探游·R329·AI部署实战(二)移植搭建AI环境
首发极术社区
如对Arm相关技术感兴趣,欢迎私信aijishu20加入技术微信群。
前言
hello呀~我又来啦~这一期拖了好久啦~由于周末抽时间做的,时间不稳定,抱歉呐~
上次做了R329的第一期,也就是解决了配置R329开发板并跑起来的问题;
这一期能解决的问题是:你能用R329上的AIPU跑个resnet50啥的,你能用R329的CPU跑起来NCNN,跑个resnet50,mobilenet啥的,并对比性能数据。
ps. 关于自定义模型如何在AIPU上跑,如YOLO_XX,KWS_XX等,就是下一节的内容啦~当然按照惯例,我会先教你们把环境搭建好;
这一期大概要解决的问题如下:
- ”我要怎么样才能在R329上跑模型的呀?不要多了,能跑你们官方的demo就行,我主要想对整体的开发流程有个主观印象。”
- ”我想跟NCNN跑的数据做对比,我该如何在R329上移植NCNN并跑benchmark的呀?要怎么准备环境、怎么跑的呀?“
- “我要跑自定义模型该如何操作的呀?”
- ”我的模型贼复杂,有前后处理balabala的,我想一部分在CPU上做一部分在AIPU上做(这有个装逼的名字叫"切图"),这要怎么搞得呀?“
我相信上述的这些问题,对大部分非经验丰富的开发者来说,是有一点点困扰的吧!?
因此本着传播知识的初衷,我将从底层细节一点点带大家开荒R329,尽量讲清楚为什么这么做的原因,而不是机械的教大家去操作。
同时,为了尽可能照顾到不同开发环境的童鞋,我准备了两个版本的开发环境,一个是WIN10自带的WSL(ubuntu18),一个是虚拟机下的ubuntu14.04, 目的是为了尽可能的把坑给踩完先。
第一节 我要怎样才能在R329上跑起来AIPU的呀?
可能有小伙伴不想看啰嗦的分析,只想一步到位跑起来呀,所以,请跟着我左手右手一个慢动作。。。。
- 先跟着教程第一章把板子准备好,注意此时的板子的linux kernel驱动是有的,但是没有把AIPU的runtime库编译进去的。
- 从【点击这里】获取下载链接,得到lib库文件;从【这里这里】下载resnet50 demo的执行文件。
- 将libaipudrv.so*文件放到开发版的/lib目录下(用usb的话直接adb push就好啦, 用wifi传的话就直接scp下载了);
- 将resnet50文件夹放到开发版的/etc/zhouyi/目录下即可;
- 运行sh脚本, 加上参数-C resnet_50即可;加上time指令就大致知道花了多少的时间啦~
下面就是详细的分析啦,不想看我叭叭的就直接跳过哈~
要能跑起来AIPU首先驱动层得支持,其次runtime库也得支持,接着我们才可以在应用层调用AIPU;
这里得好消息是驱动默认就支持了,坏消息是runtime库一时半会还不会完全开源,因此我们需要先解决runtime库得问题。
上期我们说过了,由于AIPU的知识产权是属于ARM china的,所以全志暂时是不会开放出来给我们使用的(对应的就是在开发的源码中把这一部分库代码给删除了),
但值得注意的是内核驱动时有支持的,既然有内核驱动,因此我们只需要在库层面添加用户runtime包就可支持AIPU啦~
啥?你问这个runtime包是啥?
这个runtime包的定义在不同语境里都不一样的,在这里代表的就是对AIPU驱动的一层封装;常规的嵌入式开发流程里面,有个外设,你要在应用层调用它,你就得
直接用read/write/ioctl等一系列操作来控制这个设备,很原始很低效,于是我们就在此基础上封装出一个库,来屏蔽底层的繁琐细节,这就是runtime库存在的意义。
理论可行,但实际上这个包一般也是拿不到的,因为官方没开放也没开源呀~
头疼,俗话说的好,万事开头难在,中间难,后面也难,既然都这么难了,那我选择躺好,选择求助官方。
于是经过三分钟的对话沟通,我从ARM china官方接口那获取到了runtime库的lib包,因此我会把该文件分享给有需要的人,以及教会大家如何使用它。
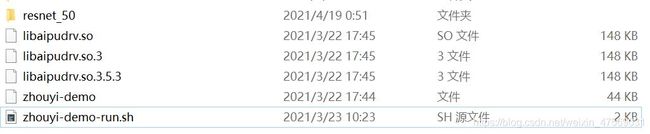
把这些文件给adb push *** /etc/zhouyi/即可,记得把libaipudrv.so/libaipudrv.so.3/libaipudrv.so.3.5.3全部复制到开发板的/lib/目录下;
跑出来的效果如下:

可以看到用户空间的耗时大致是10ms的样子,于是我们就可以根据数据分析一波了:
| Resnet50 | OPs | INT8 |
|---|---|---|
| MAC | 3857973248 | 3.8G |
| OUT | 35778536 | 35MB |
| PARA | 25557096 | 25MB |
我们知道resnet50的理论计算量大概是4Gops,而我们AIPU的理论算力是128MAC *0.8Gpbs=102.4GOPS
因此理论峰值算力下的FPS为:FPS=102.4/4=25FPS
而真实的算力约为10FPS,算力仅利用完一半不到,也就是可以大致推断出访存部分是瓶颈,嗯,访存带宽的问题没有做好呀~
做优化的都知道,访存其实这个也好分析,resnet中存在大量的3X3跟1X1卷积层,这些卷积层在硬件底层都是由脉动阵列进行计算的,而3x3的卷积属于计算密集型,实际上MAC利用率能达到百分之八九十,
而1x1卷积属于访存密集型,也就是说巨大的算力往往都在等数据ready,实际中MAC利用率也就50%左右的样子,因此这个帧率跟最终的结果就对上啦~
嗯,其他的硬件如CPU,GPU、NPU都可以这么分析,基本原理都是一样滴哇~
第二节 我要怎样才能用R329的双核A53上跑起来NCNN呀?
这部分看下如何使用交叉编译链!
上一篇中我们简单使用了gcc编译了个helloworld,可以正常运行,但是用g++则不行,后来百般调试无果之后,直接选择放弃官方提供的prebuild工具链。
我们自己动手丰衣足食。
思路是这样子的:
1. 先去板子上确认交叉编译器的版本,然后选择比这个版本低的来编译NCNN,因为发布的版本向后兼容,不会向前兼容的呀。
2. 在ubuntu上下载对应版本,解决其中出现的一些问题,链接到合适的版本,balbala~很碎所的,这就是为什么叫开荒的由来了!
3. 下载NCNN源码,配置好CMAKE,然后修改并编译好benchmark文件,解决其中出现的一大堆问题;
4. 跑benchmark,看数据~
我特意在几个版本的环境下编NCNN,期间出现了很多基本问题,虽然不是很难,但我知道总有一部分读者是需要的,需要这些“显而易见”的指引的,往往前行路上的一颗绊脚小石头就可能会阻碍你的脚步、消融你的激情,因此我希望我写的内容不单单是冰冷的技术分享,而应当是有温度的包容,这是我敲下这行字时想到的。
所以,我这里不计其繁地一一记录如下,大家权当debug手册来用吧~
要知道编译器版本,我们先去板子上看下交叉编译的版本,怎么看呢?
我们去lib目录下,系统库文件都在下面呢!

