环境,则N卡情况下,总的batch size则会变成N∗512,相应地,其迭代次数会变成250000/N。单次迭代的时间开销会有所增加,但是相应的迭代次数大大减少,这就带来了训练的加速,如图27所示。
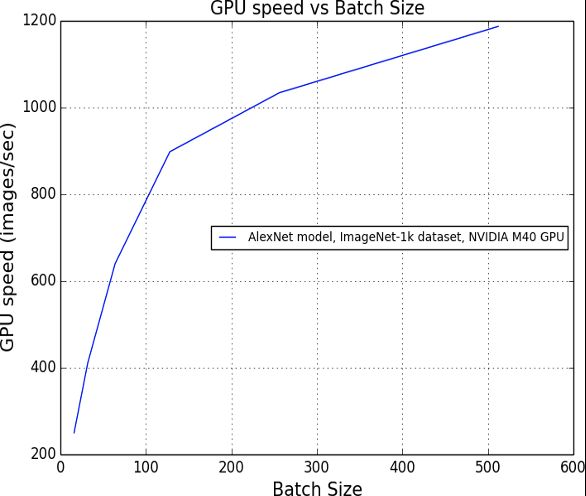
图26 单个GPUAlexNet训练速度与batch size的关系
图27 不同GPU个数下训练时间的可能变化
(二)分布式带来的大batch size优化问题
在上部分内容中,关于分布式加速的论述中,只考虑了将样本计算完的时间开销,理想情况下,训练精度不变,也就自然带来了加速。然而,当我们真的直接去利用分布式来加速训练时,不幸的发现,随着batch size的增大,训练出现了明显的精度降低如图28所示。
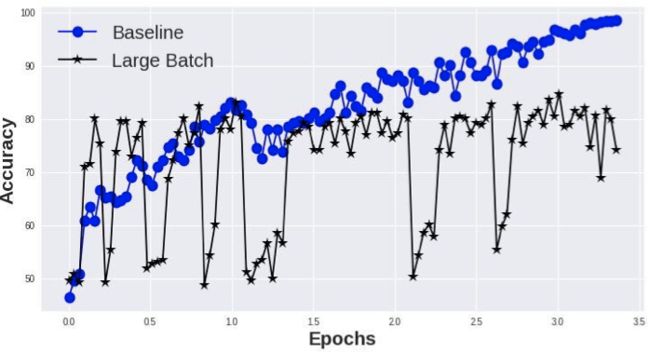
图28 大batch size导致精度降低
那么,为什么大的batch size会导致精度损失呢?有一些工作在进行探讨和寻找解决办法。
其中一个可能的原因是,大的batch size会带来泛化性变差的问题,这可能主要是由Sharp Minimum导致的。小batch size训练时,其对应的曲线更接近于Flat Minimum的结构,而大batch size训练时,则更接近于Sharp Minimum的结构。假设我们训练时都得到了很好的结果,在Flat Minimum的结构下,训练集与测试集上的结果差异较小,而在Sharp Minimum下,则会有非常大差异。
而Facebook的一个工作则认为,大batch size也可以不损失精度,只是由于分布式带来的各种不同,使得需要调整各种参数,并且,在很多情形下,分布式的训练精度就已经出现降低,而不仅仅是测试集上才出现,也就是说,泛化性问题的解释是不够的,实际上这是优化难度问题。因此,他们尝试在分布式环境中进行调整,并且,最终令人欣喜的是,他们的实验中,batch size增加到8K,利用256块P100,训练时间降低到1小时,而精度几乎没有降低,如图29所示。
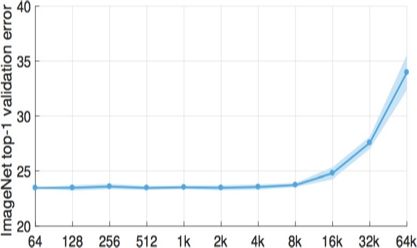
图29 Facebook参数优化后的效果
(三)训练参数调整优化
那么,Facebook上面的工作中是做了哪些事情来提升大batch size训练的精度的呢,这里主要介绍其中的两个重点的内容。
第一个是采取了Learning Rate Linear Scaling的技术,其出发点是当batch size从B增加到kB时,在总的Epochs不变时,其总的迭代次数则会减少k倍,那么,在learning rate η不变的情况下,模型参数变化的幅度显然是要比之前少了很多的,因此提出了也将η乘以k来进行线性扩大,以提升训练速度。当然,在后续的一些工作中,也有在其他的优化器中采用例如平方根来进行放缩的方式。
第二个是采用了Warmup Rule的技术,其主要的出发点是在经过上述的学习率放大后,在初始训练时,非常容易出现不稳定的现象,导致最后很难收敛。因此,他们在刚开始训练时,仍然从比较小的η开始,再逐渐增大,训练了一定的Epochs以后,再按照上述的kη的方式进行训练。在此之后,也有一些工作在训练的后期逐渐降低学习率,被称之为learning rate decay,也被广泛应用,使得后续训练更加稳定收敛,如图30所示。
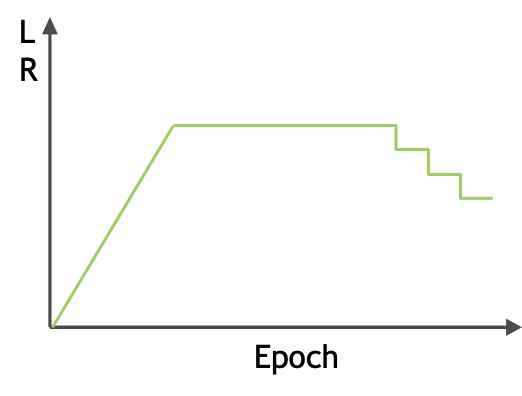
图30 learning rate的变化
(四)LARS优化器
即使在经过了上述优化后,AlexNet模型训练在分布式训练上仍然有比较明显的精度损失,难以解决。其中存在着比较多的原因,一个原因是目前深度学习的参数更新没有考虑不同层的差异。
具体地,深度学习中使用的优化器均是SGD及其相应的变体算法,即在每一次更新参数时,使用的是W=W−η∇L(W)或其他接近的变体。很显然,在这种更新公式下,W和∇L(W)的大小会对更新有很大影响,|W|/|∇L(W)|太大情况下,太小则参数很难有更新,另一方面,如果η设定为相对大的值,那么对于某些|W|/|∇L(W)|层,此次梯度更新的作用太大,从而导致网络过于震荡。如图30所示,第六层是全连接层,其权重w的|W|/|∇L(W)|为1345,而第一层为卷积层,其权重为的|W|/|∇L(W)|为5.76,差距十分巨大,此时对于第六层来说比较好的η对于第一层来说可能会导致发散[20, 21]。
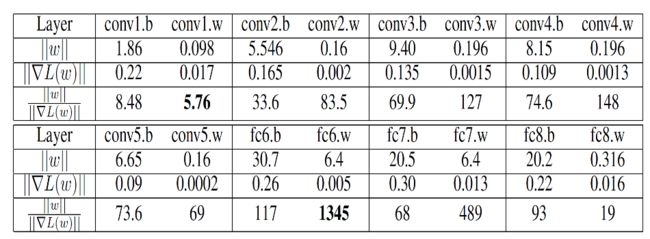
图31 不同层中|W|/|∇L(W)|情况
基于上述问题,就有了LARS优化器,如图32所示,其主要就是利用网络中每一层的权重和相应梯度的l2 Norm的比例来对学习率η做逐层的修正,得到layer-wise learning rate,即η=I×γ×||W||2||∇L(W)||2。另外,其默认是基于Momentum优化器,再与Weight Decay方法结合,即得到了LARS优化器。使用LARS优化器,继续在ImageNet上数据集上训练AlextNet,随着batch size扩大到8K及以上,其预测精度依然没有明显下降,如图33所示,并使得训练时间下降到了分钟级。