用ldd指令可以看到libc.so使用的GCC 版本是6.4.1,因此我们在ubuntu下直接安装小于等于这个版本的GCC就行啦~
通用的方法是去官网下载:
https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-a/downloads
但是我们可以简化处理,直接再ubuntu下在线下载安装。
由于我们得宿主机是ubuntu14.4,因此先看下有哪些版本得交叉编译工具可以下载:
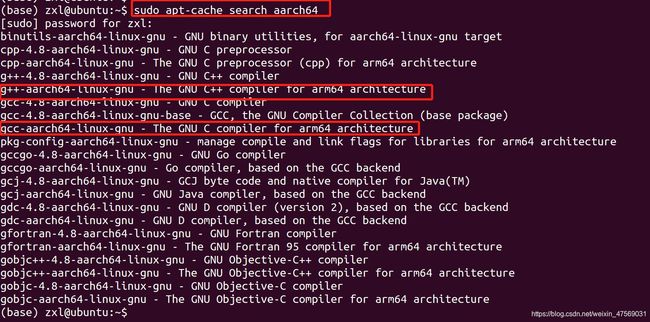
可以看到,针对arm64的,只有4.8的版本,4.8的版本比R329的6.4.1版本低,因此编译出的文件送到板子上理论上可以运行。
然后再下载一个不带版本的GCC、G++:
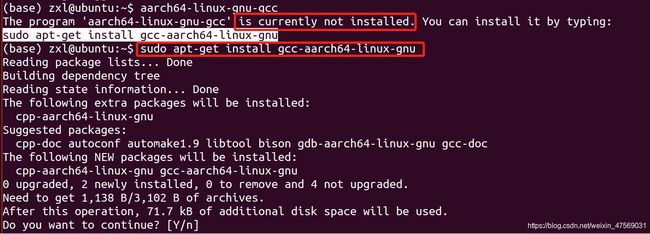

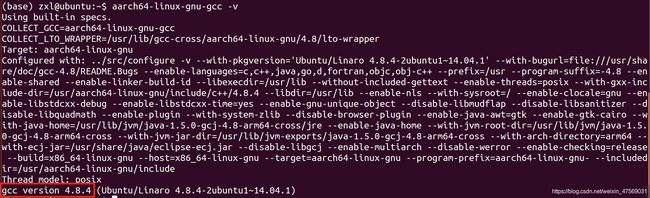
此时可以发现安装的版本对应上啦,gcc version 4.8.4 ubuntu/linaro;
这个时候我们再验证下helloworld看看,这个时候gcc g++都得验证下:

然后我们看下ELF头信息:
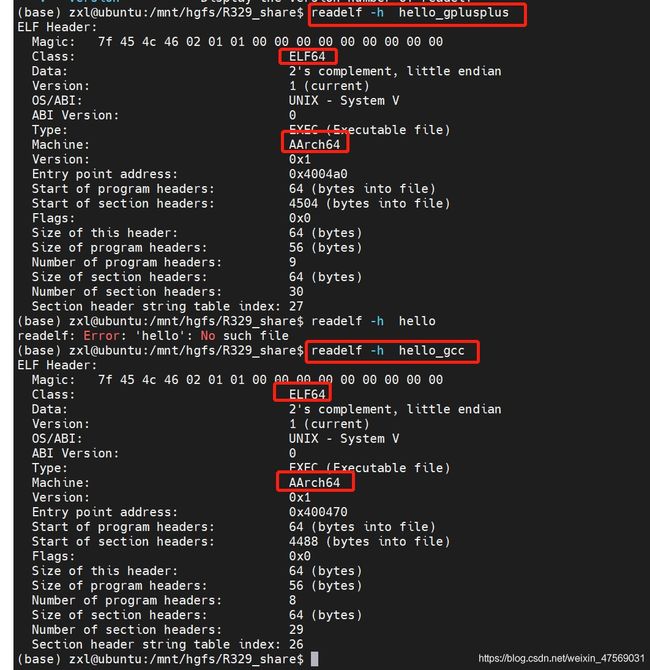
可以看到对应的是aarch64,对应上了~可以整活了~
然后,直接把编译好的gcc/g++ 版本helloword, 通过adb push推送到开发板上执行,此时发现
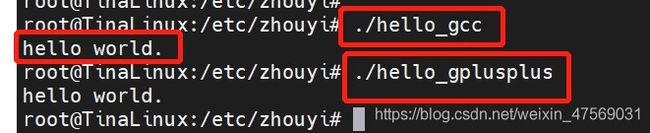
ok啦~
一切都好起来啦~
然后我们开始编译复杂点的NCNN。
git clonehttps://github.com/Tencent/ncnn.git
cd ncnn
mkdir -p build-aarch64-linux
cd build-aarch64-linux
cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/aarch64-linux-gnu.toolchain.cmake ..
make -j8
make install
按照官网流程,一套组合拳直接打下来,看现象:
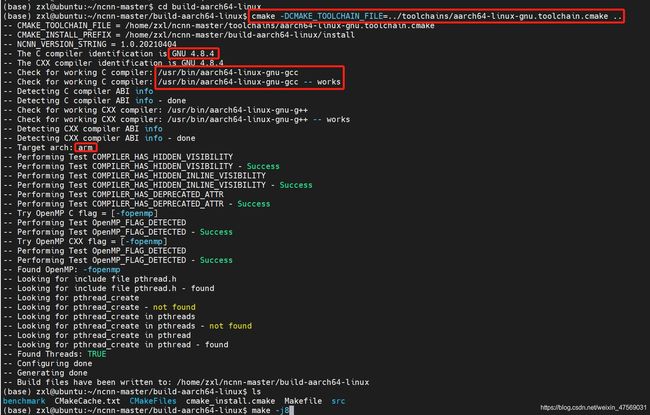
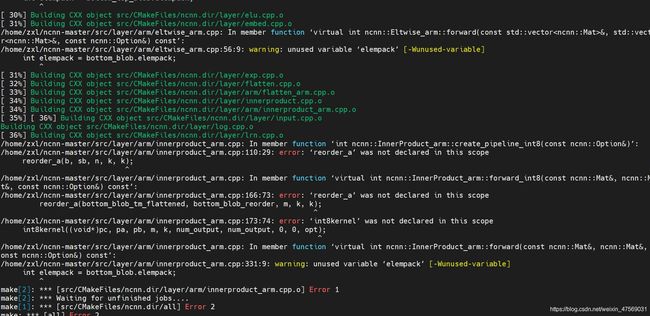
编译到36%直接报错,说是找不到某个layer的某个方法,一顿查,发现是交叉环境没装全:
sudo apt install g++-arm-linux-gnueabi g++-arm-linux-gnueabihf g++-aarch64-linux-gnu
补全后,再编译,发现最后链接时出问题啦又:
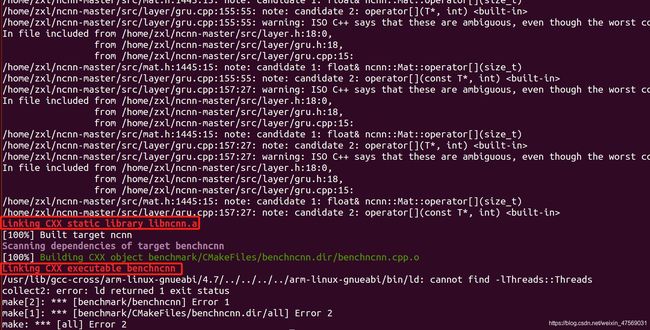
这里卡了好久,为啥不行,百般查询之后发现,是源的选择不对,我选的是阿里源,在这个源下只有4.8版本的可以安装,因此我们换一下,换成清华源:
# 清华大学源
debhttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic main restricted universe multiverse
debhttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-security main restricted universe multiverse
debhttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-updates main restricted universe multiverse
debhttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-backports main restricted universe multiverse
##測試版源
debhttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-proposed main restricted universe multiverse
# 源碼
deb-srchttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic main restricted universe multiverse
deb-srchttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-security main restricted universe multiverse
deb-srchttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-updates main restricted universe multiverse
deb-srchttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-backports main restricted universe multiverse
##測試版源
deb-srchttp://mirrors.tuna.tsinghua.edu.cn/ubuntu/bionic-proposed main restricted universe multiverse
具体操作如下:
修改源文件 sources.list:
Ubuntu 的源存放在在/etc/apt/目录下的sources.list文件中,
修改前我们先做个备份,在终端中执行以下命令:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bcakup
然后执行下面的命令打开 sources.list 文件,清空里面的内容,把上面我们编辑好的清华的源复制进去,保存后退出。
sudo gedit /etc/apt/sources.list
更新软件列表和升级,在终端上执行以下命令更新软件列表,检测出可以更新的软件:
sudo apt-get update
在终端上执行以下命令进行软件更新:
sudo apt-get upgrade
此时再检查下有哪些交叉编译器版本:

可以看到5,6,7,8版本都有的,此时我们只需要选择一个版本安装就行啦!
选择哪个版本?当然是小于等于开发板的版本呀!前面查过开发板的是6.4.1版本,这里的6版本安装后发现是6.5.0版本的,因此不行的,我们只能用5开头的版本(当然7版本的我也试过,NCNN没出什么问题,但是不排除今后移植其他三方软件的时候出问题,因此稳妥起见这里用5开头的版本):
先把之前的6.4.1版本的aarch64-arm-linux-gnu gcc/g++都删掉:
sudo apt-get remove *(注意:把依赖也要删除干净,用autoremove指令。)
然后安装之后发现aarch64-linux-gcc/g++ 链接到的不是5开头的编译器,因此修改软连接ln -snf /usr/bin/aarch64-linux-gnu-gcc-5 /usr/bin/aarch64-linux-gnu-gcc;
好啦终于把NCNN编译出来啦,由于我们只跑benchmark,因此直接在build目录下找benchnn,推到板子上运行,注意对应的param文件也要推进去哟:
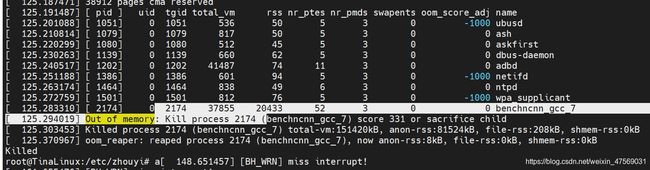
好家伙发现,直接内存爆掉了,一想也对,毕竟就256M内存,看一下剩余多少?

开机就只剩余71M内存,内存不够的呀,怎么办?
1. 修改镜像让CAM分配少一点内存给AIPU;
2. 修改ncnn的benchmark.cpp 使用inplace轻量内存模式,不开数据重排(数据重排可以使CPU加速的哟,这块我贼6,有空给大家叨叨);
方案一得该内核,太麻烦了,于是我直接改NCNN benchmark.cpp了,只跑mobilenet系列:
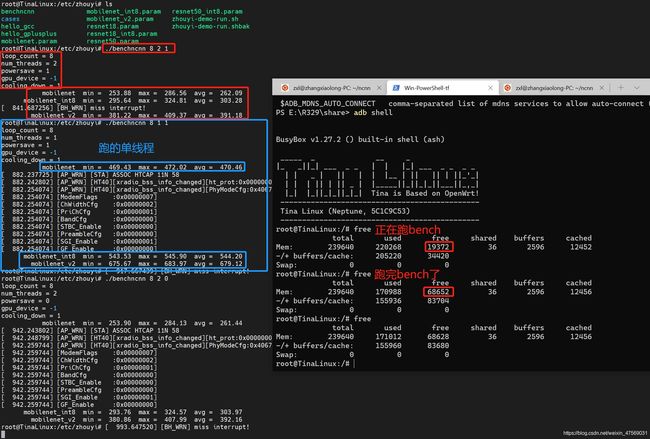
嗯结果出来啦,我跑得是A53单线程,理论峰值算力一二十个GFlops,加上访存得固有缺陷,因此跑出这个数据也是阔以理解的。
我们能得到的结论就是: AIPU大法好呀~
第三节 我要怎样才能跑自己的模型呀??
好的,至此,从下往上看,我们的硬件能跑起来了,AIPU驱动是ok的了, runtime环境也ok了(见附录:如何编译第三方package),
接下来就可以到AIPUBuilder部分了,这部分是整个AI软件部分的核心部件,也就是能让你自己的模型在R329上跑起来的关键了。
jio逗嘛嘚~~等等。。。
肯定有人要问的啦,“啥啥啥?咋又出来个AIPUBuilder?这是啥?干啥用的?怎么用?
你之前整了这么多出,啰嗦了这么多,我都整晕了,你就从我使用者的角度出发,告诉我这个是啥?能解决啥问题?”
······
·······
好的,好的,不要再骂了,我错了,我知道错了,是我写博客流程有瑕疵了,我已经深刻地认识到了我的错误了~