图32 LARS算法流程
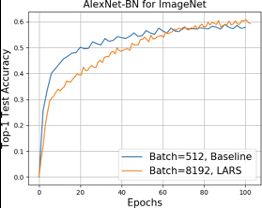
图33 LARS算法在AlexNet上的效果
(五)LAMB优化器
LARS优化器虽然在ImageNet数据集上的训练,以及相应的AlexNet,ResNet上取得了明显成功,使得分布式训练的扩展比大大增加,然而,不幸的事,当将其应用到NLP领域经常使用的Bert模型上时,其扩展比还是不很理想,在batch size增加到8K以后,预测精度明显变差,如图34所示。
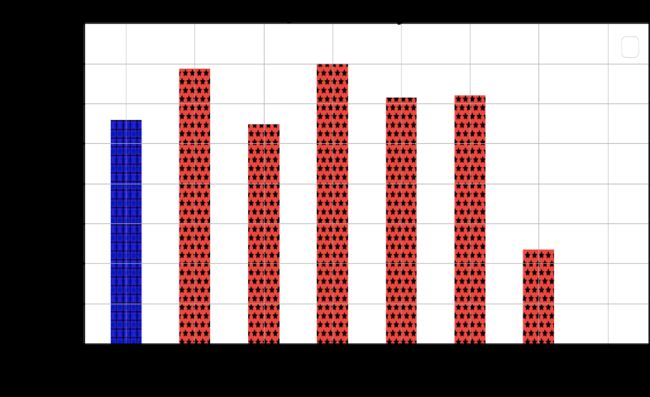
图34 LARS算法在Bert上的效果
为了进一步地解决这个问题,使得在Bert这样的更大的模型上依然可以提升扩展比,就有了LAMB优化器,如图34所示。可以粗略地认为,其主要是将Adam这样一种针对每个参数计算自适应学习率的方法与LARS这样一种在Layer层次上针对学习率做修正的方法进行结合,算法过程如下图35所示。
其与Adam算法相比,只有红框内不同,红框内实际上与LARS相似,在做layer-wise的学习率修正,即根据当前layer的参数与参数的梯度的比值进一步使得学习率更加准确。基于LAMB算法,同样地训练Bert,结果如图36所示,当batch size扩大到32K后,精度依然没有明显损失,后续由于硬件上无法继续扩大batch size才没有继续测试。并且,32K的batch size实验中,64倍的资源,获得了49.5倍的加速比,相对于ImageNet的训练加速比会小一些,但是相对于之前的工作也有了显著增加。

图35 LAMB算法流程
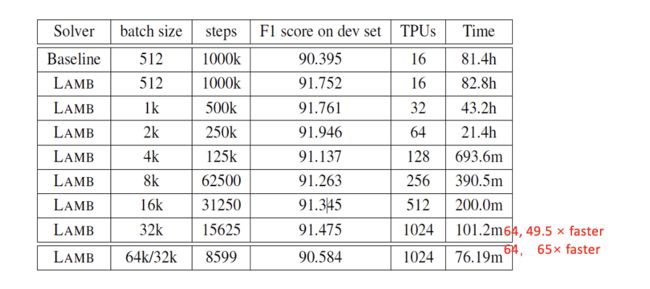
图36 LAMB算法在LAMB上的加速效果
在此之后,各家公司基于LARS优化器,结合其他的各种改动,在ImagetNet数据集上的训练时间不断缩短,世界纪录不断被打破,比如有:
Jia et al. (Tencent, August of 2018)
75.8% accuracy in 6.6 minutes (2048 P40 GPUs)Mikami et al. (Sony, Nov of 2018)
75.03% accuracy in 3.7 minutes (2176 v100 GPUs)Ying et al. (Google, Nov of 2018)
76.3% accuracy in 2.2 minutes (1024 v3 TPUs)Yamazaki et al. (Fujitsu, March of 2019)
75.08% accuracy in 1.2 minutes (2048 v100 GPUs)
六、业界分布式平台
业界在分布式机器学习方面均投入了很多研究和开发人员,在整体的研发路径上覆盖了包括本文内容在内的更加丰富的内容。如图37所示,百度的PaddlePaddle在很多方面进行了优化,通信组件库除了NCCL2外,还增加了GRPC,BRPC等,并且对于通信方式/拓扑,IO以及算子等都进行了加速优化。快手开源的分布式通信库则是期望能够将中心化/去中心化,同步/异步等通信的方式统一起来,并从理论着手证明其收敛性,也在很多数据集的训练上取得了很好的效果。公司内的机智平台也同样在通信,IO,计算等方面均进行了细致的优化,以提升训练速度,并支持了公司内很多业务团队。
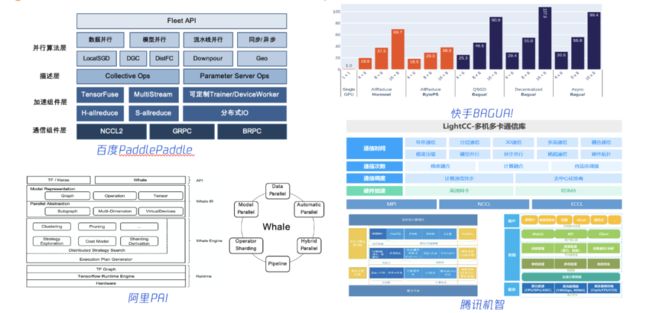
图37一些业界机器学习平台
相对于传统的分布式机器(监督)学习系统而言,分布式强化学习系统则更加复杂,其不仅需要考虑如何训练样本,还要考虑如何产生样本,在系统的性能方面会遇到更多的挑战。如图38所示,学界经常使用的是Ray以及基于其封装的RLLib,谷歌的博客上阐述了他们的分布式强化学习系统Menger的系统框架,以及相应的性能数据,但是并未开源。
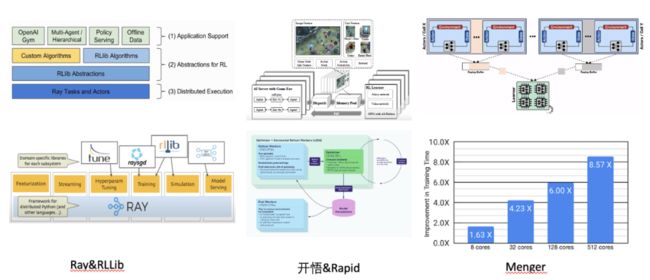
图38 一些强化学习学习平台
公司内开源的Avatar就是一个大规模分布式强化学习平台,其针对上述各个环节进行了优化,目前在OpenAI的Dota2模型(OpenAI Five)上进行测试,其性能已经达到了业界领先水平,如图39所示,并在继续优化中。同时,其已经支持了公司内各大工作室群的MOBA游戏,FPS游戏,动作格斗游戏,赛车竞速游戏等各品类游戏AI研发,均取得了满意的效果。除了训练系统以外,Avatar上还开发了数据分析/展示系统,模型管理系统,评估系统,上层调度接口,League训练等周边系统,如图40所示,以更好更快地开发游戏AI。
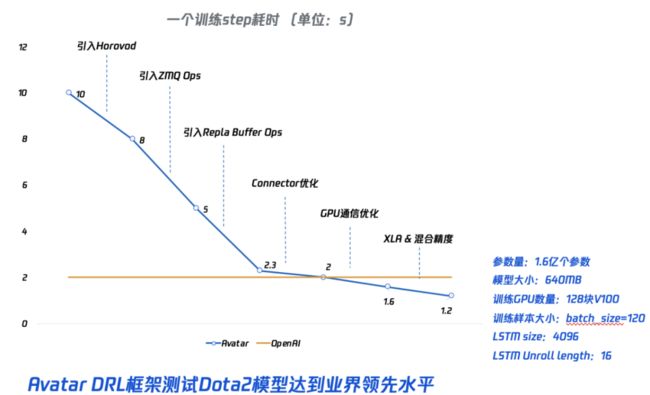
图39 Avatar上的训练加速效果
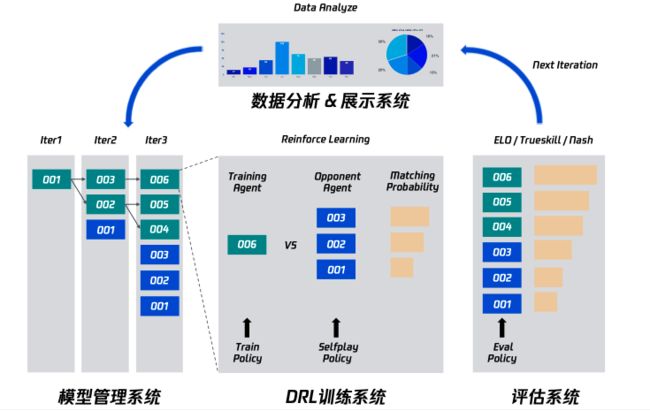
图40 Avatar上的多系统集成情况
参考资料
1.Berner, Christopher, et al. "Dota 2 with large scale deep reinforcement learning." arXiv preprint arXiv:1912.06680 (2019).