但是我还敢…还敢不改(国家一级精分表演大师show场。。。)


各位大佬们此时此刻恰如彼时彼刻:


好liao好liao,不自娱自乐了,正式开整(真好,想怎么写怎么写,想怎么乐怎么乐~周末还能宅一天):

我们看问题采用黑盒模型,输入是啥,目标(输出)是啥:
输入:是一个模型,可能来自pytorch/tensoflow/tflite/onnx/caffe….等等格式;
目标:就是把这个模型部署到R329硬件板子上,能跑起来看到效果,语音就能答应你,人脸识别就能认出你。
可以看到我们有头(输入),有尾(目标)了,因此只要在两者之间填充亿点点细节

我们的AI模型就在R329上跑起来啦~ 怎么样是不是很简单呀~
这个部分分三个阶段:
-
大致讲下AIPUBuilder是啥,能干啥;
-
准备AIPUBuilder的环境;
-
使用AIPUbuilder生成目标bin文件;(划掉,这次不想细写) -
AIPUBuilder能干啥?
你看我们的模型来自五湖四海吧(pytorch/tensoflow/tflite/onnx/caffe….),是不是格式都千奇百怪,算子也是奇形怪状,
这么多的差异要跑到特定的(固定的、单一的)硬件上来,那就可以简单认为是一个多对一的接口呀!
说个时髦一点的词,就是AI编译器啊!
说到AI编译器,我们可以看一篇2020年8月份的综述:《The Deep Learning Compiler: A Comprehensive Survey》

上面的图我大致解释下,所谓的AI编译器,分为前端跟后端,前端对接各种训练框架,把模型解析了,然后做各种与硬件无关的图优化,量化啊啥的,分的细一点的话这部分也会产生上层IR表示。
后端就是用来对接不同的硬件的,标准的AI编译器是要能对接任意硬件后端的,跟硬件相关的话简单来说就是各种算子实现了,基于各种不同硬件的算子实现,在这个层面就有各种优化策略,与上层的IR表示有所差异,因此一般会产生底层IR表示;
而R329的AIPU由于不是做通用的编译器,不需要支持很多的硬件后端,因此结构可以优化一下,比如只用一套IR表示、上层图优化与底层硬件绑定等等,当然其他的通用优化这里也都能做。
因此按照行业标准流程我们可以大致分为parser、quantization、graph optimizer、compiler,builder等等部分,但是为了简化用户操作,只留一个aipubuild的接口,具体怎么使用下一节再说。
我们简单解释下IR作用是啥?
上述的几个大的部分,就好比人的脑袋、躯体、手脚,这些部分之间需要一个东西来互相通信,在人体里面是神经系统,而在AIPUbuilder里面就是IR了,即中间表示。
IR是一套内部定义的标准让各个模块都按照这个标准来处理模型信息,厂商不同标准也不同的,比如intel的openvino里面用的肯定跟我们不一样了。
好了,到这基本解释清楚,AIPUBuilder是干啥的了!一言以蔽之:“AI 编译器”,负责将AI模型编译成能在AI芯片上跑的目标bin文件。
- AIPUBuilder环境配置
咱们接着在说下如何配置AIPU的环境,使之能跑AI模型;
咱们首先第一步先看全志的手册《AW_R329_Tina_Linux_开发入门_v0.5》,在page18 的附录1:在ubuntu14中使用Conda搭建python3.6环境;注意哈,这里是指定了版本以及环境的:

我们跟着一顿操作,然后激活conda虚拟环境,总之跟着文档来就行啦~
然后我们会拿到一个安装包AIPUBuilder-3.0.120-cp36-cp36m-linux_x86_64.whl(没有的找我要~),使用pip安装就好了。

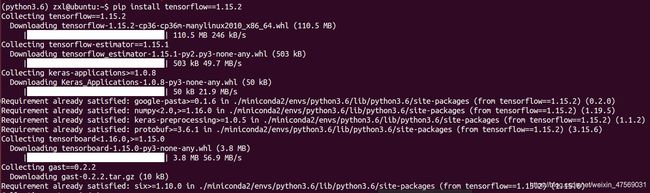
然后就开始安装了哇:pip install AIPUBuilder-3.0.120-cp36-cp36m-linux_x86_64.whl
由于网络不行,这里下载了好久,看到这里就说明,安装成功啦~
注意观察log可以看到tensorflow/pytorch的版本,这个你们在转模型的时候需要特别注意的点。
我们看下帮助指令:
![]()
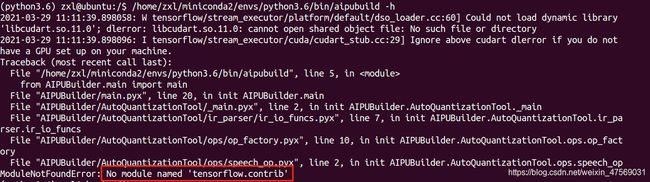
原来是安装的版本与要求的版本不一致:

我们先卸载当前版本:
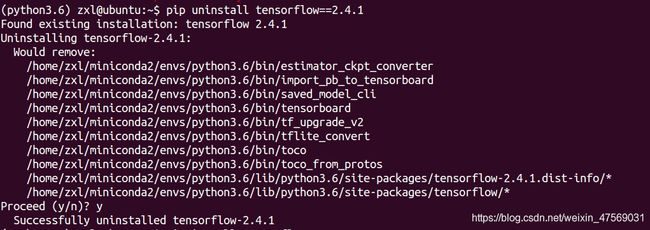
然后随便安装一个满足要求的版本:
又发现AQT里面用了PIL:

于是我们接着装pillow:

接着装networkx:
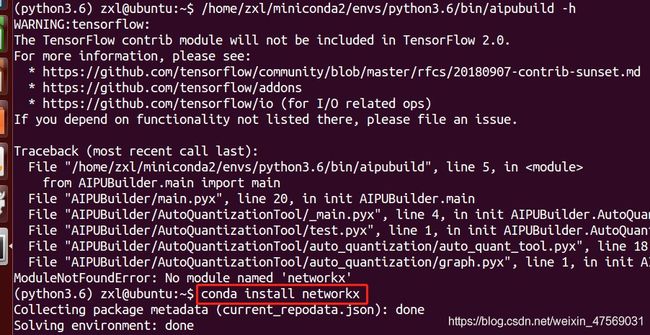
通过这亿点点操作终于环境ok啦~

- 如何使用GBuilder
我们去这里随便下载一个kws模型
https://github.com/ARM-software/ML-KWS-for-MCU

然后直接把pb文件喂给AIPUBuilder,记得加上kws.cfg文件,这个文件的参数分析留到下一次博客吧,原因是,这节内容太多啦~
最后就会生成如下的三个文件:

然后adb push推送到开发板上,运行效果如下:

正常运行啦~
具体操作细节由于篇幅过大就留到下一章啦~
第四节 我要怎样才能切图(异构计算)呀?
这部分打算配合tengine框架来用,他们的切图贼溜,但是我完全没时间,下次再写。
相关阅读:
- R329 开发环境搭建
- 修改WiFi/BT模组—R329智能语音开发板入门