2.Vinyals, Oriol, et al. "Grandmaster level in StarCraft II using multi-agent reinforcement learning." Nature 575.7782 (2019): 350-354.
3.Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." nature 529.7587 (2016): 484-489.
4.Silver, David, et al. "Mastering the game of go without human knowledge." nature 550.7676 (2017): 354-359.
5.Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." 2009 IEEE conference on computer vision and pattern recognition . Ieee, 2009.
6.Verbraeken, Joost, et al. "A survey on distributed machine learning." ACM Computing Surveys (CSUR) 53.2 (2020): 1-33.
7.N. Saeed, H. Almorad, H. Dahrouj, T. Y. Al-Naffouri, J. S. Shamma and M. -S. Alouini, "Point-to-Point Communication in Integrated Satellite-Aerial 6G Networks: State-of-the-Art and Future Challenges," in IEEE Open Journal of the Communications Society, vol. 2, pp. 1505-1525, 2021, doi: 10.1109/OJCOMS.2021.3093110.
8.Luo, Xi. "Optimization of MPI Collective Communication Operations." (2020).
9.Li, Mu, et al. ”Scaling distributed machine learning with the parameter server." 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14). 2014.
10.Baidu Ring AllReduce https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
11. NCCL developer.nvidia.com/nccl
12.Horovod https://horovod.ai/
13.Seide, Frank, et al. "1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns." Fifteenth Annual Conference of the International Speech Communication Association. 2014.
14.Wen, Wei, et al. "Terngrad: Ternary gradients to reduce communication in distributed deep learning." arXiv preprint arXiv:1705.07878 (2017).
15.Aji, Alham Fikri, and Kenneth Heafield. "Sparse communication for distributed gradient descent." arXiv preprint arXiv:1704.05021 (2017).
16.Lin, Yujun, et al. "Deep gradient compression: Reducing the communication bandwidth for distributed training." arXiv preprint arXiv:1712.01887 (2017).
17.【AI训练3倍提速】海量小文件场景下训练加速优化之路
18.Keskar et al, On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima, 2017 (ICLR)
19.Goyal et al, Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, 2017 (Facebook Report)
20. You, Yang, et al. "Imagenet training in minutes." Proceedings of the 47th International Conference on Parallel Processing. 2018.
21.LARSOptimizer https://www.tensorow.org/api
22.You, Yang, et al. "Large batch optimization for deep learning: Training bert in 76 minutes."
23.Google Menger https://ai.googleblog.com/2020/10/massively-large-scale-distributed.html
作者简介

陈世勇
腾讯高级算法研究员
腾讯高级算法研究员,毕业于南京大学机器学习与数据挖掘研究所。主要从事强化学习,分布式机器学习方面的研究工作,并在国际顶级会议和期刊上发表多篇论文。同时,对于大规模强化学习在游戏AI和推荐系统领域的落地和应用有着丰富经验。
推荐阅读
手把手教你快速理解gRPC!
golang:快来抓住让我内存泄漏的“真凶”!
一文读懂@Decorator装饰器——理解VS Code源码的基础(下)
一文读懂@Decorator装饰器——理解VS Code源码的基础(上)
